Human vs Machine Mathematical Difficulty on Project Euler: An Experimental Analysis
Pith reviewed 2026-06-26 11:53 UTC · model grok-4.3
The pith
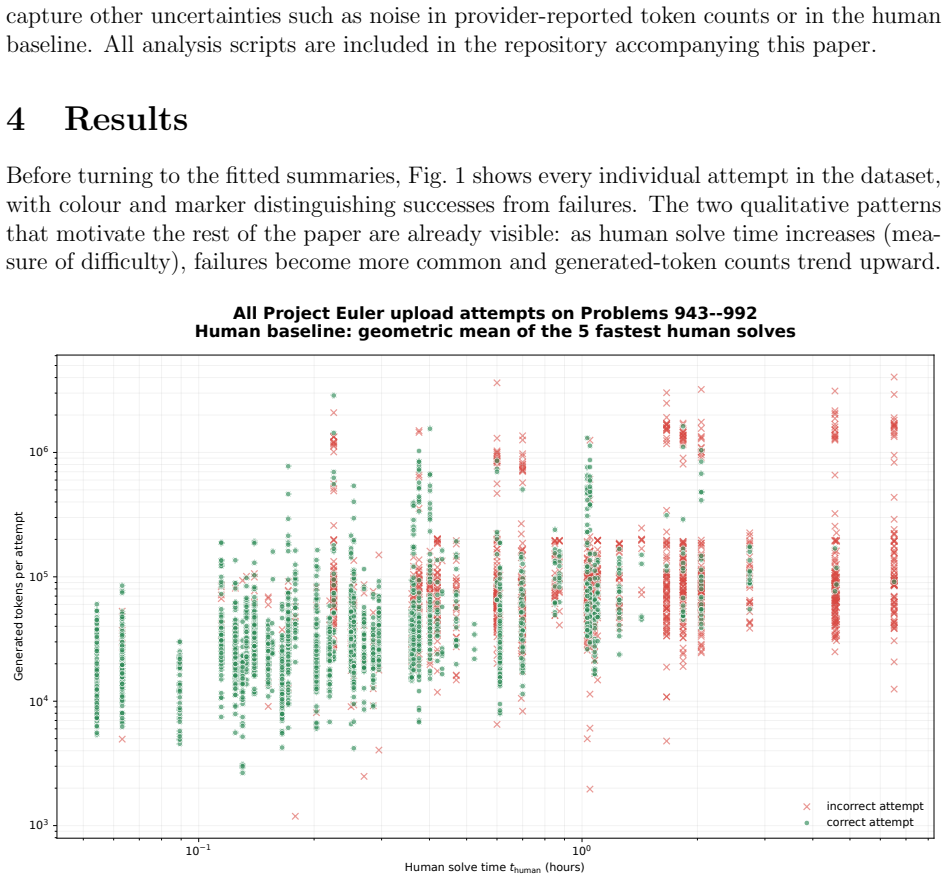
Machine solve effort on Project Euler rises more slowly than human time as difficulty increases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
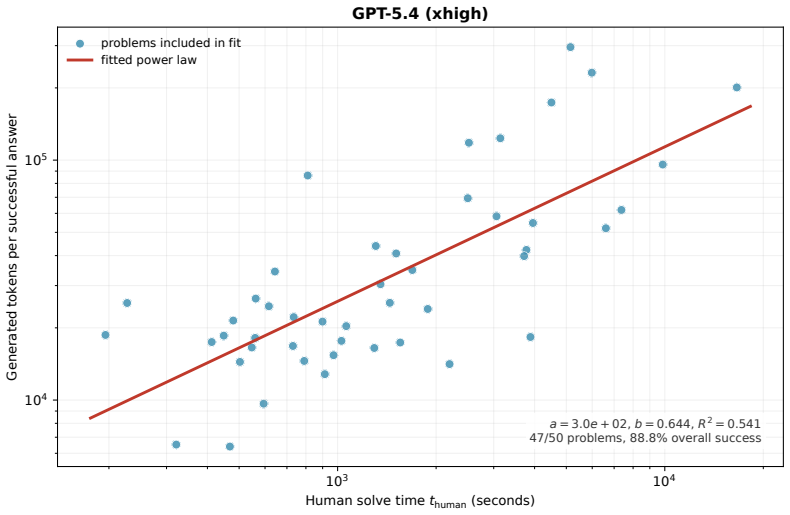
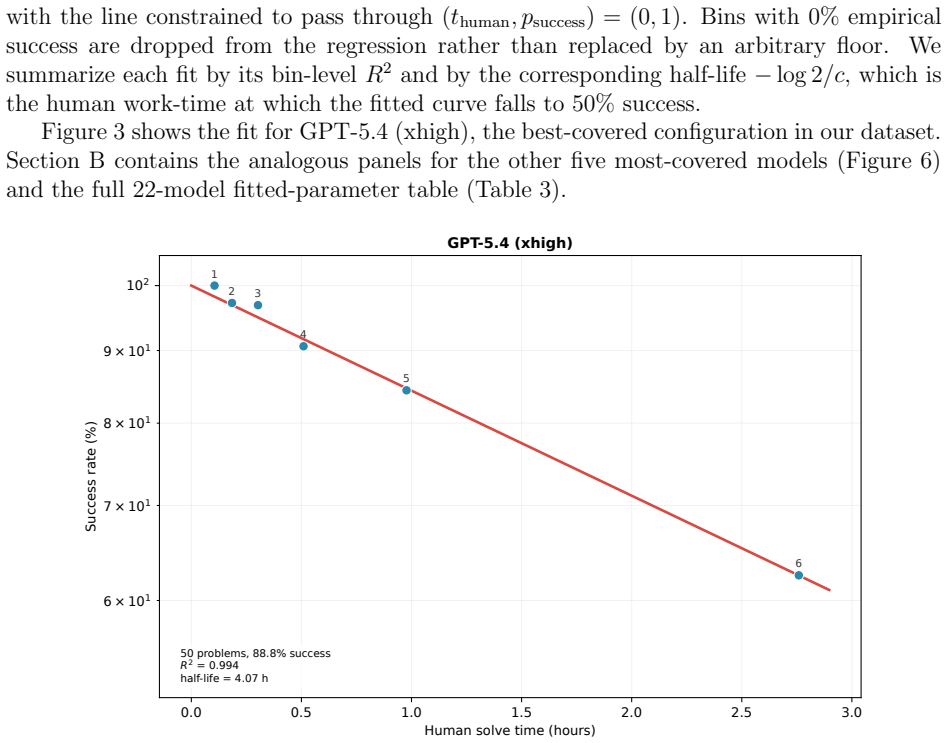
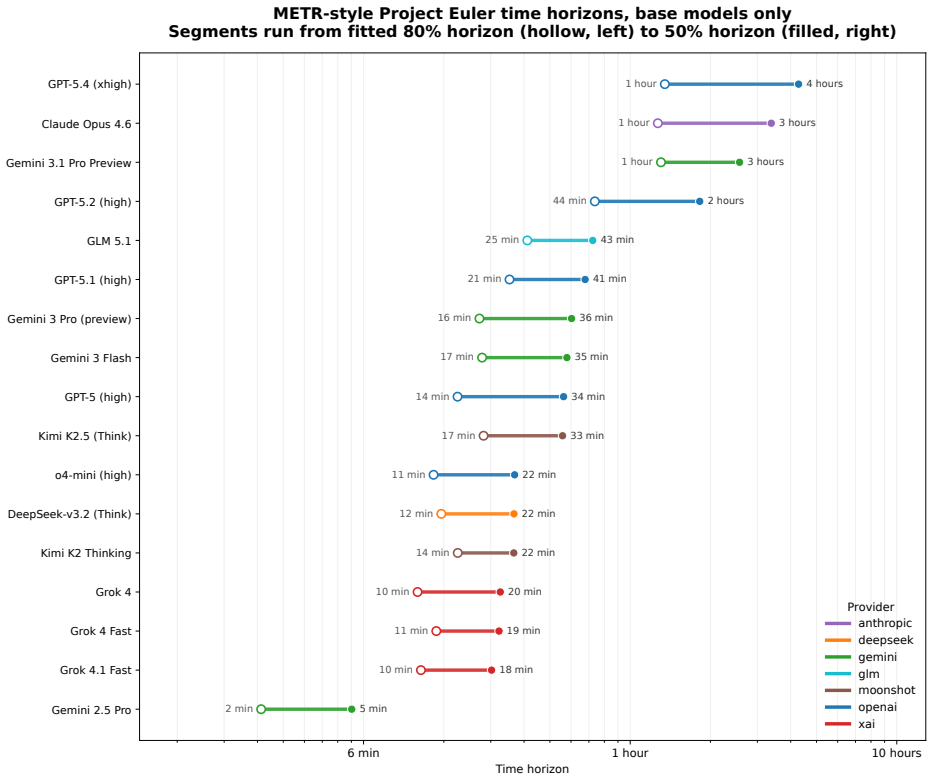
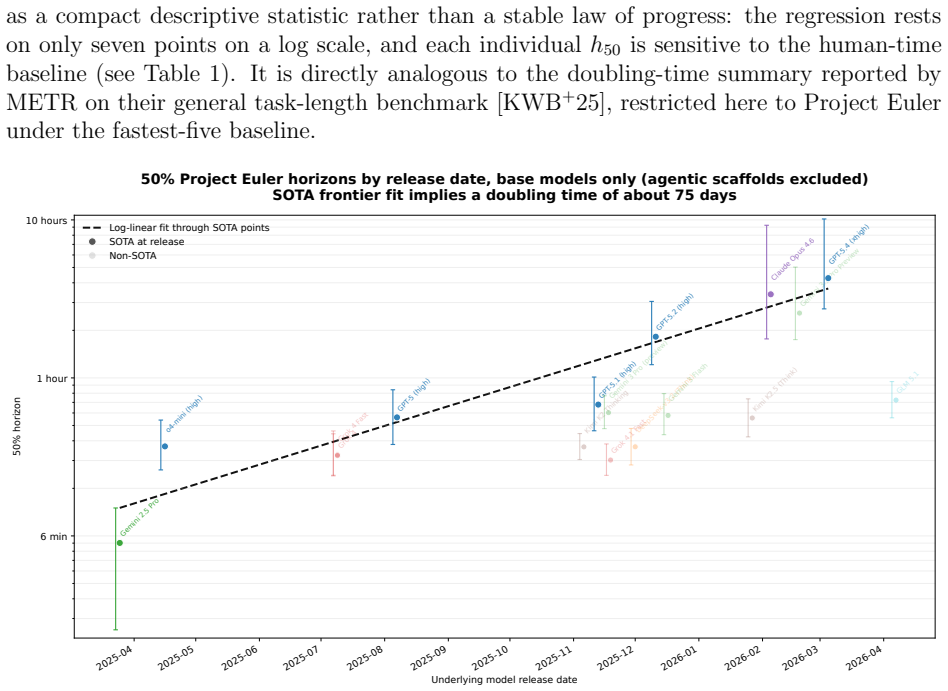
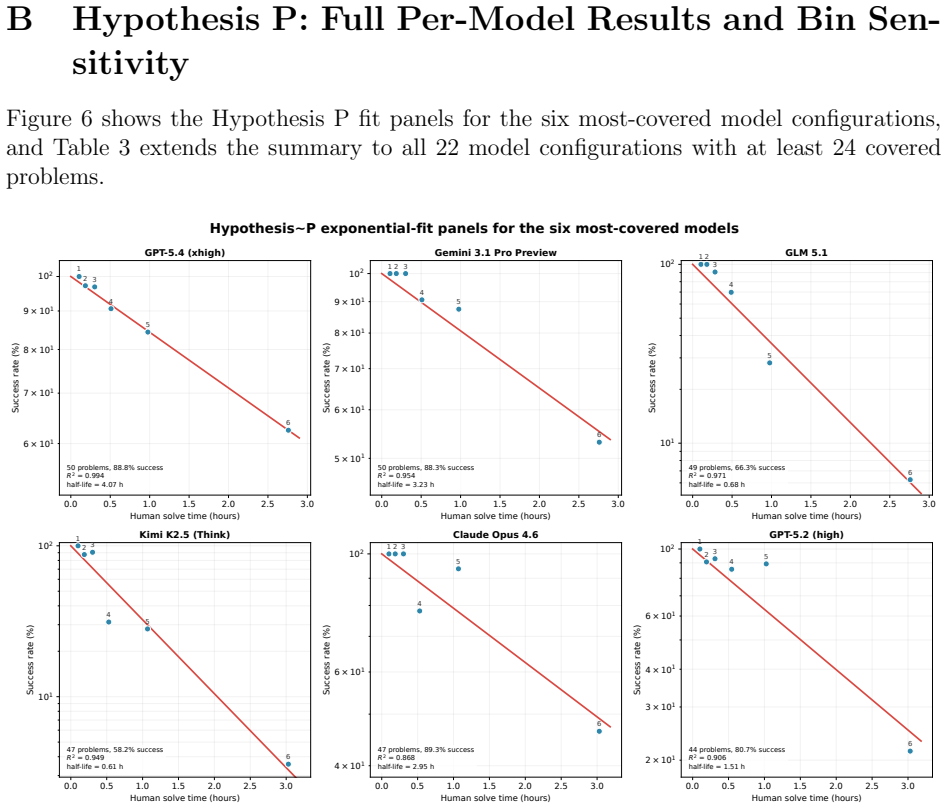
The central claim is that the power-law relation t_machine = a · t_human^b between generated-token cost per successful answer and human solve time produces an exponent b less than 1 for twenty of the twenty-five models with usable fits. The observed scaling therefore does not support the view that machine performance degrades faster than human performance with rising difficulty. In addition, success probability shows reasonable consistency with the form e^{c t_human} when data are aggregated by binning, and logistic fits supply fifty-percent task-length horizons that reach roughly 2.5 to 4.3 hours on the fastest human baseline for the strongest configurations.
What carries the argument
The power-law relation t_machine = a · t_human^b between machine token cost per success and human solve time.
If this is right
- Machine token costs do not increase faster than human times as problems become harder.
- Success probability decreases exponentially with human solve time under the tested model.
- The strongest configurations reach fifty-percent success on problems up to several hours of human time.
- A log-linear trend through frontier performance gives a descriptive doubling time of about seventy-five days for the fifty-percent horizon.
Where Pith is reading between the lines
- The sub-linear exponents could reflect AI systems exploiting patterns that become relatively cheaper on harder instances.
- Repeating the analysis on other collections of computational problems would test whether the pattern holds beyond this set.
- If future models use substantially different internal strategies, the same power-law form might yield different exponents.
Load-bearing premise
Public human solve times on the site give an unbiased measure of difficulty that applies directly to the tested AI systems without major differences in strategy or selection.
What would settle it
New solve-attempt data on a fresh set of problems where the fitted power-law exponents exceed one for most models would contradict the reported scaling result.
Figures
read the original abstract
We study how the effort and success probability of frontier AI systems scale with human difficulty on problems from Project Euler, an online platform of computational mathematics problems. Our dataset, from the MathArena benchmark, consists of 3840 attempts across 50 problems and 26 model configurations, with problem difficulty measured by the site's public human solve times. Motivated by a proposal of Timothy Gowers, we test a power-law relation $t_{\text{machine}} = a \cdot t_{\text{human}}^b$ between generated-token cost per successful answer and human time, and find $b < 1$ for 20 of the 25 models with usable fits, including the strongest base models; this operationalization therefore does not support an earlier prediction that machines scale worse than humans with difficulty. We also investigate whether success probability on the tested problems can be modeled by a simple exponential decay $p_{\text{success}} = e^{c t_{\text{human}}}$, predicting a linear relation between $\log p_{\text{success}}$ and $t_{\text{human}}$. Using a binning approach for data aggregation we find moderate empirical support (median bin-level $R^2 = 0.92$ across the 22 best-covered configurations) for this model. Following METR, we also fit logistic success curves and extract 50\% task-length horizons $h_{50}$; the strongest configurations in our 20 April 2026 snapshot reach roughly $2.5$--$4.3$ hours on our fastest-five human baseline, with a log-linear fit through the state-of-the-art frontier giving a descriptive doubling time of about $75$~days for the SOTA $h_{50}$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes scaling of AI effort and success probability on 50 Project Euler problems using 3840 attempts across 26 model configurations, with difficulty proxied by public human solve times. It tests the power-law t_machine = a · t_human^b (finding b < 1 for 20 of 25 models with usable fits) and the exponential p_success = e^{c t_human} (reporting median bin-level R² = 0.92), plus 50% task horizons h_50 reaching 2.5–4.3 hours for strongest models with ~75-day doubling time.
Significance. If the relations and selection criteria prove robust, the work supplies concrete empirical benchmarks on AI vs. human difficulty scaling in computational math, including fit statistics and horizon estimates that could inform capability forecasting. The dataset size (3840 attempts) and explicit model comparisons are strengths for reproducibility in this domain.
major comments (4)
- [Abstract (power-law results)] The central claim that the power-law operationalization does not support machines scaling worse than humans rests on b < 1 for 20/25 models with 'usable fits' (Abstract). Without explicit rules for what constitutes a usable fit or how unsolved problems are handled (e.g., omitted vs. infinite cost), selection bias is possible: harder problems may be disproportionately excluded for weaker models, leaving an easier subset that mechanically favors b < 1. This is load-bearing for the headline result.
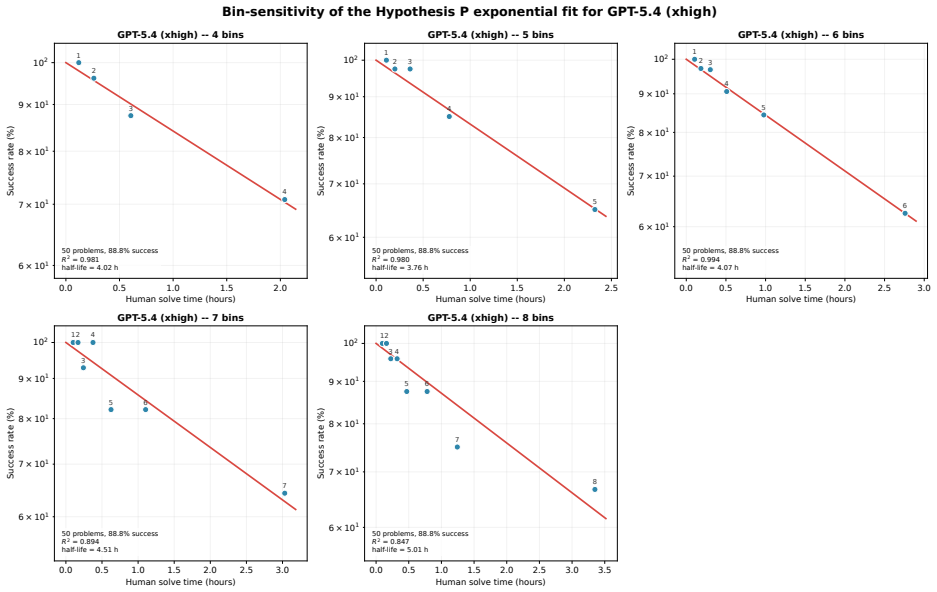
- [Abstract (exponential success model)] The exponential model reports moderate support via median bin-level R² = 0.92 across 22 configurations (Abstract), yet the text provides no information on data exclusion rules, error estimation, or sensitivity to binning choices. This prevents full verification of the empirical claims from the given details.
- [Abstract (model fitting)] Both the power-law parameters (a, b) and exponential constant c are obtained by direct fitting to the same experimental data (Abstract). The reported 'support' therefore reflects in-sample fit quality rather than any independent or out-of-sample prediction, raising circularity concerns for the model evaluations.
- [Abstract (dataset and difficulty measure)] The weakest assumption—that public human solve times form an unbiased, transferable measure of intrinsic difficulty applicable to the tested AI systems without strategy or selection differences—is not tested or bounded in the reported analysis, yet it underpins both the power-law and exponential relations.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract (power-law results)] The central claim that the power-law operationalization does not support machines scaling worse than humans rests on b < 1 for 20/25 models with 'usable fits' (Abstract). Without explicit rules for what constitutes a usable fit or how unsolved problems are handled (e.g., omitted vs. infinite cost), selection bias is possible: harder problems may be disproportionately excluded for weaker models, leaving an easier subset that mechanically favors b < 1. This is load-bearing for the headline result.
Authors: We define usable fits as regressions performed on models that successfully solved at least 8 problems (ensuring sufficient data points for stable estimation of a and b). Unsolved problems are assigned the maximum observed token cost across all attempts rather than omitted or treated as infinite. We will add this explicit definition and the minimum-problem threshold to both the abstract and the methods section. We will also report sensitivity checks using alternative thresholds (e.g., 5 and 10 solved problems) to address selection-bias concerns directly. revision: yes
-
Referee: [Abstract (exponential success model)] The exponential model reports moderate support via median bin-level R² = 0.92 across 22 configurations (Abstract), yet the text provides no information on data exclusion rules, error estimation, or sensitivity to binning choices. This prevents full verification of the empirical claims from the given details.
Authors: We will expand the methods section to specify: (i) exclusion of configurations with fewer than 5 attempted problems, (ii) equal-width binning on log(t_human) with a default of 6 bins, (iii) bootstrap-derived standard errors on the per-bin success rates, and (iv) sensitivity results for 4–8 bins. These details will also be summarized briefly in the abstract. revision: yes
-
Referee: [Abstract (model fitting)] Both the power-law parameters (a, b) and exponential constant c are obtained by direct fitting to the same experimental data (Abstract). The reported 'support' therefore reflects in-sample fit quality rather than any independent or out-of-sample prediction, raising circularity concerns for the model evaluations.
Authors: The reported R² values and parameter estimates are explicitly descriptive characterizations of the observed data rather than claims of predictive validity or out-of-sample generalization. We will revise the abstract wording to emphasize that the exponential model is evaluated for its descriptive adequacy on the collected attempts, not as a validated predictive model. No change to the fitting procedure itself is required. revision: partial
-
Referee: [Abstract (dataset and difficulty measure)] The weakest assumption—that public human solve times form an unbiased, transferable measure of intrinsic difficulty applicable to the tested AI systems without strategy or selection differences—is not tested or bounded in the reported analysis, yet it underpins both the power-law and exponential relations.
Authors: We agree this is a central and untested modeling assumption. We will add a dedicated limitations subsection that explicitly discusses potential mismatches arising from differing solution strategies between humans and AI, notes that human solve times serve as a convenient public proxy, and outlines possible future validation approaches using alternative difficulty metrics. revision: yes
Circularity Check
No circularity: empirical fitting of models to experimental data
full rationale
The paper performs an experimental analysis by fitting power-law and exponential models directly to observed data on AI solve costs and human times across the 50 problems. The reported results (b < 1 for 20/25 models; median R^2 = 0.92 for binned linear relation) are the direct numerical outcomes of those fits and the associated selection of 'usable' cases; no derivation chain, first-principles claim, or independent prediction is asserted that reduces by construction to the fitted parameters themselves. No self-citation, ansatz smuggling, or renaming of known results appears in the provided text. The work is therefore self-contained as standard empirical model evaluation.
Axiom & Free-Parameter Ledger
free parameters (3)
- a
- b
- c
axioms (2)
- domain assumption Human solve times reported on Project Euler are an appropriate scalar measure of problem difficulty for both humans and the tested AI systems.
- domain assumption The power-law functional form is a suitable model for relating machine token cost to human time.
Reference graph
Works this paper leans on
-
[1]
MathArena: Evaluating LLMs on Uncontaminated Math Competitions
Mislav Balunovi\' c , Jasper Dekoninck, Ivo Petrov, Nikola Jovanovi\' c , and Martin Vechev. MathArena: Evaluating LLMs on Uncontaminated Math Competitions https://arxiv.org/abs/2505.23281. Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Wei-Lin Chen, Liqian Peng, Tian Tan, Chao Zhao, Blake JianHang Chen, Ziqian Lin, Alec Go, and Yu Meng. Think Deep, Not Just Long: Measuring LLM Reasoning Effort via Deep-Thinking Tokens https://arxiv.org/abs/2602.13517, 2026
-
[3]
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs https://arxiv.org/abs/2412.21187, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Jasper Dekoninck, Ivo Petrov, Kristian Minchev, Mislav Balunovic, Martin Vechev, Miroslav Marinov, Maria Drencheva, Lyuba Konova, Milen Shumanov, Kaloyan Tsvetkov, Nikolay Drenchev, Lazar Todorov, Kalina Nikolova, Nikolay Georgiev, Vanesa Kalinkova, and Margulan Ismoldayev. The Open Proof Corpus: A Large-Scale Study of LLM-Generated Mathematical Proofs ht...
-
[5]
Bradley Efron and Robert J. Tibshirani. An Introduction to the Bootstrap https://doi.org/10.1201/9780429246593 , volume 57 of Monographs on Statistics and Applied Probability . Chapman & Hall/CRC, New York, 1993
-
[6]
Inverse Scaling in Test-Time Compute https://arxiv.org/abs/2507.14417, 2025
Aryo Pradipta Gema, Alexander H \"a gele, Runjin Chen, Andy Arditi, Jacob Goldman-Wetzler, Kit Fraser-Taliente, Henry Sleight, Linda Petrini, Julian Michael, Beatrice Alex, Pasquale Minervini, Yanda Chen, Joe Benton, and Ethan Perez. Inverse Scaling in Test-Time Compute https://arxiv.org/abs/2507.14417, 2025
-
[7]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset https://arxiv.org/abs/2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Me, Myself, and AI: The Situational Awareness Dataset (SAD) for LLMs
Thomas Kwa, Ben West, Joel Becker, Amy Deng, Katharyn Garcia, Max Hasin, Sami Jawhar, Megan Kinniment, Nate Rush, Sydney Von Arx, Ryan Bloom, Thomas Broadley, Haoxing Du, Brian Goodrich, Nikola Jurkovic, Luke Harold Miles, Seraphina Nix, Tao Lin, Neev Parikh, David Rein, Lucas Jun Koba Sato, Hjalmar Wijk, Daniel M. Ziegler, Elizabeth Barnes, and Lawrence ...
-
[9]
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quantitative reasoning problems with language models https://dl.acm.org/doi/10.5555/3600270.3600548. Advances in neural information processing systems , 35:3843--3857, 2022
-
[10]
MathArena: Agentic Euler https://matharena.ai/euler/
MathArena . MathArena: Agentic Euler https://matharena.ai/euler/. https://matharena.ai/euler/, 2026. Accessed 2026-04-21
2026
-
[11]
Project Euler https://projecteuler.net/
Project Euler . Project Euler https://projecteuler.net/. https://projecteuler.net/, 2026. Accessed 2026-04-21
2026
-
[12]
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Yang Sui, Yu-Neng Chuang, Guanchu Wang, Jiamu Zhang, Tianyi Zhang, Jiayi Yuan, Hongyi Liu, Andrew Wen, Shaochen Zhong, Na Zou, Hanjie Chen, and Xia Hu. Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models https://arxiv.org/abs/2503.16419, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Jinyan Su, Jennifer Healey, Preslav Nakov, and Claire Cardie. Between Underthinking and Overthinking: An Empirical Study of Reasoning Length and Correctness in LLMs https://arxiv.org/abs/2505.00127, 2025
-
[14]
Gaurav Srivastava, Aafiya Hussain, Sriram Srinivasan, and Xuan Wang. Do LLMs Overthink Basic Math Reasoning? Benchmarking the Accuracy-Efficiency Tradeoff in Language Models https://arxiv.org/abs/2507.04023, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Parshin Shojaee, Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio, and Mehrdad Farajtabar. The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity https://arxiv.org/abs/2506.06941, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Ai-assisted generation of difficult math questions
Vedant Shah, Dingli Yu, Kaifeng Lyu, Simon Park, Jiatong Yu, Yinghui He, Nan Rosemary Ke, Michael Mozer, Yoshua Bengio, Sanjeev Arora, and Anirudh Goyal. AI-Assisted Generation of Difficult Math Questions https://arxiv.org/abs/2407.21009, 2025
-
[17]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-Consistency Improves Chain of Thought Reasoning in Language Models https://arxiv.org/abs/2203.11171, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.