The Anatomy of the CTC Oracle Gap: Acoustic Exhaustion and Linguistic Recovery
Pith reviewed 2026-06-26 08:16 UTC · model grok-4.3
The pith
CTC-internal scores lose all ability to rank hypotheses by error rate once N-best lists exceed 16 entries, because blank paths proliferate and saturate acoustic discrimination.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CTC-internal representations reach a hard saturation point where no recombination of acoustic signals improves hypothesis ranking; the remaining oracle gap is purely linguistic and can be closed by external language-model posteriors in MBR decoding.
What carries the argument
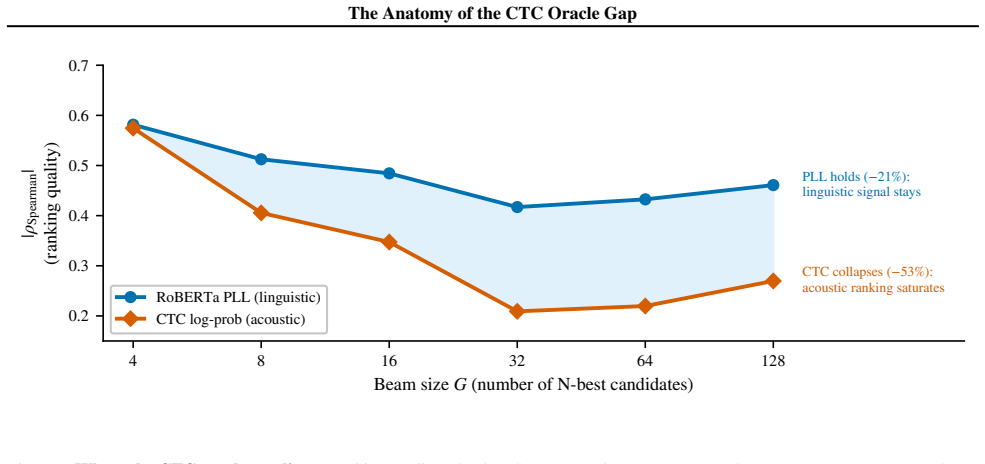
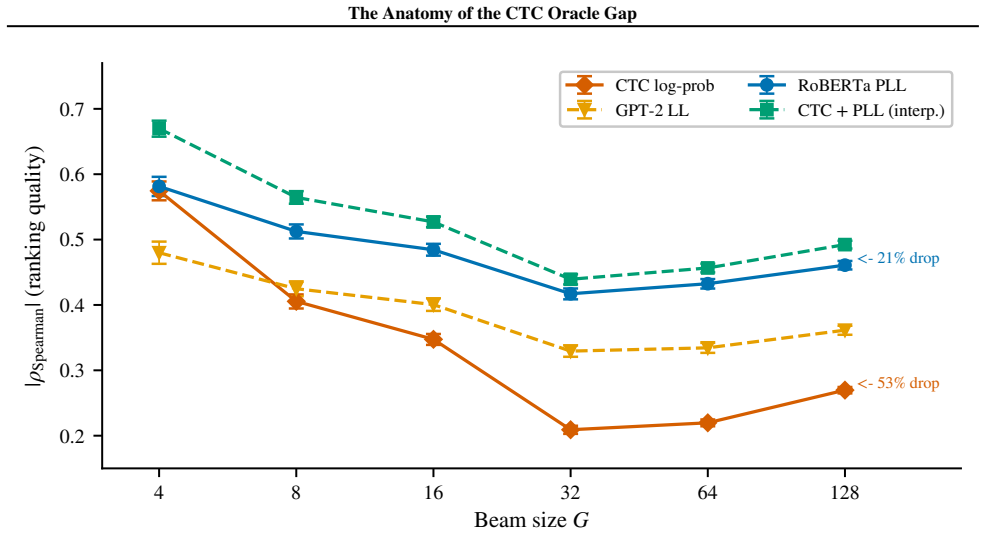
Blank-path proliferation inside CTC that drives Spearman rho degradation from -0.574 to -0.270 and thereby exhausts the discriminative capacity of CTC scores.
If this is right
- No CTC-internal scoring strategy produces statistically significant WER gains over greedy decoding once G reaches 16.
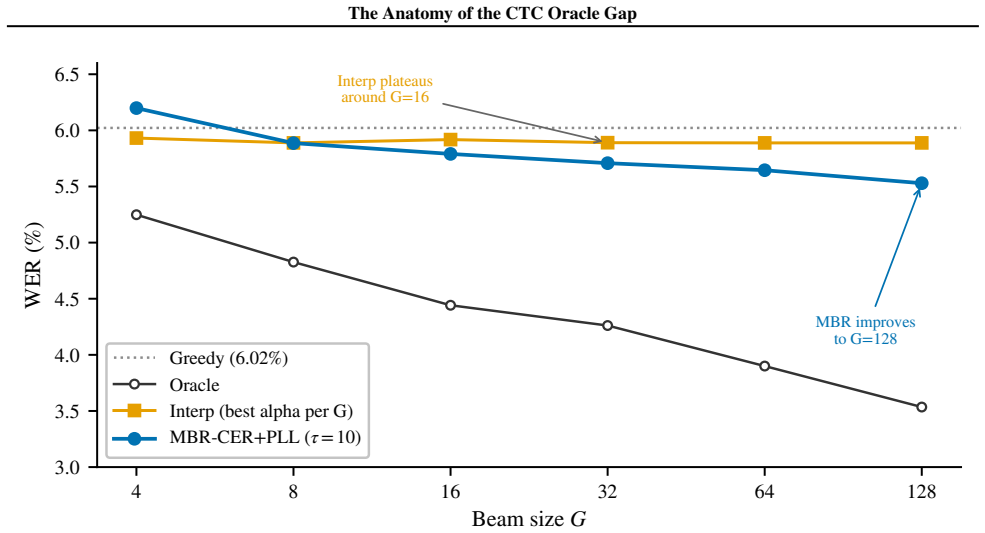
- MBR-CER with RoBERTa PLL at tau=10 and G=128 reaches 5.42 percent WER on test-other versus 5.96 percent greedy.
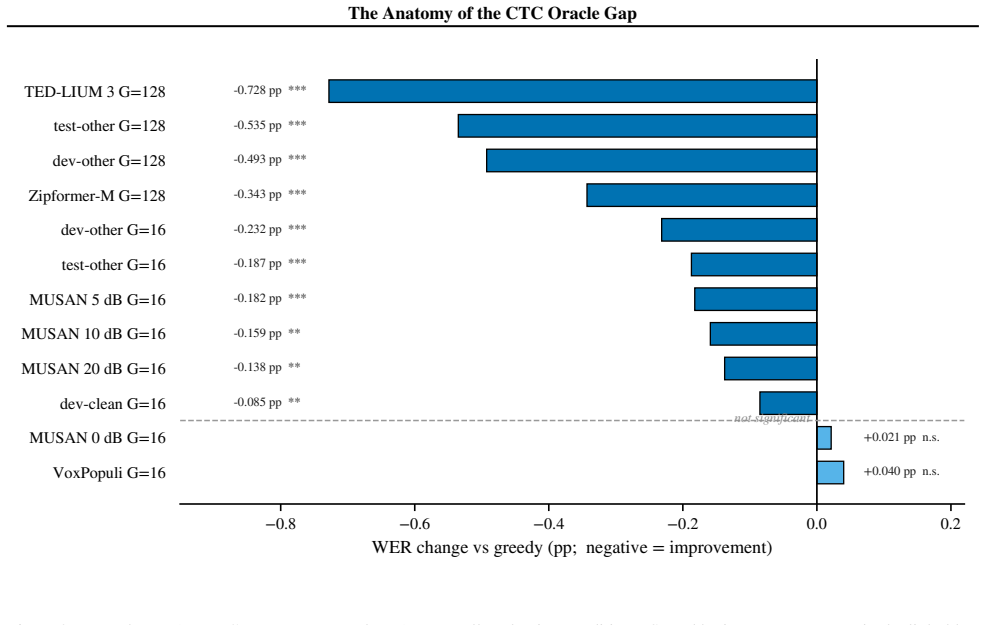
- The same RoBERTa PLL recipe delivers significant gains in 11 of 13 conditions across two Zipformer models, three corpora, and four noise levels without retuning.
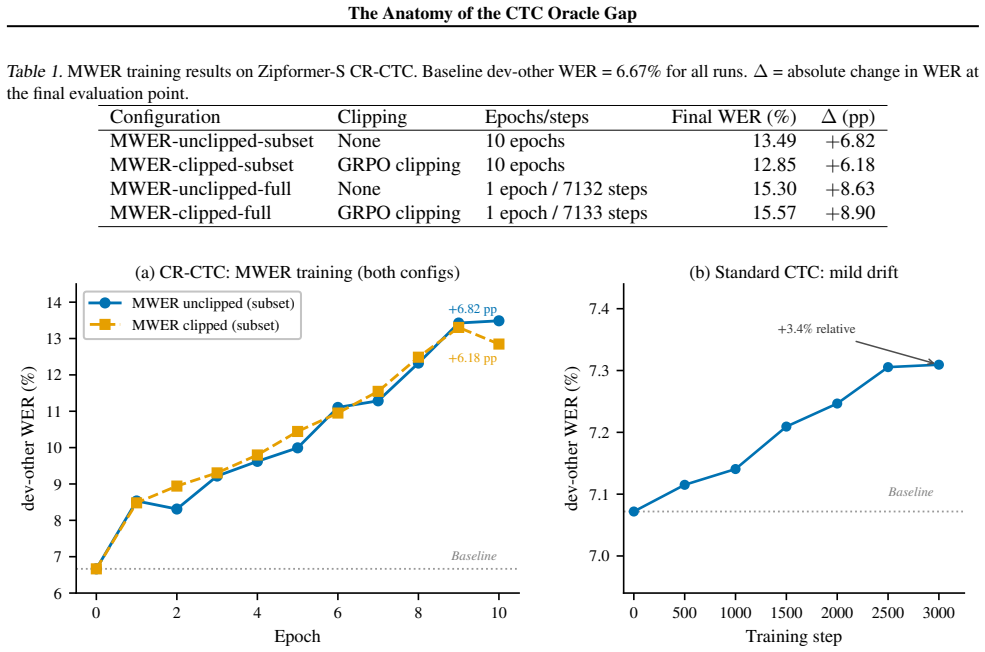
- Standard MWER training via CTC forward-backward collapses at near-converged checkpoints because the 0.007 pp training oracle gap supplies no usable reward signal.
Where Pith is reading between the lines
- Systems that keep enlarging N-best lists without adding external linguistic information will hit a hard performance wall set by CTC saturation.
- The contrast between CTC rho degradation and stable RoBERTa PLL suggests that early fusion of language-model scores inside the decoder could avoid the need for large post-hoc MBR rescoring.
- The tiny training oracle gap at convergence implies that further sequence-level fine-tuning on CTC models may require either stronger oracles or entirely different reward formulations.
Load-bearing premise
That the observed Spearman rho drop is caused specifically by blank-path proliferation rather than other CTC decoding dynamics, and that MBR gains with RoBERTa confirm a purely linguistic bottleneck without experimental confounds.
What would settle it
A controlled experiment in which CTC scores at G=128 recover strong negative correlation with WER after blank paths are removed or suppressed would falsify the saturation claim.
Figures
read the original abstract
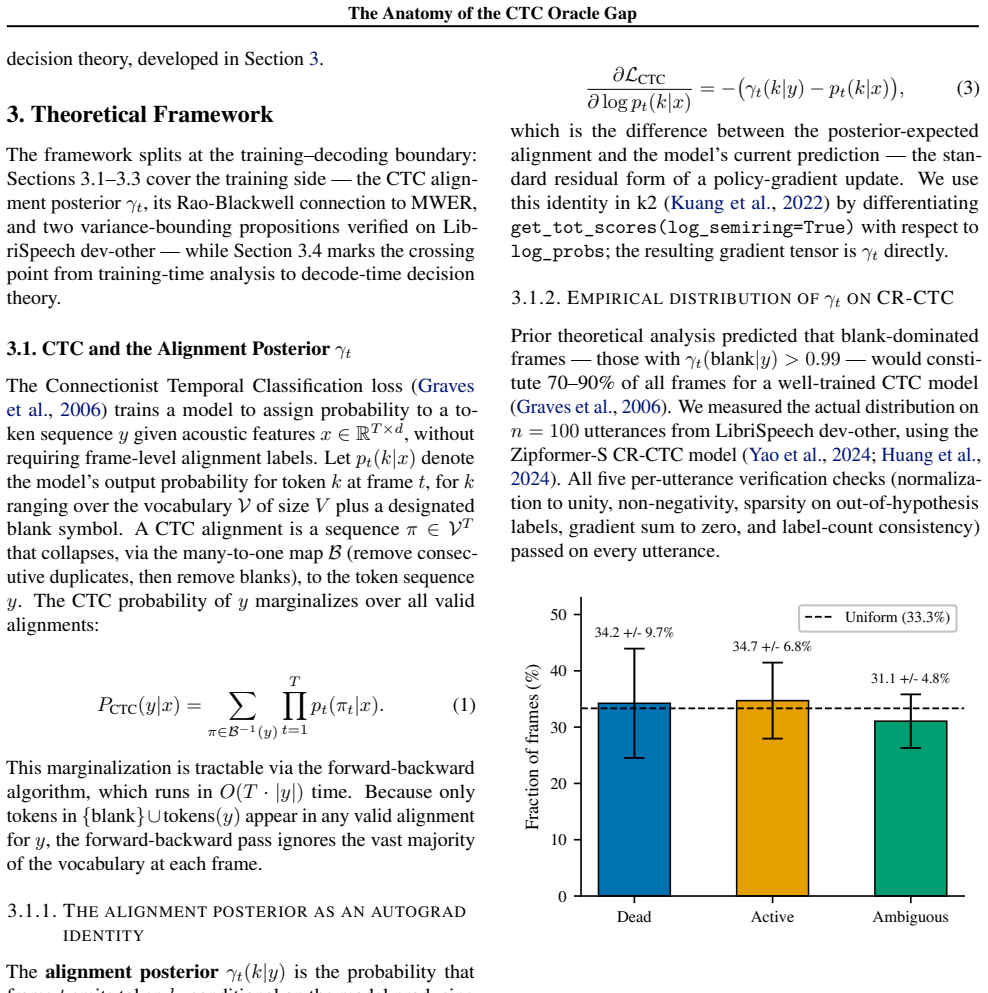
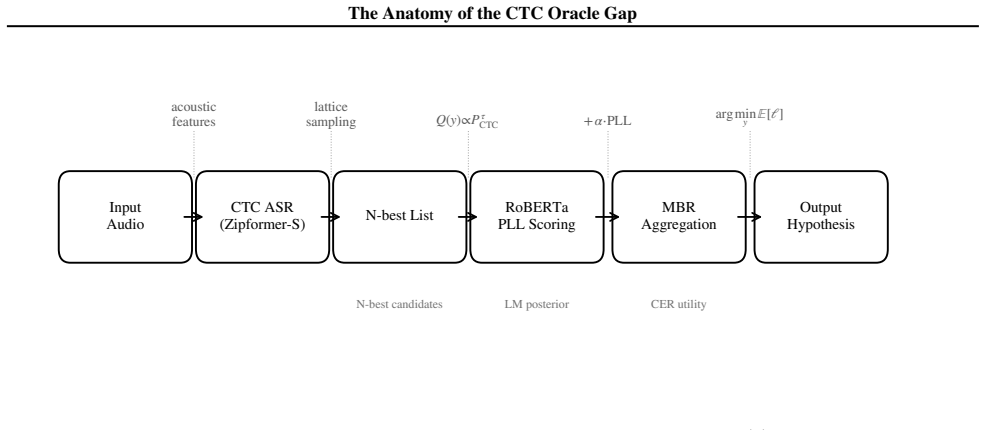
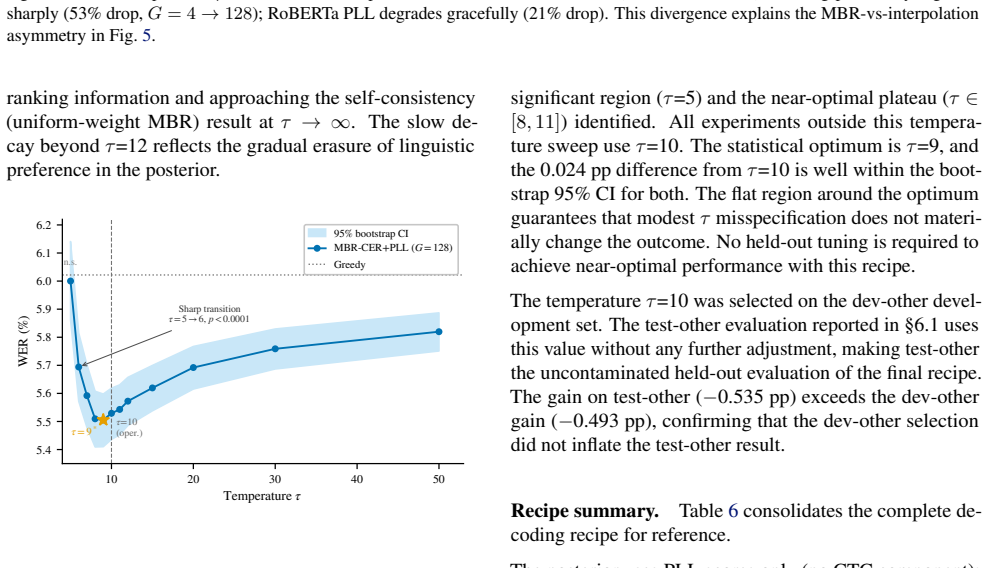
We study the limits of CTC-internal scoring for N-best hypothesis selection and locate the information bottleneck separating acoustic confidence from linguistic plausibility. Eleven CTC-internal and acoustic-feature scoring strategies produce no statistically significant WER improvement over greedy decoding on LibriSpeech dev-other at G=16 (all p > 0.05). The exhaustion is systematic: CTC's Spearman $\rho$ between hypothesis score and per-utterance WER degrades from -0.574 at G=4 to -0.270 at G=128, a 53% loss driven by blank-path proliferation. This establishes that the discriminative capacity of CTC-internal representations is saturated: no recombination of acoustic signals can close the oracle gap. Confirming that the bottleneck is linguistic, not acoustic, external linguistic information introduced via MBR decoding breaks through it. MBR-CER decoding with a RoBERTa pseudo-log-likelihood (PLL) posterior ($\tau$=10, G=128) achieves 5.42% WER on held-out LibriSpeech test-other (greedy 5.96%, $\Delta$=-0.535 pp, p<0.0001, 9.0% relative). RoBERTa PLL $\rho$ degrades only 21% over the same range, retaining discriminating power where CTC loses it. Applied without retuning across two Zipformer architectures, three domains (LibriSpeech, TED-LIUM 3, VoxPopuli), and four MUSAN noise levels, the recipe gives significant gains in 11 of 13 conditions. On the training side, standard MWER training via the CTC forward-backward algorithm implements Rao-Blackwellized REINFORCE at the output projection (variance about 3x below Viterbi). Yet sequence-level fine-tuning fails at near-converged checkpoints: all four MWER configurations on CR-CTC collapse (+6.18 to +8.90 pp WER), as a training oracle gap of 0.007 pp provides no usable reward signal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates the CTC oracle gap in ASR by testing eleven CTC-internal and acoustic scoring strategies on LibriSpeech, reporting no statistically significant WER gains over greedy decoding (all p > 0.05 at G=16). It documents a 53% degradation in Spearman ρ between hypothesis score and WER (from -0.574 at G=4 to -0.270 at G=128) attributed to blank-path proliferation, concluding that CTC-internal representations are saturated and cannot close the oracle gap via acoustic recombination. It shows that MBR decoding with RoBERTa pseudo-log-likelihood posteriors achieves significant WER reductions (e.g., 5.42% vs. 5.96% greedy on test-other), with gains generalizing across architectures, domains, and noise levels, while MWER training collapses near convergence due to a negligible training oracle gap.
Significance. If the central saturation claim and its attribution hold, the work provides a mechanistic account of why CTC requires external linguistic information and supplies a practical, retuning-free MBR recipe that yields consistent gains. The multi-domain validation and explicit comparison to MWER training strengthen the contribution to understanding information bottlenecks in sequence models.
major comments (3)
- [Abstract / Results] Abstract and results on rho degradation: The claim that the 53% Spearman ρ drop is specifically driven by blank-path proliferation lacks an isolating control that varies only blank proliferation while holding beam pruning, length normalization, and forward-backward marginalization fixed; without this, the degradation could arise from generic N-best list statistics rather than CTC-internal saturation.
- [Abstract] Abstract: Reported p-values (e.g., p<0.0001 for MBR gains) and cross-condition results are presented without details on utterance counts per condition, variance estimation method, or correction for multiple comparisons, leaving the statistical support for the saturation claim and generalization unverifiable from the given information.
- [Training experiments] Training results: The assertion that MWER training fails because the 0.007 pp training oracle gap supplies no usable reward signal requires explicit quantification of how this gap was computed (e.g., via which oracle) and why it is below the threshold for effective REINFORCE updates, as this is load-bearing for the claim that sequence-level fine-tuning is ineffective at convergence.
minor comments (1)
- [Abstract] Notation for G (beam size or hypothesis count) and τ (temperature) should be defined at first use with explicit ranges tested.
Simulated Author's Rebuttal
We thank the referee for the insightful comments, which help improve the clarity and rigor of our work. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results on rho degradation: The claim that the 53% Spearman ρ drop is specifically driven by blank-path proliferation lacks an isolating control that varies only blank proliferation while holding beam pruning, length normalization, and forward-backward marginalization fixed; without this, the degradation could arise from generic N-best list statistics rather than CTC-internal saturation.
Authors: The comparison between CTC-internal scores and RoBERTa PLL posteriors is performed on identical N-best lists generated under the same beam search parameters. The 53% degradation in Spearman ρ is observed exclusively for CTC scores, whereas RoBERTa PLL exhibits only a 21% degradation over the same range of G. This differential behavior on the same hypotheses controls for generic N-best list statistics, beam pruning, length normalization, and other factors, isolating the effect to CTC's internal representations and blank-path proliferation. revision: no
-
Referee: [Abstract] Abstract: Reported p-values (e.g., p<0.0001 for MBR gains) and cross-condition results are presented without details on utterance counts per condition, variance estimation method, or correction for multiple comparisons, leaving the statistical support for the saturation claim and generalization unverifiable from the given information.
Authors: We agree that additional statistical details are necessary for verifiability. The LibriSpeech test-other set contains 2939 utterances. P-values were computed using paired t-tests on per-utterance WER differences with bootstrap variance estimation (1000 resamples). No multiple comparison correction was applied as the primary comparisons were pre-specified. We will include these details in a revised Methods or Appendix section. revision: yes
-
Referee: [Training experiments] Training results: The assertion that MWER training fails because the 0.007 pp training oracle gap supplies no usable reward signal requires explicit quantification of how this gap was computed (e.g., via which oracle) and why it is below the threshold for effective REINFORCE updates, as this is load-bearing for the claim that sequence-level fine-tuning is ineffective at convergence.
Authors: The training oracle gap of 0.007 pp was computed as the difference in WER between the greedy decoding output and the best hypothesis in the 128-best list (selected by minimum WER against the training reference transcript) at the converged checkpoint. This near-zero gap indicates that the model has already achieved near-optimal performance on the training distribution, leaving insufficient variance in the reward signal for effective policy gradient updates via REINFORCE. We will add this explicit quantification and a brief discussion of the reward signal threshold to the revised manuscript. revision: yes
Circularity Check
No significant circularity; empirical claims rest on held-out measurements.
full rationale
The paper reports direct experimental results: 11 CTC-internal scoring strategies yield no WER gain (p>0.05) on LibriSpeech dev-other, Spearman ρ degrades from -0.574 to -0.270 across G=4 to G=128, and MBR with RoBERTa PLL yields 5.42% WER vs. 5.96% greedy. These are measured quantities on held-out data across domains and noise levels. No equations, fitted parameters, or self-citations are shown that reduce the saturation claim or oracle-gap conclusion to inputs by construction. The derivation chain consists of empirical comparisons rather than self-referential definitions or renamed fits.
Axiom & Free-Parameter Ledger
free parameters (2)
- tau =
10
- G =
128
axioms (1)
- domain assumption MBR decoding with RoBERTa PLL introduces purely linguistic information independent of the CTC acoustic model
Reference graph
Works this paper leans on
-
[1]
Freitag, M., Grangier, D., Tan, Q., and Liang, B
arXiv:2309.10966. Freitag, M., Grangier, D., Tan, Q., and Liang, B. High- quality rather than high model probability: Minimum Bayes risk decoding with neural metrics.Transactions of the Association for Computational Linguistics, 10:811– 825,
-
[2]
On using monolingual corpora in neural machine translation
Gülçehre, Ç., Firat, O., Xu, K., Cho, K., Barrault, L., Lin, H.-C., Bougares, F., Schwenk, H., and Bengio, Y . On using monolingual corpora in neural machine translation. arXiv preprint arXiv:1503.03535,
-
[3]
TED-LIUM 3: Twice as much data and corpus repartition for experiments on speaker adaptation
Hernandez, F., Nguyen, V ., Ghannay, S., Tomashenko, N., and Estève, Y . TED-LIUM 3: Twice as much data and corpus repartition for experiments on speaker adaptation. arXiv preprint arXiv:1805.04699,
-
[4]
CR-CTC: Consistency regularization on CTC for improved speech recognition
Huang, R., Ye, Z., Tan, T., and Li, J. CR-CTC: Consistency regularization on CTC for improved speech recognition. arXiv preprint arXiv:2407.21188,
-
[5]
RoBERTa: A robustly optimized BERT pretraining ap- proach.arXiv preprint arXiv:1907.11692,
Liu, Y ., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., and Stoyanov, V . RoBERTa: A robustly optimized BERT pretraining ap- proach.arXiv preprint arXiv:1907.11692,
Pith/arXiv arXiv 1907
-
[6]
Recurrent neural network based language model
Mikolov, T., Karafiat, M., Burget, L., ˇCernocký, J., and Khudanpur, S. Recurrent neural network based language model. InProceedings of Interspeech 2010, pp. 1045– 1048,
2010
-
[7]
S., Chan, W., Zhang, Y ., Chiu, C.-C., Zoph, B., Cubuk, E
Park, D. S., Chan, W., Zhang, Y ., Chiu, C.-C., Zoph, B., Cubuk, E. D., and Le, Q. V . SpecAugment: A simple data augmentation method for automatic speech recogni- tion. InProceedings of Interspeech 2019, pp. 2613–2617,
2019
-
[8]
J., Marcheret, E., Mroueh, Y ., Ross, J., and Goel, V
Rennie, S. J., Marcheret, E., Mroueh, Y ., Ross, J., and Goel, V . Self-critical sequence training for image captioning. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 7008–7024,
2017
-
[9]
Sanh, V ., Debut, L., Chaumond, J., and Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108,
Pith/arXiv arXiv 1910
-
[10]
Optimizing expected word error rate via sam- pling for speech recognition
Shannon, M. Optimizing expected word error rate via sam- pling for speech recognition. InProceedings of Inter- speech 2017, pp. 3953–3957,
2017
-
[11]
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y . K., Wu, Y ., and Guo, D. DeepSeek- Math: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
-
[12]
arXiv:1510.08484. Wang, C., Rivière, M., Lee, A., Wu, A., Talnikar, C., Haziza, D., Williamson, M., Pino, J., and Dupoux, E. V oxPopuli: A large-scale multilingual speech corpus for representa- tion learning, semi-supervised learning and interpretation. InProceedings of the 59th Annual Meeting of the Associa- tion for Computational Linguistics (ACL), pp. ...
-
[13]
Baseline 7.07%; all evaluations use the same greedy decoding pipeline
Standard CTC MWER trajectory (dev-other WER, ∼40% of one epoch). Baseline 7.07%; all evaluations use the same greedy decoding pipeline. The monotonic drift is qualita- tively distinct from the CR-CTC catastrophic collapse: no phase transition, linear increase, endpoint +3.4% relative. Step WER (%)∆(pp) 0 7.07+0.00 500 7.12+0.05 1000 7.14+0.07 1500 7.21+0....
2000
-
[14]
Every value α >0 degraded WER monotonically, reaching 7.14% at α=1.0
input features, subtracting the masked log-probabilities from the standard ones. Every value α >0 degraded WER monotonically, reaching 7.14% at α=1.0. CR-CTC is specifically trained for output consistency under augmentation (Huang et al., 2024): the masked run there- fore does not behave as a qualitatively different “amateur” that makes distinct errors. I...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.