VISTA Architect: A graph database-oriented health AI system demonstrated in multidisciplinary tumor boards
Pith reviewed 2026-06-26 10:17 UTC · model grok-4.3
The pith
VISTA Architect converts electronic health records into a persistent knowledge graph that enables 96.4 percent accurate extraction of tumor board variables.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
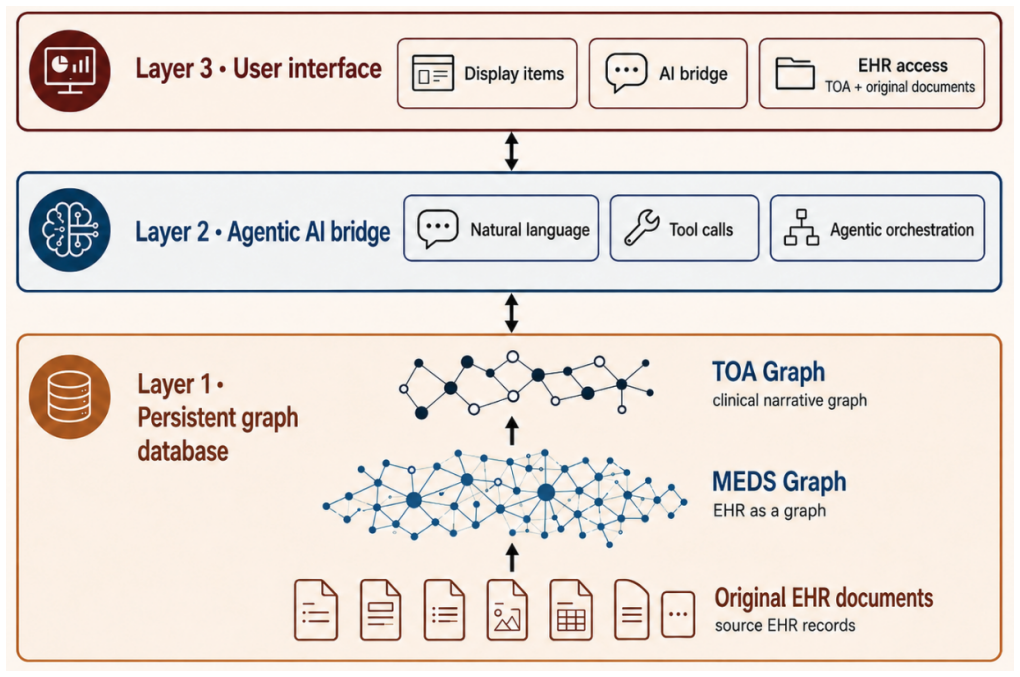
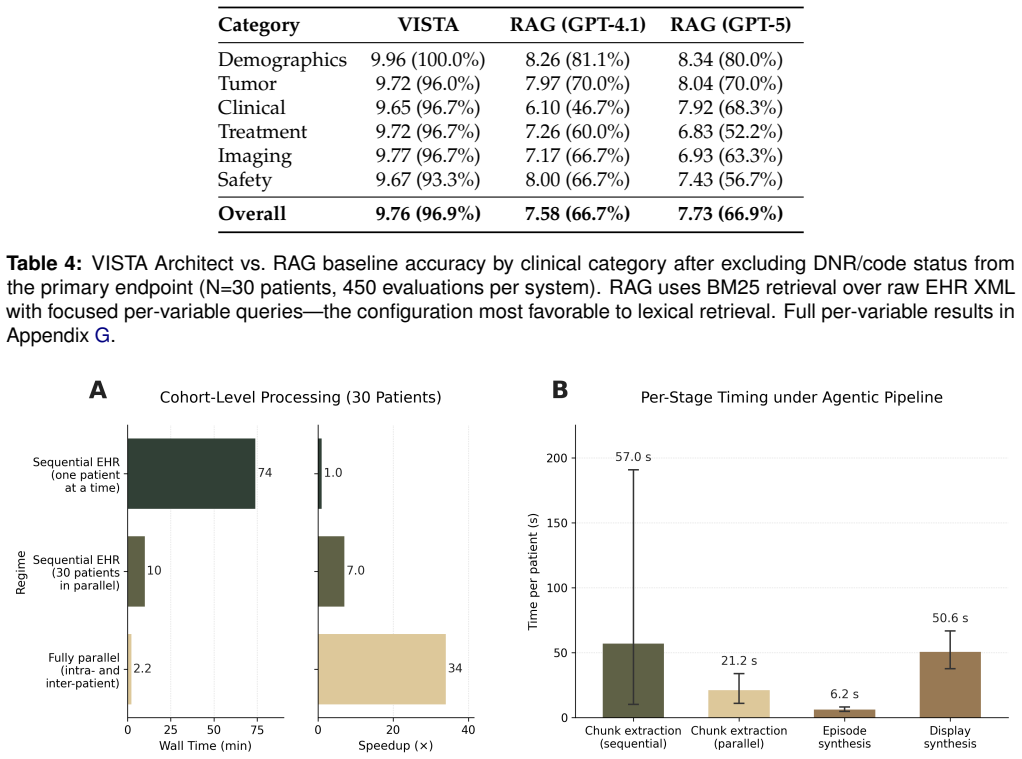
VISTA Architect transforms longitudinal electronic health records into a persistent, provenance-linked knowledge graph with two layers: a granular MEDS Graph and a Timeline Object Architecture that applies graph-guided LLM extraction to produce concise, deduplicated, temporally coherent clinical event timelines. In a demonstration on 1,180 thoracic oncology patients, this yielded 96.4 percent accuracy on 15 tumor board variables, exceeding a BM25 RAG baseline.
What carries the argument
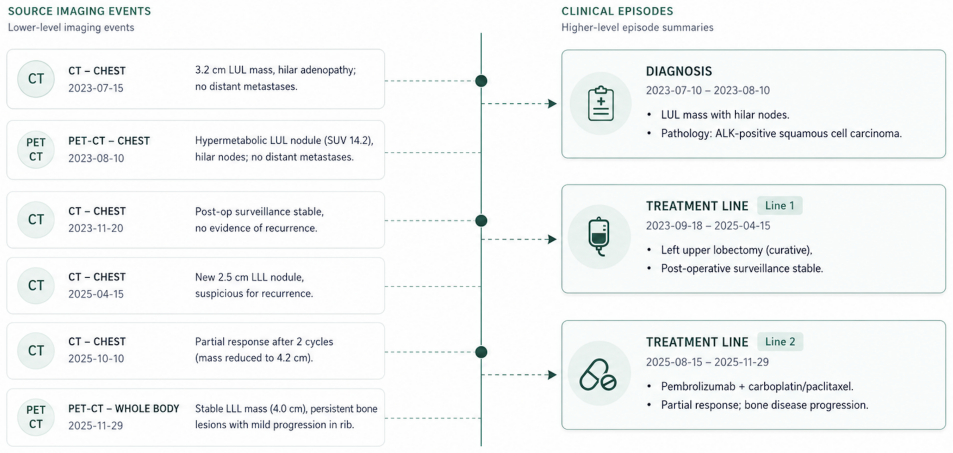
The Timeline Object Architecture (TOA), which uses graph-guided LLM extraction to synthesize a concise timeline of deduplicated, temporally coherent clinical events from the source graph.
If this is right
- Downstream queries access an organized patient state and only traverse to source documentation for detailed verification.
- The modular design allows adaptation to other medical specialties through customizable event definitions and episode structures.
- An agentic interface can reduce preparation time for patient cohorts to about 2.2 minutes without loss of accuracy.
- Repeated reprocessing of raw records at query time is eliminated, lowering cost and latency.
Where Pith is reading between the lines
- Similar graph precomputation could be tested for improving LLM performance on other longitudinal medical tasks like chronic disease management.
- The single-institution thoracic focus leaves open whether the accuracy holds when event definitions are customized for different clinical contexts.
- Integration with agentic tools suggests potential for fully automated tumor board preparation workflows in larger health systems.
Load-bearing premise
The graph-guided LLM extraction in the Timeline Object Architecture produces temporally coherent, deduplicated events that match expert judgment on the 15 tumor board variables.
What would settle it
A blinded expert review of the extracted timelines for a new cohort of patients where agreement with the reported 96.4 percent accuracy falls substantially below the 95 percent confidence interval.
Figures
read the original abstract
We introduce VISTA Architect, a database-oriented AI architecture for integrating large language models (LLMs) with longitudinal electronic health records (EHRs). At ingestion, it transforms complex clinical documentation into a persistent, provenance-linked knowledge graph, eliminating repeated reprocessing of raw records at query time. The architecture has two layers: a source-faithful MEDS Graph preserving granular EHR structure with full provenance, and a clinically abstracted Timeline Object Architecture (TOA) that uses graph-guided LLM extraction to synthesize a concise timeline of deduplicated, temporally coherent clinical events. This addresses key limitations of direct long-context prompting and retrieval-augmented generation (RAG), which often miss temporal relationships and incur high cost and latency from repeated raw-text processing. By precomputing clinical synthesis once, downstream queries access an organized patient state and traverse to source documentation only when detailed verification is needed. We demonstrate the system in multidisciplinary thoracic oncology tumor boards at Stanford Medicine, where precise reconstruction of patient histories is critical. Across 1,180 patients, VISTA Architect achieved 96.4% accuracy (mean 9.75/10) on 15 tumor board-salient variables (17,700 evaluations; 95% CI 96.1-96.7%), surpassing a matched BM25 RAG baseline and recent benchmarks for LLM-based clinical extraction. An agentic interface reduced preparation for a 30-patient held-out cohort to about 2.2 minutes without sacrificing accuracy. While configured here for thoracic oncology, the modular design adapts to other specialties through customizable event definitions, episode structures, and agentic tools; validation beyond thoracic oncology remains future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VISTA Architect, a two-layer architecture for EHR integration: a source-faithful MEDS Graph preserving provenance and a Timeline Object Architecture (TOA) that applies graph-guided LLM extraction to produce deduplicated, temporally coherent clinical timelines. This precomputes synthesis to avoid repeated raw-text processing in downstream queries. The system is demonstrated in Stanford thoracic oncology tumor boards, where it reports 96.4% accuracy (mean 9.75/10) across 15 variables on 1,180 patients (17,700 evaluations, 95% CI 96.1-96.7%), outperforming a matched BM25 RAG baseline; an agentic interface reduces preparation time for a held-out cohort.
Significance. If the accuracy result holds under rigorous validation, the architecture offers a practical advance for clinical AI by shifting synthesis to ingestion time, improving temporal coherence and query efficiency over direct LLM or RAG approaches. The modular design (customizable event definitions and tools) and real-world deployment in multidisciplinary tumor boards are strengths; the large cohort size provides a falsifiable empirical test of the central claim.
major comments (1)
- [Abstract / demonstration results] Abstract and demonstration section: the headline accuracy claim (96.4% on 17,700 evaluations) is load-bearing for the central assertion that TOA produces events matching expert judgment and surpasses the BM25 baseline, yet supplies no evaluation protocol details (annotation guidelines, number of raters per case, blinding, inter-rater reliability, or adjudication procedure). This prevents verification that the metric is reproducible and independent of system development.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in our evaluation protocol. This is a substantive point that strengthens the manuscript. We address it directly below.
read point-by-point responses
-
Referee: [Abstract / demonstration results] Abstract and demonstration section: the headline accuracy claim (96.4% on 17,700 evaluations) is load-bearing for the central assertion that TOA produces events matching expert judgment and surpasses the BM25 baseline, yet supplies no evaluation protocol details (annotation guidelines, number of raters per case, blinding, inter-rater reliability, or adjudication procedure). This prevents verification that the metric is reproducible and independent of system development.
Authors: We agree that the current version lacks sufficient detail on the evaluation protocol, which is necessary for assessing reproducibility and independence from system development. The reported accuracy derives from expert review of extracted timeline events against source EHR documentation for 15 variables across 1,180 patients. In the revised manuscript we will add a dedicated subsection (likely in Methods or a new Evaluation Protocol section) that specifies: (1) the annotation guidelines provided to reviewers, (2) the number of raters per case and their clinical expertise, (3) whether cases were blinded to system output, (4) inter-rater reliability statistics (e.g., Cohen’s kappa or percentage agreement), and (5) the adjudication procedure for disagreements. These additions will be placed before the results are presented so readers can evaluate the metric’s validity. revision: yes
Circularity Check
No circularity; empirical accuracy claims are direct measurements with no derivation chain
full rationale
The manuscript describes a system architecture (MEDS Graph + TOA) and reports measured accuracy (96.4% on 17,700 evaluations) against external expert judgments. No equations, fitted parameters, or first-principles derivations appear. The accuracy figure is presented as an empirical result, not a quantity defined from the system's own outputs or prior self-citations. The BM25 baseline comparison is an external benchmark, not a self-referential fit. No self-definitional, fitted-input, or uniqueness-imported steps exist. The paper explicitly flags that validation is limited to one specialty and site, consistent with non-circular empirical reporting.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Burnout related to elec- tronic health record use in primary care
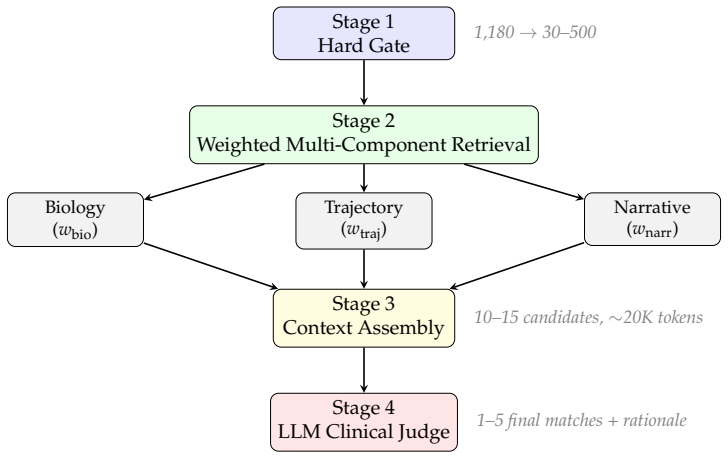
Jeffrey Budd. Burnout related to elec- tronic health record use in primary care. Journal of primary care & community health, 14:21501319231166921, 2023
2023
-
[2]
Allocation of physician time in ambulatory practice: a time and motion study in 4 specialties.Annals of internal medicine, 165(11):753–760, 2016
Christine Sinsky, Lacey Colligan, Ling Li, Mirela Prgomet, Sam Reynolds, Lindsey Goed- ers, Johanna Westbrook, Michael Tutty, and George Blike. Allocation of physician time in ambulatory practice: a time and motion study in 4 specialties.Annals of internal medicine, 165(11):753–760, 2016
2016
-
[3]
Estimating the attributable cost of physician burnout in the united states.Annals of internal medicine, 170(11):784–790, 2019
Shasha Han, Tait D Shanafelt, Christine A Sinsky, Karim M Awad, Liselotte N Dyrbye, Lynne C Fiscus, Mickey Trockel, and Joel Goh. Estimating the attributable cost of physician burnout in the united states.Annals of internal medicine, 170(11):784–790, 2019
2019
-
[4]
Digital tumor board so- lutions have significant impact on case prepara- tion.JCO Clinical Cancer Informatics, 4:757–768, 2020
Richard D Hammer, Donna Fowler, Lincoln R Sheets, Athanasios Siadimas, Chaohui Guo, and Matthew S Prime. Digital tumor board so- lutions have significant impact on case prepara- tion.JCO Clinical Cancer Informatics, 4:757–768, 2020
2020
-
[5]
Electronic health 20 record–integrated tumor board application to save preparation time and reduce errors.JCO Clinical Cancer Informatics, 6:e2100142, 2022
Alex Nobori, Chayanit Jumniensuk, Xiang Chen, Dieter Enzmann, Sarah Dry, Scott Nel- son, and Corey W Arnold. Electronic health 20 record–integrated tumor board application to save preparation time and reduce errors.JCO Clinical Cancer Informatics, 6:e2100142, 2022
2022
-
[6]
The use of an integrated digital tool to improve the efficiency of multidisciplinary tumor boards—a prospective trial in taiwan
Linda Chia-Fang Chang, Hsuan-Chih Kuo, Hung-Ming Wang, Yung-Chia Kuo, Ching-Ting Wang, Li-Chin Chen, and Jason Chia-Hsun Hsieh. The use of an integrated digital tool to improve the efficiency of multidisciplinary tumor boards—a prospective trial in taiwan. Cancers, 17(3):444, 2025
2025
-
[7]
Adapted large language models can out- perform medical experts in clinical text sum- marization.Nature medicine, 30(4):1134–1142, 2024
Dave Van Veen, Cara Van Uden, Louis Blanke- meier, Jean-Benoit Delbrouck, Asad Aali, Chris- tian Bluethgen, Anuj Pareek, Malgorzata Po- lacin, Eduardo Pontes Reis, Anna Seehofnerová, et al. Adapted large language models can out- perform medical experts in clinical text sum- marization.Nature medicine, 30(4):1134–1142, 2024
2024
-
[8]
Health system-scale language models are all-purpose prediction engines
Lavender Yao Jiang, Xujin Chris Liu, Nima Pour Nejatian, Mustafa Nasir-Moin, Duo Wang, Anas Abidin, Kevin Eaton, Howard Antony Riina, Ilya Laufer, Paawan Punjabi, et al. Health system-scale language models are all-purpose prediction engines. Nature, 619(7969):357–362, 2023
2023
-
[9]
Timer: Temporal instruc- tion modeling and evaluation for longitudinal clinical records.npj Digital Medicine, 8(1):577, 2025
Hejie Cui, Alyssa Unell, Bowen Chen, Ja- son Alan Fries, Emily Alsentzer, Sanmi Koyejo, and Nigam H Shah. Timer: Temporal instruc- tion modeling and evaluation for longitudinal clinical records.npj Digital Medicine, 8(1):577, 2025
2025
-
[10]
A framework to assess clinical safety and hallucination rates of llms for medical text summarisation.NPJ digital medicine, 8(1):274, 2025
Elham Asgari, Nina Montaña-Brown, Magda Dubois, Saleh Khalil, Jasmine Balloch, Joshua Au Yeung, and Dominic Pimenta. A framework to assess clinical safety and hallucination rates of llms for medical text summarisation.NPJ digital medicine, 8(1):274, 2025
2025
-
[11]
Retrieval- augmented generation for knowledge- intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval- augmented generation for knowledge- intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[12]
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. Beir: A heterogenous benchmark for zero-shot eval- uation of information retrieval models.arXiv preprint arXiv:2104.08663, 2021
Pith/arXiv arXiv 2021
-
[13]
Clinical entity augmented retrieval for clinical information extraction.NPJ digital medicine, 8(1):45, 2025
Ivan Lopez, Akshay Swaminathan, Karthik Vedula, Sanjana Narayanan, Fateme Nateghi Haredasht, Stephen P Ma, April S Liang, Steven Tate, Manoj Maddali, Robert Joseph Gallo, et al. Clinical entity augmented retrieval for clinical information extraction.NPJ digital medicine, 8(1):45, 2025
2025
-
[14]
Large language model integrations in cancer decision-making: a systematic review and meta-analysis.NPJ Digital Medicine, 8(1):450, 2025
Yuexing Hao, Zhiwen Qiu, Jason Holmes, Corinna E Löckenhoff, Wei Liu, Marzyeh Ghas- semi, and Saleh Kalantari. Large language model integrations in cancer decision-making: a systematic review and meta-analysis.NPJ Digital Medicine, 8(1):450, 2025
2025
-
[15]
Healthcare agent orchestrator (hao) for pa- tient summarization in molecular tumor boards
Matthias Blondeel, Noel Codella, Sam Preston, Hao Qiu, Leonardo Schettini, Frank Tuan, Wen- wai Yim, Smitha Saligrama, Mert Öz, Shrey Jain, et al. Healthcare agent orchestrator (hao) for pa- tient summarization in molecular tumor boards. arXiv preprint arXiv:2509.06602, 2025
arXiv 2025
-
[16]
Ob- servational health data sciences and informat- ics (ohdsi): opportunities for observational re- searchers.Studies in health technology and infor- matics, 216:574, 2015
George Hripcsak, Jon D Duke, Nigam H Shah, Christian G Reich, Vojtech Huser, Martijn J Schuemie, Marc A Suchard, Rae Woong Park, Ian Chi Kei Wong, Peter R Rijnbeek, et al. Ob- servational health data sciences and informat- ics (ohdsi): opportunities for observational re- searchers.Studies in health technology and infor- matics, 216:574, 2015
2015
-
[17]
Yong Shang, Yu Tian, Kewei Lyu, Tianshu Zhou, Ping Zhang, Jianghua Chen, and Jingsong Li. Electronic health record–oriented knowledge graph system for collaborative clinical decision support using multicenter fragmented medical data: design and application study.Journal of Medical Internet Research, 26:e54263, 2024. 21
2024
-
[18]
Tim Ellis-Caleo, Timothy Keyes, Nerissa Am- bers, Faraah Bekheet, Wen-wai Yim, Nikesh Kotecha, Nigam H. Shah, and Joel Neal. De- velopment, evaluation, and deployment of a multi-agent system for thoracic tumor board. arXiv preprint arXiv:2604.12161, 2026
Pith/arXiv arXiv 2026
-
[19]
Medical event data standard (meds): Facilitating ma- chine learning for health
Bert Arnrich, Edward Choi, Jason Alan Fries, Matthew BA McDermott, Jungwoo Oh, Tom Pollard, Nigam Shah, Ethan Steinberg, Michael Wornow, and Robin van de Water. Medical event data standard (meds): Facilitating ma- chine learning for health. InICLR 2024 Work- shop on Learning from Time Series For Health, pages 03–08, 2024
2024
-
[20]
Chaudhari
Yan-Ran Joyce Wang and Akshay S. Chaudhari. Ai-driven smart patient retrieval for precision oncology.Nature Reviews Cancer, 26(5):305–307, 2026
2026
-
[21]
Death by 1,000 clicks: Where electronic health records went wrong.Kaiser Health News, 18, 2019
Fred Schulte and Erika Fry. Death by 1,000 clicks: Where electronic health records went wrong.Kaiser Health News, 18, 2019
2019
-
[22]
Judging llm-as-a-judge with mt- bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt- bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
2023
-
[23]
node_type
Philip Chung, Akshay Swaminathan, Alex J Goodell, Yeasul Kim, S Momsen Reincke, Lichy Han, Ben Deverett, Mohammad Amin Sadeghi, Abdel-Badih Ariss, Marc Ghanem, et al. Ver- ifying facts in patient care documents gener- ated by large language models using electronic health records.NEJM AI, 3(1):AIdbp2500418, 2025. 22 Supplementary Information Supplementary ...
2025
-
[24]
BASELINE: Background predating diagnosis (smoking, COPD, allergies) Anchor: one day before first oncological event
-
[25]
DIAGNOSIS: Diagnostic workup -> treatment decision Includes ALL imaging, biopsies, pathology, molecular testing Anchor: specialist visit or first diagnostic procedure
-
[26]
TREATMENT LINES: Each line of therapy until change needed Includes systemic therapy, surgery, radiation (as planned) Contains all imaging, labs, symptoms during line CRITICAL: Event that ENDS line (progression, toxicity) stays IN episode Anchor: treatment start date
-
[27]
episodes
POST-ONCOLOGICAL: Hospice, palliative only, end of active treatment Anchor: transition decision or hospice enrollment OUTPUT (strict JSON, NO event_ids - auto-populated by date range): { "episodes": [ { "episode_id": "temp", "kind": "baseline|diagnosis|treatment_line|post_oncological", "start_date": "YYYY-MM-DD", "end_date": "YYYY-MM-DD", "anchor_event_id...
-
[28]
CONVERSATION HISTORY - Recent chat context
-
[29]
CLINICAL EPISODES (TOA) - High-level narrative phases
-
[30]
DETAILED TIMELINE (TOA Events) - Complete chronological log
-
[31]
PATIENT DATA - Structured JSONs (patient_info, summary)
-
[32]
NCCN v2.2024
RECENT EHR DATA - Last 10k chars of raw XML UNDERSTANDING PATIENT: - Form timeline from TOA events (most reliable source) - Cross-reference episodes for treatment phases - Patient may have transferred to Stanford - history in notes - Contradictions exist - base decisions on data support SCOPE: Base answers on provided data + latest guidelines (NCCN, ESMO,...
2024
-
[33]
Extract comprehensive demographics, medical history, tumor information
-
[34]
Use timeline for chronological progression context
-
[35]
Provide complete TNM staging (latest IASLC guidelines)
-
[36]
Cross-reference timeline events to validate dates
-
[37]
Use medical abbreviations (NSCLC, COPD, ECOG, PD-L1)
-
[38]
John/Jane Doe
If name unclear (de-identification): use "John/Jane Doe" 39 OUTPUT: Valid JSON with EXACT keys (spaces, NOT underscores): PATIENT DEMOGRAPHICS: name, date_of_birth, sex, height_cm, weight_kg previous_conditions # chronic diseases OR major past events # (e.g., "COPD, Stroke (2011)") allergies # list smoking_history # (e.g., "40 pack-years; quit 2015") medi...
2011
-
[39]
Builds context: patient data + tumor board decisions (if any)
-
[40]
Calls tumor board note prompt with GPT-4.1
-
[41]
Saves tosummary.jsonfor UI display E.5 Accuracy Evaluation (LLM-as-Judge) Prompt Source:quick_eval.py::judge_all_variables|Model:GPT-5 The system prompt below was used verbatim to score each variable evaluation in the primary accuracy assessment. Only the {N_VARS} placeholder (set to 16 as run; DNR/code status is scored by the judge but excluded from the ...
-
[42]
Unknown" or
Honest uncertainty is correct. When the EHR genuinely does not document a field, "Unknown" or "Not documented" or "No" (where appropriate per the rules below) is a SCORE 10 answer — not a 7. The pipeline is being honest
-
[43]
No" when undocumented (DNR, Metastasis with no findings, Radiation when none given),
Default-No is correct when not documented. For binary/safety fields 41 where the rubric specifies a default of "No" when undocumented (DNR, Metastasis with no findings, Radiation when none given), "No" without further qualification scores 10
-
[44]
NKDA" =
Equivalent phrasings score the same. "NKDA" = "No Known Allergies" = "None". "Former smoker, 30py, quit 2010" = "30 pack-year former smoker, quit 2010-04". Range vs single value for ECOG ("1-2" vs "1") both score 10 when both are documented
2010
-
[45]
No — PET ruled out initial concern
Verbose != wrong. Rich context alongside the core answer (e.g., "No — PET ruled out initial concern") scores the same as the bare answer ("No"). Do not deduct for extra clinically relevant detail
-
[46]
Order in lists does not matter as long as the content is right and the most relevant items are recognizable
-
[47]
Yes (sites)
Form/style preferences are not deductions. Do not deduct for: bullets vs prose, dates as YYYY-MM-DD vs YYYY-MM, "Yes (sites)" vs "Yes - sites", single-word vs sentence. DEDUCT for: (a) factually wrong values, (b) hallucinations (entities not in the EHR), (c) missed decision-relevant findings actually documented in the EHR, (d) inverted clinical meaning (F...
1957
-
[48]
Setup.Copy the patient’s MEDS graphml into a per-run working directory and extract structured demographics from the MEDS XML
-
[49]
Chunk planning.Serialize the MEDS Graph to text in temporal order and partition into encounter- aligned chunks (∼120k characters per chunk by default)
-
[50]
Sub-agents run concurrently
Parallel chunk extraction.For each chunk, invoke an LLM sub-agent that returns structured TOA event records together withsource_event_refsfor provenance. Sub-agents run concurrently
-
[51]
Unifier.Deduplicate events across chunks using union-find over shared source_event_refs; merge background facts; resolve ambiguous cross-chunk merges via an LLM-mediated sub-agent for the residual cases
-
[52]
Confirmed events are appended to the timeline
Radiology alignment safety net.Cross-check the TOA timeline against deterministically retrievable imaging dates from the OMOP structured fields; for candidate dates not represented in the timeline within ±3 days, invoke a per-date verifier sub-agent to confirm whether a real imaging study occurred. Confirmed events are appended to the timeline
-
[53]
Episode synthesis.A single LLM call segments the unified timeline into baseline, diagnosis, treatment- line, and post-oncological episodes (Section 2.1.3, Appendix D)
-
[54]
After stage 7 the patient is dashboard-ready
Display generation.A single holistic LLM call produces all patient-info fields and the pre-tumor-board summary note (Appendix E.4.1, Appendix E.4.2). After stage 7 the patient is dashboard-ready. Optional evaluation stages (LLM-as-judge scoring against ground truth) are run separately during development and are not part of the production build path. H.2 D...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.