Fidelity Probes for Specification--Code Alignment
Pith reviewed 2026-05-20 14:20 UTC · model grok-4.3
The pith
Fidelity probes turn natural-language questions with code-derived answers into a driver for iteratively aligning specifications to implementations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
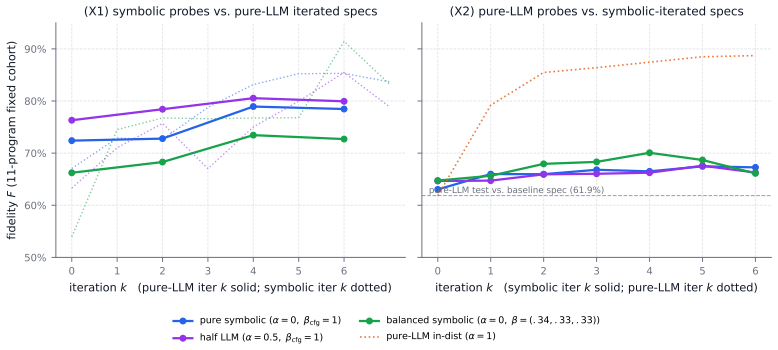
Fidelity probes are natural-language questions generated from a reference code artifact together with ground-truth answers extracted from the code itself. When the same questions are answered from a candidate specification, the fraction of matches defines fidelity, which decomposes into a contradiction rate and a coverage-gap rate. These two rates drive successive edits to the specification until agreement stabilizes. On the AWS CardDemo COBOL suite the frozen-test fidelity rises from 0.63 to 0.94 over eight iterations, and the final plateau is predicted by the fixed point F† of a two-state Markov chain fitted to the first four iterations of observed rates. Probes generated by an LLM reading
What carries the argument
Fidelity probes: natural-language questions generated from code with ground-truth answers taken from the code, whose agreement rate with a specification decomposes into contradiction and coverage-gap components that direct targeted edits.
If this is right
- Targeted edits to a specification can be driven directly by the locations of contradictions and coverage gaps revealed by the probes.
- Convergence to a stable fidelity plateau occurs for three of five independent LLM lineages when probe drift is controlled by the frozen held-out protocol.
- Graph-based static-analysis probes and LLM-generated probes are empirically complementary, each lifting fidelity when mixed with the other.
- The method applies to any pair of artifacts intended to describe the same behavior, not only specification-code pairs.
- A Hoeffding-bounded train/test gap remains more than an order of magnitude below the overfitting envelope under the resampling protocol.
Where Pith is reading between the lines
- The Markov fixed-point prediction could let practitioners stop the alignment loop early once four iterations of rates are in hand.
- Because the two generator channels are complementary, a hybrid probe generator might reach higher final fidelity than either channel alone.
- The same probe-and-edit loop could be tested on aligning high-level requirements documents with implementations written in languages other than COBOL.
- If probe generation itself can be made parameter-free, the entire alignment process might become fully automatic once an initial code artifact is supplied.
Load-bearing premise
The probes must continue to sample code behavior in a way that stays representative and unbiased across iterations, and the two-state Markov model fitted to the observed rates must correctly forecast the eventual fixed point without circular dependence on the improvement data.
What would settle it
Apply the full iterative process to a new program suite in which probe ground-truth answers are observed to change between iterations; if the measured frozen-test fidelity either fails to plateau near the predicted F† or continues rising beyond the forecast, the central convergence claim is falsified.
Figures


















read the original abstract
We introduce fidelity probes: natural-language questions generated from a reference artifact with code-derived ground-truth answers, answered from a candidate specification. The fraction of agreeing probes, which we call the fidelity, decomposes into contradiction and coverage-gap rates that drive targeted spec edits to convergence. On a 15-program, roughly 12k-line COBOL benchmark (AWS CardDemo), we raise frozen-test specification fidelity from 0.63 to 0.94 over eight iterations, with the plateau location predicted by a two-state Markov fixed point $F^\dagger$ from just four iterations of rate data. Probes come from an LLM reading the code or from a static-analysis pipeline over its control-flow, data-flow, and system-dependence graphs, with a tunable mixture. A probe-resampling protocol with a frozen held-out set gives a Hoeffding-bounded overfitting discriminant; our measured train/test gap stays more than an order of magnitude below this envelope. Three graph-grounded mixtures lift fidelity by +16 to +30 points; cross-distribution evaluation shows the LLM and symbolic channels are empirically complementary. A cross-family generator sweep on five independent LLM lineages (Anthropic, DeepSeek, Google, Alibaba, OpenAI) confirms the convergence behaviour is not tied to any single model family: three of five non-Claude generators produce trajectories consistent with the Markov fixed-point prediction, and the frozen-test protocol actively falsifies the two generators whose probe distributions drift across iterations. The method applies to any pair of artifacts that are supposed to describe the same behaviour.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces fidelity probes: natural-language questions generated from a reference artifact (code) with derived ground-truth answers, which are then answered from a candidate specification. The fraction of agreeing probes (fidelity) decomposes into contradiction and coverage-gap rates that guide targeted specification edits. On a 15-program, ~12k-line COBOL benchmark (AWS CardDemo), frozen-test fidelity rises from 0.63 to 0.94 over eight iterations; the plateau is predicted by a two-state Markov fixed point F† computed from contradiction/coverage-gap rates observed in the first four iterations. Probes are generated by LLM or static analysis over control-flow/data-flow/system-dependence graphs (with tunable mixture); a probe-resampling protocol with frozen held-out set yields a Hoeffding-bounded overfitting check, and cross-generator evaluation on five LLM families confirms convergence behavior is not model-specific.
Significance. If the central empirical result and Markov prediction hold without circularity, the work supplies a concrete, measurable protocol for aligning natural-language specifications with code, especially legacy systems. Strengths include the reported empirical gains on a named benchmark, explicit Hoeffding bounds and held-out resampling for overfitting control, cross-generator falsification across five LLM lineages, and the complementarity finding between LLM and graph-based probe channels. These elements provide falsifiable predictions and external checks that strengthen the contribution beyond a single-run demonstration.
major comments (3)
- [Markov fixed-point section (near the description of F† and rate estimation)] The central claim that the plateau at 0.94 is predicted by F† from only the first four iterations of rate data is load-bearing for the forecasting interpretation. The manuscript must explicitly state (a) that transition rates are estimated solely from iterations 1–4, (b) that the fixed-point calculation is performed before observing iterations 5–8, and (c) the numerical value of the predicted F† together with the observed fidelity in the held-out later iterations. If rates are extracted from the full trajectory or the same probe set used for editing, the result is a post-hoc summary rather than a genuine forecast.
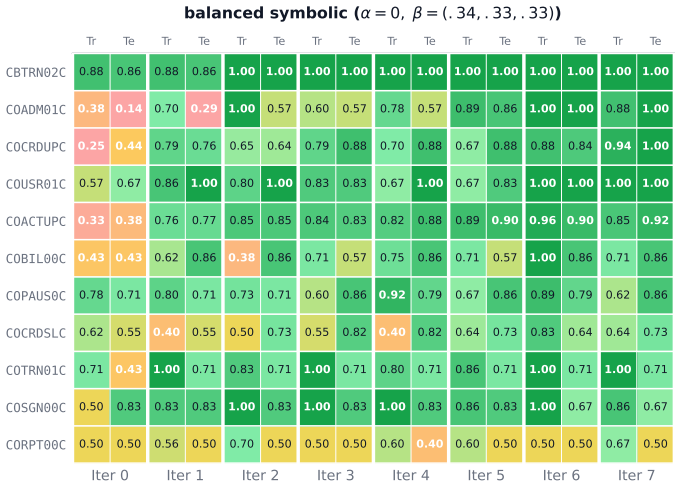
- [Probe generation and validation subsection] Probe representativeness and ground-truth stability: the weakest assumption is that generated probes (LLM or graph-based) form an unbiased sample whose ground-truth answers remain stable across iterations. Provide the exact protocol for deriving ground-truth answers from code, the number of probes per program, and any checks that the probe distribution does not drift in a way that artificially inflates later fidelity measurements.
- [Cross-generator evaluation results] Table or figure reporting the eight-iteration trajectory: the cross-period claim that three of five non-Claude generators produce trajectories consistent with the Markov prediction requires the per-iteration fidelity numbers (with error bars or the Hoeffding envelope) for each generator so that the consistency can be assessed quantitatively rather than qualitatively.
minor comments (2)
- [Experimental results] Clarify whether the 0.63-to-0.94 improvement is measured exclusively on the frozen held-out test set or includes any probes used during editing.
- [Overfitting discriminant paragraph] The abstract states the train/test gap is 'more than an order of magnitude below this envelope'; report the exact numerical gap and envelope values for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below, indicating the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: The central claim that the plateau at 0.94 is predicted by F† from only the first four iterations of rate data is load-bearing for the forecasting interpretation. The manuscript must explicitly state (a) that transition rates are estimated solely from iterations 1–4, (b) that the fixed-point calculation is performed before observing iterations 5–8, and (c) the numerical value of the predicted F† together with the observed fidelity in the held-out later iterations. If rates are extracted from the full trajectory or the same probe set used for editing, the result is a post-hoc summary rather than a genuine forecast.
Authors: We agree that these details must be stated explicitly to support the forecasting claim. In the revised manuscript we will add text in the Markov fixed-point section stating that transition rates were estimated solely from iterations 1–4, that the fixed-point calculation was performed before any data from iterations 5–8 were observed, and that we report the numerical value of the predicted F† together with the observed fidelity values in the held-out iterations. This protocol ensures the result is presented as a genuine forecast. revision: yes
-
Referee: Probe representativeness and ground-truth stability: the weakest assumption is that generated probes (LLM or graph-based) form an unbiased sample whose ground-truth answers remain stable across iterations. Provide the exact protocol for deriving ground-truth answers from code, the number of probes per program, and any checks that the probe distribution does not drift in a way that artificially inflates later fidelity measurements.
Authors: We will revise the Probe generation and validation subsection to supply the requested information. Ground-truth answers are obtained by executing the relevant COBOL code paths on the inputs implied by each probe and recording the resulting outputs or state changes. We generate approximately 150 probes per program. We will also add checks for distributional stability, including Jaccard overlap of probe sets and category counts (control-flow versus data-flow) across iterations, to confirm that fidelity gains are not artifacts of probe drift. revision: yes
-
Referee: Table or figure reporting the eight-iteration trajectory: the cross-period claim that three of five non-Claude generators produce trajectories consistent with the Markov prediction requires the per-iteration fidelity numbers (with error bars or the Hoeffding envelope) for each generator so that the consistency can be assessed quantitatively rather than qualitatively.
Authors: We agree that quantitative per-iteration data are needed for rigorous evaluation. The revised manuscript will include a new table (or augmented figure) in the cross-generator section that reports fidelity at each iteration for all five generators, together with Hoeffding envelopes or resampling-derived error bars. This will permit quantitative assessment of consistency with the Markov prediction for the three generators that align with it. revision: yes
Circularity Check
No significant circularity; Markov fixed-point uses early rates to forecast held-out plateau
full rationale
The paper computes the two-state Markov fixed point F† exclusively from contradiction and coverage-gap rates observed in the first four iterations, then compares the resulting prediction against fidelity measured at iteration eight on a frozen held-out probe set. Probe-resampling with Hoeffding bounds, cross-generator falsification on five LLM families, and explicit separation of train/test probe distributions supply independent verification that the rates are not retrofitted to the full trajectory. No equation or claim reduces the final fidelity number to a re-expression of the same fitted parameters; the derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- LLM-symbolic mixture weights
- Markov transition rates
axioms (1)
- domain assumption Probe answers are statistically independent for application of the Hoeffding bound
invented entities (2)
-
fidelity probes
no independent evidence
-
two-state Markov fixed point F†
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Corollary 4.4 (Regression-aware fidelity recursion). Under Assumption 4.2, E[Ftrain k+1] ≥ γk E[Ftrain k] + πk with γk := 1−πk−rk. Define the local fixed point F†k := πk/(πk+rk) ... geometric contraction to F†k.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 4.5 (Convergence). Suppose the rates stabilise asymptotically (πk→π∞, rk→r∞) ... E[Ftrain k] converges to a limit F⋆ ≥ F†∞ := π∞/(π∞+r∞)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 4.6 (Finite-sample generalization gap) ... Hoeffding-bounded overfitting discriminant
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume =
Autoformalization with large language models , author =. Advances in neural information processing systems , volume =
-
[2]
Draft, sketch, and prove: Guiding formal theorem provers with informal proofs , author =. arXiv preprint arXiv:2210.12283 , year =
-
[3]
International Symposium on AI Verification , pages =
Clover: Clo sed-loop ver ifiable code generation , author =. International Symposium on AI Verification , pages =. 2024 , organization =
work page 2024
-
[4]
WybeCoder: Verified Imperative Code Generation
WybeCoder: Verified Imperative Code Generation , author =. arXiv preprint arXiv:2603.29088 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2505.23135 , year =
Verina: Benchmarking verifiable code generation , author =. arXiv preprint arXiv:2505.23135 , year =
-
[6]
Evosuite: automatic test suite generation for object-oriented software , author =. Proceedings of the 19th ACM SIGSOFT symposium and the 13th European conference on Foundations of software engineering , pages =
-
[7]
Proceedings of the fifth ACM SIGPLAN international conference on Functional programming , pages =
QuickCheck: a lightweight tool for random testing of Haskell programs , author =. Proceedings of the fifth ACM SIGPLAN international conference on Functional programming , pages =
-
[8]
IEEE transactions on software engineering , volume =
An analysis and survey of the development of mutation testing , author =. IEEE transactions on software engineering , volume =. 2010 , publisher =
work page 2010
-
[9]
2022 , howpublished =
work page 2022
-
[10]
Sentence-bert: Sentence embeddings using siamese bert-networks , author =. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages =
work page 2019
-
[11]
Advances in neural information processing systems , volume =
Self-refine: Iterative refinement with self-feedback , author =. Advances in neural information processing systems , volume =
-
[12]
Shinn, Noah and Cassano, Federico and Gopinath, Ashwin and Narasimhan, Karthik and Yao, Shunyu , booktitle =
-
[13]
ReAct: Synergizing Reasoning and Acting in Language Models
React: Synergizing reasoning and acting in language models , author =. arXiv preprint arXiv:2210.03629 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
2012 34th international conference on software engineering (ICSE) , pages =
A systematic study of automated program repair: Fixing 55 out of 105 bugs for 8 each , author =. 2012 34th international conference on software engineering (ICSE) , pages =. 2012 , organization =
work page 2012
-
[15]
International Conference on Automated Deduction , pages =
The lean 4 theorem prover and programming language , author =. International Conference on Automated Deduction , pages =. 2021 , organization =
work page 2021
-
[16]
International conference on logic for programming artificial intelligence and reasoning , pages =
Dafny: An automatic program verifier for functional correctness , author =. International conference on logic for programming artificial intelligence and reasoning , pages =. 2010 , organization =
work page 2010
- [17]
-
[18]
Proceedings of the 4th ACM SIGACT-SIGPLAN symposium on Principles of programming languages , pages =
Abstract interpretation: a unified lattice model for static analysis of programs by construction or approximation of fixpoints , author =. Proceedings of the 4th ACM SIGACT-SIGPLAN symposium on Principles of programming languages , pages =
-
[19]
Communications of the ACM , volume =
Symbolic execution and program testing , author =. Communications of the ACM , volume =. 1976 , publisher =
work page 1976
-
[20]
DART: Directed automated random testing , author =. Proceedings of the 2005 ACM SIGPLAN conference on Programming language design and implementation , pages =
work page 2005
-
[21]
ACM SIGSOFT software engineering notes , volume =
CUTE: A concolic unit testing engine for C , author =. ACM SIGSOFT software engineering notes , volume =. 2005 , publisher =
work page 2005
- [22]
-
[23]
Journal of the American Statistical Association , volume =
Probable inference, the law of succession, and statistical inference , author =. Journal of the American Statistical Association , volume =. 1927 , publisher =
work page 1927
-
[24]
The American Statistician , volume =
Approximate is better than “exact” for interval estimation of binomial proportions , author =. The American Statistician , volume =. 1998 , publisher =
work page 1998
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.