MMTM: Tri-Modal Topic Modeling for Long-Form Video via Similarity-Gated Fusion
Pith reviewed 2026-06-29 08:37 UTC · model grok-4.3
The pith
Tri-modal fusion of speech, audio and visual signals produces more coherent and temporally stable topics in long-form video than single-modality baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Joint tri-modal modeling via similarity-gated fusion of speech-recognition, audio, and visual embeddings before BERTopic clustering yields substantially higher-quality topics, measured by lower noise, lower transition rates, higher normalized entropy, and improved Calinski-Harabasz indices, on both German Tagesschau and English NBC broadcast corpora.
What carries the argument
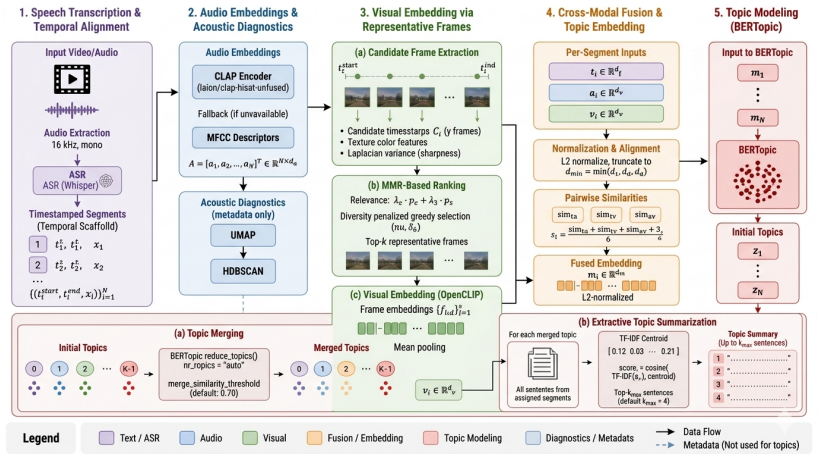
Similarity-gated fusion that merges tri-modal embeddings (ASR text, audio, visual) by weighting each pair according to their pairwise similarity before clustering.
If this is right
- Topics extracted from hour-scale videos become temporally coherent enough for automatic segmentation and indexing without manual boundaries.
- Cluster validity scores rise by five- to twelve-fold across embedding spaces, indicating tighter and more separable topic groups.
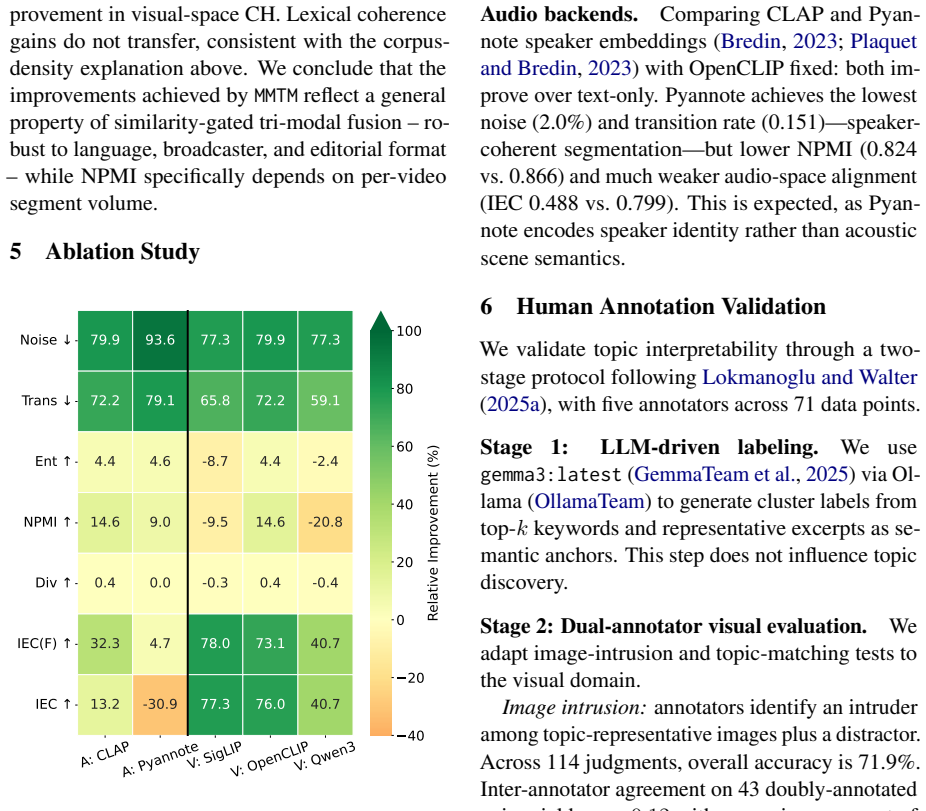
- Lexical coherence measured by NPMI improves on longer German broadcasts but remains corpus-dependent and does not generalize to shorter English ones.
- The released 54-hour human-validated corpus supplies a benchmark for future multimodal topic models.
Where Pith is reading between the lines
- The same gated-fusion pattern could be tested on non-news video domains such as lectures or sports broadcasts to check whether the stability gains persist.
- Replacing the downstream BERTopic step with a different clustering algorithm would isolate how much of the reported improvement is due to fusion versus the choice of clusterer.
- If the fusion gate proves robust, it could be inserted as a pre-processing layer in existing video-retrieval pipelines to reduce topic drift across long recordings.
Load-bearing premise
The similarity gate successfully combines the three modalities without discarding essential information or creating fusion artifacts that harm the subsequent clustering.
What would settle it
Re-running the identical pipeline on the same Tagesschau and NBC videos but replacing the similarity gate with uniform averaging or random weighting and checking whether the reported drops in noise and transition rate disappear.
Figures
read the original abstract
We introduce MMTM, a modular pipeline for topic discovery in long-form video that integrates speech recognition, audio and visual embeddings, and BERTopic clustering through a deterministic similarity-gated fusion. Evaluated cross-lingually on German (Tagesschau) and English (NBC) broadcast news, joint tri-modal modeling substantially improves topic quality: noise drops from 0.27 to 0.06, transition rate from 0.70 to 0.21, and normalized entropy rises from 0.84 to 0.92, indicating more coherent and temporally stable topics. Cluster validity (Calinski-Harabasz) improves by 5-12X across embedding spaces. Lexical coherence (NPMI) rises from 0.77 to 0.86 on German but is corpus-dependent and does not transfer to the shorter NBC broadcasts. We release the pipeline code and a human-validated 54-hour multimodal video topic corpus with dual-annotator visual evaluation and LLM-assisted labeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MMTM, a modular pipeline for topic discovery in long-form video that integrates speech recognition, audio and visual embeddings via a deterministic similarity-gated fusion step before BERTopic clustering. Evaluated on German (Tagesschau) and English (NBC) broadcast news, it reports large gains in custom topic quality metrics (noise 0.27→0.06, transition rate 0.70→0.21, normalized entropy 0.84→0.92) and cluster validity (Calinski-Harabasz 5-12×), with NPMI improving on one corpus but not the other; code and a 54-hour human-validated multimodal corpus are released.
Significance. If the attribution to tri-modal gated fusion holds, the work supplies a practical, reproducible pipeline and corpus for multimodal video topic modeling that could benefit media analysis and long-form content understanding. The deterministic, parameter-free design and dual-annotator validation of the corpus are concrete strengths for downstream use.
major comments (3)
- [§3] §3 (Methods), similarity-gated fusion paragraph: no equation, similarity function, or threshold is supplied for the gate, so it is impossible to verify whether the mechanism integrates complementary signals from speech/audio/visual embeddings or simply discards weaker modalities; this directly affects attribution of the reported metric gains.
- [§4] §4 (Experiments) and Table 2/3: no ablation isolating the gated fusion from single-modality baselines, late fusion, or simple concatenation is presented, leaving open the possibility that gains arise from the strongest single modality rather than joint tri-modal modeling.
- [§4.3] §4.3 (Metrics): the custom metrics (noise, transition rate, normalized entropy) are defined post-hoc on the output clusters; without an explicit validation that they are independent of the fusion step, the claim that tri-modal modeling produces “more coherent and temporally stable topics” rests on potentially circular evaluation.
minor comments (2)
- [Abstract] Abstract and §1: NPMI improvement is stated as corpus-dependent yet the cross-lingual claim is not qualified; clarify the conditions under which lexical coherence transfers.
- [§5] §5 (Conclusion): the released corpus size (54 hours) and annotation protocol are valuable but the dual-annotator agreement statistics are not reported; add them for transparency.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and outline the revisions we will make to improve clarity and strengthen the experimental claims.
read point-by-point responses
-
Referee: [§3] §3 (Methods), similarity-gated fusion paragraph: no equation, similarity function, or threshold is supplied for the gate, so it is impossible to verify whether the mechanism integrates complementary signals from speech/audio/visual embeddings or simply discards weaker modalities; this directly affects attribution of the reported metric gains.
Authors: We agree that the similarity-gated fusion description in §3 requires an explicit mathematical formulation to enable verification and proper attribution of results. The current text describes the approach as deterministic but omits the equation. In the revised manuscript we will insert the precise definition of the similarity function (cosine similarity on L2-normalized embeddings), the gating rule, and the fixed threshold value. revision: yes
-
Referee: [§4] §4 (Experiments) and Table 2/3: no ablation isolating the gated fusion from single-modality baselines, late fusion, or simple concatenation is presented, leaving open the possibility that gains arise from the strongest single modality rather than joint tri-modal modeling.
Authors: Tables 2 and 3 already report single-modality baselines for comparison with the tri-modal pipeline. We nevertheless acknowledge that dedicated ablations contrasting the gated fusion against late fusion and simple concatenation are absent. We will add these controlled comparisons in the revised experimental section to isolate the contribution of the similarity gate. revision: yes
-
Referee: [§4.3] §4.3 (Metrics): the custom metrics (noise, transition rate, normalized entropy) are defined post-hoc on the output clusters; without an explicit validation that they are independent of the fusion step, the claim that tri-modal modeling produces “more coherent and temporally stable topics” rests on potentially circular evaluation.
Authors: The metrics are defined from intrinsic cluster properties (intra-cluster dispersion, temporal transition counts, and entropy of topic distribution) that do not reference the fusion mechanism. To address the circularity concern we will expand §4.3 with an explicit discussion of their independence and will report supplementary correlation with the dual-annotator human labels already collected for the corpus. revision: partial
Circularity Check
No circularity detected; empirical pipeline with external validation
full rationale
The paper describes a modular, deterministic pipeline (speech/audio/visual embeddings + similarity-gated fusion + BERTopic) evaluated on external cross-lingual broadcast datasets (Tagesschau, NBC). Reported gains in noise, transition rate, normalized entropy, Calinski-Harabasz, and NPMI are measured against baselines on held-out data. No equations, parameter fits, self-definitional steps, or load-bearing self-citations appear in the provided text; the similarity gate is presented as a fixed component whose effect is assessed empirically rather than derived from the target metrics. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
David M Blei and Michael I Jordan. 2003. Modeling annotated data. In Proceedings of the 26th annual international ACM SIGIR conference on Research and development in informaion retrieval, pages 127--134
2003
-
[2]
David M Blei, Andrew Y Ng, and Michael I Jordan. 2003. Latent dirichlet allocation. Journal of machine Learning research, 3(Jan):993--1022
2003
-
[3]
Hervé Bredin. 2023. pyannote.audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe . In Proc. INTERSPEECH 2023
2023
-
[4]
Oliver Budzinski, Sophia Gaenssle, and Nadine Lindst \"a dt-Dreusicke. 2021. The battle of YouTube , TV and netflix: an empirical analysis of competition in audiovisual media markets. SN Business & Economics, 1(9):116
2021
-
[5]
Jaime Carbonell and Jade Goldstein. 1998. https://doi.org/10.1145/290941.291025 The use of mmr, diversity-based reranking for reordering documents and producing summaries . In Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR '98, page 335–336, New York, NY, USA. Association for C...
-
[6]
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. 2023. Reproducible scaling laws for contrastive language-image learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2818--2829
2023
- [7]
-
[8]
Zhe Fu, Kanlun Wang, Wangjiaxuan Xin, Lina Zhou, Shi Chen, Yaorong Ge, Daniel Janies, and Dongsong Zhang. 2024. https://arxiv.org/abs/2409.00022 Detecting misinformation in multimedia content through cross-modal entity consistency: A dual learning approach . Preprint, arXiv:2409.00022
-
[9]
GemmaTeam, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, and 197 others. 2025. https://arxiv.org/abs/2503.19786 ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Felipe Gonz \'a lez-Pizarro and Giuseppe Carenini. 2024. Neural multimodal topic modeling: A comprehensive evaluation. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 12159--12172
2024
-
[11]
Maarten Grootendorst. 2022. Bertopic: Neural topic modeling with a class-based tf-idf procedure. arXiv preprint arXiv:2203.05794
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Pengfei Hu, Wenju Liu, Wei Jiang, and Zhanlei Yang. 2014. Latent topic model for audio retrieval. Pattern Recognition, 47(3):1138--1143
2014
-
[13]
Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. 2021. https://doi.org/10.5281/zenodo.5143773 Openclip . If you use this software, please cite it as below
-
[14]
Yangqing Jia, Mathieu Salzmann, and Trevor Darrell. 2011. Learning cross-modality similarity for multinomial data. In 2011 international conference on computer vision, pages 2407--2414. IEEE
2011
-
[15]
Samuel Kim, Shrikanth Narayanan, and Shiva Sundaram. 2009. Acoustic topic model for audio information retrieval. In 2009 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, pages 37--40. IEEE
2009
-
[16]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. 2026. https://arxiv.org/abs/2601.04720 Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking . Preprint, arXiv:2601.04720
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Ayse D. Lokmanoglu and Dror Walter. 2025 a . https://doi.org/10.1080/19312458.2025.2549707 Topic modeling of video and image data: a visual semantic unsupervised approach . Communication Methods and Measures, 19(3):232–279
- [18]
-
[19]
Claudia Malzer and Marcus Baum. 2020. https://doi.org/10.1109/mfi49285.2020.9235263 A hybrid approach to hierarchical density-based cluster selection . In 2020 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), page 223–228. IEEE
-
[20]
Leland McInnes, John Healy, and James Melville. 2020. https://arxiv.org/abs/1802.03426 Umap: Uniform manifold approximation and projection for dimension reduction . Preprint, arXiv:1802.03426
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[21]
Yishu Miao, Lei Yu, and Phil Blunsom. 2016. Neural variational inference for text processing. In International conference on machine learning, pages 1727--1736. PMLR
2016
-
[22]
gemma3 --- ollama.com
OllamaTeam. gemma3 --- ollama.com. https://ollama.com/library/gemma3. [Accessed 12-05-2026]
2026
-
[23]
Youngja Park and Ying Li. 2007. https://doi.org/10.1109/ICSC.2007.31 Semantic analysis for topical segmentation of videos . In International Conference on Semantic Computing (ICSC 2007), pages 161--168
-
[24]
Alexis Plaquet and Hervé Bredin. 2023. Powerset multi-class cross entropy loss for neural speaker diarization . In Proc. INTERSPEECH 2023
2023
-
[25]
Nirmalendu Prakash, Han Wang, Nguyen Khoi Hoang, Ming Shan Hee, and Roy Ka-Wei Lee. 2023. Promptmtopic: Unsupervised multimodal topic modeling of memes using large language models. In Proceedings of the 31st ACM International Conference on Multimedia, pages 621--631
2023
-
[26]
Duangmanee Putthividhy, Hagai T Attias, and Srikantan S Nagarajan. 2010. Topic regression multi-modal latent dirichlet allocation for image annotation. In 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pages 3408--3415. IEEE
2010
-
[27]
Jipeng Qiang, Ping Chen, Tong Wang, and Xindong Wu. 2017. Topic modeling over short texts by incorporating word embeddings. In Pacific-Asia Conference on Knowledge Discovery and Data Mining, pages 363--374. Springer
2017
-
[28]
Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever
Alec Radford, Jong Wook Kim, Chris Hallacy, A. Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning transferable visual models from natural language supervision. In ICML
2021
-
[29]
Alec Radford , Jong Wook Kim , Tao Xu , Greg Brockman , Christine McLeavey , and Ilya Sutskever . 2022. https://doi.org/10.48550/arXiv.2212.04356 Robust Speech Recognition via Large-Scale Weak Supervision . arXiv e-prints, arXiv:2212.04356
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.04356 2022
-
[30]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade W Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, Patrick Schramowski, Srivatsa R Kundurthy, Katherine Crowson, Ludwig Schmidt, Robert Kaczmarczyk, and Jenia Jitsev. 2022. https://openreview.net/forum?id=M3Y74vmsMcY LAION -5b: An open large-scale ...
2022
-
[31]
P E Shrout and J L Fleiss. 1979. Intraclass correlations: uses in assessing rater reliability. Psychol Bull, 86(2):420--428
1979
-
[32]
Akash Srivastava and Charles Sutton. 2017. Autoencoding variational inference for topic models. arXiv preprint arXiv:1703.01488
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. https://arxiv.org/abs/2303.15343 Sigmoid loss for language image pre-training . Preprint, arXiv:2303.15343
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Yin Zheng, Yu-Jin Zhang, and Hugo Larochelle. 2014. Topic modeling of multimodal data: an autoregressive approach. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1370--1377
2014
-
[35]
Qiusha Zhu, Mei-Ling Shyu, and Haohong Wang. 2013. Videotopic: Content-based video recommendation using a topic model. In 2013 IEEE International Symposium on Multimedia, pages 219--222. IEEE
2013
-
[36]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[37]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.