Network-Aware Bilinear Tokenization for Brain Functional Connectivity Representation Learning
Pith reviewed 2026-05-20 20:42 UTC · model grok-4.3
The pith
Partitioning functional connectivity matrices into network-pair patches and embedding them bilinearly produces more stable, cross-cohort transferable representations than uniform or graph-based alternatives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
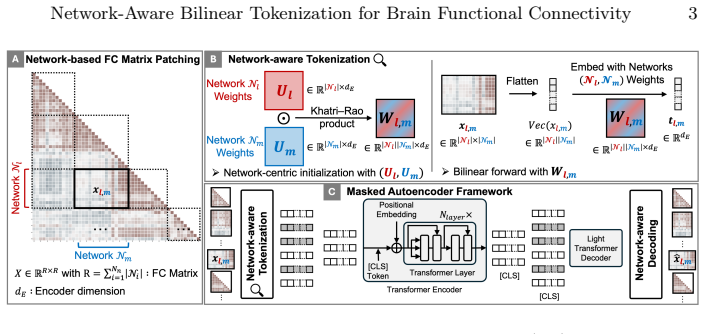
By redefining FC tokenization as patches of intra- and inter-network connectivity blocks drawn from anatomically grounded network pairs and embedding those heterogeneous patches with a structured bilinear factorization that preserves network identity, NERVE produces self-supervised representations that are more stable and transferable across cohorts than those obtained from structurally agnostic MAE variants or graph-based baselines.
What carries the argument
Structured bilinear factorization that embeds variable-sized network-pair FC patches while preserving each network's distinct functional role and achieving linear parameter scaling with the number of networks.
If this is right
- Representations trained with network-aware bilinear tokenization generalize more reliably to unseen cohorts for predicting individual differences in behavior and psychopathology.
- The bilinear formulation reduces parameter count from quadratic to linear in the number of networks while retaining network-specific identity.
- Ablations establish that both the anatomically grounded parcellation and the bilinear embedding are required for the reported stability and transfer gains.
- Incorporating domain-specific structural priors into self-supervised pipelines for functional connectomics yields measurable improvements over treating connectivity matrices as homogeneous or purely graph-structured data.
Where Pith is reading between the lines
- Similar network-boundary priors could be tested on dynamic or task-based connectivity to see whether the same modular alignment improves representation quality in those settings.
- The linear scaling property would allow the method to be applied to finer-grained atlases containing more networks without a prohibitive increase in model size.
- If the gains stem from explicit preservation of network identity, the approach might also serve as a way to inject known network-level priors into supervised or contrastive learning frameworks for neuroimaging.
Load-bearing premise
That anatomically defined network pairs create patches that match the brain's intrinsic modular organization and that this match is required to learn representations that transfer across cohorts.
What would settle it
If, in head-to-head cross-cohort tests, the network-aware bilinear model shows no improvement or worse performance than a standard fixed-size patch MAE on the same behavior and psychopathology prediction tasks, the central claim would be falsified.
Figures

read the original abstract
Masked autoencoders (MAEs) have recently shown promise for self-supervised representation learning of resting-state brain functional connectivity (FC). However, a fundamental question remains unresolved: how should FC matrices be tokenized to align with the intrinsic modular organization of large-scale brain networks? Existing approaches typically adopt region-centric or graph-based schemes that treat FC as structurally homogeneous elements and overlook the large-scale network brain organization. We introduce NERVE (Network-Aware Representations of Brain Functional Connectivity via Bilinear Tokenization), a self-supervised learning framework that redefines FC tokenization by partitioning FC matrices into patches of intra- and inter-network connectivity blocks. Unlike image-based MAE, where fixed-size patches share a common tokenizer, FC patches defined by network pairs are heterogeneous in size and correspond to distinct functional roles. To resolve this problem, NERVE embeds FC patches through a novel structured bilinear factorization. This formulation preserves network identity and reduces parameter complexity from quadratic to linear scaling in the number of networks. We evaluate NERVE across three large-scale developmental cohorts (ABCD, PNC, and CCNP) for behavior and psychopathology prediction. Compared to structurally agnostic MAE variants and graph-based self-supervised baselines, the proposed network-aware formulation yields more stable and transferable representations, particularly in cross-cohort evaluation. Ablation studies confirm that the proposed bilinear network embedding and anatomically grounded parcellation are critical for performance. These findings highlight the importance of incorporating domain-specific structural priors into self-supervised learning for functional connectomics. Code is available at: https://github.com/leomlck/NERVE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces NERVE, a masked autoencoder framework for self-supervised representation learning on resting-state functional connectivity (FC) matrices. It partitions FC into intra- and inter-network patches using an anatomically grounded parcellation and embeds these heterogeneous patches via a structured bilinear factorization that preserves network identity while scaling linearly with the number of networks. Evaluations across ABCD, PNC, and CCNP cohorts for behavior and psychopathology prediction tasks claim superior stability and cross-cohort transferability relative to structurally agnostic MAE variants and graph-based self-supervised baselines, with ablations attributing gains to the bilinear embedding and anatomical parcellation.
Significance. If the central claims hold, the work would advance self-supervised learning for functional connectomics by demonstrating how domain-specific priors on large-scale brain network organization can be incorporated into tokenization schemes. The bilinear formulation addresses a practical scaling issue for heterogeneous FC patches, and the multi-cohort cross-evaluation design provides a meaningful test of transferability. Code availability supports reproducibility.
major comments (2)
- [Ablation studies] Ablation studies: The results show that anatomically grounded parcellation improves performance over alternatives, but the experiments do not include a control using random or non-anatomical structured partitioning of comparable heterogeneity. This leaves open whether gains derive from alignment with intrinsic functional modularity or simply from introducing any bilinear low-rank structure into the MAE training.
- [Cross-cohort evaluation] Cross-cohort evaluation and embedding analysis: The central claim that network-aware tokenization yields more transferable representations would be strengthened by direct verification that learned embeddings respect modular boundaries (e.g., quantitative intra- versus inter-network similarity metrics on the resulting tokens). Without this, the motivation for the anatomical prior remains partially unverified even if performance improves.
minor comments (2)
- [Abstract] The abstract would benefit from reporting at least one key quantitative metric (e.g., improvement in R² or AUC with confidence interval) rather than purely qualitative statements about stability and transferability.
- [Methods] Notation in the bilinear factorization section could be expanded with an explicit equation showing how network-pair identity is preserved across heterogeneous patch sizes.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and have revised the manuscript to incorporate additional experiments and analyses that directly respond to the concerns raised.
read point-by-point responses
-
Referee: Ablation studies: The results show that anatomically grounded parcellation improves performance over alternatives, but the experiments do not include a control using random or non-anatomical structured partitioning of comparable heterogeneity. This leaves open whether gains derive from alignment with intrinsic functional modularity or simply from introducing any bilinear low-rank structure into the MAE training.
Authors: We agree that a random partitioning control is needed to isolate the contribution of anatomical alignment from the bilinear structure itself. In the revised manuscript we have added this ablation: FC matrices were randomly partitioned into patches of comparable size heterogeneity and the model was retrained under identical conditions. Results show that the bilinear factorization alone yields moderate gains, but the anatomically grounded parcellation produces statistically significant further improvements in cross-cohort transfer performance. These new results are reported in the updated ablation section with appropriate statistical tests. revision: yes
-
Referee: Cross-cohort evaluation and embedding analysis: The central claim that network-aware tokenization yields more transferable representations would be strengthened by direct verification that learned embeddings respect modular boundaries (e.g., quantitative intra- versus inter-network similarity metrics on the resulting tokens). Without this, the motivation for the anatomical prior remains partially unverified even if performance improves.
Authors: We thank the referee for this suggestion. In the revised manuscript we now include a quantitative embedding analysis that computes average cosine similarity among tokens belonging to the same network versus tokens from different networks. The analysis demonstrates that NERVE embeddings exhibit markedly higher intra-network similarity than inter-network similarity and than the corresponding metrics from the structurally agnostic baselines. This verification is presented in a new subsection on embedding properties and supports the role of the anatomical prior in producing modular representations. revision: yes
Circularity Check
No significant circularity; method is a design choice evaluated empirically
full rationale
The paper proposes NERVE as a new tokenization scheme using anatomically defined network-pair patches and a structured bilinear factorization to handle heterogeneous patch sizes while preserving network identity. This is presented as an architectural prior motivated by domain knowledge of brain networks, not as a derived prediction or first-principles result. Claims of improved stability and transferability rest on direct empirical comparisons against baselines and ablations across held-out cohorts (ABCD, PNC, CCNP), without any reduction of outputs to fitted parameters from the same data or load-bearing self-citations. The bilinear formulation is introduced to address a practical scaling issue and is validated by performance, not by construction equivalence to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large-scale brain networks exhibit distinct functional roles that should be preserved when tokenizing functional connectivity matrices.
invented entities (1)
-
Structured bilinear factorization for network-pair FC patches
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
we propose a bilinear network-aware tokenization... W_{l,m}=U_l ⊙ U_m ... replaces quadratic growth ... with linear scaling in the number of networks
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
anatomically grounded parcellation ... 17-network ... ablation studies confirm ... critical for performance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Psychological Bulletin85(6), 1275–1301 (1978)
Achenbach, T.M., Edelbrock, C.S.: The classification of child psychopathology: A review and analysis of empirical efforts. Psychological Bulletin85(6), 1275–1301 (1978)
work page 1978
-
[2]
Button, K.S., Ioannidis, J.P., Mokrysz, C., Nosek, B.A., Flint, J., Robinson, E.S., et al.: Power failure: why small sample size undermines the reliability of neuroscience. Nat. Rev. Neurosci.14(5), 365–376 (2013)
work page 2013
- [3]
-
[4]
Dong, Z., Li, R., Wu, Y., Nguyen, T., Su, J., Chong, et al.: Brain-JEPA: Brain Dy- namics Foundation Model with Gradient Positioning and Spatiotemporal Masking. In: NeurIPS. vol. 37, pp. 86048–86073. Curran Associates, Inc. (2024)
work page 2024
-
[5]
Frontiers in Neuroscience13(2019)
Farahani, F.V., Karwowski, W., Lighthall, N.R.: Application of graph theory for identifying connectivity patterns in human brain networks: A systematic review. Frontiers in Neuroscience13(2019)
work page 2019
-
[6]
Medical Image Analysis107(Pt B), 103861 (2026)
Gao, J., Ge, B., Qiang, N., Zhao, S.: 3D masked autoencoder with spatiotemporal transformer for modeling of 4D fMRI data. Medical Image Analysis107(Pt B), 103861 (2026)
work page 2026
-
[7]
Devel- opmental Cognitive Neuroscience32, 16–22 (2018)
Garavan, H., Bartsch, H., Conway, K., Decastro, A., Goldstein, R.Z., Heeringa, S., et al.: Recruiting the ABCD sample: design considerations and procedures. Devel- opmental Cognitive Neuroscience32, 16–22 (2018)
work page 2018
- [8]
-
[9]
He, T., Kong, R., Holmes, A.J., Nguyen, M., Sabuncu, M.R., et al.: Deep neural networks and kernel regression achieve comparable accuracies for functional connec- tivity prediction of behavior and demographics. NeuroImage206(2020)
work page 2020
- [10]
-
[11]
Assessment31(2), 502–517 (2024)
Hoffmann, M.S., Moore, T.M., Axelrud, L.K., Tottenham, N., Pan, P.M., Miguel, et al.: An Evaluation of Item Harmonization Strategies Between Assessment Tools of Psychopathology in Children and Adolescents. Assessment31(2), 502–517 (2024)
work page 2024
-
[12]
Hou, Z., Liu, X., Cen, Y., Dong, Y., Yang, H., Wang, C., et al.: GraphMAE: Self- Supervised Masked Graph Autoencoders. In: SIGKDD. pp. 594–604. Association for Computing Machinery (2022)
work page 2022
-
[13]
NeuroImage80, 360–378 (2013) 10 L
Hutchison, R.M., Womelsdorf, T., Allen, E.A., Bandettini, P.A., Calhoun, V.D., Corbetta, et al.: Dynamic functional connectivity: Promise, issues, and interpreta- tions. NeuroImage80, 360–378 (2013) 10 L. Milecki et al
work page 2013
-
[14]
Kan, X., Dai, W., Cui, H., Zhang, Z., Guo, Y., Yang, C.: Brain Network Trans- former. In: NeurIPS. vol. 35. Curran Associates, Inc. (2022)
work page 2022
-
[15]
NeuroImage146, 1038–1049 (2017)
Kawahara, J., Brown, C.J., Miller, S.P., Booth, B.G., Chau, V., Grunau, R.E., et al.: BrainNetCNN: Convolutional neural networks for brain networks; towards predicting neurodevelopment. NeuroImage146, 1038–1049 (2017)
work page 2017
-
[16]
The Indian Journal of Statistics30(2), 167–180 (1968)
Khatri, C.G., Radhakrishna Rao, C.: Solutions to Some Functional Equations and Their Applications to Characterization of Probability Distributions. The Indian Journal of Statistics30(2), 167–180 (1968)
work page 1968
-
[17]
Medical Image Analysis 74, 102233 (2021)
Li, X., Zhou, Y., Dvornek, N., Zhang, M., Gao, S., Zhuang, et al.: BrainGNN: In- terpretable Brain Graph Neural Network for fMRI Analysis. Medical Image Analysis 74, 102233 (2021)
work page 2021
-
[18]
NeuroImage262(3), 119531 (2022)
Litwińczuk, M.C., Muhlert, N., Cloutman, L., Trujillo-Barreto, N., Woollams, A.: Combination of structural and functional connectivity explains unique variation in specific domains of cognitive function. NeuroImage262(3), 119531 (2022)
work page 2022
-
[19]
Developmental Cognitive Neuroscience52, 101020 (2021)
Liu, S., Wang, Y.S., Zhang, Q., Zhou, Q., Cao, L.Z., Jiang, C., et al.: Chinese Color Nest Project : An accelerated longitudinal brain-mind cohort. Developmental Cognitive Neuroscience52, 101020 (2021)
work page 2021
-
[20]
IEEE transac- tions on neural networks and learning systems36(6), 10707–10720 (2025)
Ma, H., Xu, Y., Tian, L.: RS-MAE: Region-State Masked Autoencoder for Neu- ropsychiatric Disorder Classifications Based on Resting-State fMRI. IEEE transac- tions on neural networks and learning systems36(6), 10707–10720 (2025)
work page 2025
-
[21]
Ooi, L.Q.R., Chen, J., Zhang, S., Kong, R., Tam, A., Li, J., et al.: Comparison of individualized behavioral predictions across anatomical, diffusion and functional connectivity MRI. NeuroImage263, 119636 (2022)
work page 2022
-
[22]
IEEE Transactions on Medical Imaging42(2), 391–402 (2023)
Peng, L., Wang, N., Xu, J., Zhu, X., Li, X.: GATE: Graph CCA for Temporal Self-Supervised Learning for Label-Efficient fMRI Analysis. IEEE Transactions on Medical Imaging42(2), 391–402 (2023)
work page 2023
-
[23]
Pervaiz, U., Vidaurre, D., Woolrich, M.W., Smith, S.M.: Optimising network mod- elling methods for fMRI. NeuroImage211, 116604 (2020)
work page 2020
-
[24]
Nature Methods22(3), 473–476 (2025)
Ren,J.,An,N.,Lin,C.,Zhang,Y.,Sun,Z.,Zhang,etal.:DeepPrep:anaccelerated, scalable and robust pipeline for neuroimaging preprocessing empowered by deep learning. Nature Methods22(3), 473–476 (2025)
work page 2025
-
[25]
Neu- roImage86, 544–553 (2014)
Satterthwaite, T.D., Elliott, M.A., Ruparel, K., Loughead, J., Prabhakaran, K., Calkins, et al.: Neuroimaging of the Philadelphia Neurodevelopmental Cohort. Neu- roImage86, 544–553 (2014)
work page 2014
-
[26]
Cerebral cortex28(9), 3095–3114 (2018)
Schaefer, A., Kong, R., Gordon, E.M., Laumann, T.O., Zuo, X.N., Holmes, et al.: Local-Global Parcellation of the Human Cerebral Cortex from Intrinsic Functional Connectivity MRI. Cerebral cortex28(9), 3095–3114 (2018)
work page 2018
-
[27]
Nature Communications11(1), 1–15 (2020)
Schulz, M.A., Yeo, B.T., Vogelstein, J.T., Mourao-Miranada, J., Kather, J.N., Ko- rding, K., et al.: Different scaling of linear models and deep learning in UKBiobank brain images versus machine-learning datasets. Nature Communications11(1), 1–15 (2020)
work page 2020
-
[28]
Nature Mental Health1(5), 304–315 (2023)
Tiego, J., Martin, E.A., DeYoung, C.G., Hagan, K., Cooper, S.E., Pasion, et al.: Precision behavioral phenotyping as a strategy for uncovering the biological corre- lates of psychopathology. Nature Mental Health1(5), 304–315 (2023)
work page 2023
-
[29]
Brain Research1822, 148634 (2024)
Wei, W., Zhang, K., Chang, J., Zhang, S., Ma, L., Wang, H., et al.: Analyzing 20 years of Resting-State fMRI Research: Trends and collaborative networks revealed. Brain Research1822, 148634 (2024)
work page 2024
-
[30]
Wen, G., Cao, P., Liu, L., Yang, J., Zhang, X., Wang, F., et al.: Graph Self- Supervised Learning With Application to Brain Networks Analysis. IEEE Journal of Biomedical and Health Informatics27(8), 4154–4165 (2023) Network-Aware Bilinear Tokenization for Brain Functional Connectivity 11
work page 2023
-
[31]
Woo, C.W., Chang, L.J., Lindquist, M.A., Wager, T.D.: Building better biomark- ers:brainmodelsintranslationalneuroimaging.NatureNeuroscience20(3),365–377 (2017)
work page 2017
-
[32]
IEEE Transactions on Medical Imaging43(11), 4004–4016 (2024)
Yang,Y.,Ye,C.,Su,G.,Zhang,Z.,Chang,Z.,Chen,H.,etal.:BrainMass:Advanc- ing Brain Network Analysis for Diagnosis with Large-scale Self-Supervised Learning. IEEE Transactions on Medical Imaging43(11), 4004–4016 (2024)
work page 2024
-
[33]
Journal of Neurophysiology106(3), 1125–1165 (2011)
Yeo, B.T., Krienen, F.M., Sepulcre, J., Sabuncu, M.R., Lashkari, D., Hollinshead, M., et al.: The organization of the human cerebral cortex estimated by intrinsic functional connectivity. Journal of Neurophysiology106(3), 1125–1165 (2011)
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.