HumanSplatHMR: Closing the Loop Between Human Mesh Recovery and Gaussian Splatting Avatar
Pith reviewed 2026-05-22 10:58 UTC · model grok-4.3
The pith
Backpropagating rendering losses refines 3D human poses and avatars from video
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
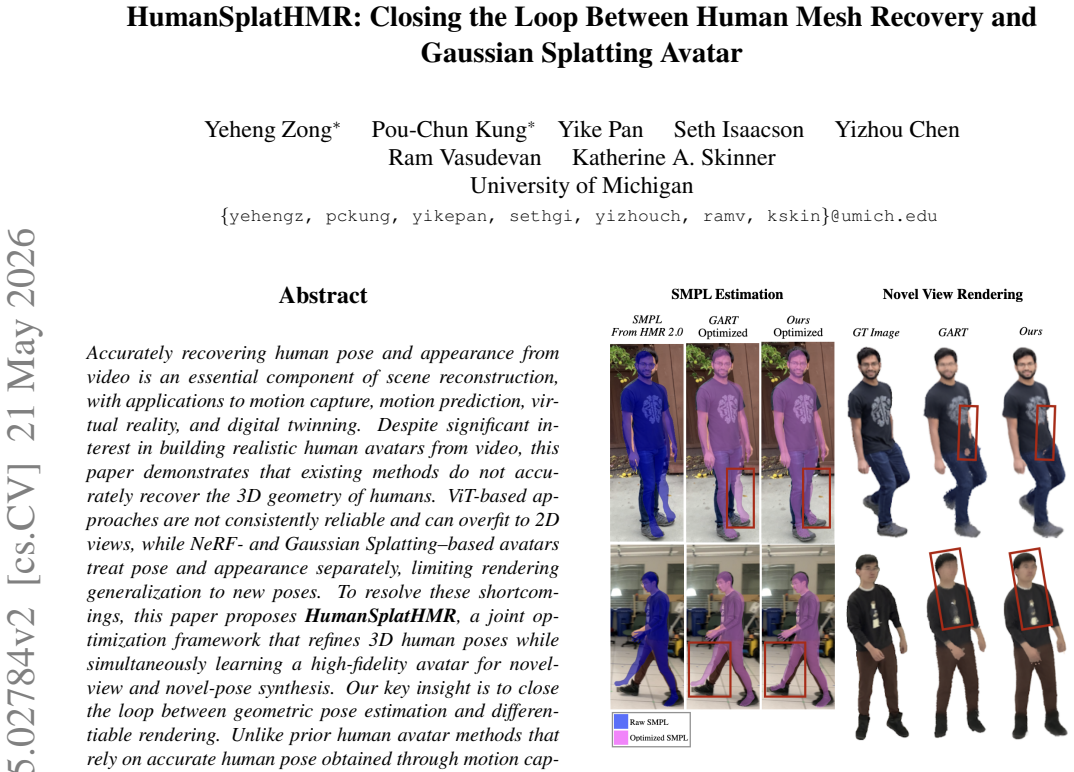
HumanSplatHMR is a joint optimization framework that refines 3D human poses while simultaneously learning a high-fidelity avatar for novel-view and novel-pose synthesis. It achieves this by closing the loop between geometric pose estimation and differentiable rendering, backpropagating photometric, segmentation, and depth losses through the renderer to the pose parameters and global position, using only initial human mesh estimates from a state-of-the-art estimator.
What carries the argument
The differentiable renderer that couples the human mesh recovery and Gaussian splatting avatar, allowing backpropagation of image-based losses to refine pose parameters and global position.
If this is right
- Refines the global 3D pose over time for better accuracy and alignment.
- Produces improved renderings from novel views compared to decoupled methods.
- Enables practical use in in-the-wild video scenarios without motion capture systems.
- Improves both pose recovery and avatar reconstruction consistency.
Where Pith is reading between the lines
- This coupling could be extended to other articulated objects or full scene reconstruction tasks.
- Further optimization might allow the method to run on longer video sequences or in real time.
- The reliance on initial pose estimates suggests testing robustness with noisier starting points from different estimators.
Load-bearing premise
Initial human mesh estimates from a state-of-the-art pose estimator are accurate enough to start joint optimization without the process diverging to poor solutions in real-world video.
What would settle it
Running the optimization on a dataset with ground truth poses and observing that the refined poses have higher error or that novel view synthesis quality does not improve would falsify the central claim.
Figures





read the original abstract
Accurately recovering human pose and appearance from video is an essential component of scene reconstruction, with applications to motion capture, motion prediction, virtual reality, and digital twinning. Despite significant interest in building realistic human avatars from video, this paper demonstrates that existing methods do not accurately recover the 3D geometry of humans. ViT-based approaches are not consistently reliable and can overfit to 2D views, while NeRF- and Gaussian Splatting-based avatars treat pose and appearance separately, limiting rendering generalization to new poses. To resolve these shortcomings, this paper proposes HumanSplatHMR, a joint optimization framework that refines 3D human poses while simultaneously learning a high-fidelity avatar for novel-view and novel-pose synthesis. Our key insight is to close the loop between geometric pose estimation and differentiable rendering. Unlike prior human avatar methods that rely on accurate human pose obtained through motion capture systems or offline refinement, which are impractical in in-the-wild scenarios, our approach uses only human mesh estimates from a state-of-the-art human pose estimator to better reflect real-world conditions. Therefore, instead of using the human pose only as a deformation prior, HumanSplatHMR backpropagates photometric, segmentation, and depth losses through a differentiable renderer to the pose parameters and global position. This coupling refines the global 3D pose over time, improving accuracy and alignment while producing better renderings from novel views. Experiments show consistent improvements over pose recovery baselines that omit image-level refinement and avatar baselines that decouple pose estimation from avatar reconstruction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HumanSplatHMR, a joint optimization framework that refines 3D human poses (starting from off-the-shelf HMR estimates) while simultaneously learning a Gaussian Splatting avatar. It backpropagates photometric, segmentation, and depth losses through a differentiable renderer to the SMPL pose parameters and global translation, claiming this closes the loop between geometry and appearance to yield both more accurate poses and better novel-view/novel-pose renderings than decoupled baselines.
Significance. If the joint optimization reliably improves pose accuracy rather than trading one error source for another, the work would provide a practical route to higher-fidelity in-the-wild human avatars without motion-capture data. The explicit use of differentiable rendering to couple pose and appearance is a clear methodological contribution that could influence subsequent avatar and HMR pipelines.
major comments (2)
- [§3.2] §3.2 (Joint Optimization): The claim that gradients from the still-learning Gaussian avatar provide reliable signals for pose refinement is load-bearing, yet the text does not analyze or bound the effect of early-training appearance mismatch on pose gradients; this leaves open whether the procedure converges to improved 3D geometry or simply overfits the input views.
- [§4.3] §4.3 and Table 2: While the paper reports lower MPJPE and better novel-view PSNR relative to pose-only and avatar-only baselines, the absence of per-sequence error bars, statistical significance, and an ablation that freezes the avatar while optimizing only pose makes it impossible to isolate whether the observed pose gains are due to the closed loop or to other implementation details.
minor comments (2)
- [§2.1] §2.1: The related-work discussion of Gaussian Splatting avatars omits several recent works that also use differentiable rendering for human reconstruction; adding them would strengthen the positioning.
- [Figure 4] Figure 4: The qualitative novel-pose renderings would be more convincing if the input views and the initial (unrefined) HMR mesh were shown side-by-side for the same frames.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript. We address each major comment below and describe the revisions we will make to strengthen the presentation of our joint optimization approach and experimental validation.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Joint Optimization): The claim that gradients from the still-learning Gaussian avatar provide reliable signals for pose refinement is load-bearing, yet the text does not analyze or bound the effect of early-training appearance mismatch on pose gradients; this leaves open whether the procedure converges to improved 3D geometry or simply overfits the input views.
Authors: We acknowledge that the current text does not provide a formal analysis or bound on the influence of early-training appearance mismatch on the pose gradients. At the same time, the empirical results show that the joint procedure yields both lower MPJPE on held-out poses and higher novel-pose PSNR than the decoupled baselines; such gains in generalization would be unlikely if the optimization were merely fitting the input views. The combination of photometric, segmentation, and depth losses supplies multiple supervisory signals that remain informative even while the avatar is still converging. In the revised manuscript we will expand §3.2 with a short discussion of training dynamics, including a plot of pose error versus optimization step that illustrates progressive refinement rather than divergence or stagnation. revision: yes
-
Referee: [§4.3] §4.3 and Table 2: While the paper reports lower MPJPE and better novel-view PSNR relative to pose-only and avatar-only baselines, the absence of per-sequence error bars, statistical significance, and an ablation that freezes the avatar while optimizing only pose makes it impossible to isolate whether the observed pose gains are due to the closed loop or to other implementation details.
Authors: We agree that these additional controls would make the contribution of the closed-loop coupling clearer. We will augment Table 2 with per-sequence MPJPE values together with standard deviations, report the results of paired statistical significance tests across sequences, and add a new ablation in which the Gaussian avatar is trained to convergence and then frozen while only the SMPL pose and translation parameters continue to be optimized under the same losses. These changes will be presented in the revised §4.3. revision: yes
Circularity Check
No significant circularity; derivation is self-contained optimization
full rationale
The paper describes a joint optimization that backpropagates photometric, segmentation, and depth losses through a differentiable renderer to refine pose and global position parameters, starting from external off-the-shelf human mesh estimates. This is a standard differentiable-rendering procedure whose outcome is not forced by definition, by renaming a fitted quantity as a prediction, or by a load-bearing self-citation chain. No equations or claims reduce the reported improvement to an input by construction; the central claim remains an empirical statement about the effect of the optimization loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A differentiable renderer exists that can propagate photometric, segmentation, and depth losses back to 3D pose parameters
Reference graph
Works this paper leans on
-
[1]
Keep it smpl: Automatic estimation of 3d human pose and shape from a single image
Federica Bogo, Angjoo Kanazawa, Christoph Lassner, Peter Gehler, Javier Romero, and Michael J Black. Keep it smpl: Automatic estimation of 3d human pose and shape from a single image. InEuropean conference on computer vision, pages 561–578. Springer, 2016. 2, 4, 6
work page 2016
-
[2]
Meva: A large-scale multiview, multimodal video dataset for activity detection
Kellie Corona, Katie Osterdahl, Roderic Collins, and An- thony Hoogs. Meva: A large-scale multiview, multimodal video dataset for activity detection. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1060–1068, 2021. 2
work page 2021
-
[3]
Tokenhmr: Advancing human mesh re- covery with a tokenized pose representation
Sai Kumar Dwivedi, Yu Sun, Priyanka Patel, Yao Feng, and Michael J Black. Tokenhmr: Advancing human mesh re- covery with a tokenized pose representation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1323–1333, 2024. 2
work page 2024
-
[4]
Humans in 4d: Re- constructing and tracking humans with transformers
Shubham Goel, Georgios Pavlakos, Jathushan Rajasegaran, Angjoo Kanazawa, and Jitendra Malik. Humans in 4d: Re- constructing and tracking humans with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14783–14794, 2023. 1, 2, 4, 6, 8
work page 2023
-
[5]
Antoine Gu ´edon and Vincent Lepetit. Sugar: Surface- aligned gaussian splatting for efficient 3d mesh reconstruc- tion and high-quality mesh rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5354–5363, 2024. 4
work page 2024
-
[6]
Gauhuman: Articu- lated gaussian splatting from monocular human videos
Shoukang Hu, Tao Hu, and Ziwei Liu. Gauhuman: Articu- lated gaussian splatting from monocular human videos. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 20418–20431, 2024. 2, 3, 4, 7
work page 2024
-
[7]
2d gaussian splatting for geometrically ac- curate radiance fields
Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2d gaussian splatting for geometrically ac- curate radiance fields. InACM SIGGRAPH 2024 conference papers, pages 1–11, 2024. 4
work page 2024
-
[8]
Robust estimation of a location parameter
Peter J Huber. Robust estimation of a location parameter. In Breakthroughs in statistics: Methodology and distribution, pages 492–518. Springer, 1992. 5
work page 1992
-
[9]
Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. Human3. 6m: Large scale datasets and pre- dictive methods for 3d human sensing in natural environ- ments.IEEE transactions on pattern analysis and machine intelligence, 36(7):1325–1339, 2013. 6
work page 2013
-
[10]
Fast automatic skinning transformations
Alec Jacobson, Ilya Baran, Ladislav Kavan, Jovan Popovi ´c, and Olga Sorkine. Fast automatic skinning transformations. ACM Transactions on Graphics (ToG), 31(4):1–10, 2012. 2
work page 2012
-
[11]
In- stantavatar: Learning avatars from monocular video in 60 seconds
Tianjian Jiang, Xu Chen, Jie Song, and Otmar Hilliges. In- stantavatar: Learning avatars from monocular video in 60 seconds. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16922– 16932, 2023. 2, 6
work page 2023
-
[12]
Neuman: Neural human radiance field from a single video
Wei Jiang, Kwang Moo Yi, Golnoosh Samei, Oncel Tuzel, and Anurag Ranjan. Neuman: Neural human radiance field from a single video. InEuropean Conference on Computer Vision, pages 402–418. Springer, 2022. 6
work page 2022
-
[13]
End-to-end recovery of human shape and pose
Angjoo Kanazawa, Michael J Black, David W Jacobs, and Jitendra Malik. End-to-end recovery of human shape and pose. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7122–7131, 2018. 2, 6
work page 2018
-
[14]
Learning 3d human dynamics from video
Angjoo Kanazawa, Jason Y Zhang, Panna Felsen, and Jiten- dra Malik. Learning 3d human dynamics from video. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 5614–5623, 2019. 2
work page 2019
-
[15]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1,
-
[16]
Autosplat: Constrained gaussian splatting for autonomous driving scene reconstruction
Mustafa Khan, Hamidreza Fazlali, Dhruv Sharma, Tongtong Cao, Dongfeng Bai, Yuan Ren, and Bingbing Liu. Autosplat: Constrained gaussian splatting for autonomous driving scene reconstruction. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8315–8321. IEEE,
-
[17]
Vibe: Video inference for human body pose and shape estimation
Muhammed Kocabas, Nikos Athanasiou, and Michael J Black. Vibe: Video inference for human body pose and shape estimation. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 5253–5263, 2020. 2
work page 2020
-
[18]
Muhammed Kocabas, Jen-Hao Rick Chang, James Gabriel, Oncel Tuzel, and Anurag Ranjan. Hugs: Human gaussian splats. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 505–515, 2024. 2, 3, 4, 7
work page 2024
-
[19]
Learning to reconstruct 3d human pose and shape via model-fitting in the loop
Nikos Kolotouros, Georgios Pavlakos, Michael J Black, and Kostas Daniilidis. Learning to reconstruct 3d human pose and shape via model-fitting in the loop. InProceedings of the IEEE/CVF international conference on computer vision, pages 2252–2261, 2019. 2
work page 2019
-
[20]
Sad-gs: Shape-aligned depth- supervised gaussian splatting
Pou-Chun Kung, Seth Isaacson, Ram Vasudevan, and Katherine A Skinner. Sad-gs: Shape-aligned depth- supervised gaussian splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2842–2851, 2024. 4
work page 2024
-
[21]
Gart: Gaussian articulated template mod- els
Jiahui Lei, Yufu Wang, Georgios Pavlakos, Lingjie Liu, and Kostas Daniilidis. Gart: Gaussian articulated template mod- els. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 19876–19887,
-
[22]
Splatface: Gaus- sian splat face reconstruction leveraging an optimizable sur- face
Jiahao Luo, Jing Liu, and James Davis. Splatface: Gaus- sian splat face reconstruction leveraging an optimizable sur- face. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 774–783. IEEE, 2025. 4
work page 2025
-
[23]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021. 2
work page 2021
-
[24]
ihuman: Instant animatable digital humans from monocular videos
Pramish Paudel, Anubhav Khanal, Danda Pani Paudel, Jyoti Tandukar, and Ajad Chhatkuli. ihuman: Instant animatable digital humans from monocular videos. InEuropean Con- ference on Computer Vision, pages 304–323. Springer, 2024. 2, 3, 7
work page 2024
-
[25]
Sida Peng, Yuanqing Zhang, Yinghao Xu, Qianqian Wang, Qing Shuai, Hujun Bao, and Xiaowei Zhou. Neural body: 9 Implicit neural representations with structured latent codes for novel view synthesis of dynamic humans. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9054–9063, 2021. 2
work page 2021
-
[26]
UniDepthV2: Universal Monocular Metric Depth Estimation Made Simpler
Luigi Piccinelli, Christos Sakaridis, Yung-Hsu Yang, Mat- tia Segu, Siyuan Li, Wim Abbeloos, and Luc Van Gool. Unidepthv2: Universal monocular metric depth estimation made simpler.arXiv preprint arXiv:2502.20110, 2025. 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Splattingavatar: Realistic real-time human avatars with mesh-embedded gaussian splatting
Zhijing Shao, Zhaolong Wang, Zhuang Li, Duotun Wang, Xiangru Lin, Yu Zhang, Mingming Fan, and Zeyu Wang. Splattingavatar: Realistic real-time human avatars with mesh-embedded gaussian splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1606–1616, 2024. 2, 3, 4, 7
work page 2024
-
[29]
Recovering ac- curate 3d human pose in the wild using imus and a moving camera
Timo V on Marcard, Roberto Henschel, Michael J Black, Bodo Rosenhahn, and Gerard Pons-Moll. Recovering ac- curate 3d human pose in the wild using imus and a moving camera. InProceedings of the European conference on com- puter vision (ECCV), pages 601–617, 2018. 6
work page 2018
-
[30]
Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4): 600–612, 2004. 5
work page 2004
-
[31]
Gomavatar: Efficient an- imatable human modeling from monocular video using gaussians-on-mesh
Jing Wen, Xiaoming Zhao, Zhongzheng Ren, Alexander G Schwing, and Shenlong Wang. Gomavatar: Efficient an- imatable human modeling from monocular video using gaussians-on-mesh. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 2059–2069, 2024. 2, 3, 4, 7
work page 2059
-
[32]
Hu- mannerf: Free-viewpoint rendering of moving people from monocular video
Chung-Yi Weng, Brian Curless, Pratul P Srinivasan, Jonathan T Barron, and Ira Kemelmacher-Shlizerman. Hu- mannerf: Free-viewpoint rendering of moving people from monocular video. InProceedings of the IEEE/CVF con- ference on computer vision and pattern Recognition, pages 16210–16220, 2022. 2
work page 2022
-
[33]
Reconstructing humans with a biome- chanically accurate skeleton
Yan Xia, Xiaowei Zhou, Etienne V ouga, Qixing Huang, and Georgios Pavlakos. Reconstructing humans with a biome- chanically accurate skeleton. InProceedings of the Com- puter Vision and Pattern Recognition Conference, pages 5355–5365, 2025. 2
work page 2025
-
[34]
Menglei Yang, Yuhang Han, Shenhao Zhang, and Xiaohui Zhang. Animatable nerf dynamic detail enhancement based on residual deformation field with progressive training. In 2025 5th International Conference on Computer Graphics, Image and Virtualization (ICCGIV), pages 161–165. IEEE,
work page 2025
-
[35]
Yuchen Yang, Linfeng Dong, Wei Wang, Zhihang Zhong, and Xiao Sun. Learnable smplify: A neural solution for optimization-free human pose inverse kinematics.arXiv preprint arXiv:2508.13562, 2025. 2
-
[36]
Decoupling human and camera motion from videos in the wild
Vickie Ye, Georgios Pavlakos, Jitendra Malik, and Angjoo Kanazawa. Decoupling human and camera motion from videos in the wild. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 21222–21232, 2023. 2
work page 2023
-
[37]
Ning Zhang and Belei Pu. Film and television animation pro- duction technology based on expression transfer and virtual digital human.Scalable Computing: Practice and Experi- ence, 25(6):5560–5567, 2024. 2 10
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.