Second-Order Actor-Critic Methods for Discounted MDPs via Policy Hessian Decomposition
Pith reviewed 2026-06-30 21:36 UTC · model grok-4.3
The pith
Treating the action-value function as locally constant justifies second-order actor updates in a two-timescale actor-critic framework for discounted MDPs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
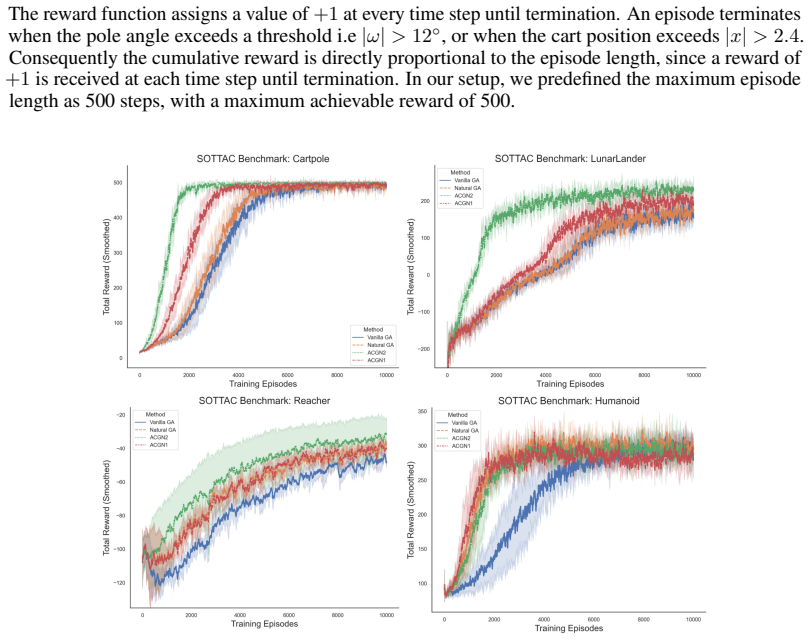
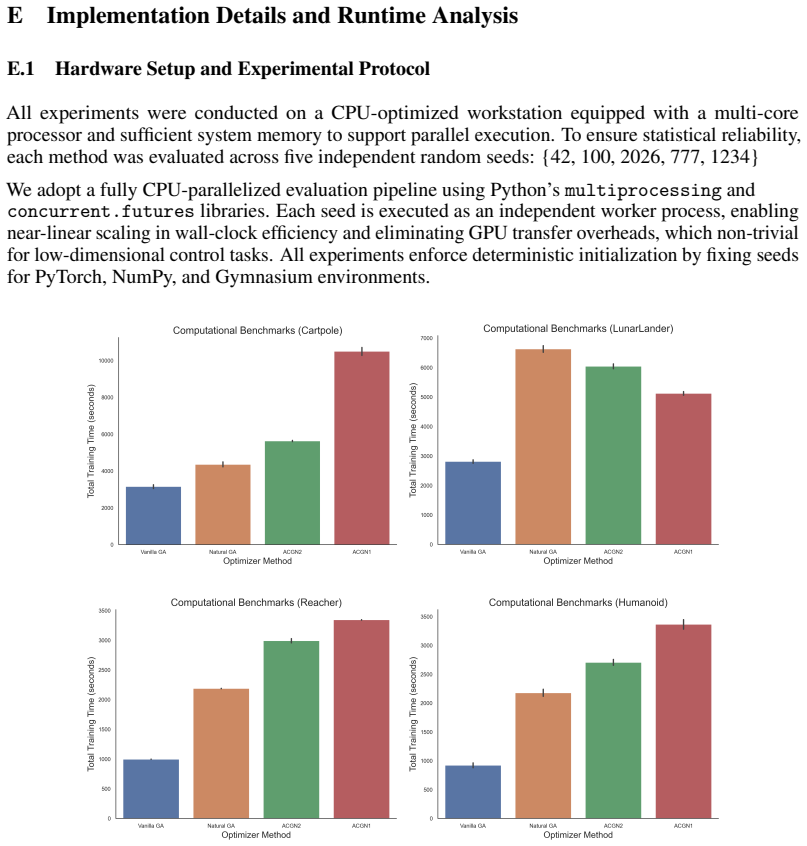
We formulate a second-order actor-critic method for the discounted reward setting that leverages Hessian-vector product computations. This rests on second-order approximations for the actor update that incorporate full curvature information of the objective as far as possible, with the required local-constancy approximation of the action-value function becoming well-justified under a two-timescale separation in which the critic is treated as quasi-stationary during actor updates.
What carries the argument
Policy Hessian decomposition under the local-constancy approximation of the action-value function with respect to policy parameters, which enables stable Hessian-vector product updates for the actor.
Load-bearing premise
The action-value function can be treated as locally constant with respect to the policy parameters during each actor update step.
What would settle it
An empirical trace showing that the critic's action-value estimates change substantially during a single actor update step would violate the quasi-stationary assumption and falsify the stability justification.
Figures
read the original abstract
We address the discounted reward setting in reinforcement learning (RL). To mitigate the value approximation challenges in policy gradient methods, actor-critic approaches have been developed and are known to converge to stationary points under suitable assumptions. However, these methods rely on first-order updates. In contrast, second-order optimization provides principled curvature-aware updates that are proven to accelerate convergence, but its application in RL is limited by the computational complexity of Hessian estimation. In this work, we analyze second-order approximations for the actor update that leverage the full curvature information of the objective as much as possible. A stable approximation requires treating the action-value function as locally constant with respect to policy parameters, which does not generally hold in policy gradient methods. We show that this approximation becomes well-justified under a two-timescale actor-critic framework, where the critic evolves on a faster timescale and can be treated as quasi-stationary during actor updates. Building on this insight, we formulate a second-order actor-critic method for the discounted reward setting that leverages Hessian-vector product (HVP) computations, resulting in a computationally efficient and stable second-order update.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes second-order actor-critic methods for discounted MDPs. It decomposes the policy Hessian and claims that a two-timescale separation (faster critic updates) justifies treating the action-value function as quasi-stationary with respect to policy parameters, enabling a stable approximation that ignores dQ/d heta terms and permits efficient Hessian-vector product updates.
Significance. If the two-timescale analysis supplies a rigorous vanishing error bound, the result would supply a principled route to curvature-aware actor updates in RL without prohibitive Hessian costs, potentially improving convergence rates over standard first-order actor-critic methods while preserving stability guarantees.
major comments (2)
- [Abstract and two-timescale framework] Abstract / two-timescale justification: the claim that quasi-stationarity makes the local-constancy approximation (ignoring dependence of Q on heta) 'well-justified' is load-bearing for the central contribution, yet the provided text offers no explicit error bound showing that the additional Hessian terms arising from the discounted occupancy measure and Bellman operator vanish with the timescale ratio; without this, the approximation remains formally incomplete.
- [Hessian decomposition and actor update] Policy Hessian decomposition: the decomposition must be accompanied by a theorem establishing that the approximated HVP equals the true policy Hessian plus a term that is o(1) under the two-timescale limit; otherwise the curvature information used in the actor update may not be accurate enough to support the claimed stability and acceleration.
minor comments (2)
- [Notation and definitions] Notation for the timescale separation parameter and the resulting error term should be introduced explicitly with a clear limit statement.
- [Abstract] The abstract states the approximation becomes justified but does not reference the specific theorem or proposition that proves the error bound; adding such a pointer would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address the two major comments point by point below. Both comments correctly identify that the current manuscript lacks explicit quantitative bounds on the approximation error; we will add the requested results in revision.
read point-by-point responses
-
Referee: [Abstract and two-timescale framework] Abstract / two-timescale justification: the claim that quasi-stationarity makes the local-constancy approximation (ignoring dependence of Q on heta) 'well-justified' is load-bearing for the central contribution, yet the provided text offers no explicit error bound showing that the additional Hessian terms arising from the discounted occupancy measure and Bellman operator vanish with the timescale ratio; without this, the approximation remains formally incomplete.
Authors: We agree that an explicit error bound is required to make the two-timescale justification rigorous. In the revised manuscript we will insert a new theorem (with proof) that bounds the difference between the true policy Hessian and the approximated Hessian that ignores dQ/d heta; the bound will be shown to vanish as the ratio of the critic and actor step-size sequences tends to zero under standard two-timescale assumptions. revision: yes
-
Referee: [Hessian decomposition and actor update] Policy Hessian decomposition: the decomposition must be accompanied by a theorem establishing that the approximated HVP equals the true policy Hessian plus a term that is o(1) under the two-timescale limit; otherwise the curvature information used in the actor update may not be accurate enough to support the claimed stability and acceleration.
Authors: We accept this point. The revised version will contain an additional theorem stating that the Hessian-vector product computed under the locally constant critic approximation equals the true policy Hessian plus a remainder that is o(1) in the two-timescale limit. The proof will rely on the same separation of timescales used for the critic convergence. revision: yes
Circularity Check
No circularity: two-timescale quasi-stationarity invoked as external modeling assumption
full rationale
The paper's central step invokes a two-timescale actor-critic separation to justify treating the action-value function as locally constant w.r.t. policy parameters when forming the Hessian. This is presented as a standard modeling choice that makes the approximation valid, rather than a quantity fitted from the target result or defined in terms of itself. No equations reduce the claimed justification to a self-citation chain, a fitted parameter renamed as prediction, or an ansatz smuggled via prior work by the same authors. The derivation therefore remains self-contained against external benchmarks such as standard two-timescale analyses in the literature.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Two-timescale separation where the critic updates faster than the actor, allowing the critic to be treated as quasi-stationary
Reference graph
Works this paper leans on
-
[1]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
The critic value estimate ( Qc) evolves on a faster timescale than the actor
B The Two-timescale Insight Under the two-timescale actor-critic framework Konda and Tsitsiklis [2000], Borkar [1997], Q is estimated using a separate function network known as the critic. The critic value estimate ( Qc) evolves on a faster timescale than the actor. As a result, during policy (actor) updates the critic can be treated as approximately stat...
2000
-
[3]
In this section, we analyze the curvature structure of the policy Hessians and after approximations used in ACGN1 and ACGN2
13 C Curvature Properties of the Policy Hessian Once we remove the policy Hessian using the two-timescale insight, we approximate the policy Hessian as ACGN1 and ACGN2 as mentioned in Section ?? and ??. In this section, we analyze the curvature structure of the policy Hessians and after approximations used in ACGN1 and ACGN2. Specifically, we characterize...
2016
-
[4]
Consequently, ACGN2 preserves the concave curvature structure required for stable maximization and admits a well-conditioned second-order ascent direction
ForACGN2, under log-concave policy parameterizations (e.g., softmax or Gaussian policies), the intrinsic curvature satisfies eHt ⪯0, which implies that the damped matrix −eHt +λI is naturally positive definite. Consequently, ACGN2 preserves the concave curvature structure required for stable maximization and admits a well-conditioned second-order ascent d...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.