FracEvent: Event-Camera Simulation via Fractional-Relaxation Pixel Dynamics
Pith reviewed 2026-06-26 05:55 UTC · model grok-4.3
The pith
FracEvent models event-camera pixels with fractional-relaxation voltage dynamics to produce more accurate event timing than contrast-threshold simulators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
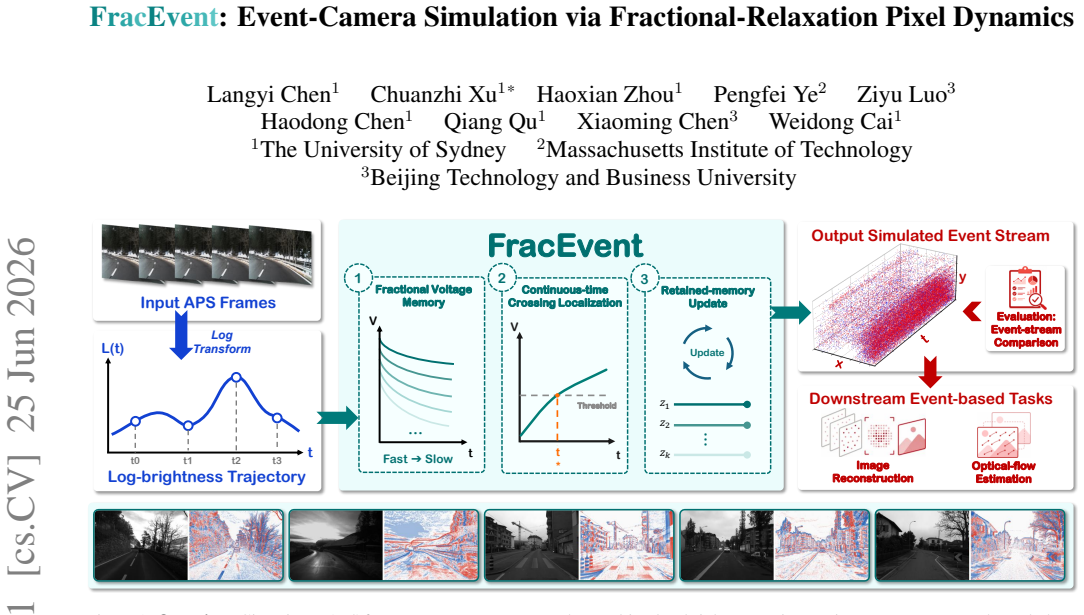
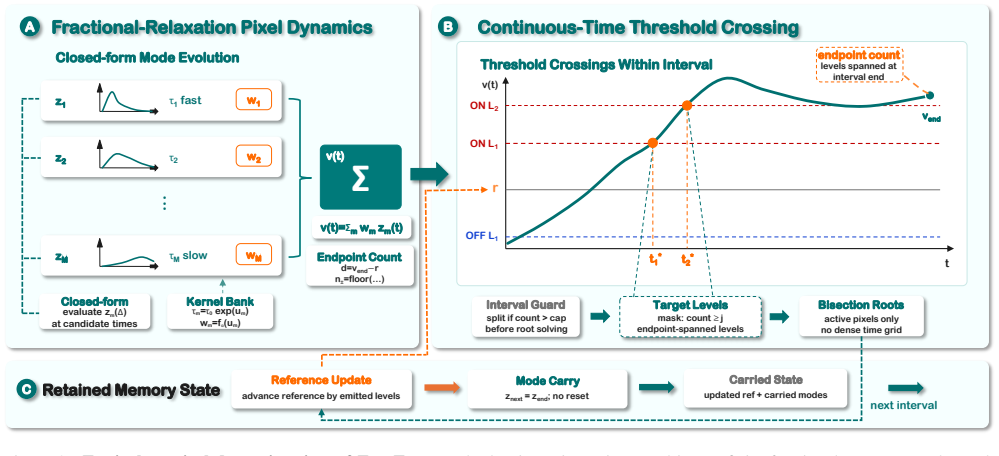
FracEvent models the pixel lifecycle with fractional-relaxation voltage dynamics: a compact stack of relaxation modes is driven from a log-intensity trajectory, their responses are combined into a voltage state, ON/OFF events are emitted at threshold crossings on the continuous trajectory, and the reference is updated while the underlying modes retain memory to affect later timing.
What carries the argument
a compact stack of relaxation modes combined into voltage whose retained memory after each event influences subsequent threshold crossings
If this is right
- Simulated event streams exhibit improved temporal structure matching real data more closely than baselines.
- Downstream models for image reconstruction achieve stronger results when trained on FracEvent outputs.
- Downstream models for optical flow estimation achieve stronger results when trained on FracEvent outputs.
- The method outperforms competing simulator baselines across multiple evaluation datasets.
Where Pith is reading between the lines
- Retained memory modes could support simulation of longer-term adaptation behaviors observed in physical sensors.
- The same retained-state approach might extend to modeling other asynchronous sensors that report threshold crossings.
- Adding spatial coupling among neighboring pixel modes could address limitations in scenes with strong local contrast changes.
Load-bearing premise
A stack of fractional relaxation modes driven from log-intensity trajectories and updated only at event times sufficiently captures the dominant temporal dynamics of real event-camera pixels.
What would settle it
Direct comparison of inter-event time distributions or voltage response shapes produced by FracEvent against recordings from a physical event camera on the same controlled log-intensity stimulus sequence.
Figures


read the original abstract
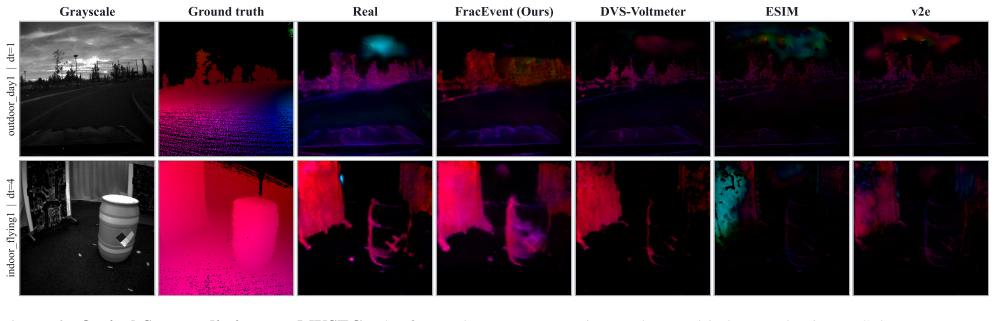
Event cameras asynchronously report brightness changes with microsecond-level temporal resolution, but real event data remain difficult to collect at scale because specialized sensors, careful synchronization, and task-specific annotations are required. Event-camera simulation is therefore important to event-based vision tasks. Most practical simulators build on contrast-threshold event generation, some with additional filtering, stochastic noise, or hand-tuned sensor parameters. While effective, such formulations often simplify the temporal structure produced by the lifecycle of each pixel, which can distort event timing and weaken downstream transfer. We introduce FracEvent, an event simulator that models this pixel-level lifecycle with fractional-relaxation voltage dynamics. Given a log-intensity trajectory, FracEvent drives a compact stack of relaxation modes, combines their responses into a voltage state, emits ON/OFF events by localizing threshold crossings on the continuous voltage trajectory, and updates the reference while retaining the underlying memory modes. This retained state links residual voltage response to later event timing. We evaluate FracEvent through event-stream comparison and downstream transfer on image reconstruction and optical flow estimation. Across multiple datasets, FracEvent improves the temporal structure of generated events and achieves stronger downstream-transfer results than competing simulator baselines, showing its practical value for event-camera simulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FracEvent, an event-camera simulator that models each pixel's voltage lifecycle via a compact stack of fractional-relaxation modes driven from log-intensity trajectories. Events are emitted by localizing threshold crossings on the continuous voltage state; after each event the reference is updated while the underlying memory modes are retained to influence subsequent timing. The method is evaluated via event-stream statistics and downstream transfer on image reconstruction and optical flow tasks, with the claim that it produces more realistic temporal event structure and stronger transfer performance than prior simulators across multiple datasets.
Significance. If the fractional-relaxation formulation demonstrably improves fidelity to real pixel dynamics, the simulator could narrow the sim-to-real gap for event-based vision, enabling more reliable synthetic data for training and evaluation. The explicit retention of memory modes after reference updates is a concrete modeling choice that could preserve temporal dependencies not captured by simpler threshold or filtered models.
major comments (3)
- [Abstract] Abstract: the central claim that FracEvent 'improves the temporal structure of generated events and achieves stronger downstream-transfer results' is stated without any quantitative metrics (e.g., event-rate histograms, timing-error distributions, or transfer-task accuracies with error bars), rendering the magnitude and reliability of the reported gains impossible to assess.
- [Pixel lifecycle modeling paragraph] Pixel-lifecycle-modeling paragraph (and associated method description): the assumption that driving a stack of fractional relaxation modes from log-intensity trajectories and updating only at event times sufficiently reproduces dominant real-pixel voltage dynamics is load-bearing for the entire contribution, yet no direct comparison to measured pixel responses, continuous-time simulations, or non-fractional baselines is supplied to test this assumption.
- [Evaluation section] Evaluation section: no ablation results are reported on the number of relaxation modes in the stack or on the choice of fractional orders, both of which are free parameters introduced by the method and directly affect the claimed temporal-structure improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that FracEvent 'improves the temporal structure of generated events and achieves stronger downstream-transfer results' is stated without any quantitative metrics (e.g., event-rate histograms, timing-error distributions, or transfer-task accuracies with error bars), rendering the magnitude and reliability of the reported gains impossible to assess.
Authors: We agree that the abstract would be strengthened by quantitative support. The revised abstract will include key metrics such as timing-error reductions and downstream accuracy gains with error bars drawn from the evaluation results. revision: yes
-
Referee: [Pixel lifecycle modeling paragraph] Pixel-lifecycle-modeling paragraph (and associated method description): the assumption that driving a stack of fractional relaxation modes from log-intensity trajectories and updating only at event times sufficiently reproduces dominant real-pixel voltage dynamics is load-bearing for the entire contribution, yet no direct comparison to measured pixel responses, continuous-time simulations, or non-fractional baselines is supplied to test this assumption.
Authors: The current validation uses event-stream statistics and transfer performance as indirect evidence. We will add direct comparisons against non-fractional baselines and continuous-time simulations. Measured real-pixel responses are not available in the public datasets used, so that specific comparison cannot be supplied. revision: partial
-
Referee: [Evaluation section] Evaluation section: no ablation results are reported on the number of relaxation modes in the stack or on the choice of fractional orders, both of which are free parameters introduced by the method and directly affect the claimed temporal-structure improvements.
Authors: We agree that ablations on these parameters are necessary. The revised evaluation will report results for varying numbers of modes and fractional orders, quantifying their effect on temporal structure and transfer performance. revision: yes
Circularity Check
No significant circularity; modeling choice is independent
full rationale
The paper presents FracEvent as an explicit modeling decision: a stack of fractional-relaxation modes driven from log-intensity trajectories, with events emitted at continuous threshold crossings and memory modes retained after reference updates. This is introduced as a new ansatz for pixel lifecycle dynamics rather than derived from prior equations or fitted parameters within the paper. No self-citations are invoked as load-bearing uniqueness theorems, no parameters are fitted to a subset and then relabeled as predictions, and the reported gains in event timing and downstream transfer are framed as empirical outcomes on external datasets. The derivation chain therefore remains self-contained against the stated modeling assumptions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A 240 x 180 130 db 3 us latency global shutter spatiotemporal vision sensor.IEEE Journal of Solid-State Circuits, 49(10):2333–2341, 2014
Christian Brandli, Raphael Berner, Minhao Yang, Shih-Chii Liu, and Tobi Delbruck. A 240 x 180 130 db 3 us latency global shutter spatiotemporal vision sensor.IEEE Journal of Solid-State Circuits, 49(10):2333–2341, 2014
2014
-
[2]
EVREAL: Towards a comprehensive benchmark and analysis suite for event-based video reconstruction
Burak Ercan, Onur Eker, Aykut Erdem, and Erkut Erdem. EVREAL: Towards a comprehensive benchmark and analysis suite for event-based video reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 3943–3952. IEEE, 2023
2023
-
[3]
Video to events: Recycling video datasets for event cameras
Daniel Gehrig, Mathias Gehrig, Javier Hidalgo-Carrio, and Davide Scaramuzza. Video to events: Recycling video datasets for event cameras. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3586–3595, 2020
2020
-
[4]
v2e: From video frames to realistic DVS events
Yuhuang Hu, Shih-Chii Liu, and Tobi Delbruck. v2e: From video frames to realistic DVS events. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 1312–1321, 2021
2021
-
[5]
Shi, and Ryad B
Xavier Lagorce, Garrick Orchard, Francesco Galluppi, Bertram E. Shi, and Ryad B. Benosman. HOTS: A hierarchy of event-based time-surfaces for pattern recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(7):1346–1359, 2017
2017
-
[6]
DVS-V oltmeter: Stochastic process-based event simulator for dynamic vision sensors
Songnan Lin, Ye Ma, Zhenhua Guo, and Bihan Wen. DVS-V oltmeter: Stochastic process-based event simulator for dynamic vision sensors. InComputer Vision – ECCV 2022, pages 578–593. Springer Nature Switzerland, 2022
2022
-
[7]
The event-camera dataset and simulator: Event-based data for pose estimation, visual odometry, and SLAM.The International Journal of Robotics Research, 36(2):142–149, 2017
Elias Mueggler, Henri Rebecq, Guillermo Gallego, Tobi Delbruck, and Davide Scaramuzza. The event-camera dataset and simulator: Event-based data for pose estimation, visual odometry, and SLAM.The International Journal of Robotics Research, 36(2):142–149, 2017
2017
-
[8]
Deep multi-scale convolutional neural network for dynamic scene deblurring
Seungjun Nah, Tae Hyun Kim, and Kyoung Mu Lee. Deep multi-scale convolutional neural network for dynamic scene deblurring. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3883–3891, 2017
2017
-
[9]
ESIM: An open event camera simulator
Henri Rebecq, Daniel Gehrig, and Davide Scaramuzza. ESIM: An open event camera simulator. InProceedings of The 2nd Confer- ence on Robot Learning, pages 969–982. PMLR, 2018
2018
-
[10]
Events-to-video: Bringing modern computer vision to event cameras
Henri Rebecq, Rene Ranftl, Vladlen Koltun, and Davide Scaramuzza. Events-to-video: Bringing modern computer vision to event cameras. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3857–3866, 2019
2019
-
[11]
HATS: Histograms of averaged time surfaces for robust event-based object classification
Amos Sironi, Manuele Brambilla, Nicolas Bourdis, Xavier Lagorce, and Ryad Benosman. HATS: Histograms of averaged time surfaces for robust event-based object classification. InProceedings of the IEEE Conference on Computer Vision and Pattern Recog- nition, pages 1731–1740, 2018
2018
-
[12]
Reducing the sim-to-real gap for event cameras
Timo Stoffregen, Cedric Scheerlinck, Davide Scaramuzza, Tom Drummond, Nick Barnes, Lindsay Kleeman, and Robert Mahony. Reducing the sim-to-real gap for event cameras. InEuropean Conference on Computer Vision, pages 534–549. Springer, 2020
2020
-
[13]
Springer, Berlin, Heidelberg, 2009
Cedric Villani.Optimal Transport: Old and New. Springer, Berlin, Heidelberg, 2009
2009
-
[14]
Bovik, Hamid R
Zhou Wang, Alan C. Bovik, Hamid R. Sheikh, and Eero P. Simoncelli. Image quality assessment: From error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004
2004
-
[15]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 586–595, 2018
2018
-
[16]
The multi vehicle stereo event camera dataset: An event camera dataset for 3D perception.IEEE Robotics and Automation Letters, 3(3):2032–2039, 2018
Alex Zihao Zhu, Dinesh Thakur, Tolga Ozaslan, Bernd Pfrommer, Vijay Kumar, and Kostas Daniilidis. The multi vehicle stereo event camera dataset: An event camera dataset for 3D perception.IEEE Robotics and Automation Letters, 3(3):2032–2039, 2018
2032
-
[17]
EV-FlowNet: Self-supervised optical flow estimation for event-based cameras
Alex Zihao Zhu, Liangzhe Yuan, Kenneth Chaney, and Kostas Daniilidis. EV-FlowNet: Self-supervised optical flow estimation for event-based cameras. InRobotics: Science and Systems, 2018. 23
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.