Representation Curriculum: Stagewise Training for Robust Ranking and Allocation
Pith reviewed 2026-06-28 07:17 UTC · model grok-4.3
The pith
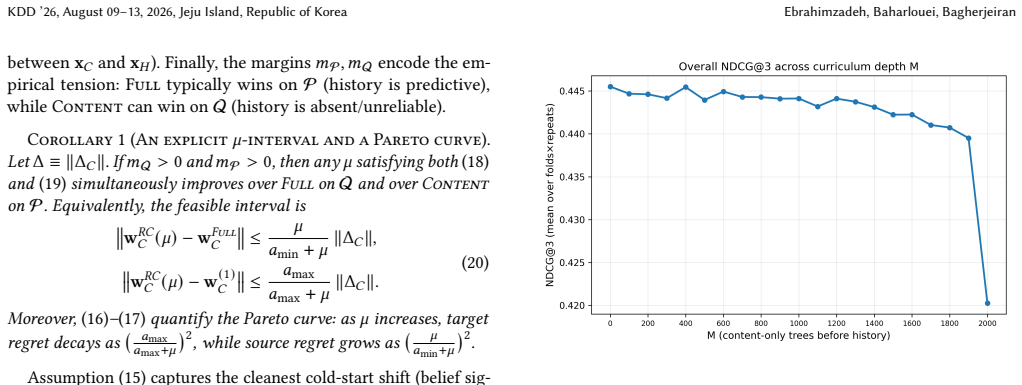
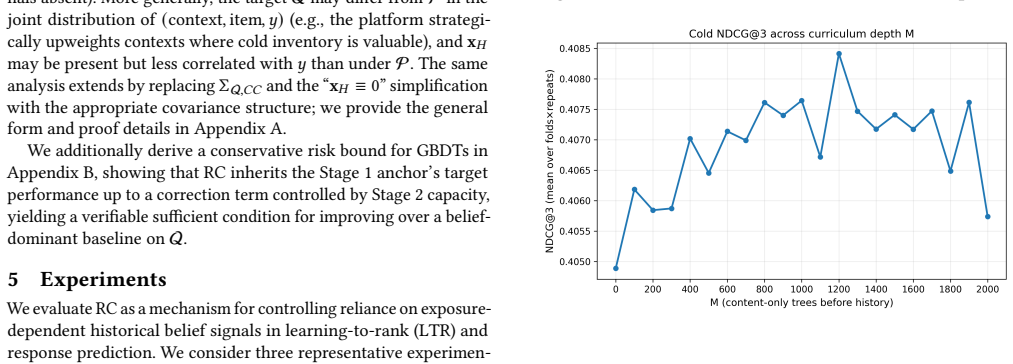
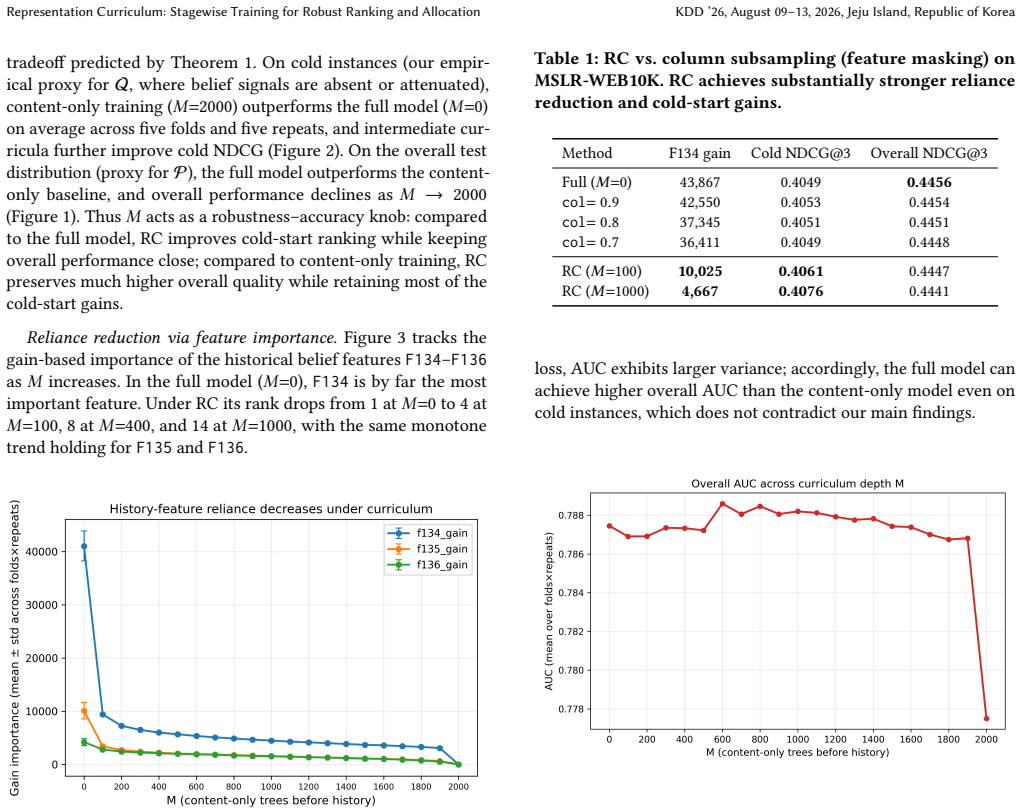
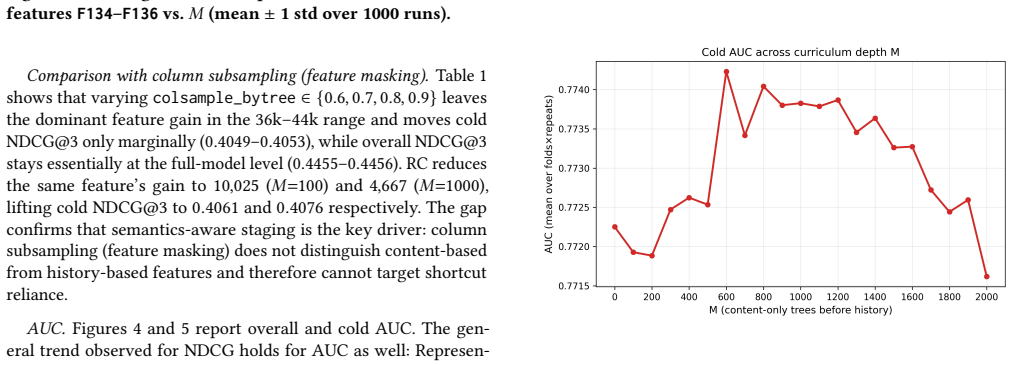
Representation Curriculum stages content merit signals before exposure signals to reduce cold-start risk in ranking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Representation Curriculum (RC) is a training-time intervention that temporally stages feature utilization by foregrounding content-based merit signals initially, then introducing exposure-dependent belief signals while anchoring the content pathway near the learned merit representation. This curbs shortcut reliance on historical signals and mitigates gradient starvation on content signals. In a Gaussian linear ridge setting, closed-form solutions and sufficient conditions are derived under which RC strictly reduces population risk on a cold-start target distribution, with a quantified Pareto tradeoff against source performance.
What carries the argument
Representation Curriculum (RC), the stagewise training procedure that separates learning of exposure-independent merit signals from exposure-dependent belief signals through initial foregrounding followed by anchoring.
If this is right
- RC shifts reliance from historical belief signals toward content-based merit signals.
- Consistent gains occur on cold populations with a controlled trade-off in head performance.
- Sufficient conditions exist under which RC strictly reduces population risk on cold-start target distributions.
- RC can be formalized independently of task and hypothesis class, with specific instantiations for ranking.
Where Pith is reading between the lines
- The staging and anchoring approach could extend to other supervised settings where features have differing degrees of confounding with outcomes.
- Validation in non-linear models would test whether the risk-reduction guarantees depend on the linearity of the ridge setting.
- Similar temporal curricula might address shortcut learning in related allocation problems such as advertising or recommendation.
Load-bearing premise
Content-based merit signals can be learned first in isolation and then anchored near the resulting representation while exposure-dependent signals are introduced, without the anchoring step itself creating instability or undermining the separation of signal types.
What would settle it
If the closed-form population risk on the cold-start target distribution is not strictly reduced under the stated sufficient conditions in the Gaussian linear ridge setting, or if randomized online experiments show no measurable shift from historical belief signals toward content merit signals.
Figures
read the original abstract
Ranking in digital marketplaces is a dynamic exposure-allocation mechanism: displayed items shape discovery trajectories and success events logged by the platform to update future allocation policies. Modern ranking systems rely heavily on exposure-confounded signals (e.g. popularity estimates, CTR/CVR aggregates, and ID-based representation), because they are highly predictive under stationary demand. Yet this predictive power can become a learning shortcut: early access to exposure-dependent belief signals steers optimization toward over-reliance on them and away from exposure-independent merit signals (e.g., content-based competitiveness and semantic affinity). Consequently, the learned policy tends to entrench incumbents and degrade cold-start generalization and robustness under distribution shift. We propose Representation Curriculum (RC), a training-time intervention that temporally stages feature utilization. RC foregrounds content-based merit signals initially, then introduces exposure-dependent belief signals while anchoring the content pathway near the learned merit representation, curbing shortcut reliance on historical signals and mitigating gradient starvation on content signals. We formalize RC independently of task and hypothesis class and provide ranking-specific instantiations. In a Gaussian linear ridge setting, we derive closed-form solutions and sufficient conditions under which RC strictly reduces population risk on a cold-start target distribution, with a quantified Pareto tradeoff against source performance. Experiments on public learning-to-rank and recommendation benchmarks, and randomized online experiments in a large-scale e-commerce search system, show that RC measurably shifts reliance from historical belief signals toward content-based merit signals and yields consistent gains on cold populations with a controlled trade-off in head performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Representation Curriculum (RC), a training-time intervention for ranking systems that stages feature utilization by first learning content-based merit signals in isolation, then introducing exposure-dependent signals while anchoring the content pathway near the learned merit representation. It formalizes RC independently of task and hypothesis class, derives closed-form solutions and sufficient conditions in a Gaussian linear ridge setting under which RC strictly reduces population risk on a cold-start target distribution (with a quantified Pareto tradeoff against source performance), and reports empirical gains on public learning-to-rank/recommendation benchmarks plus randomized online experiments in a large-scale e-commerce search system, showing reduced reliance on historical belief signals and improved cold-start robustness.
Significance. If the closed-form derivations and anchoring stability hold, the work supplies an analytically grounded method to mitigate exposure-confounded shortcut learning in dynamic ranking and allocation, with explicit conditions for risk reduction and tradeoff quantification. The provision of closed-form solutions in the Gaussian linear ridge setting is a clear strength, enabling precise insight into the mechanism rather than purely empirical claims; combined with the online A/B results, this could inform more robust production ranking policies under distribution shift.
major comments (2)
- [Gaussian linear ridge analysis] Gaussian linear ridge analysis section (derivation of closed-form solutions): The claim of strict population-risk reduction on the cold-start target rests on the anchoring step fixing the content-based weights such that no perturbation occurs upon introduction of exposure signals. The derivation appears to treat this as given (via penalty or projection), but does not explicitly address whether finite regularization allows gradient flow that violates the zero-perturbation assumption used to obtain the closed-form expressions and the strict inequality; this is load-bearing for the central analytical claim.
- [sufficient conditions] § on sufficient conditions for risk reduction: The quantified Pareto tradeoff is derived under the same anchoring assumption; if the joint optimization landscape permits even small adjustments to the anchored representation, the reported risk-reduction magnitude and the 'strictly reduces' guarantee may not hold in the stated form. Please supply the explicit anchoring loss term (e.g., the coefficient and norm) and verify the closed-form remains valid under it.
minor comments (3)
- [Abstract] The abstract states 'quantified Pareto tradeoff' but the main text should more prominently display the numerical magnitude of the source-performance penalty versus target-risk gain (e.g., in a table or highlighted equation) to make the tradeoff concrete for readers.
- Notation for the content-based versus exposure-dependent feature partitions could be introduced earlier and used consistently; occasional shifts between 'merit signals' and 'content pathway' slightly reduce readability.
- [Experiments] The experimental section would benefit from an explicit statement of the number of random seeds and statistical significance tests for the reported cold-start gains, even if the online results already include randomization.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments identify a need for greater explicitness in the anchoring mechanism within the Gaussian linear ridge analysis, which we will address through revision.
read point-by-point responses
-
Referee: [Gaussian linear ridge analysis] Gaussian linear ridge analysis section (derivation of closed-form solutions): The claim of strict population-risk reduction on the cold-start target rests on the anchoring step fixing the content-based weights such that no perturbation occurs upon introduction of exposure signals. The derivation appears to treat this as given (via penalty or projection), but does not explicitly address whether finite regularization allows gradient flow that violates the zero-perturbation assumption used to obtain the closed-form expressions and the strict inequality; this is load-bearing for the central analytical claim.
Authors: We appreciate this observation on the load-bearing nature of the anchoring assumption. The manuscript implements anchoring via an additive penalty term in the stage-2 objective that constrains the content pathway to remain near the stage-1 merit representation. To make the finite-regularization behavior explicit, the revision will state the precise anchoring term, derive the resulting closed-form solution, and supply a perturbation bound showing that the strict risk-reduction guarantee holds exactly in the large-penalty limit and approximately (with vanishing error) for finite but sufficiently large coefficients. revision: yes
-
Referee: [sufficient conditions] § on sufficient conditions for risk reduction: The quantified Pareto tradeoff is derived under the same anchoring assumption; if the joint optimization landscape permits even small adjustments to the anchored representation, the reported risk-reduction magnitude and the 'strictly reduces' guarantee may not hold in the stated form. Please supply the explicit anchoring loss term (e.g., the coefficient and norm) and verify the closed-form remains valid under it.
Authors: We agree that the explicit anchoring loss term and its effect on the closed-form must be stated for the sufficient conditions to be fully rigorous. The revision will introduce the term λ‖θ_content − θ_merit‖₂² into the objective, re-derive the closed-form solution under this regularized objective, and restate the sufficient conditions with the explicit dependence on λ, confirming that the Pareto tradeoff and risk-reduction claims remain valid for λ above a derived threshold. revision: yes
Circularity Check
No significant circularity; derivation is self-contained under explicit assumptions.
full rationale
The paper formalizes RC independently of task and hypothesis class, then derives closed-form solutions and sufficient conditions for strict population-risk reduction in a Gaussian linear ridge regression setting. This is a direct mathematical derivation from the model assumptions (Gaussian features, ridge penalty, staged anchoring) rather than any reduction of the claimed risk inequality to a fitted parameter, self-referential definition, or load-bearing self-citation. No patterns of self-definitional equivalence, fitted-input-as-prediction, or ansatz smuggling via prior work appear in the abstract or stated claims. The Pareto tradeoff is quantified from the same closed-form expressions, preserving independent content.
Axiom & Free-Parameter Ledger
free parameters (1)
- curriculum staging schedule and anchoring strength
axioms (2)
- domain assumption Content-based features provide exposure-independent merit signals that can be learned prior to and anchored against exposure-dependent belief signals
- domain assumption The Gaussian linear ridge regression setting is representative enough to yield transferable sufficient conditions for risk reduction on cold-start distributions
invented entities (1)
-
Representation Curriculum (RC)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Himan Abdollahpouri, Robin Burke, and Bamshad Mobasher. 2019. Managing Popularity Bias in Recommender Systems with Personalized Re-ranking. In Proceedings of the International Florida Artificial Intelligence Research Society Conference (FLAIRS). 413–418
2019
-
[2]
Randy Ardywibowo, Rakesh Sunki, Shin Tsz Lucy Kuo, and Sankalp Nayak
-
[3]
InProceedings of the AAAI Conference on Artificial Intelligence, Vol
BAYESCNS: A Unified Bayesian Approach to Address Cold Start and Non- Stationarity in Search Systems at Scale. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 12–20
-
[4]
Martin Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. 2019. Invariant risk minimization.arXiv preprint arXiv:1907.02893(2019)
Pith/arXiv arXiv 2019
-
[5]
Allison JB Chaney, Brandon M Stewart, and Barbara E Engelhardt. 2018. How algorithmic confounding in recommendation systems increases homogeneity and decreases utility. InProceedings of the 12th ACM conference on recommender systems. 224–232
2018
-
[6]
Jiawei Chen, Yuxiao Dong, Xiang Wang, Fuli Feng, Meng Wang, and Xiangnan He
-
[7]
ACM Transactions on Information Systems41, 3, Article 67 (2023)
Bias and Debias in Recommender System: A Survey and Future Directions. ACM Transactions on Information Systems41, 3, Article 67 (2023). doi:10.1145/ 3564284
2023
-
[8]
Minmin Chen, Can Xu, Vince Gatto, Devanshu Jain, Aviral Kumar, and Ed Chi
-
[9]
InProceedings of the 16th ACM Conference on Recommender Systems
Off-policy actor-critic for recommender systems. InProceedings of the 16th ACM Conference on Recommender Systems. 338–349
-
[10]
Ehsan Ebrahimzadeh, Alex Cozzi, and Abraham Bagherjeiran. 2024. Counter- factual Learning to Rank via Knowledge Distillation. InProceedings of the ACM SIGIR Workshop on eCommerce (eCom@SIGIR)
2024
-
[11]
Ehsan Ebrahimzadeh, Nikhil Monga, Hang Gao, Alex Cozzi, and Abraham Bagher- jeiran. 2024. Ranking Policy Learning via Marketplace Expected Value Estimation From Observational Data. SURE at 18th ACM Conference on Recommender Systems (RecSys)
2024
-
[12]
Nicola Ferro, Claudio Lucchese, Maria Maistro, and Raffaele Perego. 2018. Contin- uation methods and curriculum learning for learning to rank. InProceedings of the 27th ACM International Conference on Information and Knowledge Management. 1523–1526
2018
-
[13]
Cuize Han, Tao Yang, Zhenduo Wang, Anh Tran, and Qingyao Ai. 2022. Address- ing Cold Start in Product Search via Empirical Bayes. InProceedings of the 31st ACM International Conference on Information and Knowledge Management (CIKM ’22)
2022
-
[14]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the Knowledge in a Neural Network. arXiv preprint arXiv:1503.02531
Pith/arXiv arXiv 2015
-
[15]
Thorsten Joachims, Adith Swaminathan, and Tobias Schnabel. 2017. Unbiased Learning-to-Rank with Biased Feedback. InProceedings of the 10th ACM In- ternational Conference on Web Search and Data Mining (WSDM ’17). 781–789. doi:10.1145/3018661.3018699
-
[16]
Jonas Peters, Peter Bühlmann, and Nicolai Meinshausen. 2016. Causal inference by using invariant prediction: identification and confidence intervals.Journal of the Royal Statistical Society Series B: Statistical Methodology78, 5 (2016), 947–1012
2016
-
[17]
Mohammad Pezeshki, Oumar Kaba, Yoshua Bengio, Aaron C Courville, Doina Precup, and Guillaume Lajoie. 2021. Gradient starvation: A learning proclivity in neural networks.Advances in Neural Information Processing Systems34 (2021), 1256–1272
2021
-
[18]
Tao Qin and Tie-Yan Liu. 2010. LETOR 4.0 Datasets (MSLR-WEB10K / MSLR- WEB30K). Microsoft Research dataset page
2010
-
[19]
Tao Qin and Tie-Yan Liu. 2013. Introducing LETOR 4.0 Datasets. arXiv preprint arXiv:1306.2597
Pith/arXiv arXiv 2013
-
[20]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks.arXiv preprint arXiv:1908.10084(2019)
Pith/arXiv arXiv 2019
-
[21]
Dominik Rothenhäusler, Nicolai Meinshausen, Peter Bühlmann, and Jonas Peters
-
[22]
Anchor Regression: Heterogeneous Data Meets Causality.Journal of the Royal Statistical Society: Series B83, 2 (2021), 215–246. doi:10.1111/rssb.12398
-
[23]
Tobias Schnabel, Adith Swaminathan, Ashudeep Singh, Navin Chandak, and Thorsten Joachims. 2016. Recommendations as Treatments: Debiasing Learning and Evaluation. InProceedings of the 33rd International Conference on Machine Learning (ICML). 1670–1679
2016
-
[24]
Ashudeep Singh and Thorsten Joachims. 2018. Fairness of Exposure in Rankings. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’18). 2219–2228
2018
-
[25]
Ashudeep Singh and Thorsten Joachims. 2019. Policy Learning for Fairness in Ranking. InAdvances in Neural Information Processing Systems (NeurIPS)
2019
-
[26]
Ashudeep Singh, David Kempe, and Thorsten Joachims. 2021. Fairness in Rank- ing under Uncertainty. InAdvances in Neural Information Processing Systems (NeurIPS)
2021
-
[27]
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. Dropout: A Simple Way to Prevent Neural Networks from Overfitting.Journal of Machine Learning Research15 (2014), 1929–1958
2014
-
[28]
Adith Swaminathan and Thorsten Joachims. 2015. Counterfactual Risk Min- imization: Learning from Logged Bandit Feedback. InProceedings of the 32nd International Conference on Machine Learning (ICML). 814–823
2015
-
[29]
Jie Tang, Huiji Gao, Liwei He, and Sanjeev Katariya. 2024. Multi-objective Learning to Rank by Model Distillation. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5783–5792
2024
-
[30]
Maksims Volkovs, Guangwei Yu, and Tomi Poutanen. 2017. DropoutNet: Ad- dressing Cold Start in Recommender Systems. InAdvances in Neural Information Processing Systems (NeurIPS)
2017
-
[31]
Cheng Wang, Mathias Niepert, and Hui Li. 2018. LRMM: Learning to Recommend with Missing Modalities.Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP)(2018), 3360–3370. doi:10.18653/v1/D18- 1372
-
[32]
Xuanhui Wang, Cheng Li, Nadav Golbandi, Michael Bendersky, and Marc Najork
-
[33]
InProceedings of the 27th ACM international conference on information and knowledge manage- ment
The lambdaloss framework for ranking metric optimization. InProceedings of the 27th ACM international conference on information and knowledge manage- ment. 1313–1322
-
[34]
Tianxin Wei, Fuli Feng, Jiawei Chen, Ziwei Wu, Jinfeng Yi, and Xiangnan He
-
[35]
InProceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining
Model-agnostic counterfactual reasoning for eliminating popularity bias in recommender system. InProceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining. 1791–1800
-
[36]
Phillips, and Qingyao Ai
Tao Yang, Cuize Han, Chen Luo, Parth Gupta, Jeff M. Phillips, and Qingyao Ai
-
[37]
InProceedings of the ACM Web Conference 2024 (WWW ’24)
Mitigating Exploitation Bias in Learning to Rank with an Uncertainty- aware Empirical Bayes Approach. InProceedings of the ACM Web Conference 2024 (WWW ’24). 1486–1496. doi:10.1145/3589334.3645487
-
[38]
Tao Yang, Chen Luo, Hanqing Lu, Parth Gupta, Bing Yin, and Qingyao Ai. 2022. Can Clicks Be Both Labels and Features?: Unbiased Behavior Feature Collection and Uncertainty-aware Learning to Rank. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’22). 6–17. doi:10.1145/3477495.3531948
-
[39]
Hansi Zeng, Hamed Zamani, and Vishwa Vinay. 2022. Curriculum learning for dense retrieval distillation. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1979–1983
2022
-
[40]
Yang Zhang, Fuli Feng, Xiangnan He, Tianxin Wei, Chonggang Song, Guohui Ling, and Yongdong Zhang. 2021. Causal intervention for leveraging popularity bias in recommendation. InProceedings of the 44th international ACM SIGIR conference on research and development in information retrieval. 11–20. A Proofs for Section 4 This appendix provides full proofs for...
2021
-
[41]
controlled refinement
Dif- ferentiating and setting the gradient to zero yields the population normal equations (Σ P +𝜆𝐼)𝑤 Full =E P [𝑥𝑦]=E P [𝑥𝑥 ⊤]𝛽=Σ P 𝛽.(23) Content-only ridge (Stage 1) under P.Similarly, differentiating (9) gives (Σ P,𝐶𝐶 +𝜆𝐼)𝑤 (1) 𝐶 =E P [𝑥𝐶𝑦]=Σ P,𝐶𝐶 𝛽𝐶 +Σ P,𝐶𝐻 𝛽𝐻 .(24) Anchored ridge (Stage 2) underP.The objective in (10) is 𝑅 P (𝑤)+ 𝜆(∥𝑤 𝐶 ∥2 + ∥𝑤 𝐻 ∥2)...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.