CasaMaestro: Multi-View Panoramas for House-Scale 3D Reconstruction
Pith reviewed 2026-07-01 06:27 UTC · model grok-4.3
The pith
CasaMaestro reconstructs entire houses in metric 3D from 20-50 panoramic views by directly predicting depth and camera poses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
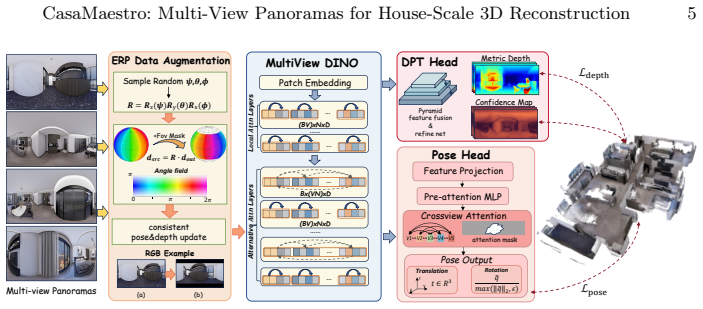
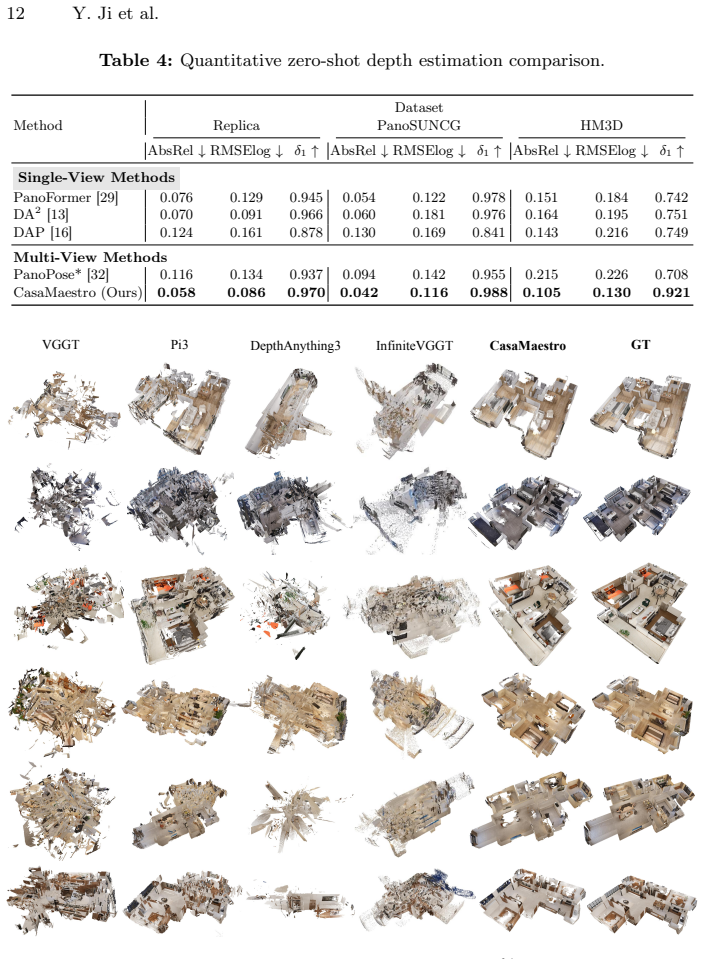
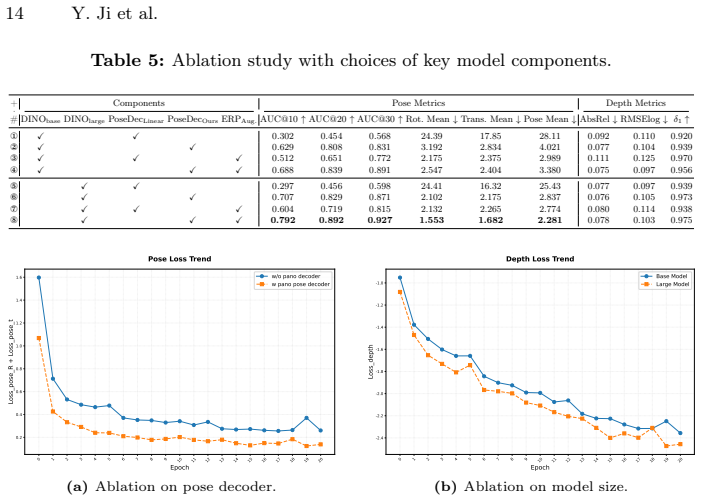
CasaMaestro is a feedforward model that takes only twenty to fifty sparse multi-view indoor panoramas as input and directly predicts metric depth along with camera poses, allowing fast point-cloud reconstruction of the entire house with full coverage. It is the first model that supports house-scale reconstruction with multi-view panoramas and produces high quality results in both real-world and synthetic scenes as a foundation for closed-loop simulation.
What carries the argument
The feedforward network that maps sparse panoramic inputs directly to metric depth maps and camera poses for point-cloud output.
If this is right
- Full house coverage becomes possible with far fewer images than traditional pinhole pipelines require.
- Drift from incremental alignment is avoided through direct prediction rather than chained steps.
- Fast acquisition of complete 3D indoor assets supports navigation and interaction tasks in embodied AI.
- High-quality results hold across both real-world captures and synthetic test scenes.
Where Pith is reading between the lines
- The direct prediction approach could support incremental updates when new panoramas are added without restarting the full reconstruction.
- Similar sparse panoramic inputs might reduce capture time in practical home scanning for robotics or virtual models.
- The method opens a path to combining panoramic depth with other sensors for improved accuracy in complex layouts.
Load-bearing premise
A feedforward network trained on panoramas can generate accurate metric depths and poses across whole multi-room houses without the alignment drift that builds in sequential pinhole pipelines.
What would settle it
Running the model on a real multi-room house with 20-50 panoramas and measuring large metric scale errors or visible drift in the resulting point cloud compared to ground truth.
Figures



read the original abstract
The rise of home-deployed embodied AI systems is driving a growing need for fast, metric 3D reconstruction of residential spaces to support navigation, interaction, and long-horizon task execution. However, the commonly used pinhole-camera 3D reconstruction pipelines struggle to model large indoor residences efficiently due to their limited field of view, to which achieving full coverage across multiple rooms often requires thousands of images and incurs drift from long chains of incremental alignment. In this work, we present CasaMaestro (Spanish words meaning ``house'' and ``master''), a feedforward model that can take only twenty to fifty sparse multi-view indoor panoramas as input and directly predicts metric depth along with camera poses, allowing fast point-cloud reconstruction of the entire house with full coverage. CasaMaestro is the first model that supports house-scale reconstruction with multi-view panoramas. Experiments show that CasaMaestro can robustly provide high quality results in both real-world and synthetic scenes, which can serve as a strong foundation for acquiring house-scale 3D indoor assets to be applied in close-loop simulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CasaMaestro, a feedforward model that accepts 20–50 sparse multi-view indoor panoramas and directly outputs metric depth maps together with camera poses, enabling rapid point-cloud reconstruction of entire multi-room houses. It claims to be the first such model for house-scale panoramic reconstruction and reports robust high-quality results on both real-world and synthetic scenes, positioning the method as a foundation for embodied-AI simulation assets.
Significance. If the performance claims hold, the work would address a practical bottleneck in indoor reconstruction by replacing long incremental SfM pipelines (thousands of pinhole images, drift accumulation) with a single forward pass on panoramic inputs, potentially enabling scalable metric 3D assets for navigation and long-horizon tasks.
major comments (2)
- [Abstract] Abstract: the central claim that the model 'directly predicts metric depth along with camera poses' and achieves 'full coverage' without drift is load-bearing, yet the abstract supplies neither the network architecture, the training objective, nor any quantitative metrics, baselines, or error analysis; without these elements the claim cannot be evaluated.
- [Abstract] Abstract (and implied method section): the assertion that a feedforward network resolves pose ambiguities and scale across multi-room houses from only 20–50 views with minimal overlap requires evidence that global consistency is enforced (e.g., via joint pose-depth prediction, global loss terms, or architectural inductive biases); absent any description of how per-view predictions are coupled, the implicit global-optimization claim rests on unstated assumptions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that strengthening the abstract with additional technical and quantitative details will better support evaluation of the central claims. We will revise the abstract in the next version and ensure the method description explicitly highlights the mechanisms for global consistency.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the model 'directly predicts metric depth along with camera poses' and achieves 'full coverage' without drift is load-bearing, yet the abstract supplies neither the network architecture, the training objective, nor any quantitative metrics, baselines, or error analysis; without these elements the claim cannot be evaluated.
Authors: We acknowledge that the abstract, as a concise summary, omits these specifics and that including them would aid immediate evaluation. In revision, we will expand the abstract to note the multi-view transformer architecture, the joint depth-pose training objective with global consistency terms, and key results (e.g., depth MAE and pose error versus incremental SfM baselines on synthetic and real house-scale scenes). Full architecture, objective, metrics, and error analysis remain in Sections 3 and 4. revision: yes
-
Referee: [Abstract] Abstract (and implied method section): the assertion that a feedforward network resolves pose ambiguities and scale across multi-room houses from only 20–50 views with minimal overlap requires evidence that global consistency is enforced (e.g., via joint pose-depth prediction, global loss terms, or architectural inductive biases); absent any description of how per-view predictions are coupled, the implicit global-optimization claim rests on unstated assumptions.
Authors: Section 3 details a shared multi-view transformer that processes all panoramas jointly via cross-view attention, coupling per-view depth and pose predictions. Global consistency is enforced by a composite loss combining per-view metric depth supervision with a global pose-alignment term that penalizes drift across the full set of views. This learned inductive bias, trained on large-scale multi-room data, enables the feedforward model to resolve scale and ambiguities. We will add a brief clause to the abstract summarizing the joint prediction and global loss to make this explicit. revision: yes
Circularity Check
No circularity: empirical model claims with no derivations or self-referential reductions
full rationale
The manuscript describes a feedforward neural network trained to predict metric depth and poses from sparse panoramas. No equations, parameter-fitting steps, uniqueness theorems, or ansatzes appear in the provided text. Claims rest on empirical performance rather than any derivation chain that could reduce to its own inputs by construction. No self-citation load-bearing elements or fitted-input-called-prediction patterns are present, so the result is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, J., Huang, L., Guo, J., Gong, W., Li, Y., Guo, Y.: 360-gs: Layout-guided panoramicgaussiansplattingforindoorroaming.In:2025InternationalConference on 3D Vision (3DV). pp. 1042–1053. IEEE (2025)
2025
-
[2]
IEEE Transactions on Image Processing33, 2936–2949 (2024)
Bai, J., Qin, H., Lai, S., Guo, J., Guo, Y.: Glpanodepth: Global-to-local panoramic depth estimation. IEEE Transactions on Image Processing33, 2936–2949 (2024)
2024
-
[3]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Cabon, Y., Stoffl, L., Antsfeld, L., Csurka, G., Chidlovskii, B., Revaud, J., Leroy, V.: Must3r: Multi-view network for stereo 3d reconstruction. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 1050–1060 (2025)
2025
-
[4]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Cao, Z., Zhu, J., Zhang, W., Ai, H., Bai, H., Zhao, H., Wang, L.: Panda: To- wards panoramic depth anything with unlabeled panoramas and mobius spatial augmentation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 982–992 (2025)
2025
-
[5]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Chen, Z., Wu, C., Shen, Z., Zhao, C., Ye, W., Feng, H., Ding, E., Zhang, S.H.: Splatter-360: Generalizable 360 gaussian splatting for wide-baseline panoramic im- ages. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21590–21599 (2025)
2025
-
[6]
Deng, K., Ti, Z., Xu, J., Yang, J., Xie, J.: Vggt-long: Chunk it, loop it, align it – pushing vggt’s limits on kilometer-scale long rgb sequences (2025),https: //arxiv.org/abs/2507.16443
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
arXiv preprint arXiv:2412.08376 (2024)
Dong, S., Wang, S., Liu, S., Cai, L., Fan, Q., Kannala, J., Yang, Y.: Reloc3r: Large-scale training of relative camera pose regression for generalizable, fast, and accurate visual localization. arXiv preprint arXiv:2412.08376 (2024)
-
[8]
In: 2025 International Conference on 3D Vision (3DV)
Duisterhof, B.P., Zust, L., Weinzaepfel, P., Leroy, V., Cabon, Y., Revaud, J.: Mast3r-sfm: a fully-integrated solution for unconstrained structure-from-motion. In: 2025 International Conference on 3D Vision (3DV). pp. 1–10. IEEE (2025)
2025
-
[9]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Elflein, S., Zhou, Q., Leal-Taixé, L.: Light3r-sfm: Towards feed-forward structure- from-motion. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16774–16784 (2025)
2025
-
[10]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Guo,Y.,Garg,S.,Miangoleh,S.M.H.,Huang,X.,Ren,L.:Depthanycamera:Zero- shot metric depth estimation from any camera. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 26996–27006 (2025)
2025
-
[11]
Keetha, N., Müller, N., Schönberger, J., Porzi, L., Zhang, Y., Fischer, T., Knapitsch, A., Zauss, D., Weber, E., Antunes, N., Luiten, J., Lopez-Antequera, M., Bulò, S.R., Richardt, C., Ramanan, D., Scherer, S., Kontschieder, P.: MapA- nything: Universal feed-forward metric 3D reconstruction (2025), arXiv preprint arXiv:2509.13414
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
In: European Conference on Computer Vision
Leroy, V., Cabon, Y., Revaud, J.: Grounding image matching in 3d with mast3r. In: European Conference on Computer Vision. pp. 71–91. Springer (2024)
2024
-
[13]
arXiv preprint arXiv:2509.26618 (2025) 16 Y
Li, H., Zheng, W., He, J., Liu, Y., Lin, X., Yang, X., Chen, Y.C., Guo, C.: Da2: Depth anything in any direction. arXiv preprint arXiv:2509.26618 (2025) 16 Y. Ji et al
-
[14]
Li, L., Wu, Y., Li, X., Wang, L., Rao, T., Zhou, J., Pan, C., Hui, X.: Re- alsee3d: A large-scale multi-view rgb-d dataset of indoor scenes (version 1.0) (2025).https://doi.org/10.5281/zenodo.17826243,https://doi.org/10. 5281/zenodo.17826243
-
[15]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J.H., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Lin, X., Song, M., Zhang, D., Lu, W., Li, H., Du, B., Yang, M.H., Nguyen, T., Qi, L.: Depth any panoramas: A foundation model for panoramic depth estimation. arXiv preprint arXiv:2512.16913 (2025)
-
[17]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, J., Xu, Y., Li, S., Li, J.: Estimating depth of monocular panoramic image with teacher-student model fusing equirectangular and spherical representations. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1262–1271 (2024)
2024
-
[18]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Murai, R., Dexheimer, E., Davison, A.J.: Mast3r-slam: Real-time dense slam with 3d reconstruction priors. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16695–16705 (2025)
2025
-
[19]
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez,P.,Haziza,D.,Massa,F.,El-Nouby,A.,Howes,R.,Huang,P.Y.,Xu,H., Sharma, V., Li, S.W., Galuba, W., Rabbat, M., Assran, M., Ballas, N., Synnaeve, G., Misra, I., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: Dinov2: Learning robust visual features without ...
2023
-
[20]
In: Proceedings of the Computer Vi- sion and Pattern Recognition Conference
Pataki, Z., Sarlin, P.E., Schönberger, J.L., Pollefeys, M.: Mp-sfm: Monocular sur- face priors for robust structure-from-motion. In: Proceedings of the Computer Vi- sion and Pattern Recognition Conference. pp. 21891–21901 (2025)
2025
-
[21]
arXiv preprint arXiv:2210.10414 (2022)
Peng, C.H., Zhang, J.: High-resolution depth estimation for 360-degree panora- mas through perspective and panoramic depth images registration. arXiv preprint arXiv:2210.10414 (2022)
-
[22]
In: IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR) (2025)
Piccinelli, L., Sakaridis, C., Segu, M., Yang, Y.H., Li, S., Abbeloos, W., Van Gool, L.: UniK3D: Universal camera monocular 3d estimation. In: IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR) (2025)
2025
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Pintore, G., Agus, M., Almansa, E., Schneider, J., Gobbetti, E.: Slicenet: deep dense depth estimation from a single indoor panorama using a slice-based repre- sentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11536–11545 (2021)
2021
-
[24]
Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
Ramakrishnan, S.K., Gokaslan, A., Wijmans, E., Maksymets, O., Clegg, A., Turner, J., Undersander, E., Galuba, W., Westbury, A., Chang, A.X., et al.: Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for em- bodied ai. arXiv preprint arXiv:2109.08238 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[25]
ArXiv preprint (2021)
Ranftl, R., Bochkovskiy, A., Koltun, V.: Vision transformers for dense prediction. ArXiv preprint (2021)
2021
-
[26]
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) (2020)
Ranftl, R., Lasinger, K., Hafner, D., Schindler, K., Koltun, V.: Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) (2020)
2020
-
[27]
In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision
Ren, J., Xiang, M., Zhu, J., Dai, Y.: Panosplatt3r: Leveraging perspective pretrain- ing for generalized unposed wide-baseline panorama reconstruction. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision. pp. 28959– 28969 (2025)
2025
-
[28]
FastVGGT: Training-Free Acceleration of Visual Geometry Transformer
Shen, Y., Zhang, Z., Qu, Y., Cao, L.: Fastvggt: Training-free acceleration of visual geometry transformer. arXiv preprint arXiv:2509.02560 (2025) CasaMaestro: Multi-View Panoramas for House-Scale 3D Reconstruction 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
In: European Conference on Com- puter Vision
Shen, Z., Lin, C., Liao, K., Nie, L., Zheng, Z., Zhao, Y.: Panoformer: panorama transformer for indoor 360◦ depth estimation. In: European Conference on Com- puter Vision. pp. 195–211. Springer (2022)
2022
-
[30]
The Replica Dataset: A Digital Replica of Indoor Spaces
Straub, J., Whelan, T., Ma, L., Chen, Y., Wijmans, E., Green, S., Engel, J.J., Mur-Artal, R., Ren, C., Verma, S., et al.: The replica dataset: A digital replica of indoor spaces. arXiv preprint arXiv:1906.05797 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[31]
Tang,Z.,Fan,Y.,Wang,D.,Xu,H.,Ranjan,R.,Schwing,A.,Yan,Z.:Mv-dust3r+: Single-stage scene reconstruction from sparse views in 2 seconds. arXiv preprint arXiv:2412.06974 (2024)
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Tu, D., Cui, H., Zheng, X., Shen, S.: Panopose: Self-supervised relative pose es- timation for panoramic images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20009–20018 (2024)
2024
-
[33]
In: Asian Conference on Computer Vision
Wang, F.E., Hu, H.N., Cheng, H.T., Lin, J.T., Yang, S.T., Shih, M.L., Chu, H.K., Sun, M.: Self-supervised learning of depth and camera motion from 360 videos. In: Asian Conference on Computer Vision. pp. 53–68. Springer (2018)
2018
-
[34]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition
Wang, F.E., Yeh, Y.H., Sun, M., Chiu, W.C., Tsai, Y.H.: Bifuse: Monocular 360 depth estimation via bi-projection fusion. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition. pp. 462–471 (2020)
2020
-
[35]
IEEE transactions on pattern analysis and machine intelligence45(5), 5448–5460 (2022)
Wang, F.E., Yeh, Y.H., Tsai, Y.H., Chiu, W.C., Sun, M.: Bifuse++: Self-supervised and efficient bi-projection fusion for 360 depth estimation. IEEE transactions on pattern analysis and machine intelligence45(5), 5448–5460 (2022)
2022
-
[36]
3D Reconstruction with Spatial Memory
Wang, H., Agapito, L.: 3d reconstruction with spatial memory. arXiv preprint arXiv:2408.16061 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (2025)
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (2025)
2025
-
[38]
Advances in Neural Information Processing Systems37, 127739–127764 (2024)
Wang, N.H.A., Liu, Y.L.: Depth anywhere: Enhancing 360 monocular depth esti- mation via perspective distillation and unlabeled data augmentation. Advances in Neural Information Processing Systems37, 127739–127764 (2024)
2024
-
[39]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, Q., Zhang, Y., Holynski, A., Efros, A.A., Kanazawa, A.: Continuous 3d perception model with persistent state. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 10510–10522 (2025)
2025
-
[40]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: Dust3r: Geometric 3d vision made easy. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20697–20709 (2024)
2024
-
[41]
Wang, Y., Zhou, J., Zhu, H., Chang, W., Zhou, Y., Li, Z., Chen, J., Pang, J., Shen, C., He, T.:π3: Scalable permutation-equivariant visual geometry learning (2025), https://arxiv.org/abs/2507.13347
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
In: European Conference on Computer Vision
Yan, Z., Li, X., Wang, K., Zhang, Z., Li, J., Yang, J.: Multi-modal masked pre- training for monocular panoramic depth completion. In: European Conference on Computer Vision. pp. 378–395. Springer (2022)
2022
-
[43]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2025)
Yang, J., Sax, A., Liang, K.J., Henaff, M., Tang, H., Cao, A., Chai, J., Meier, F., Feiszli, M.: Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2025)
2025
-
[44]
Yuan, S., Yang, Y., Yang, X., Zhang, X., Zhao, Z., Zhang, L., Zhang, Z.: In- finitevggt: Visual geometry grounded transformer for endless streams (2026)
2026
-
[45]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Yun, I., Lee, H.J., Rhee, C.E.: Improving 360 monocular depth estimation via non-local dense prediction transformer and joint supervised and self-supervised learning. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 36, pp. 3224–3233 (2022) 18 Y. Ji et al
2022
-
[46]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zheng, J., Liu, R., Chen, Y., Chen, Z., Yang, K., Zhang, J., Stiefelhagen, R.: Scene- agnostic pose regression for visual localization. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 27092–27102 (2025)
2025
-
[47]
Streaming 4D Visual Geometry Transformer
Zhuo, D., Zheng, W., Guo, J., Wu, Y., Zhou, J., Lu, J.: Streaming 4d visual geometry transformer. arXiv preprint arXiv:2507.11539 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
In: Proceedings of the European Confer- ence on Computer Vision (ECCV)
Zioulis, N., Karakottas, A., Zarpalas, D., Daras, P.: Omnidepth: Dense depth esti- mation for indoors spherical panoramas. In: Proceedings of the European Confer- ence on Computer Vision (ECCV). pp. 448–465 (2018)
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.