The Geometry of Updates: Fisher Alignment at Vocabulary Scale
Pith reviewed 2026-06-26 04:48 UTC · model grok-4.3
The pith
In shared-output heads, Fisher alignment is exactly the cosine between kernel mean embeddings in the joint activation-error space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Head Fisher alignment is exactly a cosine between kernel mean embeddings in the joint activation-error space, exposing activation, error, and coupling factors rather than requiring a materialized Fisher matrix; FisherSketch estimates this cosine directly in a single streaming pass.
What carries the argument
The identity that equates head Fisher alignment to the cosine of kernel mean embeddings in activation-error space, together with the FisherSketch streaming estimator that computes it without forming the full matrix.
If this is right
- Enables practical head Fisher alignment computation at vocabulary scale with a 16 KB task signature and 192 KB streaming state.
- Supports training-free source selection among candidate corpora that share a tokenizer but differ in prediction targets.
- Supplies per-task signatures and marginals that diagnose whether LLM task similarity is driven by activations, errors, or coupling.
- Remains informative on Llama-3.1-8B verbalizer-shift experiments where activation similarity alone cannot distinguish tasks.
Where Pith is reading between the lines
- The same signatures could be applied to measure transfer potential across any collection of tasks that share an output head.
- The separation into activation, error, and coupling factors offers a route to targeted interventions that modify only one component.
- Compact signatures stored next to model hashes could enable large-scale task clustering based on update geometry rather than representation geometry.
Load-bearing premise
Models share an identical output head and operate in the activation-dark regime where representation similarity metrics cannot identify transfer.
What would settle it
On a small-vocabulary model pair, compute the exact head Fisher alignment matrix inner product and verify whether it equals the cosine obtained from the kernel mean embeddings in activation-error space.
Figures
read the original abstract
Training-free source selection for LLM families with shared vocabularies arises in scientific string domains such as SMILES, protein, and genomic sequences, where candidate corpora share a tokenizer but differ in prediction targets. This creates an activation-dark regime: representation-similarity metrics can be uninformative without assumptions about label-conditioned error geometry, while classical update-geometry metrics are computationally prohibitive at vocabulary scale. We show that, in a shared-output head setting, representation metrics (e.g., CKA) are non-identifiable for transfer; models can share identical representations yet have orthogonal head updates. The key identity is that head Fisher alignment is exactly a cosine between kernel mean embeddings in the joint activation-error space, exposing activation, error, and coupling factors rather than requiring a materialized Fisher matrix. FisherSketch estimates this cosine directly in a single streaming pass, making K=128,256 head Fisher alignment practical with a 16 KB task signature (m=4096) and a 192 KB per-task streaming state, small enough to store next to a model hash, but encoding transfer-relevant update structure. Beyond source selection, the same signatures and marginals provide a diagnostic instrument for studying whether LLM task similarity is driven by activations, errors, or their coupling; shared-parameter and internal-layer validations, together with Llama-3.1-8B verbalizer-shift experiments, show that FisherSketch remains informative when activation similarity cannot distinguish tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that, in a shared-output head setting, head Fisher alignment equals exactly the cosine between kernel mean embeddings in the joint activation-error space. It introduces FisherSketch, a single-pass streaming estimator that computes this cosine using a sketch of size m=4096, yielding a 16 KB task signature and 192 KB per-task state. The work argues that representation metrics such as CKA are non-identifiable for transfer in the activation-dark regime (identical representations can yield orthogonal head updates), and demonstrates the estimator's utility for source selection and diagnostics via Llama-3.1-8B verbalizer-shift, shared-parameter, and internal-layer experiments.
Significance. If the central identity holds, the result supplies a theoretically exact and memory-efficient instrument for measuring update geometry at vocabulary scale without materializing the Fisher matrix. This is practically relevant for transfer in scientific string domains that share tokenizers but differ in targets. The streaming construction and small signatures enable storage alongside model hashes; the decomposition into activation, error, and coupling factors supplies a diagnostic that activation-only metrics lack. The non-identifiability observation is a useful cautionary contribution.
minor comments (3)
- [Abstract] The abstract states that FisherSketch 'estimates this cosine directly' but does not indicate whether the streaming state update is unbiased or whether bias vanishes with m; a short error analysis or bias bound would strengthen the estimator claim.
- The parameter choices m=4096 and K=128,256 are presented as practical; a brief sensitivity table or reference to approximation guarantees for the kernel mean embedding sketch would clarify robustness.
- The Llama-3.1-8B experiments are summarized at a high level; explicit reporting of the number of tasks, data exclusion rules, and quantitative comparison against CKA baselines would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the work, including the recognition of the central identity, the utility of the streaming estimator, and the cautionary contribution regarding non-identifiability of representation metrics. The recommendation for minor revision is noted; we will address any editorial or minor points in the revised manuscript.
Circularity Check
No significant circularity; central identity is a stated mathematical equivalence derived from definitions
full rationale
The paper's core claim is an exact identity equating head Fisher alignment to a cosine of kernel mean embeddings in activation-error space under the shared-output head setting, together with a streaming estimator derived directly from that cosine definition. No equations reduce a fitted parameter or prediction back to the input data by construction, no self-citation chain is invoked to justify the identity, and no ansatz is smuggled via prior work. The provided material presents the identity as holding exactly in the stated regime rather than as an empirical fit renamed as a result. The streaming estimator (FisherSketch) follows from the cosine definition without additional tuning parameters that would force the outcome. This is the most common honest case of a self-contained derivation against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- m =
4096
- K
axioms (2)
- domain assumption Models operate in a shared-output head setting where representation metrics are non-identifiable for transfer
- domain assumption A single streaming pass suffices to estimate the cosine without materializing the full Fisher matrix
Reference graph
Works this paper leans on
-
[1]
The vectorization leaves diagonal entries unchanged and scales off-diagonals by √ 2: ⟨vecsym(A),vec sym(B)⟩= X i AiiBii + X i<j ( √ 2Aij)( √ 2Bij) =⟨A, B⟩ F
Then for any symmetricA, B: ⟨vecsym(A),vec sym(B)⟩=⟨A, B⟩ F = tr(A⊤B) Proof.For symmetric matrices, the Frobenius inner product is ⟨A, B⟩F = X i AiiBii + 2 X i<j AijBij. The vectorization leaves diagonal entries unchanged and scales off-diagonals by √ 2: ⟨vecsym(A),vec sym(B)⟩= X i AiiBii + X i<j ( √ 2Aij)( √ 2Bij) =⟨A, B⟩ F . B.2. Mean Embedding Represen...
2007
-
[2]
Samplempairs of structured Rademacher vectors(r (j), s(j))with per-layer factorization
-
[3]
For each samplex t: run forward pass to get{a ℓ−1(xt)}L ℓ=1; run backward pass to get{δ ℓ(xt)}L ℓ=1
-
[4]
Compute sketch featuresψ (j)(xt) = (r(j)⊤g(xt))(s(j)⊤g(xt))using (11)
-
[5]
Full-network Fisher alignment is thenA full F (i, j)≈cos(µ i, µj)
Average to get mean embeddingµ k = 1 nk P t ψ(xt)∈R m. Full-network Fisher alignment is thenA full F (i, j)≈cos(µ i, µj). Complexity.Per sample: O(L·d max ·m) for m sketch dimensions. Per task: O(nk ·L·d max ·m) . Cross-task alignment: O(T 2 ·m) . This is independent of parameter count p (linear in hidden sizes and positions), enabling full-network Fisher...
-
[6]
Pad and sign flip:˜e′ ←D⊙˜e O(N)
-
[7]
Compute Hadamard transform:u←H N ˜e′ O(NlogN)
-
[8]
How can we efficiently approximate the natural gradient for optimization?
Gather entries:{u tj }m j=1 O(m) Total:O(NlogN+m) =O(KlogK+m)(sinceN <2K), instead ofO(mK)on the error side. Memory reduction.Dense Rademacher matrices require O(mK) entries (about ∼2 GB if stored asfloat32, or ∼0.5 GB if stored as int8 signs). SRHT requires only O(N) float32 signs for diagonal matrices (D, D′) plus O(m) integers for row indices; since N ...
2012
-
[9]
K-FAC does not study cross-task alignment or representation metrics
Error covariance alignment as the critical factor.While K-FAC uses the approximation Σψ,k ≈M a,k ⊗Γ e,k (Lemma B.2) for computational efficiency, we identify error-covariance alignmentScov(Γe,i,Γ e,j) as the missing factor that explains why CKA can decouple from Fisher alignment. K-FAC does not study cross-task alignment or representation metrics
-
[10]
This is a fundamental limitation independent of any approximation quality
Formal characterization of CKA’s limitation.We prove that CKA (and all representation-only metrics) structurally cannot, in general, access error covariance information (Theorem 3.2). This is a fundamental limitation independent of any approximation quality
-
[11]
K-FAC focuses on optimization convergence, not metric reliability
Quantitative diagnostics for the CKA–Fisher gap.Our analysis exposes measurable drivers of the gap, including the coupling correction ρ (Theorem 4.2), the Kronecker residual δ (Remark 4.4), and the coupling-misalignment term κ (Appendix I). K-FAC focuses on optimization convergence, not metric reliability
-
[12]
This is orthogonal to K-FAC’s optimization focus
Label structure dependence.We show that Scov(Γe,i,Γ e,j) drops to zero for disjoint K-class tasks under the shared output-space embedding (Appendix F), illustrating a failure mode for CKA when label structures differ. This is orthogonal to K-FAC’s optimization focus
-
[13]
K-FAC requires gradient computation for natural gradient steps
Practical estimator (FA-CKA).FA-CKA provides a forward-pass-only estimator of head Fisher alignment without computing gradients or Fisher matrices. K-FAC requires gradient computation for natural gradient steps. H.3. Independence Assumption: Our Analysis vs. K-FAC K-FAC relies on approximate independence between activations and backpropagated errors (deno...
2015
-
[14]
We useλ≈10 −6 for numerical stability
Compute sample covariances with regularization: ˆΣ(λ) i =Z ⊤ i Zi/ni +λI , ˆΣ(λ) j =Z ⊤ j Zj/nj +λI , ˆΣij = (Z(ij) i )⊤Z(ij) j /nij. We useλ≈10 −6 for numerical stability
-
[15]
Compute eigendecompositions and extract the leading rsub-dimensional subspace bases: take ˆUi, ˆUj ∈R d×rsub from the top-rsub eigenvectors of ˆΣi and ˆΣj
-
[16]
Compute regularized whitened cross-covariance: ˆ˜C= ( ˆΣ(λ) i )−1/2 ˆΣij(ˆΣ(λ) j )−1/2
-
[17]
Project onto the shared subspace: ˆCr = ˆU ⊤ i ˆ˜C ˆUj
-
[18]
Define ˆκ(i, j) =∥ ˆCr −Q ⋆∥F √rsub
Solve the orthogonal Procrustes problemQ ⋆ = arg minQ∈O(rsub) ∥ ˆCr −Q∥ F (via SVD). Define ˆκ(i, j) =∥ ˆCr −Q ⋆∥F √rsub . 34 The Geometry of Updates: Fisher Alignment at Vocabulary Scale If the spectrum is simple, sign-aligning the eigenvectors yields Q⋆ =I , so ˆκreduces to ∥ ˆCr −I∥ F /√rsub. Because Q⋆ solves the Procrustes problem, ˆκdepends only on ...
-
[19]
Empirical validation: Head-level validation uses exact Fisher alignment via the kernel identity (Appendix A), while full-network LLM validation uses parameter-subsampled gradients across all layers for computational tractability
-
[20]
=−0.34 , Spearman corr
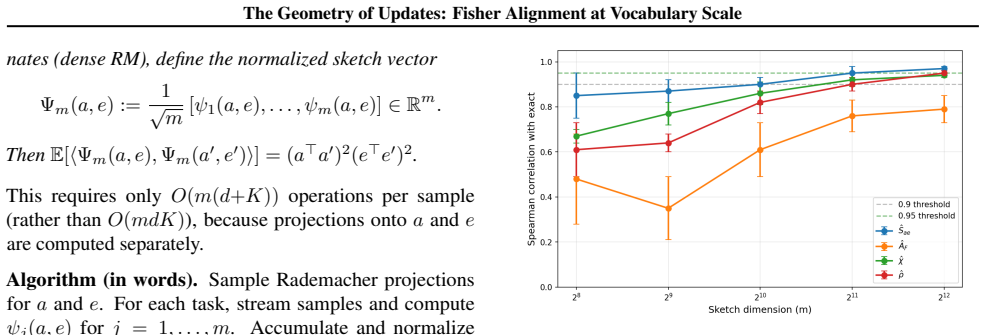
Negative proxy rank correlation on ViT: On ViT-B/16 (n= 40 same-dataset pairs), Pearson Corr(ˆρ, Aproxy) = −0.85, and the proxy is negatively correlated with exact Fisher (Pearson corr. =−0.34 , Spearman corr. =−0.30 ; Table 5), indicating an inverted ranking signal. FA-CKA succeeds (Pearson corr. = 0.79, Spearman corr. = 0.90) because it is validated aga...
2008
-
[21]
Thus all pairwise distances are determined by Ki
Then Di =1diag(K i)⊤ + diag(Ki)1 ⊤ −2K i where 1 is the all-ones vector. Thus all pairwise distances are determined by Ki. Since RDMi is the vector of entries Di,ab fora < b, it is a deterministic function ofK i (and similarly forj). Therefore RSA(Zi, Zj) = CorrSpearman(f(K i), f(K j)), which depends only on(Z i, Zj)through(K i, Kj)and not on errors or gr...
-
[22]
adversarial
Thus if P(∥a∥2 >0∧ ∥e k∥2 > 0)>0(equivalentlyE∥g k∥2 2 >0), then∥F head k ∥F >0fork∈ {i, j}, henceA head F (i, i) =A head F (j, j) = 1. Representation metric blindness.On the shared probe set, the encoder is shared, so Zi =Z j. Any representation-only metric M therefore satisfies M(Z i, Zj) =M(Z i, Zi) (and equals 1 if M is normalized). Yet Ahead F (i, j)...
2021
-
[23]
Collect 200 samples from the new domain
-
[24]
Compute the domain signature via a single forward pass (4.7 seconds on an A100)
-
[25]
No” indicates true, “Yes
Append the signature to the index. No retraining is required—signatures are simply appended. Evaluation.We evaluate on four held-out domains (code, medical, legal, math), each added to an existing 674-domain index. Retrieval accuracy on 30 held-out prompts from each new domain: Table 21.Dynamic addition: retrieval accuracy on held-out prompts from newly a...
2048
-
[26]
the answer is one of {Yes, No}
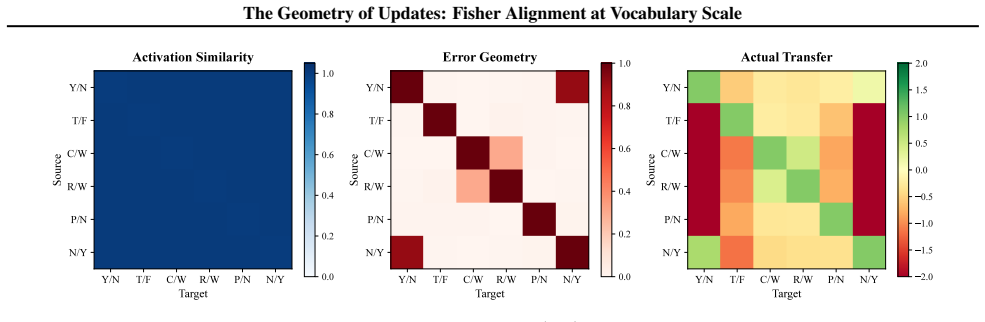
Activation invariance confirmed: Scov(Ma) mean is 1.0013 ± 0.0006 across all runs, confirming that activations are identical. 2.Error divergence confirmed:S cov(Γe)ranges from near-zero to 0.99 across verbalizer pairs. 3.FisherSketch predicts transfer: 66.7% top-1 (3.3×random), 95.7% of oracle. U.8. Flipped Verbalizer Analysis A surprising finding: the fl...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.