ABACUS: Adapting Unified Foundation Model for Bridging Image Count Understanding and Generation
Pith reviewed 2026-06-26 08:50 UTC · model grok-4.3
The pith
ABACUS adapts a 3B vision-language model to unify object counting and count-faithful image generation without benchmark-specific training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
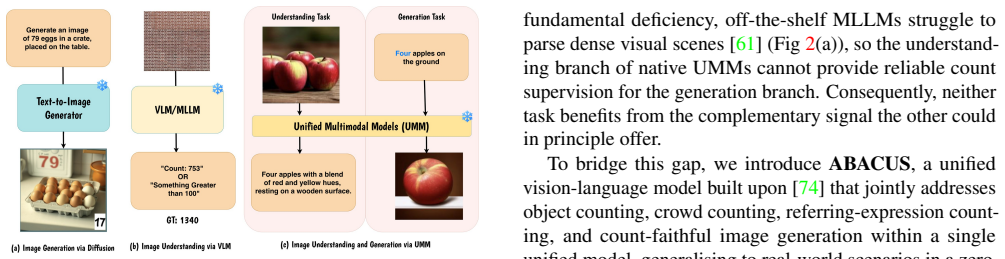
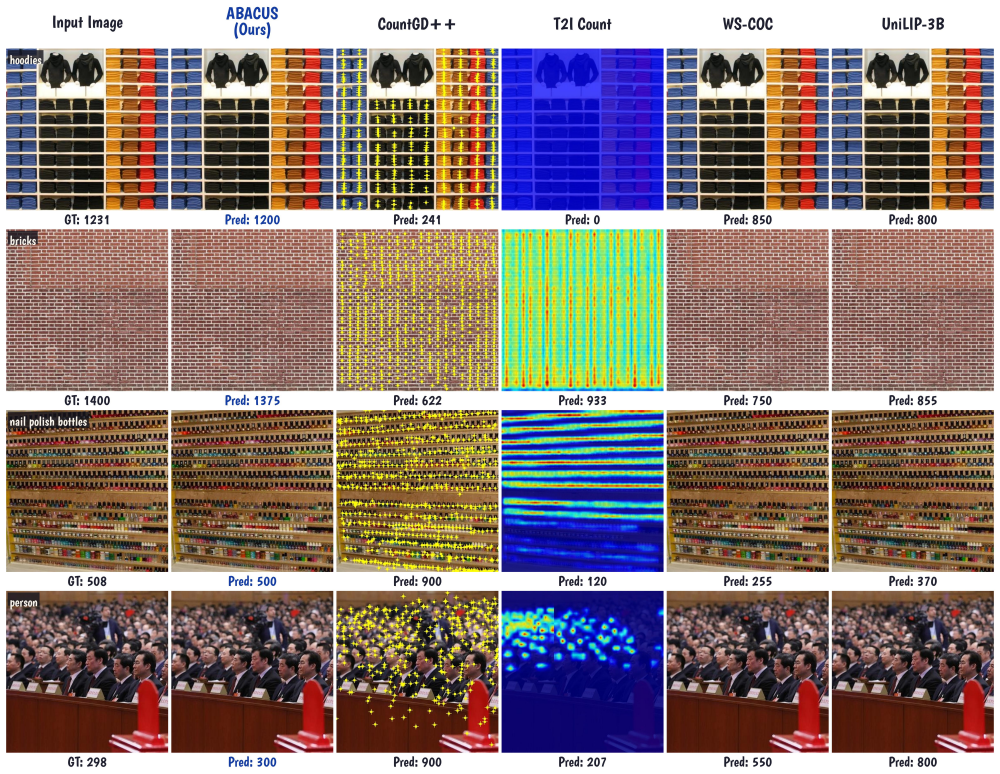
ABACUS is a unified vision-language model built on an existing 3B-parameter foundation model that handles multiple counting tasks and count-faithful image generation without any benchmark-specific training. It achieves this by integrating density-aware adaptive zooming with objectness maps for spatial grounding, a boundary-aware count policy via GRPO to eliminate crop-boundary errors, and a cycle-consistent GRPO strategy where the understanding branch self-critiques generated outputs to close the understanding-generation gap without external annotations. The model achieves state-of-the-art results across seven benchmarks, outperforming task-specific specialists and larger generalist models.
What carries the argument
Cycle-consistent GRPO strategy integrated with density-aware adaptive zooming and boundary-aware count policy, enabling self-critique between understanding and generation branches in the 3B model.
If this is right
- Handles object counting, crowd counting, referring-expression counting, and count-faithful image generation in one model.
- Achieves state-of-the-art performance on seven benchmarks without task-specific training or external annotations.
- Outperforms both task-specific specialist models and larger generalist models.
- Closes the understanding-generation gap through internal self-critique mechanisms.
Where Pith is reading between the lines
- The self-critique approach could extend to aligning other perception and generation tasks in vision-language models.
- Using a smaller 3B model suggests potential for efficient deployment in resource-constrained environments.
- Adaptive zooming and boundary policies might improve localization accuracy in other dense prediction tasks.
Load-bearing premise
The three proposed innovations can be successfully integrated into the base 3B model to close the understanding-generation gap without any external annotations or benchmark-specific training.
What would settle it
Demonstrating that the cycle-consistent GRPO does not improve generation quality on a counting benchmark or that performance drops below specialist models when any innovation is removed would falsify the central claim.
Figures









read the original abstract
ABACUS is a unified vision-language model that handles object counting, crowd counting, referring-expression counting, and count-faithful image generation without any benchmark-specific training required. Our model is built on existing 3B-parameter unified foundation model and is adapted for object localization tasks using three key innovations: density-aware adaptive zooming with objectness maps for spatial grounding; a boundary-aware count policy via GRPO to eliminate crop-boundary errors; and a cycle-consistent GRPO strategy where the understanding branch self-critiques generated outputs, closing the understanding-generation gap without any external annotations. ABACUS achieves state-of-the-art results across seven benchmarks, outperforming both task-specific specialists and larger generalist models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ABACUS, a 3B-parameter unified vision-language model adapted from an existing foundation model using three innovations (density-aware adaptive zooming with objectness maps, boundary-aware count policy via GRPO, and cycle-consistent GRPO) to handle object counting, crowd counting, referring-expression counting, and count-faithful image generation without benchmark-specific training or external annotations. It claims state-of-the-art results across seven benchmarks, outperforming both task-specific specialists and larger generalist models.
Significance. If substantiated, the result would be significant for showing that a compact unified model can close the understanding-generation gap in counting tasks via self-critique mechanisms, offering an efficient alternative to specialized models and reducing reliance on task-specific data.
major comments (2)
- Abstract: The claim of achieving state-of-the-art results on seven benchmarks is presented without any quantitative metrics, tables, error bars, ablation studies, or baseline comparisons, which is load-bearing for the central empirical claim and prevents verification of whether the three innovations drive the reported gains.
- The manuscript text provides no methods, equations, implementation details, or result sections to examine the integration of density-aware adaptive zooming, the GRPO policies, or the cycle-consistent loop, leaving the central claim that these close the understanding-generation gap without external annotations unverifiable.
Simulated Author's Rebuttal
We thank the referee for the feedback. We address each major comment below and will revise the manuscript to improve the verifiability of our claims.
read point-by-point responses
-
Referee: Abstract: The claim of achieving state-of-the-art results on seven benchmarks is presented without any quantitative metrics, tables, error bars, ablation studies, or baseline comparisons, which is load-bearing for the central empirical claim and prevents verification of whether the three innovations drive the reported gains.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revised manuscript we will add specific performance numbers (e.g., absolute gains on each of the seven benchmarks versus the strongest baselines) and a brief statement on the contribution of each innovation, while remaining within length limits. revision: yes
-
Referee: The manuscript text provides no methods, equations, implementation details, or result sections to examine the integration of density-aware adaptive zooming, the GRPO policies, or the cycle-consistent loop, leaving the central claim that these close the understanding-generation gap without external annotations unverifiable.
Authors: The full manuscript contains dedicated methodology and results sections that describe the density-aware adaptive zooming (with objectness-map equations), the boundary-aware GRPO policy, the cycle-consistent self-critique loop, implementation details, and supporting ablations. We will ensure these sections are more prominently cross-referenced from the abstract and introduction in the revision. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description contain no equations, derivations, or first-principles claims. All central assertions are empirical performance results on external benchmarks after adaptation of a base model. No self-citations, fitted parameters renamed as predictions, or self-definitional steps are present or load-bearing. The work is therefore self-contained against external benchmarks with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
nocaps: novel object captioning at scale
Harsh Agrawal, Karan Desai, Yufei Wang, Xinlei Chen, Rishabh Jain, Mark Johnson, Dhruv Batra, Devi Parikh, Ste- fan Lee, and Peter Anderson. nocaps: novel object captioning at scale. InICCV, pages 8948–8957, 2019. 3
2019
-
[2]
Mea- suring the objectness of image windows.IEEE transactions on pattern analysis and machine intelligence, 34(11):2189– 2202, 2012
Bogdan Alexe, Thomas Deselaers, and Vittorio Ferrari. Mea- suring the objectness of image windows.IEEE transactions on pattern analysis and machine intelligence, 34(11):2189– 2202, 2012. 2
2012
-
[3]
Amini-Naieni, K
N. Amini-Naieni, K. Amini-Naieni, T. Han, and A. Zisser- man. Open-world text-specified object counting. InBritish Machine Vision Conference, 2023. 1
2023
-
[4]
Amini-Naieni, T
N. Amini-Naieni, T. Han, and A. Zisserman. Countgd: Multi- modal open-world counting. InNeurIPS (NeurIPS), 2024. 3
2024
-
[5]
CountGD++: Generalized Prompting for Open-World Counting
Niki Amini-Naieni and Andrew Zisserman. Countgd++: Gen- eralized prompting for open-world counting.arXiv preprint arXiv:2512.23351, 2025. 2, 7, 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Open-world text-specified object count- ing.arXiv preprint arXiv:2306.01851, 2023
Niki Amini-Naieni, Kiana Amini-Naieni, Tengda Han, and Andrew Zisserman. Open-world text-specified object count- ing.arXiv preprint arXiv:2306.01851, 2023. 2, 7
-
[7]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5- vl technical report.a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens.arXiv preprint arXiv:2303.08112, 2023. 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Improving image generation with better cap- tions.Computer Science, 2(3):8, 2023
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better cap- tions.Computer Science, 2(3):8, 2023. DALL-E 3 technical report. 3
2023
-
[10]
Make it count: Text-to- image generation with an accurate number of objects, 2024
Lital Binyamin, Yoad Tewel, et al. Make it count: Text-to- image generation with an accurate number of objects, 2024. arXiv:2406.10210. 9
-
[11]
Make it count: Text-to-image generation with an accurate number of objects
Lital Binyamin, Yoad Tewel, Hilit Segev, Eran Hirsch, Royi Rassin, and Gal Chechik. Make it count: Text-to-image generation with an accurate number of objects. InCVPR, pages 13242–13251, 2025. 1, 2, 3, 6, 7, 16
2025
-
[12]
Black-Forest-Labs. FLUX. https://github.com/ black-forest-labs/flux, 2024. 3
2024
-
[13]
Counting everyday objects in everyday scenes
Prithvijit Chattopadhyay, Ramakrishna Vedantam, Ram- prasaath R Selvaraju, Dhruv Batra, and Devi Parikh. Counting everyday objects in everyday scenes. InCVPR, pages 1135– 1144, 2017. 3
2017
-
[14]
Attend-and-excite: Attention-based semantic guid- ance for text-to-image diffusion models
Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, and Daniel Cohen-Or. Attend-and-excite: Attention-based semantic guid- ance for text-to-image diffusion models. volume 42, pages 1–10, 2023. 3
2023
-
[15]
Revisiting referring expression comprehension evaluation in the era of large multimodal models
Jierun Chen, Fangyun Wei, Jinjing Zhao, Sizhe Song, Bohuai Wu, Zhuoxuan Peng, S-H Gary Chan, and Hongyang Zhang. Revisiting referring expression comprehension evaluation in the era of large multimodal models. InCVPR, pages 513–524,
-
[16]
Dc-ae 1.5: Accelerating dif- fusion model convergence with structured latent space
Junyu Chen, Dongyun Zou, Wenkun He, Junsong Chen, Enze Xie, Song Han, and Han Cai. Dc-ae 1.5: Accelerating dif- fusion model convergence with structured latent space. In ICCV, pages 19628–19637, 2025. 6, 14
2025
-
[17]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025. 2, 7, 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InCVPR, pages 24185–24198, 2024. 6, 14
2024
-
[19]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. Sft memorizes, rl generalizes: A comparative study of foundation model post-training.arXiv preprint arXiv:2501.17161, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Be yourself: Bounded attention for multi-subject text-to-image generation
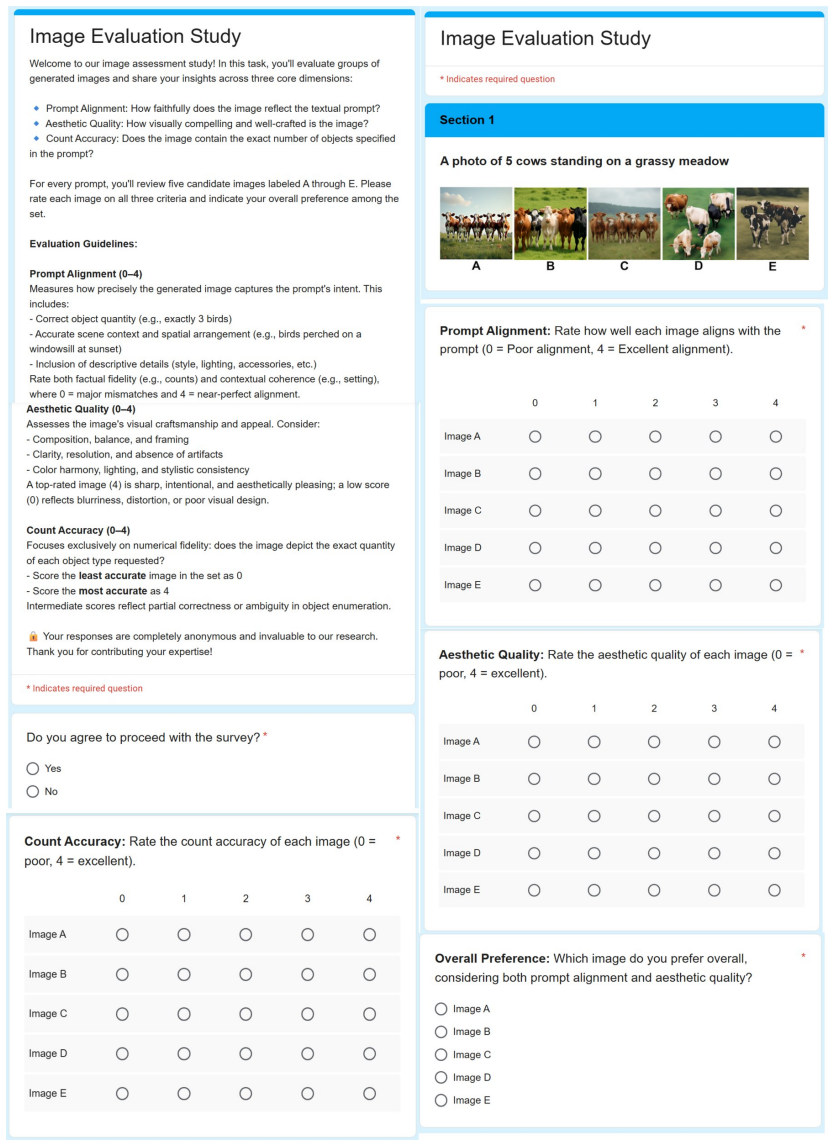
Omer Dahary, Or Patashnik, Kfir Aberman, and Daniel Cohen-Or. Be yourself: Bounded attention for multi-subject text-to-image generation. InECCV, pages 432–448, 2024. 2, 3, 7, 16 Figure 12. Human evaluation form.For each prompt, annotators rate five anonymized images on Count Accuracy, Aesthetic Quality, and Prompt Alignment (0–4 Likert), then select an ov...
2024
-
[21]
Referring ex- pression counting
Siyang Dai, Jun Liu, and Ngai-Man Cheung. Referring ex- pression counting. InCVPR (CVPR), pages 16985–16995, June 2024. 3
2024
-
[22]
Referring ex- pression counting
Siyang Dai, Jun Liu, and Ngai-Man Cheung. Referring ex- pression counting. InCVPR, pages 16985–16995, 2024. 6, 7
2024
-
[23]
Referring ex- pression counting
Siyang Dai, Jun Liu, and Ngai-Man Cheung. Referring ex- pression counting. InCVPR, pages 16985–16995, 2024. 2, 6
2024
-
[24]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pre- training.arXiv preprint arXiv:2505.14683, 2025. 2, 7, 9, 10, 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Domain- general crowd counting in unseen scenarios
Zhipeng Du, Jiankang Deng, and Miaojing Shi. Domain- general crowd counting in unseen scenarios. InAAAI, vol- ume 37, pages 561–570, 2023. 3
2023
-
[26]
LayoutGPT: compositional visual plan- ning and generation with large language models.NeurIPS, 36:18225–18250, 2023
Weixi Feng, Wanrong Zhu, Tsu-jui Fu, Varun Jampani, Ar- jun Akula, Xuehai He, Sugato Basu, Xin Eric Wang, and William Yang Wang. LayoutGPT: compositional visual plan- ning and generation with large language models.NeurIPS, 36:18225–18250, 2023. 3
2023
-
[27]
Geneval: An object-focused framework for evaluating text-to- image alignment.NeurIPS, 36:52132–52152, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to- image alignment.NeurIPS, 36:52132–52152, 2023. 6
2023
-
[28]
Precise detection in densely packed scenes
Eran Goldman, Roei Herzig, Aviv Eisenschtat, Jacob Gold- berger, and Tal Hassner. Precise detection in densely packed scenes. InProc. Conf. Comput. Vision Pattern Recognition (CVPR), 2019. 6
2019
-
[29]
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: El- evating the role of image understanding in visual ques- tion answering. InCVPR, pages 6325–6334, 2017. doi: 10.1109/CVPR.2017.670. 3
-
[30]
Regressor-segmenter mutual prompt learning for crowd counting
Mingyue Guo, Li Yuan, Zhaoyi Yan, Binghui Chen, Yaowei Wang, and Qixiang Ye. Regressor-segmenter mutual prompt learning for crowd counting. InCVPR, pages 28380–28389,
-
[31]
Drone- based object counting by spatially regularized regional pro- posal network
Meng-Ru Hsieh, Yen-Liang Lin, and Winston H Hsu. Drone- based object counting by spatially regularized regional pro- posal network. InICCV, pages 4145–4153, 2017. 3, 6
2017
-
[32]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InICLR,
-
[33]
URL https://openreview.net/forum?id= nZeVKeeFYf9. 6, 14
-
[34]
CLIP-Count: Towards Text-Guided Zero-Shot Object Counting
Ruixiang Jiang, Lingbo Liu, and Changwen Chen. Clip-count: Towards text-guided zero-shot object counting.arXiv preprint arXiv:2305.07304, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[35]
Vlcounter: Text-aware visual representation for zero- shot object counting
Seunggu Kang, WonJun Moon, Euiyeon Kim, and Jae-Pil Heo. Vlcounter: Text-aware visual representation for zero- shot object counting. InAAAI, volume 38, pages 2714–2722,
-
[36]
Counting guidance for high fidelity text-to-image synthesis
Wonjun Kang, Kevin Galim, Hyung Il Koo, and Nam Ik Cho. Counting guidance for high fidelity text-to-image synthesis. InWACV, pages 899–908, 2025. 1, 2, 3, 7, 9, 16
2025
-
[37]
Referitgame: Referring to objects in pho- tographs of natural scenes
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. Referitgame: Referring to objects in pho- tographs of natural scenes. InProceedings of the 2014 con- ference on empirical methods in natural language processing (EMNLP), pages 787–798, 2014. 4
2014
-
[38]
Deep- box: Learning objectness with convolutional networks
Weicheng Kuo, Bharath Hariharan, and Jitendra Malik. Deep- box: Learning objectness with convolutional networks. In ICCV, pages 2479–2487, 2015. 2
2015
-
[39]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Calibrating uncertainty for semi-supervised crowd counting
Chen Li, Xiaoling Hu, Shahira Abousamra, and Chao Chen. Calibrating uncertainty for semi-supervised crowd counting. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 16685–16695. IEEE, 2023. 3
2023
-
[41]
Blip: Bootstrapping language-image pre-training for unified vision- language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision- language understanding and generation. InICML, pages 12888–12900. PMLR, 2022. 3
2022
-
[42]
GLIGEN: open-set grounded text-to-image generation
Yuheng Li, Haotian Liu, Jianwei Yang, et al. GLIGEN: open-set grounded text-to-image generation. InCVPR, pages 22511–22521, 2023. 3
2023
-
[43]
Csrnet: Di- lated convolutional neural networks for understanding the highly congested scenes
Yuhong Li, Xiaofan Zhang, and Deming Chen. Csrnet: Di- lated convolutional neural networks for understanding the highly congested scenes. InCVPR, pages 1091–1100, 2018. 3
2018
-
[44]
An end-to-end transformer model for crowd localization.ECCV, 2022
Dingkang Liang, Wei Xu, and Xiang Bai. An end-to-end transformer model for crowd localization.ECCV, 2022. 3
2022
-
[45]
Crowdclip: Unsupervised crowd counting via vision-language model
Dingkang Liang, Jiahao Xie, Zhikang Zou, Xiaoqing Ye, Wei Xu, and Xiang Bai. Crowdclip: Unsupervised crowd counting via vision-language model. InCVPR, pages 2893–2903, 2023. 2
2023
-
[46]
Countr: Transformer-based generalised visual count- ing.arXiv preprint arXiv:2208.13721, 2022
Chang Liu, Yujie Zhong, Andrew Zisserman, and Weidi Xie. Countr: Transformer-based generalised visual count- ing.arXiv preprint arXiv:2208.13721, 2022. 1, 3
-
[47]
Point- query quadtree for crowd counting, localization, and more
Chengxin Liu, Hao Lu, Zhiguo Cao, and Tongliang Liu. Point- query quadtree for crowd counting, localization, and more. In ICCV, pages 1676–1685, 2023. 3
2023
-
[48]
Llavanext: Improved reason- ing, ocr, and world knowledge, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llavanext: Improved reason- ing, ocr, and world knowledge, 2024. 3
2024
-
[49]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection.arXiv preprint arXiv:2303.05499, 2023. 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InECCV, pages 38–55. Springer, 2024. 4
2024
-
[51]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InECCV, pages 38–55. Springer, 2024. 7
2024
-
[52]
Countse: Soft exemplar open-set object counting
Shuai Liu, Peng Zhang, Shiwei Zhang, and Wei Ke. Countse: Soft exemplar open-set object counting. InICCV, pages 21536–21546, 2025. 7
2025
-
[53]
Class-agnostic counting
Erika Lu, Weidi Xie, and Andrew Zisserman. Class-agnostic counting. InComputer Vision–ACCV 2018: 14th Asian Con- ference on Computer Vision, Perth, Australia, December 2–6, 2018, Revised Selected Papers, Part III 14, pages 669–684. Springer, 2019. 3
2018
-
[54]
CountLoop: Training-Free High-Instance Image Generation via Iterative Agent Guidance
Anindya Mondal, Ayan Banerjee, Sauradip Nag, Josep Llados, Xiatian Zhu, and Anjan Dutta. Countloop: Training-free high- instance image generation via iterative agent guidance.arXiv preprint arXiv:2508.16644, 2025. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
A large contextual dataset for classification, de- tection and counting of cars with deep learning
T Nathan Mundhenk, Goran Konjevod, Wesam A Sakla, and Kofi Boakye. A large contextual dataset for classification, de- tection and counting of cars with deep learning. InComputer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part III 14, pages 785–800. Springer, 2016. 3
2016
-
[56]
Towards interpreting visual in- formation processing in vision-language models
Clement Neo, Luke Ong, Philip Torr, Mor Geva, David Krueger, and Fazl Barez. Towards interpreting visual in- formation processing in vision-language models. InICLR, volume 2025, pages 57172–57189, 2025. 4
2025
-
[57]
Gpt-5.5 system card, 2026
OpenAI. Gpt-5.5 system card, 2026. URL https:// deploymentsafety.openai.com/gpt-5-5/gpt- 5-5.pdf. Accessed: 2026-05-04. 7
2026
-
[58]
Teaching clip to count to ten
Roni Paiss, Ariel Ephrat, Omer Tov, Shiran Zada, Inbar Mosseri, Michal Irani, and Tali Dekel. Teaching clip to count to ten. InICCV, pages 3170–3180, 2023. 3
2023
-
[59]
Dave-a detect-and-verify paradigm for low-shot counting
Jer Pelhan, Vitjan Zavrtanik, Matej Kristan, et al. Dave-a detect-and-verify paradigm for low-shot counting. InCVPR, pages 23293–23302, 2024. 3
2024
-
[60]
Single domain general- ization for crowd counting
Zhuoxuan Peng and S-H Gary Chan. Single domain general- ization for crowd counting. InCVPR, pages 28025–28034,
-
[61]
SDXL: improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. SDXL: improving latent diffusion models for high-resolution image synthesis. InICLR, 2024. 3
2024
-
[62]
Muhammad Fetrat Qharabagh, Mohammadreza Ghofrani, and Kimon Fountoulakis. Lvlm-count: Enhancing the count- ing ability of large vision-language models.arXiv preprint arXiv:2412.00686, 2024. 2, 3, 4
-
[63]
T2icount: Enhancing cross-modal understanding for zero-shot counting
Yifei Qian, Zhongliang Guo, Bowen Deng, Chun Tong Lei, Shuai Zhao, Chun Pong Lau, Xiaopeng Hong, and Michael P Pound. T2icount: Enhancing cross-modal understanding for zero-shot counting. InCVPR, 2025. 3, 7
2025
-
[64]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InICML, pages 8748–8763. PmLR, 2021. 3
2021
-
[65]
Crowddiff: Multi-hypothesis crowd density estimation using diffusion models
Yasiru Ranasinghe, Nithin Gopalakrishnan Nair, Wele Gedara Chaminda Bandara, and Vishal M Patel. Crowddiff: Multi-hypothesis crowd density estimation using diffusion models. InCVPR, pages 12809–12819, 2024. 3
2024
-
[66]
Learning to count everything
Viresh Ranjan, Udbhav Sharma, Thu Nguyen, and Minh Hoai. Learning to count everything. InCVPR, pages 3394–3403,
-
[67]
Laion-5b: An open large-scale dataset for training next gen- eration image-text models.Advances in neural information processing systems, 35:25278–25294, 2022
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next gen- eration image-text models.Advances in neural information processing systems, 35:25278–25294, 2022. 6
2022
-
[68]
Objects365: A large-scale, high-quality dataset for object detection
Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. Objects365: A large-scale, high-quality dataset for object detection. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 8430–8439, 2019. 6
2019
-
[69]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 2, 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
Re- visiting perspective information for efficient crowd counting
Miaojing Shi, Zhaohui Yang, Chao Xu, and Qijun Chen. Re- visiting perspective information for efficient crowd counting. InCVPR, pages 7279–7288, 2019. 3
2019
-
[71]
Training-free object counting with prompts
Zenglin Shi, Ying Sun, and Mengmi Zhang. Training-free object counting with prompts. InWACV, pages 323–331,
-
[72]
Crowd counting in the frequency domain
Weibo Shu, Jia Wan, Kay Chen Tan, Sam Kwong, and An- toni B Chan. Crowd counting in the frequency domain. In CVPR, pages 19618–19627, 2022. 2
2022
-
[73]
Principles of object perception.Cognitive science, 14(1):29–56, 1990
Elizabeth S Spelke. Principles of object perception.Cognitive science, 14(1):29–56, 1990. 2
1990
-
[74]
Jayant Sravan Tamarapalli, Rynaa Grover, Nilay Pande, and Sahiti Yerramilli. Countqa: How well do mllms count in the wild?arXiv preprint arXiv:2508.06585, 2025. 6, 7
-
[75]
Unilip: Adapting clip for unified multimodal understanding, generation and editing
Hao Tang, Chenwei Xie, Xiaoyi Bao, Tingyu Weng, Pandeng Li, Yun Zheng, and Liwei Wang. Unilip: Adapting clip for unified multimodal understanding, generation and editing. arXiv preprint arXiv:2507.23278, 2025. 2, 4, 5, 6, 7, 9, 14, 16
-
[76]
Training-free consistent text-to-image generation.ACM TOG, 43(4):1–18, 2024
Yoad Tewel, Omri Kaduri, Rinon Gal, Yoni Kasten, Lior Wolf, Gal Chechik, and Yuval Atzmon. Training-free consistent text-to-image generation.ACM TOG, 43(4):1–18, 2024. 3
2024
-
[77]
Attention is all you need.NeurIPS, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.NeurIPS, 30, 2017. 2, 4
2017
-
[78]
Diffusion model align- ment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model align- ment using direct preference optimization. InCVPR, pages 8228–8238, 2024. 3
2024
-
[79]
Distribution matching for crowd counting.NeurIPS, 33:1595–1607, 2020
Boyu Wang, Huidong Liu, Dimitris Samaras, and Minh Hoai Nguyen. Distribution matching for crowd counting.NeurIPS, 33:1595–1607, 2020. 3
2020
-
[80]
Yolov9: Learning what you want to learn using programmable gradient information
Chien-Yao Wang, I-Hau Yeh, and Hong-Yuan Mark Liao. Yolov9: Learning what you want to learn using programmable gradient information. InECCV, pages 1–21. Springer, 2024. 6
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.