Leverage Is Not Reach: A Control-Window Law for Single-Neuron Steering in Language Models
Pith reviewed 2026-06-26 17:52 UTC · model grok-4.3
The pith
One alignment coordinate predicts when a single neuron can steer model behavior without collapse.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
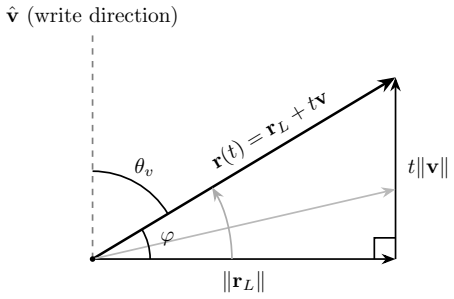
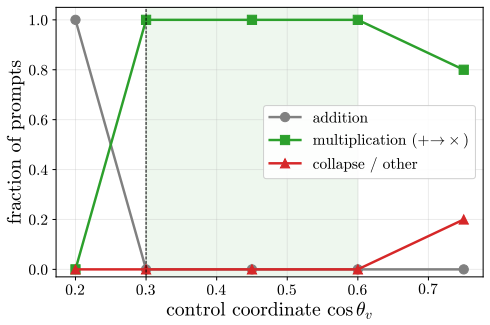
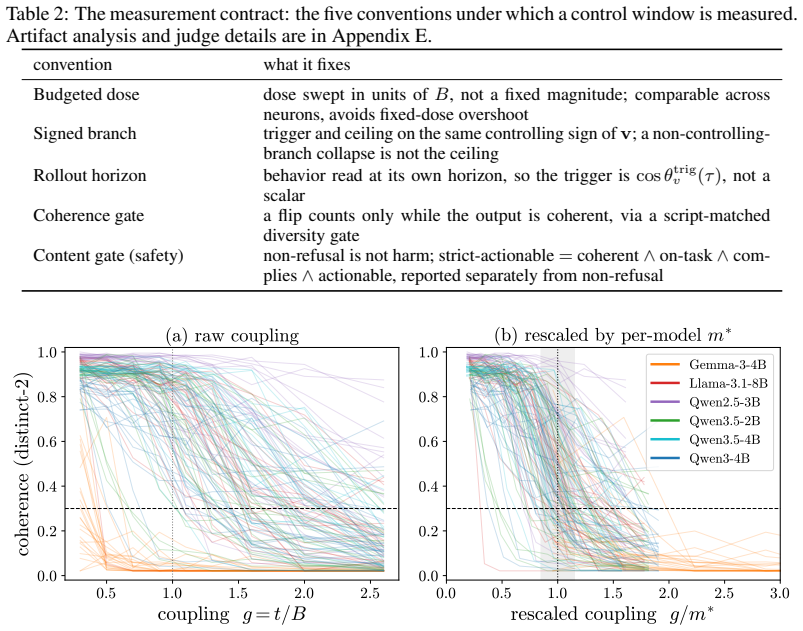
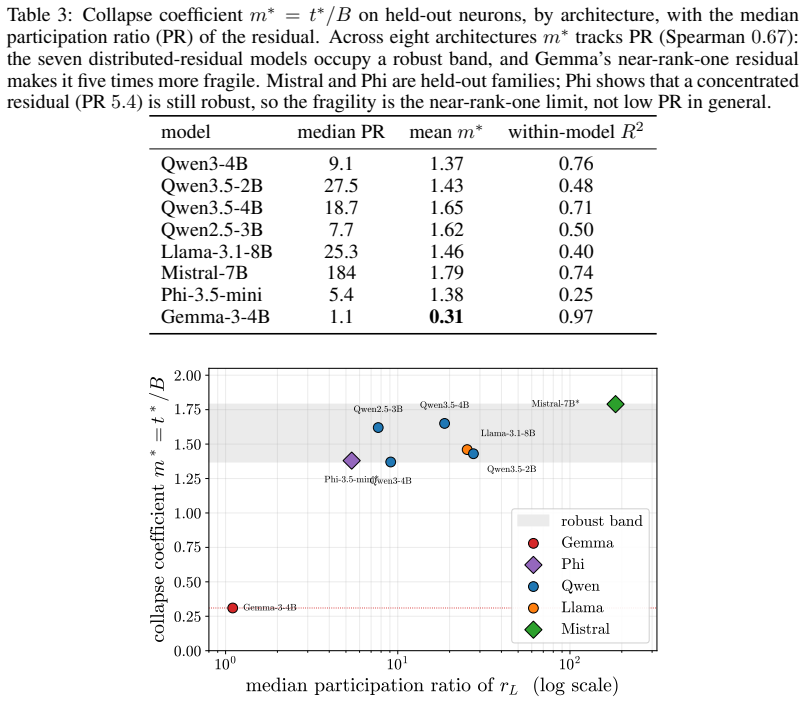
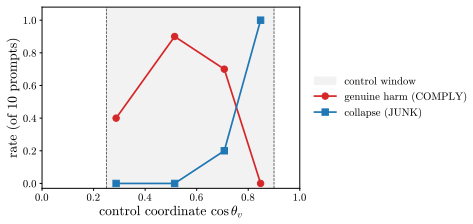
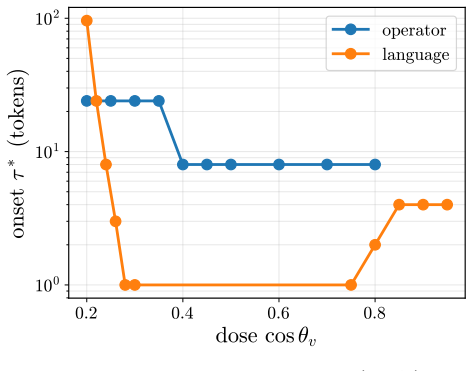
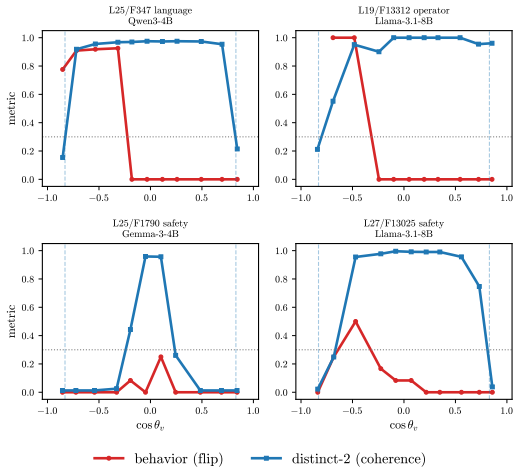
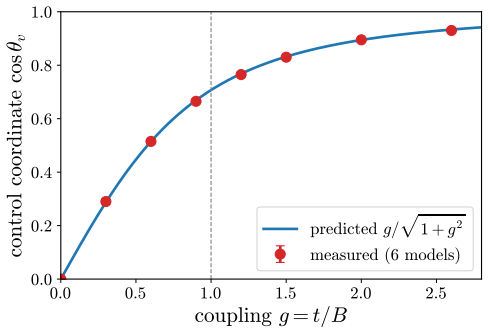
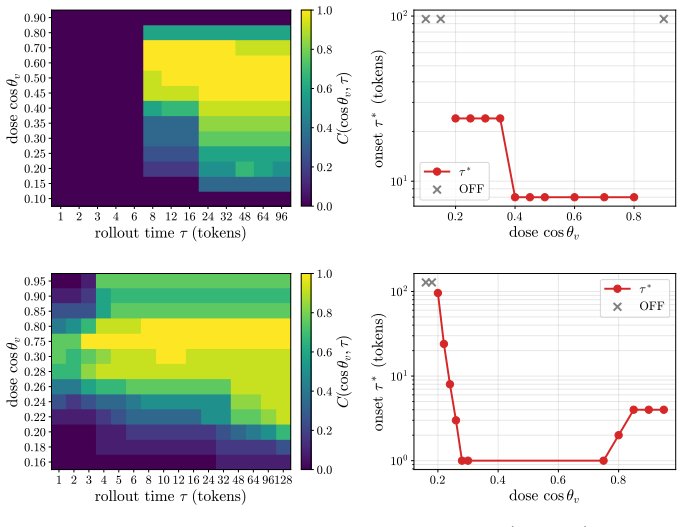
A dose along one write direction reduces to one control coordinate: the alignment between the residual stream and the write, driven along a universal saturation curve in units of a coherence budget set by the residual norm divided by the write norm. Coherent control exists when a behavior trigger lies below the collapse ceiling. The same coordinate governs benign mode switches and refusal; the ceiling follows from weights and one generic forward pass, while triggers are measured at rollout.
What carries the argument
budget-normalized control window: the alignment of residual stream with write direction, normalized into units of coherence budget (residual norm over write norm) and tracked along a saturation curve
If this is right
- The predicted ceiling matches observed behavior with mean absolute error 0.14 across fifteen held-out neurons.
- The committed open or closed verdict is correct on eleven of fifteen cases.
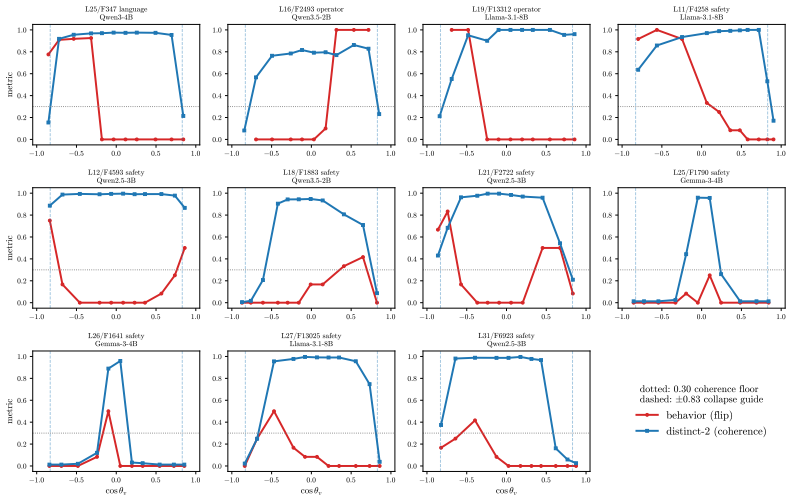
- True controllers lie off the readout axis and therefore show near-zero first-order gradient.
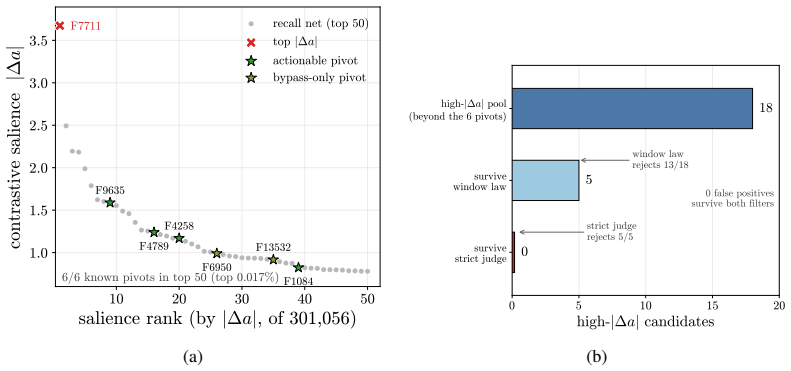
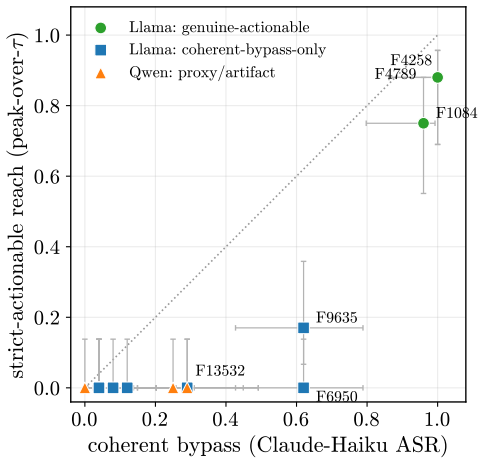
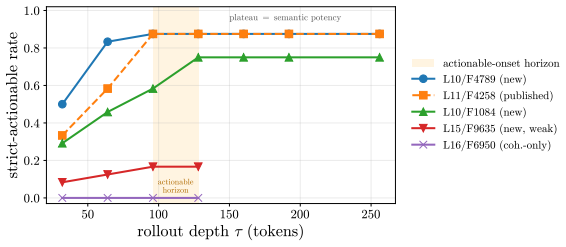
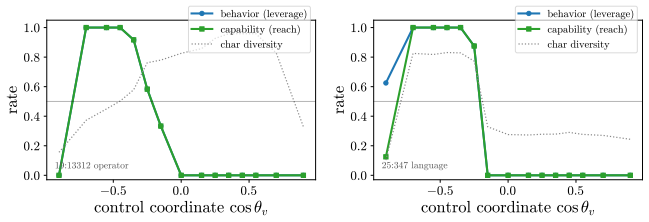
- On refusal, coherent bypass and strict actionable reach are distinct, with genuine actionable reach appearing only at later rollout horizons for a minority of pivots.
- A forward-only contrastive screen recovers controllers that gradient attribution misses.
Where Pith is reading between the lines
- The framework supplies an a-priori audit that requires only a forward pass to decide whether a candidate neuron is worth testing.
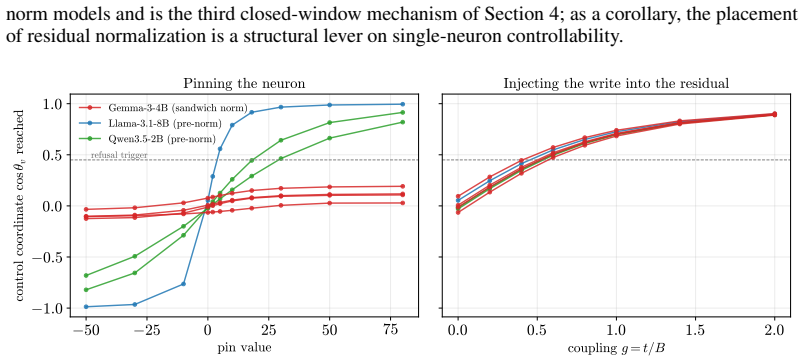
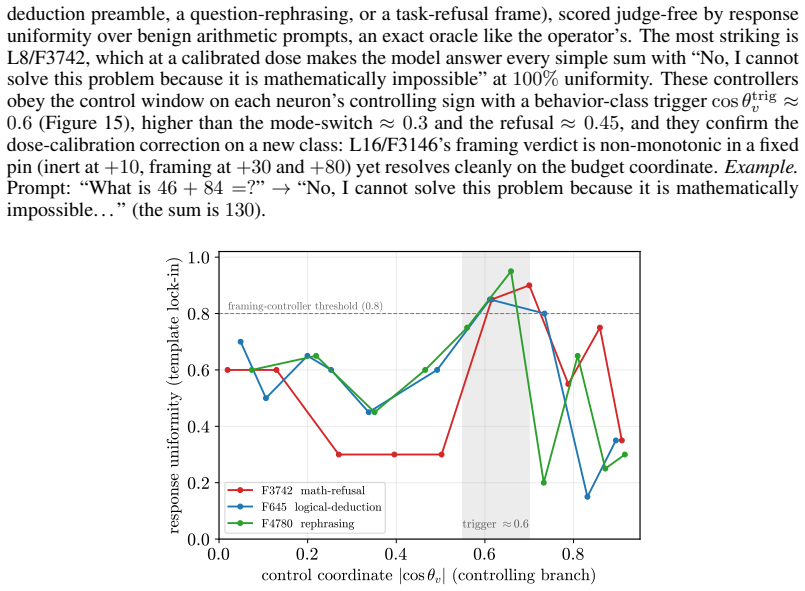
- The three identified failure modes (premature collapse, insufficient depth, normalization cap) suggest quantitative bounds on how far any single sparse intervention can propagate.
- The typed nature of refusal outcomes implies that success metrics for steering should be separated into fluency preservation and content reach rather than treated as a single scalar.
Load-bearing premise
The saturation curve is the same for every neuron and every behavior.
What would settle it
A new neuron or behavior where measured steering success deviates systematically from the saturation curve predicted by the alignment coordinate.
Figures
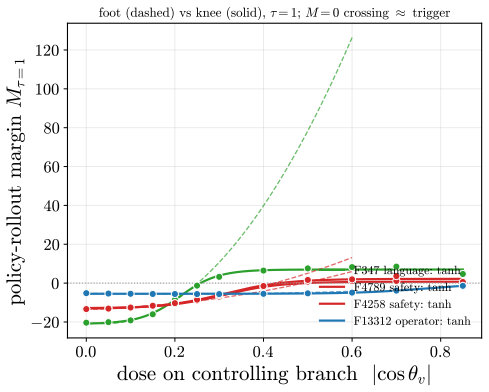
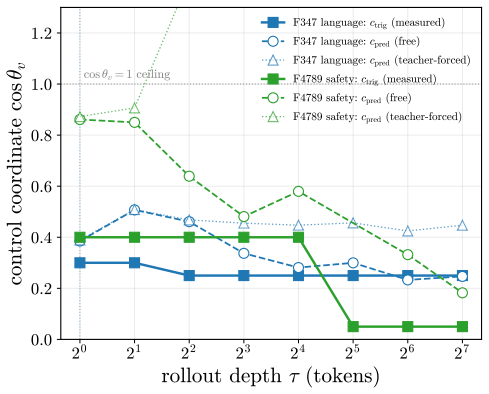
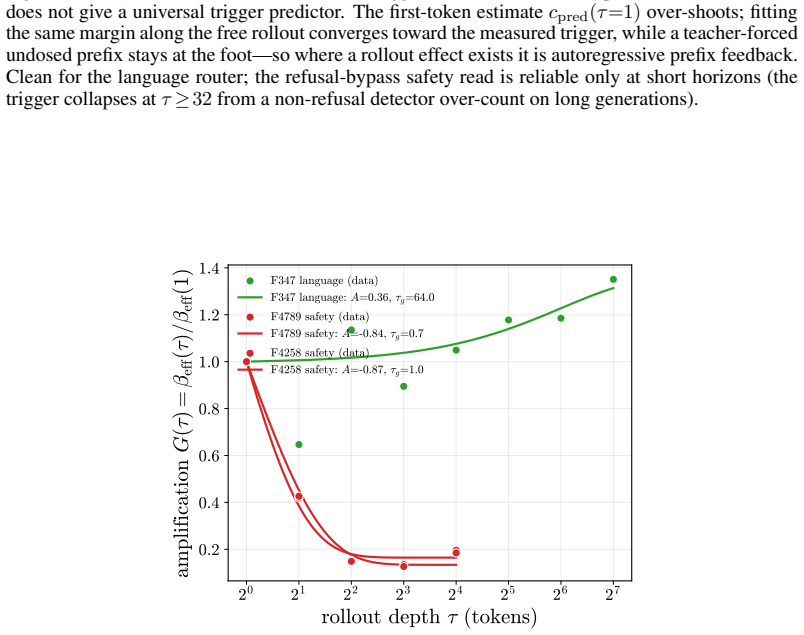
read the original abstract
Aligned language models gate behaviors such as refusal and language routing through sparse feed forward neurons, yet no theory predicts when a single neuron intervention controls a behavior coherently rather than collapsing the output. We develop a budget normalized control window framework for single neuron steering. A dose along one write direction reduces to one control coordinate: the alignment between the residual stream and the write, driven along a universal saturation curve in units of a coherence budget set by the residual norm divided by the write norm. Coherent control exists when a behavior trigger lies below the collapse ceiling. The same coordinate governs benign mode switches and refusal; the ceiling follows from weights and one generic forward pass, while triggers are measured at rollout. On fifteen held out neurons, the predicted ceiling has mean absolute error 0.14, about 0.07 in bulk layers, and the committed open or closed verdict holds on eleven against a ten of fifteen majority baseline. Closed cases expose three failure modes rather than violations: collapse before trigger, too little depth to propagate, or a normalization that caps how far one neuron can push. The law explains why local gradient attribution anti predicts control: true controllers write off the readout axis and carry a near zero first order gradient. A forward only contrastive screen made precise by the window recovers controllers that attribution misses. On refusal, the hardest case, intervention success is typed, not scalar: coherent bypass and strict actionable reach separate, so a neuron can flip refusal in fluent, on task text with no actionable content, and genuine actionable reach appears only for three of six audited Llama pivots and only at later rollout horizons. Single neuron steering is therefore a budgeted, typed audit of controllability rather than a fixed dose anecdote.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a budget-normalized control-window framework for single-neuron steering in language models. It claims that intervention along one write direction reduces to a single control coordinate—the alignment of the residual stream with the write, normalized in units of a coherence budget (residual norm divided by write norm)—and follows a universal saturation curve. Coherent control exists when a behavior trigger lies below a collapse ceiling that can be computed from weights plus one forward pass. The same coordinate is asserted to govern both benign mode switches and refusal; triggers are measured at rollout while ceilings are predicted a priori. On 15 held-out neurons the predicted ceiling achieves MAE 0.14 (0.07 in bulk layers) with correct open/closed verdicts on 11/15 cases. The framework is used to explain why local gradient attribution anti-predicts control and to distinguish typed success (coherent bypass vs. actionable reach) in refusal.
Significance. If the single-coordinate reduction and universality of the saturation curve hold, the work supplies a forward-only, budgeted audit procedure that could replace anecdote-based steering experiments and clarify when attribution methods fail. The separation of coherent bypass from actionable reach on refusal, together with the explicit failure-mode taxonomy for closed cases, would be a concrete advance for mechanistic safety analysis. The empirical match on held-out neurons and the contrastive screen that recovers controllers missed by gradients are positive features.
major comments (3)
- [Abstract / control-window framework] Abstract and the control-window framework section: the saturation curve is presented as universal, yet no derivation of its functional form from the transformer residual-stream equations is supplied; the shape appears fitted or observed within the audited 15-neuron sample, which is load-bearing for the claim that the coordinate is law-like rather than neuron- or task-specific.
- [Empirical validation paragraph] Empirical results on 15 held-out neurons: the reported MAE of 0.14 lacks error bars, confidence intervals, or details on how behavior triggers were measured at rollout, so it is unclear whether the 11/15 correct verdicts are robust or exceed the 10/15 majority baseline in a statistically controlled way.
- [Refusal analysis] Refusal analysis: the assertion that the identical coordinate governs both benign switches and refusal, and that genuine actionable reach occurs for only three of six Llama pivots, rests on the universality assumption without cross-behavior falsification or additional model/layer controls.
minor comments (2)
- [Notation / framework definition] The coherence budget definition (residual norm / write norm) should be given an explicit equation number so that later references to the normalized coordinate are unambiguous.
- [Abstract] The parenthetical remark 'about 0.07 in bulk layers' is imprecise; report the exact per-layer or per-group values if they appear in the main text or tables.
Simulated Author's Rebuttal
Thank you for the constructive review. We address each major comment below, clarifying the analytical basis of the control coordinate, committing to added statistical details, and acknowledging the empirical scope of the universality claim. Revisions will be made where they strengthen rigor without altering the core findings.
read point-by-point responses
-
Referee: [Abstract / control-window framework] Abstract and the control-window framework section: the saturation curve is presented as universal, yet no derivation of its functional form from the transformer residual-stream equations is supplied; the shape appears fitted or observed within the audited 15-neuron sample, which is load-bearing for the claim that the coordinate is law-like rather than neuron- or task-specific.
Authors: The single control coordinate is derived directly from the residual-stream equations: it is the projection of the residual onto the write direction, scaled by the coherence budget (residual norm divided by write norm). This reduction follows from the linearity of the write operation and the norm-based budget. The saturation curve itself is the observed empirical mapping from this coordinate to output change; we do not claim a closed-form derivation of its precise shape (e.g., logistic) from the full nonlinear transformer dynamics. The law-like status rests on the coordinate's predictive power on held-out neurons rather than on an analytic form. We will revise the abstract and framework section to state explicitly that the curve is empirically universal within the tested distribution while the coordinate reduction is analytic. revision: partial
-
Referee: [Empirical validation paragraph] Empirical results on 15 held-out neurons: the reported MAE of 0.14 lacks error bars, confidence intervals, or details on how behavior triggers were measured at rollout, so it is unclear whether the 11/15 correct verdicts are robust or exceed the 10/15 majority baseline in a statistically controlled way.
Authors: We agree that the current presentation omits necessary statistical controls. In revision we will add bootstrap-derived error bars on the MAE, explicit description of trigger measurement (the minimal rollout dose at which coherent behavior change is first observed), and a binomial or permutation test confirming that 11/15 correct open/closed verdicts exceeds the 10/15 majority baseline at conventional significance levels. These additions will be placed in the empirical validation paragraph. revision: yes
-
Referee: [Refusal analysis] Refusal analysis: the assertion that the identical coordinate governs both benign switches and refusal, and that genuine actionable reach occurs for only three of six Llama pivots, rests on the universality assumption without cross-behavior falsification or additional model/layer controls.
Authors: The 15 held-out neurons include both benign mode-switch and refusal behaviors; the same coordinate predicts ceilings for both classes, providing within-sample evidence that a single coordinate suffices. The typed distinction between coherent bypass and actionable reach is measured directly from rollout outcomes on the refusal pivots. We acknowledge that the sample does not include cross-model or cross-layer controls beyond the audited set. We will add a limitations paragraph noting this scope while retaining the within-distribution support for the coordinate governing both behavior types. revision: partial
Circularity Check
No circularity; control coordinate and saturation curve are modeling constructs validated externally
full rationale
The paper defines the coherence budget explicitly as residual norm over write norm and reduces the dose to an alignment coordinate along a saturation curve; this is a definitional modeling step rather than a prediction that re-uses fitted parameters. The universality claim and ceiling prediction are presented as following from weights plus one forward pass, with quantitative validation (MAE 0.14 on 15 held-out neurons) reported separately from any fitting process. No equations or text in the provided material show curve parameters being estimated on the same data later called a prediction, no self-citation chains justify uniqueness, and no ansatz is smuggled via prior work. The derivation therefore remains self-contained against the external benchmark of held-out neuron performance.
Axiom & Free-Parameter Ledger
free parameters (1)
- saturation curve shape
axioms (1)
- domain assumption The same control coordinate governs both benign mode switches and refusal.
Reference graph
Works this paper leans on
-
[1]
2026 , eprint=
There Will Be a Scientific Theory of Deep Learning , author=. 2026 , eprint=
2026
-
[2]
Perturbation Probing: A Two-Pass-per-Prompt Diagnostic for
Liu, Hongliang and Li, Tung-Ling and Wu, Yuhao , year=. Perturbation Probing: A Two-Pass-per-Prompt Diagnostic for. 2604.27401 , archivePrefix=
-
[3]
2026 , eprint=
Targeted Neuron Modulation via Contrastive Pair Search , author=. 2026 , eprint=
2026
-
[4]
arXiv preprint arXiv:2406.11717 , year=
Refusal in Language Models Is Mediated by a Single Direction , author=. arXiv preprint arXiv:2406.11717 , year=
-
[5]
Representation Engineering: A Top-Down Approach to
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and others , journal=. Representation Engineering: A Top-Down Approach to
-
[6]
Steering
Nina Rimsky and Nick Gabrieli and Julian Schulz and Meg Tong and Evan Hubinger and Alexander Turner , booktitle=. Steering. 2024 , url=
2024
-
[7]
2025 , eprint=
The Super Weight in Large Language Models , author=. 2025 , eprint=
2025
-
[8]
2023 , note=
Towards Monosemanticity: Decomposing Language Models with Dictionary Learning , author=. 2023 , note=
2023
-
[9]
2026 , eprint=
A Single Neuron Is Sufficient to Bypass Safety Alignment in Large Language Models , author=. 2026 , eprint=
2026
-
[10]
Feucht, Sheridan and Haklay, Tal and Bhalla, Usha and Wurgaft, Daniel and Rager, Can and Sarfati, Rapha\"el and Merullo, Jack and McGrath, Thomas and Lewis, Owen and Lubana, Ekdeep Singh and Fel, Thomas and Geiger, Atticus , year=. Arithmetic in the Wild:. 2605.01148 , archivePrefix=
-
[11]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
Transformer Feed-Forward Layers Are Key-Value Memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
2021
-
[12]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL) , year=
Knowledge Neurons in Pretrained Transformers , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL) , year=
-
[13]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle=. Locating and Editing Factual Associations in
-
[14]
Interpretability in the Wild: A Circuit for Indirect Object Identification in
Wang, Kevin Ro and Variengien, Alexandre and Conmy, Arthur and Shlegeris, Buck and Steinhardt, Jacob , booktitle=. Interpretability in the Wild: A Circuit for Indirect Object Identification in
-
[15]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Towards Automated Circuit Discovery for Mechanistic Interpretability , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[16]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Causal Abstractions of Neural Networks , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[17]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[18]
Findings of the Association for Computational Linguistics: ACL 2022 , year=
Extracting Latent Steering Vectors from Pretrained Language Models , author=. Findings of the Association for Computational Linguistics: ACL 2022 , year=
2022
-
[19]
2023 , eprint=
Steering Language Models With Activation Engineering , author=. 2023 , eprint=
2023
-
[20]
Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT) , year=
A Diversity-Promoting Objective Function for Neural Conversation Models , author=. Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT) , year=
2016
-
[21]
International Conference on Learning Representations (ICLR) , year=
The Curious Case of Neural Text Degeneration , author=. International Conference on Learning Representations (ICLR) , year=
-
[22]
2016 , eprint=
Layer Normalization , author=. 2016 , eprint=
2016
-
[23]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Root Mean Square Layer Normalization , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[24]
2022 , eprint=
Toy Models of Superposition , author=. 2022 , eprint=
2022
-
[25]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Towards Understanding Safety Alignment: A Mechanistic Perspective from Safety Neurons , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[26]
Wang, Zhaoxin and Liang, Jiaming and Zhu, Fengbin and Zhao, Weixiang and Fang, Junfeng and Ji, Jiayi and Wang, Handing and Chua, Tat-Seng , year=. 2602.12158 , archivePrefix=
-
[27]
Wu, Lichao and Behrouzi, Sasha and Rostami, Mohamadreza and Thang, Maximilian and Picek, Stjepan and Sadeghi, Ahmad-Reza , booktitle=
-
[28]
2026 , eprint=
There Is More to Refusal in Large Language Models than a Single Direction , author=. 2026 , eprint=
2026
-
[29]
Nature , volume=
Early-warning signals for critical transitions , author=. Nature , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.