CATPO: Critique-Augmented Tree Policy Optimization
Pith reviewed 2026-06-27 19:28 UTC · model grok-4.3
The pith
CATPO diagnoses uninformative tree rollouts in LLM reinforcement learning and heals failing branches with critiques to improve gradient updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
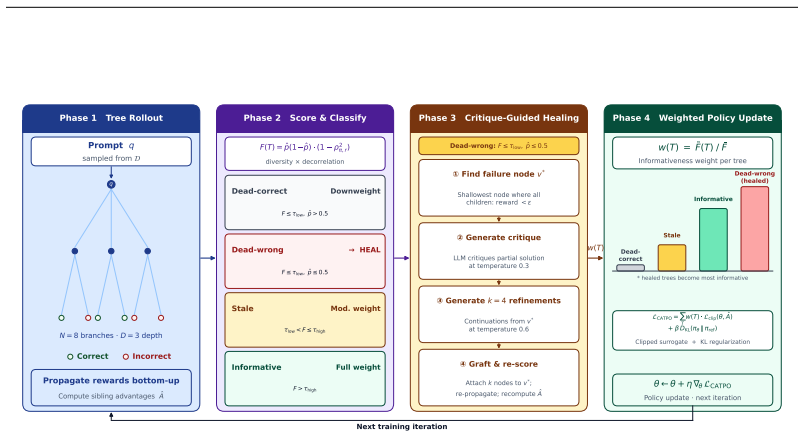
CATPO scores each tree with an informativeness function F(T) that multiplies leaf-outcome diversity by policy-reward decorrelation, down-weights low-scoring trees in the loss, and for all-failure trees inserts critique-guided continuations at the shallowest failure point; the resulting weighted policy optimization produces higher final accuracy than uniform tree sampling or prior flat and tree baselines.
What carries the argument
The tree informativeness score F(T), which multiplies leaf-outcome diversity by a policy-reward decorrelation term and is used both to diagnose waste and to scale each tree's contribution to the policy gradient.
If this is right
- Training compute is reallocated from uninformative trees to those carrying new information, raising sample efficiency.
- Dead-wrong trees no longer contribute zero or negative signal because their shallowest failure points receive targeted repairs.
- The overall gradient magnitude stays constant while its direction concentrates on higher-value updates.
- The method remains compatible with existing verifiable-reward setups and requires no separate process reward model.
Where Pith is reading between the lines
- Natural-language critiques may transfer the benefit of process supervision without training an explicit reward model.
- The same scoring and healing logic could apply to non-math domains that admit verifiable outcomes, such as code generation or theorem proving.
- If the decorrelation term dominates F(T), future work might simplify the score to rely only on outcome diversity.
Load-bearing premise
The informativeness score actually selects trees whose gradients improve final model performance rather than merely correlating with observable diversity.
What would settle it
A controlled ablation that trains identical models with uniform tree weighting versus F(T)-weighted loss and measures whether accuracy on the four benchmarks remains unchanged or drops.
Figures
read the original abstract
Reinforcement learning with verifiable rewards (RLVR) has become a dominant paradigm for improving the reasoning capabilities of large language models (LLMs). Recent tree-based methods such as TreeRPO extend flat trajectory sampling with tree-structured rollouts to obtain dense, step-level reward signals without a separate process reward model. However, not all trees are equally informative: trees where all leaves succeed, all leaves fail, or the policy already predicts the reward distribution contribute little to gradient updates, wasting compute. We introduce CATPO (Critique-Augmented Tree Policy Optimization), which diagnoses and addresses this waste at the tree level. CATPO first scores each tree via a tree informativeness score, F(T), combining leaf-outcome diversity with policy-reward decorrelation at zero extra compute. For dead-wrong trees where all branches fail, CATPO applies critique-guided healing: it locates the shallowest failure point, generates a natural-language critique, and grafts refined continuations to recover training signal. Finally, an informativeness-weighted loss scales each tree's gradient contribution by its normalized score, concentrating parameter updates on the most informative trees while preserving overall gradient magnitude. Experiments on Qwen2.5-Math-1.5B trained with the MATH dataset show that CATPO achieves 37.5% macro accuracy across four benchmarks (AIME24, MATH-500, OlympiadBench, and MinervaMath), improving over TreeRPO by 1.9% and GRPO by 4.8%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CATPO, which augments tree-based RLVR methods like TreeRPO by computing a tree informativeness score F(T) from leaf-outcome diversity and policy-reward decorrelation, applying critique-guided healing to all-failure trees, and using an F(T)-normalized weighted loss to scale gradient contributions. On Qwen2.5-Math-1.5B trained with the MATH dataset, it reports 37.5% macro accuracy across AIME24, MATH-500, OlympiadBench, and MinervaMath, for gains of 1.9% over TreeRPO and 4.8% over GRPO.
Significance. If the weighting and healing components prove effective, the approach could improve sample efficiency in tree-structured RL for LLM reasoning by concentrating updates on informative trees and recovering signal from failed rollouts, without requiring a separate process reward model.
major comments (2)
- [Experiments / loss weighting procedure] The central performance claim (37.5% macro accuracy and the 1.9%/4.8% lifts) rests on the informativeness-weighted loss that multiplies each tree's gradient by its normalized F(T). However, the manuscript provides no controlled ablation that holds the tree rollouts fixed and compares F(T) weighting against uniform (or constant) coefficients; without this isolation it is impossible to attribute gains specifically to the weighting rather than to critique healing, tree generation, or other hyperparameters.
- [Method / tree informativeness score F(T)] F(T) is defined to combine leaf-outcome diversity with policy-reward decorrelation and is used both diagnostically (to identify waste) and as the loss modifier. The manuscript supplies no separate validation that high-F(T) trees produce gradients that improve final benchmark performance over uniform sampling of the same trees; the normalization constants inside F(T) and the loss weighting are listed as free parameters, raising the risk that reported gains are sensitive to these choices.
minor comments (2)
- [Abstract / Experiments] The abstract and method description omit details on the exact functional form of F(T), the critique generation procedure, number of runs, error bars, and statistical significance tests for the reported accuracy differences.
- [Experiments] No table or figure shows per-benchmark breakdowns or comparisons that would allow readers to assess whether the macro-average improvement is driven by a subset of the four evaluation sets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight the need for stronger isolation of the weighting and validation of F(T). We address each major comment below and commit to revisions that include additional ablations and clarifications.
read point-by-point responses
-
Referee: [Experiments / loss weighting procedure] The central performance claim (37.5% macro accuracy and the 1.9%/4.8% lifts) rests on the informativeness-weighted loss that multiplies each tree's gradient by its normalized F(T). However, the manuscript provides no controlled ablation that holds the tree rollouts fixed and compares F(T) weighting against uniform (or constant) coefficients; without this isolation it is impossible to attribute gains specifically to the weighting rather than to critique healing, tree generation, or other hyperparameters.
Authors: We agree that the current results compare the full CATPO method against TreeRPO and GRPO but do not isolate the contribution of the F(T)-based weighting while holding the generated trees fixed. This is a valid concern for attribution. We will add a controlled ablation in the revised manuscript that reuses the same tree rollouts (including healing) and compares the informativeness-weighted loss against uniform weighting, reporting the resulting benchmark accuracies. revision: yes
-
Referee: [Method / tree informativeness score F(T)] F(T) is defined to combine leaf-outcome diversity with policy-reward decorrelation and is used both diagnostically (to identify waste) and as the loss modifier. The manuscript supplies no separate validation that high-F(T) trees produce gradients that improve final benchmark performance over uniform sampling of the same trees; the normalization constants inside F(T) and the loss weighting are listed as free parameters, raising the risk that reported gains are sensitive to these choices.
Authors: F(T) is presented as a diagnostic and weighting mechanism motivated by the observation that uniform trees or decorrelated ones contribute less signal. The manuscript does not contain a dedicated experiment that samples only high-F(T) trees versus uniform sampling of identical trees to measure downstream benchmark improvement. We will add a sensitivity study over the normalization constants (with fixed values reported) and an analysis of performance when weighting is replaced by uniform coefficients on the same data. revision: yes
Circularity Check
No load-bearing circularity; F(T) weighting is a heuristic evaluated on external benchmarks
full rationale
The paper defines F(T) heuristically from leaf-outcome diversity and policy-reward decorrelation, then applies it to scale gradients in the loss. Performance is measured on external benchmarks (AIME24, MATH-500, etc.) using verifiable rewards, not derived tautologically from F(T). No equations reduce claimed accuracy lifts to a fitted quantity by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes smuggled via citation appear in the provided text. The lack of ablation is a support issue, not a circularity reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- normalization constants inside F(T) and loss weighting
axioms (1)
- domain assumption Verifiable rewards are available at the leaf level for the MATH dataset and evaluation benchmarks
Reference graph
Works this paper leans on
-
[1]
Meng Cao, Lei Shu, Lei Yu, Yun Zhu, Nevan Wichers, Yinxiao Liu, and Lei Meng. Beyond sparse rewards: Enhancing reinforcement learning with language model critique in text generation.arXiv preprint arXiv:2401.07382,
-
[2]
Process reinforcement through implicit rewards.arXiv preprint arXiv:2502.01456,
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Yuchen Zhang, Jiacheng Chen, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, Jiarui Yuan, Huayu Chen, Kaiyan Zhang, Xingtai Lv, Shuo Wang, Yuan Yao, Xu Han, Hao Peng, Yu Cheng, Zhiyuan Liu, Maosong Sun, Bowen Zhou, and Ning Ding. Process reinforcement through implicit rewards.arXiv prepr...
-
[3]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
-
[4]
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
doi: 10.1038/s41586-025-09422-z. Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. rstar-math: Small LLMs can master math reasoning with self-evolved deep thinking.arXiv preprint arXiv:2501.04519,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-025-09422-z
-
[5]
Reasoning with language model is planning with world model
Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. Reasoning with language model is planning with world model. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP),
2023
-
[6]
Alex Havrilla, Sharath Raparthy, Christoforus Nalmpantis, Jane Dwivedi-Yu, Maksym Zhuravin- skyi, Eric Hambro, and Roberta Raileanu. Glore: When, where, and how to improve llm reasoning via global and local refinements.arXiv preprint arXiv:2402.10963,
-
[7]
Large language models cannot self-correct reasoning yet.arXiv preprint arXiv:2310.01798,
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet.arXiv preprint arXiv:2310.01798,
-
[8]
Deyang Kong, Qi Guo, Xiangyu Xi, Wei Wang, Jingang Wang, Xunliang Cai, Shikun Zhang, and Wei Ye. Rethinking the sampling criteria in reinforcement learning for LLM reasoning: A competence-difficulty alignment perspective.arXiv preprint arXiv:2505.17652,
-
[9]
Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, Lei M Zhang, Kay McKinney, Disha Shrivastava, Cosmin Paduraru, George Tucker, Doina Precup, Feryal Behbahani, and Aleksandra Faust. Train- ing language models to self-correct via reinforcement learning.arXiv preprint...
-
[10]
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Meiqi Guo, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, Jiao Sun, and Abhinav Rastogi. Improve mathematical reasoning in language models by automated process supervision.arXiv preprint arXiv:2406.06592,
-
[11]
Yuxiao Qu, Tianjun Zhang, Naman Garg, and Aviral Kumar. Recursive introspection: Teaching language model agents how to self-improve.arXiv preprint arXiv:2407.18219,
-
[12]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
-
[13]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models.arXiv preprint arXiv:2402.03300,
-
[14]
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao
doi: 10.1145/ 3689031.3696075. Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36,
-
[15]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. Qwen2.5-math technical report: Toward mathematical ex- pert model via self-improvement.arXiv preprint arXiv:2409.12122,
-
[16]
Bartoldson, Bhavya Kailkhura, Fan Lai, Jiawei Zhao, and Beidi Chen
Haizhong Zheng, Yang Zhou, Brian R. Bartoldson, Bhavya Kailkhura, Fan Lai, Jiawei Zhao, and Beidi Chen. Act only when it pays: Efficient reinforcement learning for LLM reasoning via selective rollouts.arXiv preprint arXiv:2506.02177,
-
[17]
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. Lan- guage agent tree search unifies reasoning acting and planning in language models.arXiv preprint arXiv:2310.04406,
-
[18]
All experiments are built on therllm framework2 derived fromverl(Sheng et al., 2025), using vLLM (Kwon et al.,
13:end for B IMPLEMENTATIONDETAILS We provide full implementation details for reproducibility. All experiments are built on therllm framework2 derived fromverl(Sheng et al., 2025), using vLLM (Kwon et al.,
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.