On the Policy Gradient Foundations of Group Relative Policy Optimization: Credit Assignment, Gradient Sparsity, and Rank Collapse
Pith reviewed 2026-06-30 08:38 UTC · model grok-4.3
The pith
Under output-only rewards GRPO assigns identical advantages to every token in a rollout, collapsing the gradient matrix to effective rank approximately 2.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
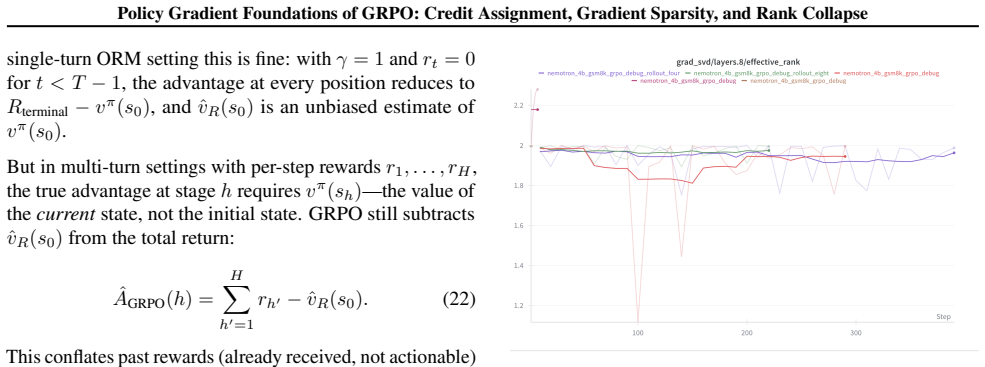
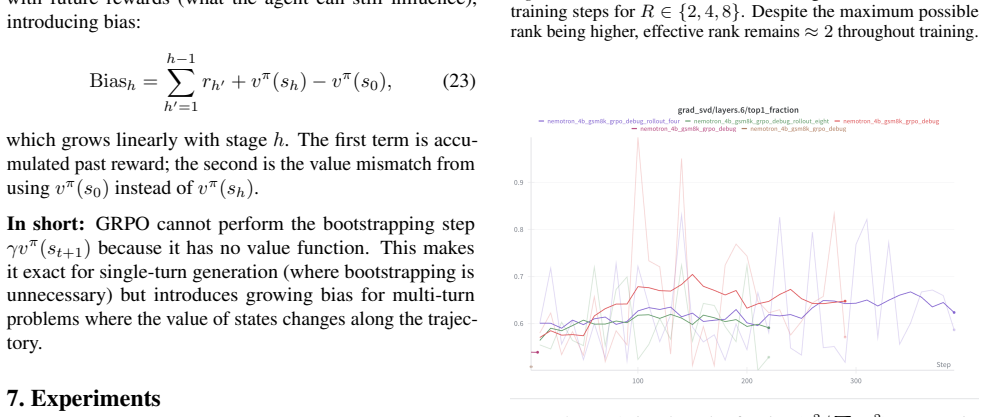
GRPO's group-mean baseline produces identical advantages for all tokens whenever reward is supplied only at rollout completion; the resulting zero-sum constraint on advantages forces the policy gradient matrix to possess an intrinsic rank-2 structure, which the authors prove induces increasing gradient sparsity over training and which SVD measurements on a 4B model confirm remains near rank 2 independent of group size R.
What carries the argument
The group-mean advantage estimator that subtracts the average reward of R rollouts from each rollout's reward, assigning the identical scalar to every token within that rollout.
If this is right
- Gradient sparsity intensifies as training proceeds.
- Effective rank of the gradient matrix stays near 2 for any group size in {2, 4, 8}.
- The group-mean baseline is optimal only under conditions derived from the zero-sum advantage constraint.
- Multi-step reasoning performance is limited by the inability to assign differentiated credit to individual tokens.
Where Pith is reading between the lines
- Any RL method that relies solely on end-of-sequence rewards may encounter similar rank collapse unless auxiliary per-token signals are added.
- Alternative baseline estimators or learned critics could restore higher gradient rank by breaking the identical-advantage property.
- The rank-2 structure may generalize to other group-based advantage estimators that enforce zero-sum constraints within each group.
Load-bearing premise
Rewards arrive only after each complete rollout finishes and supply no per-token or intermediate signals that could differentiate contributions inside a sequence.
What would settle it
Compute the singular-value spectrum of the GRPO gradient matrix on a task that supplies per-token reward labels and check whether the effective rank rises well above 2.
Figures
read the original abstract
Group Relative Policy Optimization (GRPO) eliminates the learned critic in PPO by using the mean reward of grouped rollouts as a baseline. We provide a rigorous derivation of GRPO from first principles of the policy gradient theorem, revealing a fundamental credit assignment failure: under output-only reward, every token in a rollout receives identical advantage, collapsing token-level credit to a single scalar. We prove this induces gradient sparsity that intensifies over training, and demonstrate empirically via SVD analysis of GRPO gradients on Nemotron-4B/GSM8K that the gradient matrix has effective rank $\approx$ 2 regardless of group size $R \in \{2, 4, 8\}$. We formalize this as an intrinsic rank-2 structure arising from the zero-sum constraint on advantages and derive conditions under which GRPO's baseline is optimal. Our results characterize when GRPO's simplicity is theoretically justified and identify the credit assignment bottleneck as the key limitation for multi-step reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript derives GRPO from the policy gradient theorem under the output-only reward regime, showing that identical per-rollout advantages collapse token-level credit assignment to a scalar. It proves this produces gradient sparsity that intensifies during training and an intrinsic rank-2 structure in the gradient matrix arising from the zero-sum constraint on grouped advantages. The claims are supported by SVD analysis of GRPO gradients on Nemotron-4B/GSM8K demonstrating effective rank approximately 2 independent of group size R in {2,4,8}, together with conditions under which the GRPO baseline is optimal.
Significance. If the derivation and empirical signature hold, the work supplies a precise theoretical account of GRPO's credit-assignment bottleneck in multi-step reasoning, clarifying when its critic-free simplicity is justified. The first-principles derivation from the standard policy-gradient theorem, the algebraic rank-2 result, and the concrete SVD experiment constitute clear strengths that advance understanding of relative-baseline methods.
minor comments (2)
- The experimental section would benefit from an explicit statement of how effective rank is computed (e.g., the precise singular-value threshold or cumulative-energy cutoff) to allow direct reproduction of the rank-2 finding.
- Notation for the advantage estimator and the grouped baseline could be introduced earlier with a short table contrasting it to the standard advantage in PPO.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for the positive recommendation to accept. The summary accurately captures the core contributions regarding the derivation of GRPO, the credit-assignment collapse under output-only rewards, the induced gradient sparsity, and the intrinsic rank-2 structure.
Circularity Check
No significant circularity
full rationale
The derivation begins from the standard policy gradient theorem applied under the explicitly stated output-only reward regime. The credit-assignment collapse and rank-2 gradient structure follow directly from the algebraic fact that grouped advantages sum to zero; neither step reduces to a fitted parameter inside the paper nor to a self-citation chain. The SVD analysis on Nemotron-4B/GSM8K is presented as empirical corroboration of the algebraic prediction rather than a self-referential result. The paper is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Policy gradient theorem
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, YK and Wu, Y and Guo, Daya , journal=
-
[4]
arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Advances in Neural Information Processing Systems , pages=
Policy gradient methods for reinforcement learning with function approximation , author=. Advances in Neural Information Processing Systems , pages=
-
[6]
Machine Learning , volume=
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine Learning , volume=
-
[7]
Uncertainty in Artificial Intelligence , pages=
The optimal reward baseline for gradient-based reinforcement learning , author=. Uncertainty in Artificial Intelligence , pages=
-
[8]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
High-dimensional continuous control using generalized advantage estimation , author=. arXiv preprint arXiv:1506.02438 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Ahmadian, Arash and Cremer, Chris and Gall. Back to basics: Revisiting. arXiv preprint arXiv:2402.14740 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Advances in Neural Information Processing Systems , year=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in Neural Information Processing Systems , year=
-
[11]
Let's verify step by step , author=. arXiv preprint arXiv:2305.20050 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Hu, Edward J and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , journal=
-
[13]
Measuring the Intrinsic Dimension of Objective Landscapes
Measuring the intrinsic dimension of objective landscapes , author=. arXiv preprint arXiv:1804.08838 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
arXiv preprint arXiv:2402.16819 , year=
Nemotron-4 15B Technical Report , author=. arXiv preprint arXiv:2402.16819 , year=
-
[15]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.