VAGS: Velocity Adaptive Guidance Scale for Image Editing and Generation
Pith reviewed 2026-05-20 18:28 UTC · model grok-4.3
The pith
Dynamically scaling classifier-free guidance with velocity alignments raises structural fidelity in editing and generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
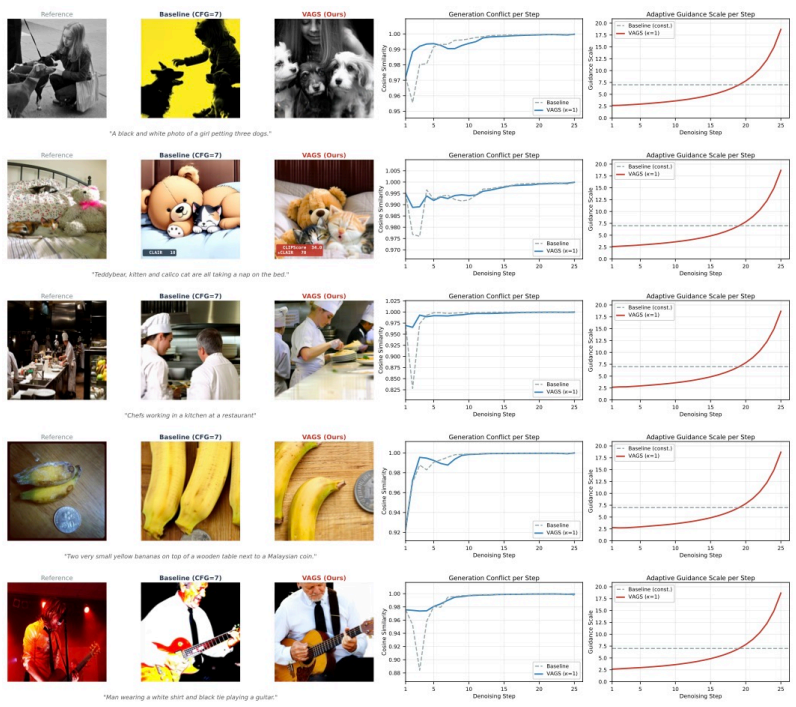
VAGS multiplies the nominal guidance scale by a bounded factor that combines a temporal signal-level term with the cosine similarity between task-relevant velocity fields. For inversion-free editing the factor uses alignment between source- and target-guided velocities so that edit strength reflects local compatibility between preservation and change. For generation the analogous factor uses alignment between unconditional and conditional velocities. The method needs no fine-tuning, auxiliary networks, or extra forward passes and reduces to ordinary fixed-scale CFG when the similarity term is ignored.
What carries the argument
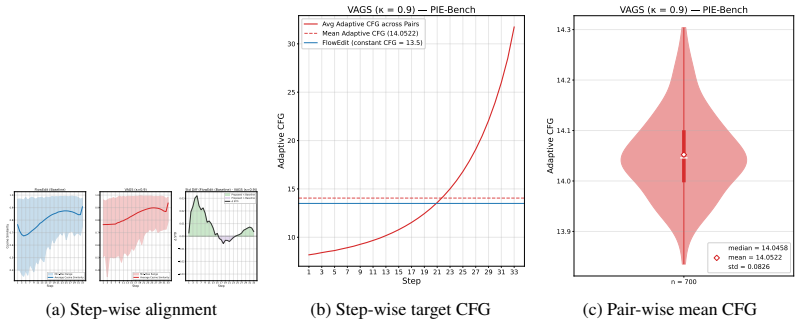
The Velocity-Adaptive Guidance Scale, a per-step multiplier on guidance strength computed from cosine similarity of the relevant velocity fields to decide when to strengthen or weaken the directional pull.
If this is right
- Editing tasks show higher structural fidelity on PIE-Bench and DIV2K than fixed CFG or prior training-free variants.
- Generation tasks achieve higher quality metrics on COCO17, CUB-200, and Flickr30K while preserving the same sampling budget.
- Both editing and generation variants remain training-free and recover standard CFG as the special case of constant similarity.
- No auxiliary networks or extra model evaluations are required at inference time.
Where Pith is reading between the lines
- The same velocity-similarity signal might be tested on video or 3D generation pipelines to check whether the adaptation generalizes beyond 2D images.
- High-guidance regimes that currently produce artifacts could be self-regulated by lowering the multiplier when alignment drops, reducing the need for manual scale tuning.
- The bounded multiplier might be combined with other adaptive schedulers to handle different noise schedules or model families without redesign.
Load-bearing premise
The cosine similarity between the relevant velocity fields supplies a clean, artifact-free signal for raising or lowering guidance strength at each step.
What would settle it
On PIE-Bench or DIV2K, if VAGS produces lower structural similarity scores or higher perceptual error than the strongest fixed-scale CFG baseline under identical sampling settings, the performance advantage would be refuted.
Figures










read the original abstract
Classifier-free guidance (CFG) is the primary control over how strongly text semantics move a flow-based sampler, yet standard practice holds its scale fixed across the entire ODE trajectory. This is a fundamental mismatch: early steps are noise-dominated and carry weak semantic signal, while late steps commit image structure and demand stronger directional commitment; more critically, the value of any guidance strength depends on whether the guided velocity is consistent with the model's current dynamics or working against them. We propose \textit{Velocity-Adaptive Guidance Scale} (VAGS), a training-free replacement that multiplies the nominal scale by a bounded factor combining a temporal signal-level term with the cosine similarity between task-relevant velocity fields. For inversion-free editing, VAGS measures the alignment between source- and target-guided velocities, so edit strength at each step reflects local compatibility between preservation and transformation. For generation, VAGS-Gen uses the alignment between unconditional and conditional velocities as the analogous signal. Neither variant requires fine-tuning, auxiliary networks, or extra forward passes, and fixed CFG is recovered as a special case. On PIE-Bench and DIV2K for editing, and COCO17, CUB-200, and Flickr30K for generation, VAGS consistently improves structural fidelity and generation quality over fixed CFG and recent training-free guidance variants. The code is publicly available at https://github.com/Harvard-AI-and-Robotics-Lab/Velocity_Adaptive_Guidance_Scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Velocity-Adaptive Guidance Scale (VAGS), a training-free technique that replaces fixed classifier-free guidance (CFG) with a dynamic scale for flow-based image editing and generation. The nominal CFG scale is multiplied at each ODE step by a bounded factor formed from a temporal signal-level term plus the cosine similarity between task-relevant velocity fields (source vs. target velocities for inversion-free editing; unconditional vs. conditional velocities for generation). Fixed CFG is recovered when the similarity term is constant. Experiments report consistent gains in structural fidelity and perceptual quality on PIE-Bench and DIV2K (editing) and on COCO17, CUB-200, and Flickr30K (generation) relative to fixed CFG and recent training-free baselines.
Significance. If the reported metric improvements hold under the velocity-alignment premise, the work supplies a lightweight, zero-extra-forward-pass refinement to a ubiquitous control mechanism in diffusion/flow models. The method is parameter-light (only the bounded-multiplier bounds), recovers the standard baseline by construction, and is accompanied by public code, which aids reproducibility. It directly targets the mismatch between a constant guidance strength and the varying semantic content of velocity fields across the trajectory.
major comments (1)
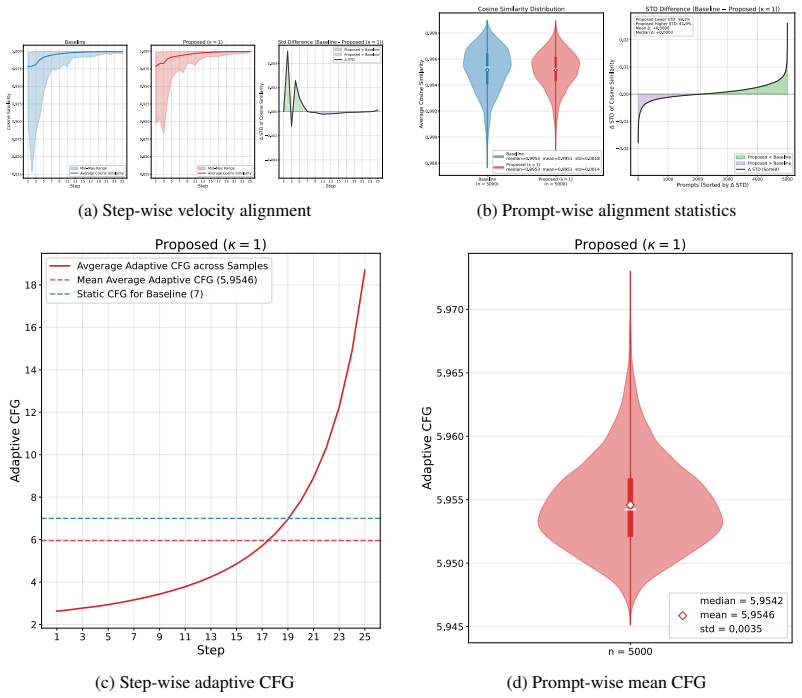
- [Method (definition of bounded multiplier and velocity-similarity term)] The central claim that VAGS improves fidelity without introducing new failure modes rests on the premise that cosine similarity between the relevant velocity pairs supplies a reliable, artifact-free local compatibility signal. This premise is invoked when the bounded multiplier is defined. In early ODE steps the velocities are noise-dominated; low or fluctuating cosine values could suppress guidance precisely when directional commitment is most needed or introduce trajectory jitter. The manuscript should supply either (a) an analysis showing that the resulting per-step scale schedule remains monotonic or bounded relative to fixed CFG or (b) an ablation that isolates early-step behavior and confirms absence of overshoot/undershoot.
minor comments (2)
- [Abstract] The abstract states that VAGS 'consistently improves' over 'recent training-free guidance variants' but does not name the specific baselines; listing them explicitly would improve readability.
- [Experiments / Results tables] Tables reporting metric gains should include standard deviations across runs or seeds to allow readers to judge the stability of the observed improvements.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation for minor revision. The comment on the bounded multiplier and early-step behavior of the velocity-similarity term is well-taken; we respond below and will strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Method (definition of bounded multiplier and velocity-similarity term)] The central claim that VAGS improves fidelity without introducing new failure modes rests on the premise that cosine similarity between the relevant velocity pairs supplies a reliable, artifact-free local compatibility signal. This premise is invoked when the bounded multiplier is defined. In early ODE steps the velocities are noise-dominated; low or fluctuating cosine values could suppress guidance precisely when directional commitment is most needed or introduce trajectory jitter. The manuscript should supply either (a) an analysis showing that the resulting per-step scale schedule remains monotonic or bounded relative to fixed CFG or (b) an ablation that isolates early-step behavior and confirms absence of overshoot/undershoot.
Authors: We agree that early ODE steps merit explicit verification because velocities are initially noise-dominated. The VAGS multiplier is deliberately bounded (clamped between fixed lower and upper limits) and combines the cosine-similarity term with an explicit temporal signal-level term that grows with denoising progress; this construction prevents the similarity signal from driving the effective scale below a minimum threshold or introducing large per-step jumps. Fixed CFG is recovered exactly when the similarity term is constant, so any deviation is controlled. To address the request directly, we will add (i) plots of per-step effective scale schedules across representative trajectories and (ii) an early-step ablation that freezes the multiplier after the first 20 % of steps and compares fidelity/jitter metrics against the full VAGS schedule. These additions will confirm that the schedule remains bounded relative to fixed CFG and does not produce overshoot or new artifacts. revision: yes
Circularity Check
No significant circularity detected in VAGS derivation
full rationale
The paper defines VAGS by constructing a bounded multiplier from a temporal signal term plus the cosine similarity of velocity fields (source/target for editing or unconditional/conditional for generation) and applies it to the nominal CFG scale. This functional form is computed directly from the diffusion model's intermediate velocity outputs at each ODE step and does not reduce by construction to any fitted parameter, renamed empirical pattern, or self-citation chain. Fixed CFG is recovered explicitly as the constant-similarity special case, but the variable adaptation itself is presented as an independent, training-free modification without auxiliary networks or extra passes. The central performance claims rest on empirical results across PIE-Bench, DIV2K, COCO17, CUB-200, and Flickr30K rather than definitional equivalence to the inputs. No load-bearing step in the described method equates to its own premises via self-definition or imported uniqueness theorems.
Axiom & Free-Parameter Ledger
free parameters (1)
- bounded multiplier bounds
axioms (1)
- domain assumption Cosine similarity between velocity fields is a meaningful local compatibility measure
Reference graph
Works this paper leans on
-
[1]
Denoising diffusion probabilistic models.NeurIPS, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.NeurIPS, 2020
work page 2020
-
[2]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InICLR, 2021
work page 2021
-
[3]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022
work page 2022
-
[4]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. InICLR, 2021
work page 2021
-
[5]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InICLR, 2023
work page 2023
-
[6]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InICLR, 2023
work page 2023
-
[7]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis.arXiv preprint arXiv:2403.03206, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
FLUX.1.https://blackforestlabs.ai, 2024
Black Forest Labs. FLUX.1.https://blackforestlabs.ai, 2024. Open-weight rectified-flow text-to-image model
work page 2024
-
[9]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Prompt-to-prompt image editing with cross attention control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control. InICLR, 2023
work page 2023
-
[11]
Plug-and-play diffusion features for text-driven image-to-image translation
Narek Tumanyan, Michal Geyer, Shai Bagon, and Tali Dekel. Plug-and-play diffusion features for text-driven image-to-image translation. InCVPR, 2023
work page 2023
-
[12]
Null-text inversion for editing real images using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models. InCVPR, 2023
work page 2023
-
[13]
EDICT: Exact diffusion inversion via coupled transformations
Bram Wallace, Akash Gokul, and Nikhil Naik. EDICT: Exact diffusion inversion via coupled transformations. InCVPR, 2023
work page 2023
-
[14]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros. InstructPix2Pix: Learning to follow image editing instructions. InCVPR, 2023
work page 2023
-
[15]
Semantic im- age inversion and editing using rectified stochastic differen- tial equations
Litu Rout, Yujia Chen, Nataniel Ruiz, Constantine Caramanis, Sanjay Shakkottai, and Wen-Sheng Chu. Semantic image inversion and editing using rectified stochastic differential equations.arXiv preprint arXiv:2410.10792, 2024
-
[16]
Tam- ing rectified flow for inversion and editing
Jiangshan Wang, Junfu Pu, Zhongang Qi, Jiayi Guo, Yue Ma, Nisha Huang, Yuxin Chen, Xiu Li, and Ying Shan. Taming rectified flow for inversion and editing.arXiv preprint arXiv:2411.04746, 2024
-
[17]
Fireflow: Fast inversion of rectified flow for image semantic editing,
Yingying Deng, Xiangyu He, Changwang Mei, Peisong Wang, and Fan Tang. FireFlow: Fast inversion of rectified flow for image semantic editing.arXiv preprint arXiv:2412.07517, 2024
-
[18]
Pengcheng Xu, Boyuan Jiang, Xiaobin Hu, Donghao Luo, Qingdong He, Jiangning Zhang, Chengjie Wang, Yunsheng Wu, Charles Ling, and Boyu Wang. Unveil inversion and invariance in flow transformer for versatile image editing.arXiv preprint arXiv:2411.15843, 2025
-
[19]
Inversion- free image editing with natural language.arXiv preprint arXiv:2312.04965,
Sihan Xu, Yidong Huang, Jiayi Pan, Ziqiao Ma, and Joyce Chai. Inversion-free image editing with natural language.arXiv preprint arXiv:2312.04965, 2023
-
[20]
Vladimir Kulikov, Matan Kleiner, Inbar Huberman-Spiegelglas, and Tomer Michaeli. FlowEdit: Inversion-free text-based editing using pre-trained flow models.arXiv preprint arXiv:2412.08629, 2024
-
[21]
Text-to-image rectified flow as plug-and-play priors.arXiv preprint arXiv:2406.03293, 2025
Xiaofeng Yang, Cheng Chen, Xulei Yang, Fayao Liu, and Guosheng Lin. Text-to-image rectified flow as plug-and-play priors.arXiv preprint arXiv:2406.03293, 2025
-
[22]
Sung-Hoon Yoon, Minghan Li, Gaspard Beaudouin, Congcong Wen, Muhammad Rafay Azhar, and Mengyu Wang. Splitflow: Flow decomposition for inversion-free text-to-image editing.arXiv preprint arXiv:2510.25970, 2025. 10
-
[23]
Huiwen Chang, Han Zhang, Jarred Barber, AJ Maschinot, Jose Lezama, Lu Jiang, Ming-Hsuan Yang, Kevin Murphy, William T Freeman, Michael Rubinstein, et al. Muse: Text-to-image generation via masked generative transformers.arXiv preprint arXiv:2301.00704, 2023
-
[24]
Analysis of classifier-free guidance weight schedulers
Xi Wang, Nicolas Dufour, Nefeli Andreou, Marie-Paule Cani, Victoria Fernández Abrevaya, David Picard, and Vicky Kalogeiton. Analysis of classifier-free guidance weight schedulers.arXiv preprint arXiv:2404.13040, 2024
-
[25]
Applying guidance in a limited interval improves sample and distribution quality in diffusion models
Tuomas Kynkäänniemi, Miika Aittala, Tero Karras, Samuli Laine, Timo Aila, and Jaakko Lehtinen. Applying guidance in a limited interval improves sample and distribution quality in diffusion models. arXiv preprint arXiv:2404.07724, 2024
-
[26]
Dynamic classifier-free diffusion guidance via online feedback.arXiv preprint arXiv:2509.16131, 2025
Pinelopi Papalampidi, Olivia Wiles, Ira Ktena, Aleksandar Shtedritski, Emanuele Bugliarello, Ivana Kaji´c, Isabela Albuquerque, and Aida Nematzadeh. Dynamic classifier-free diffusion guidance via online feedback.arXiv preprint arXiv:2509.16131, 2025
-
[27]
Learn to guide your diffusion model.arXiv preprint arXiv:2510.00815, 2025
Alexandre Galashov, Ashwini Pokle, Arnaud Doucet, Arthur Gretton, Mauricio Delbracio, and Valentin De Bortoli. Learn to guide your diffusion model.arXiv preprint arXiv:2510.00815, 2025
-
[28]
Weichen Fan, Amber Yijia Zheng, Raymond A Yeh, and Ziwei Liu. Cfg-zero*: Improved classifier-free guidance for flow matching models.arXiv preprint arXiv:2503.18886, 2025
-
[29]
Rectified-cfg++ for flow based models.arXiv preprint arXiv:2510.07631, 2025
Shreshth Saini, Shashank Gupta, and Alan C Bovik. Rectified-cfg++ for flow based models.arXiv preprint arXiv:2510.07631, 2025
-
[30]
Xuan Ju, Ailing Zeng, Yuxuan Bian, Shaoteng Liu, and Qiang Xu. Direct inversion: Boosting diffusion-based editing with 3 lines of code.arXiv preprint arXiv:2310.01506, 2023
-
[31]
Ntire 2017 challenge on single image super-resolution: Dataset and study
Eirikur Agustsson and Radu Timofte. Ntire 2017 challenge on single image super-resolution: Dataset and study. InCVPR, 2017
work page 2017
-
[32]
Lawrence Zitnick, and Piotr Dollár
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft COCO: Common objects in context. InECCV, 2014
work page 2014
-
[33]
P. Welinder, S. Branson, T. Mita, C. Wah, F. Schroff, S. Belongie, and P. Perona. Caltech-UCSD birds 200. Technical Report CNS-TR-2010-001, California Institute of Technology, 2010
work page 2010
-
[34]
Bryan A. Plummer, Liwei Wang, Chris M. Cervantes, Juan C. Caicedo, Julia Hockenmaier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. InICCV, 2015
work page 2015
-
[35]
Cheng Jin, Zhenyu Xiao, and Yuantao Gu. A-FloPS: Accelerating diffusion models via adaptive flow path sampler.arXiv preprint arXiv:2509.00036, 2025. Also appeared in AAAI 2026
-
[36]
Self-guidance: Boosting flow and diffusion generation on their own.IEEE TPAMI, 2025
Tiancheng Li, Weijian Luo, Zhiyang Chen, Liyuan Ma, and Guo-Jun Qi. Self-guidance: Boosting flow and diffusion generation on their own.IEEE TPAMI, 2025
work page 2025
-
[37]
Applying guidance in a limited interval improves sample and distribution quality in diffusion models
Tuomas Kynkäänniemi, Miika Aittala, Tero Karras, Samuli Laine, Timo Aila, and Jaakko Lehtinen. Applying guidance in a limited interval improves sample and distribution quality in diffusion models. NeurIPS, 2024
work page 2024
-
[38]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. InICML, 2023
work page 2023
-
[39]
Hansam Cho and Seoung Bum Kim. Improving diffusion-based image editing faithfulness via guidance and scheduling.arXiv preprint arXiv:2506.21045, 2025
-
[40]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, 2018
work page 2018
-
[41]
Godiva: Generating open-domain videos from natural descriptions
Chenfei Wu, Lun Huang, Qianxi Zhang, Binyang Li, Lei Ji, Fan Yang, Guillermo Sapiro, and Nan Duan. Godiva: Generating open-domain videos from natural descriptions.arXiv preprint arXiv:2104.14806, 2021
-
[42]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. InAdv. Neural Inform. Process. Syst., 2017
work page 2017
-
[43]
Improved techniques for training gans
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. InAdv. Neural Inform. Process. Syst., 2016. 11
work page 2016
-
[44]
CLIPScore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. CLIPScore: A reference-free evaluation metric for image captioning. InProc. Conf. Empir. Methods Nat. Lang. Process., 2021
work page 2021
-
[45]
BLEU: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. BLEU: a method for automatic evaluation of machine translation. InACL, 2002
work page 2002
-
[46]
METEOR: An automatic metric for MT evaluation with improved correlation with human judgments
Satanjeev Banerjee and Alon Lavie. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. InACL Workshop, 2005
work page 2005
-
[47]
ROUGE: A package for automatic evaluation of summaries
Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. InACL Workshop, 2004
work page 2004
-
[48]
Pytorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. InNeurIPS, 2019
work page 2019
-
[49]
Diffusers: State-of-the-art diffusion models
Patrick von Platen, Suraj Patil, Anton Lozhkov, Pedro Cuenca, Nathan Lambert, Kashif Rasul, Mishig Davaadorj, and Thomas Wolf. Diffusers: State-of-the-art diffusion models. https://github.com/huggingface/diffusers, 2022
work page 2022
-
[50]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023. 12 A Technical appendices and supplementary material This appendix collects implementation pseudocode, diagnostic evide...
work page 2023
-
[51]
Its sign reflects a qualitative shift in the sampler’s task across the trajectory
and positive in the clean regime (σi > 1 2), this signed factor passes through zero at σi = 1 2, where λi recovers the nominal scale exactly. Its sign reflects a qualitative shift in the sampler’s task across the trajectory. Early steps performbasin selection: from a near-isotropic latent the sampler must commit to a region of the data manifold, and the u...
-
[52]
is used to generate captions from the generated images, enabling evaluation with the caption- based metrics. V AGS-Gen yields consistent FID and IS gains, with the largest improvement on fine-grained generation. Generation κ ablation.The optimal κ on each dataset is unchanged under scaling ( κ=1.0 on COCO17 and CUB-200, κ=0.9 on Flickr30K), and the same c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.