Priority-Aware Learning-Unlearning Correction for Dynamic Decentralized LoRA Fine-Tuning
Pith reviewed 2026-06-26 09:27 UTC · model grok-4.3
The pith
Orthogonal LoRA produces contribution coordinates that allow history-free addition and deletion of device updates in dynamic decentralized fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the orthogonal LoRA mechanism yields post-training contribution coordinates enabling history-free projection addition and deletion in response to membership changes, combined with a priority-aware policy that selects among topology refinement, local correction, proximal damping, and synchronization scheduling according to the dominant residual term, plus a resource allocation algorithm that prioritizes communication across layer groups within per-round wireless constraints.
What carries the argument
The orthogonal LoRA mechanism that yields post-training contribution coordinates enabling history-free projection addition and deletion of device contributions.
If this is right
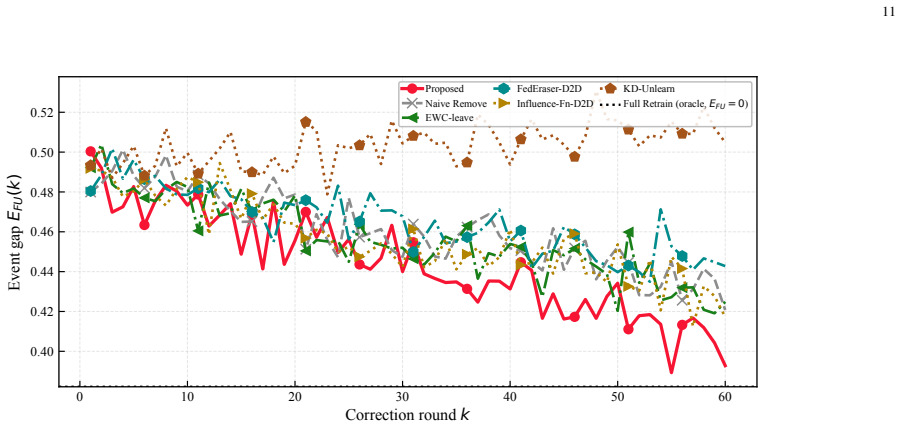
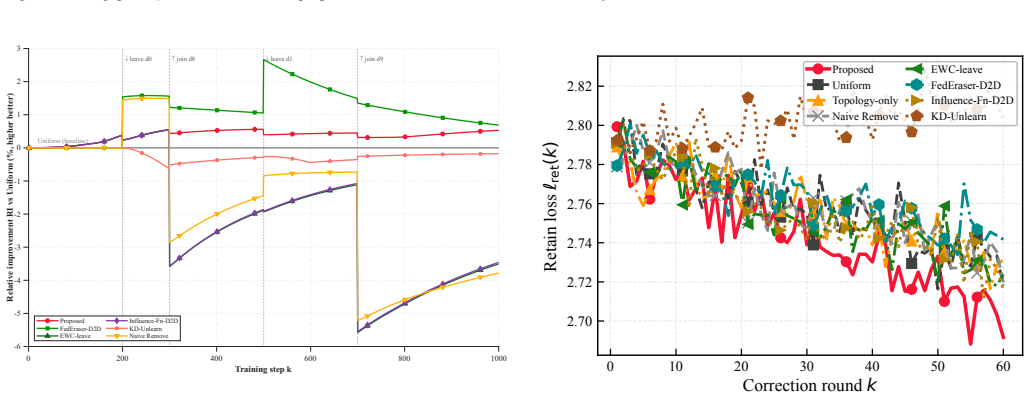
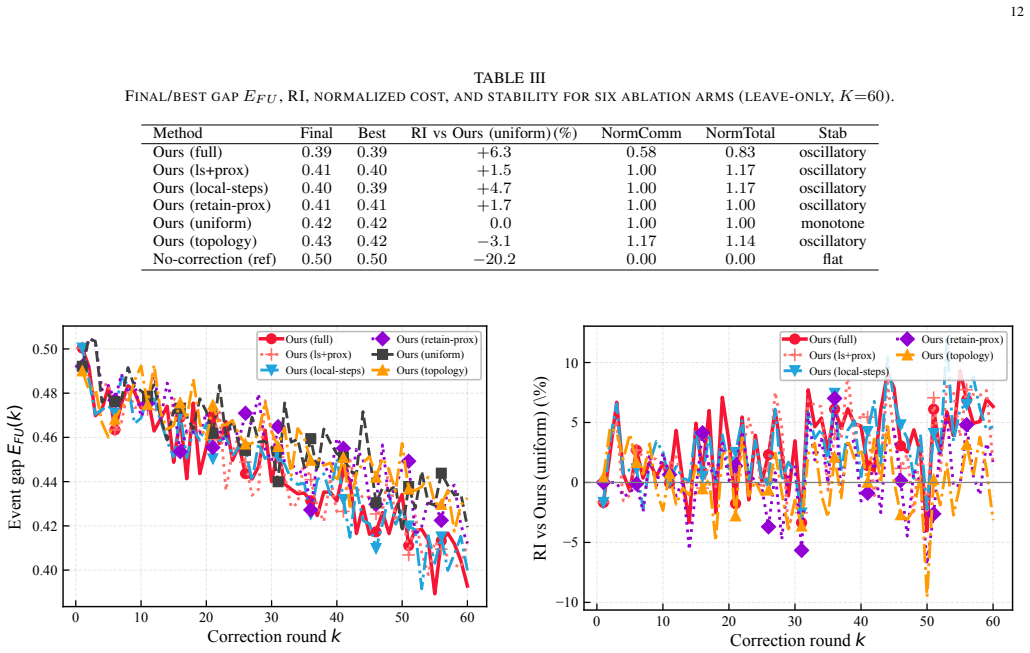
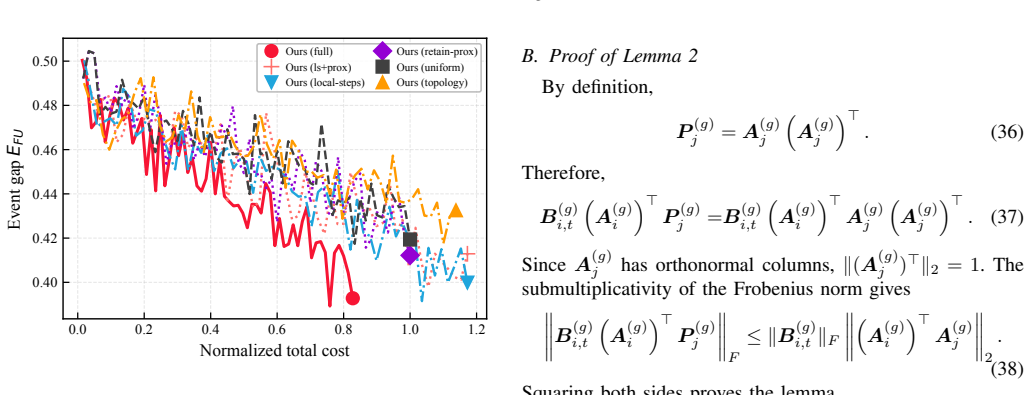
- Robust post-event correction is achieved for both device join and leave events.
- Different residual regimes necessitate distinct correction actions such as topology refinement or proximal damping.
- Communication resources are allocated across layer groups by prioritizing primary bottlenecks within per-round wireless constraints.
Where Pith is reading between the lines
- The coordinate projection approach may reduce storage needs compared with methods that retain full update histories.
- Similar orthogonal decompositions could be explored for other parameter-efficient adapters beyond LoRA.
- The residual-based policy choice could be combined with existing wireless scheduling to test end-to-end latency in larger networks.
Load-bearing premise
The orthogonal LoRA mechanism yields post-training contribution coordinates that enable history-free projection addition and deletion in response to membership changes.
What would settle it
Run a controlled experiment in which a device leaves, the global model is corrected using only the new contribution coordinates with no stored history of prior updates, and the resulting accuracy is compared against full retraining on the remaining devices' data.
Figures

read the original abstract
As large language models (LLMs) are increasingly deployed at the network edge to provide pervasive generative AI services, decentralized federated learning (DFL) provides a vital mechanism for privacy-preserving, domain-specific fine-tuning through peer-to-peer exchanges of parameter-efficient updates. However, the dynamic nature of practical decentralized edge networks, where devices may dynamically join or leave the collaborative training process, requires the system to continuously adapt to new data while selectively removing prior contributions. This correction process remains a significant bottleneck, as individual device updates become deeply entangled within the global fine-tuned parameters. To address this challenge, we propose a priority-aware learning-unlearning correction framework based on orthogonal LoRA that can enhance the knowledge evaluation through topology adjustment. Specifically, we first design an orthogonal LoRA mechanism that yields post-training contribution coordinates, enabling history-free projection addition and deletion in response to membership changes. We then analyze the correction bottleneck and develop a priority-aware policy that selects among topology refinement, local correction, proximal damping, and synchronization scheduling according to the dominant residual term. A resource allocation algorithm is further developed to allocate limited communication across layer groups, prioritizing the primary bottlenecks within per-round wireless constraints. Experiments demonstrate that the proposed framework achieves robust post-event correction for both device join and leave events and validate that different residual regimes necessitate distinct correction actions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a priority-aware learning-unlearning correction framework for dynamic decentralized LoRA fine-tuning in edge networks. It introduces an orthogonal LoRA mechanism to produce contribution coordinates that allow history-free projection-based addition and deletion of device updates upon membership changes. A priority-aware policy is developed to choose among topology refinement, local correction, proximal damping, and synchronization scheduling based on the dominant residual term, complemented by a resource allocation algorithm for communication constraints. The abstract claims that experiments validate robust correction for device join and leave events and that different residual regimes require distinct correction actions.
Significance. If the orthogonality is preserved under decentralized aggregation, the framework could significantly advance dynamic federated learning for LLMs by enabling efficient unlearning without retraining from scratch. The integration of priority policy and resource allocation addresses practical wireless network issues. Credit is given for attempting to tackle the entanglement problem in DFL.
major comments (2)
- [Abstract (orthogonal LoRA paragraph)] Abstract (orthogonal LoRA paragraph): The claim that the orthogonal LoRA mechanism yields post-training contribution coordinates enabling history-free projection addition and deletion is presented without any definition of the inner product, proof of orthogonality preservation after peer-to-peer merging, or analysis of potential cross-terms from aggregation or base model interaction. This is load-bearing for the central claim, as the skeptic concern indicates that loss of independence would corrupt the residual terms used by the priority policy.
- [Abstract (experiments claim)] Abstract (experiments claim): The assertion that experiments demonstrate robust post-event correction and validate that different residual regimes necessitate distinct correction actions provides no quantitative results, baselines, error bars, dataset details, or comparison to existing methods, making it impossible to assess the soundness of the framework's performance claims.
minor comments (1)
- [Abstract] The abstract is dense; clearer separation between the orthogonal LoRA design, the priority policy, and the experimental claims would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions to the abstract will be made for clarity.
read point-by-point responses
-
Referee: [Abstract (orthogonal LoRA paragraph)] The claim that the orthogonal LoRA mechanism yields post-training contribution coordinates enabling history-free projection addition and deletion is presented without any definition of the inner product, proof of orthogonality preservation after peer-to-peer merging, or analysis of potential cross-terms from aggregation or base model interaction. This is load-bearing for the central claim, as the skeptic concern indicates that loss of independence would corrupt the residual terms used by the priority policy.
Authors: The abstract is a high-level summary. The inner product is defined in Section 3.1, orthogonality preservation under decentralized aggregation is proven in Theorem 1 (Section 4), and cross-term analysis appears in Section 5.2. We agree the abstract could better indicate these supporting results and will revise it to reference the orthogonality guarantee. revision: partial
-
Referee: [Abstract (experiments claim)] The assertion that experiments demonstrate robust post-event correction and validate that different residual regimes necessitate distinct correction actions provides no quantitative results, baselines, error bars, dataset details, or comparison to existing methods, making it impossible to assess the soundness of the framework's performance claims.
Authors: Abstracts conventionally omit detailed metrics. Quantitative results with baselines, error bars, dataset details, and comparisons are reported in Section 6. We will revise the abstract to include one or two key quantitative highlights supporting the claims. revision: partial
Circularity Check
No circularity; design claims are self-contained proposals
full rationale
The abstract presents an orthogonal LoRA mechanism as a designed component that produces contribution coordinates enabling projection-based add/delete operations. This is a constructive proposal rather than a derivation that reduces by construction to fitted inputs or prior self-citations. No equations, fitted parameters renamed as predictions, or load-bearing self-citations are visible in the provided text. The priority policy and resource allocation operate on residuals defined by the new design, without the central claims collapsing into tautological redefinitions or imported uniqueness theorems. The derivation chain remains independent of its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language models are few-shot learners,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 1877–1901
2020
-
[2]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V . Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” inAdvances in Neural Information Processing Systems, vol. 35, 2022, pp. 24 824–24 837
2022
-
[3]
Codet5+: Open code large language models for code understanding and generation,
Y . Wang, H. Le, A. D. Gotmare, N. D. Q. Bui, J. Li, and S. C. H. Hoi, “Codet5+: Open code large language models for code understanding and generation,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 1069–1088
2023
-
[4]
A survey on large language model based autonomous agents,
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, and Y . Lin, “A survey on large language model based autonomous agents,”Frontiers of Computer Science, vol. 18, no. 6, p. 186345, 2024
2024
-
[5]
Large Language Models for Networking: Applications, Enabling Techniques, and Challenges,
Y . Huang, H. Du, X. Zhang, D. Niyato, J. Kang, Z. Xiong, S. Wang, and T. Huang, “Large Language Models for Networking: Applications, Enabling Techniques, and Challenges,”IEEE Network, vol. 39, no. 1, pp. 235–242, July 2024
2024
-
[6]
Lora: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” arXiv, vol. 2106.09685, 2021
Pith/arXiv arXiv 2021
-
[7]
Mobile-LLaMA: Instruction Fine-Tuning Open-Source LLM for Network Analysis in 5G Net- works,
K. B. Kan, H. Mun, G. Cao, and Y . Lee, “Mobile-LLaMA: Instruction Fine-Tuning Open-Source LLM for Network Analysis in 5G Net- works,”IEEE Network, vol. 38, no. 5, pp. 76–83, July 2024
2024
-
[8]
Federated Large Language Model: Solutions, Challenges and Future Directions,
J. Hu, D. Wang, Z. Wang, X. Pang, H. Xu, J. Ren, and K. Ren, “Federated Large Language Model: Solutions, Challenges and Future Directions,”IEEE Wireless Communications, vol. 32, no. 4, pp. 82–89, Aug. 2025
2025
-
[9]
Federated Fine-Tuning of LLMs: Framework Comparison and Research Directions,
N. Yan, Y . Su, Y . Deng, and R. Schober, “Federated Fine-Tuning of LLMs: Framework Comparison and Research Directions,”IEEE Communications Magazine, vol. 63, no. 10, pp. 52–58, Sep. 2025. 14
2025
-
[10]
The role of federated learning in a wireless world with foundation models,
Z. Chen, H. H. Yang, Y . Tay, K. F. E. Chong, and T. Q. Quek, “The role of federated learning in a wireless world with foundation models,” IEEE Wireless Commun., vol. 31, no. 3, pp. 42–49, 2024
2024
-
[11]
SoK: Challenges and opportu- nities in federated unlearning,
H. Jeong, S. Ma, and A. Houmansadr, “SoK: Challenges and opportu- nities in federated unlearning,”Proc. Privacy Enhancing Technologies, 2024
2024
-
[12]
A survey on federated unlearning: Challenges, methods, and future directions,
Z. Liu, Y . Jiang, J. Shen, M. Peng, K.-Y . Lam, X. Yuan, and X. Liu, “A survey on federated unlearning: Challenges, methods, and future directions,”ACM Comput. Surv., vol. 57, no. 1, oct 2024. [Online]. Available: https://doi.org/10.1145/3679014
-
[13]
Fedalora: Adaptive local lora aggregation for personalized federated learning in llm,
X. Yi, C. Hu, B. Cai, H. Huang, Y . Chen, and K. Wang, “Fedalora: Adaptive local lora aggregation for personalized federated learning in llm,”IEEE Internet of Things Journal, 2025
2025
-
[14]
Fed-hello: Efficient federated foundation model fine-tuning with heterogeneous lora allocation,
Z. Zhang, P. Liu, J. Xu, and R. Hu, “Fed-hello: Efficient federated foundation model fine-tuning with heterogeneous lora allocation,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 10, pp. 17 556–17 569, 2025
2025
-
[15]
Fedquad: Adaptive layer-wise lora deployment and activation quantization for federated fine-tuning,
R. Li, J. Liu, H. Xu, and L. Huang, “Fedquad: Adaptive layer-wise lora deployment and activation quantization for federated fine-tuning,” IEEE Transactions on Mobile Computing, pp. 1–15, 2025, early access
2025
-
[16]
Decentralized low-rank fine-tuning of large language models,
S. Ghiasvand, M. Alizadeh, and R. Pedarsani, “Decentralized low-rank fine-tuning of large language models,” 2025
2025
-
[17]
Fedsvd: Adaptive orthogonalization for private federated learning with lora,
S. Lee, S. Park, D. B. Lee, D. Wagner, H. Seong, T. Bocklet, J. Lee, and S. J. Hwang, “Fedsvd: Adaptive orthogonalization for private federated learning with lora,” 2025
2025
-
[18]
Wireless federated multi-task LLM fine-tuning via sparse-and- orthogonal LoRA,
N. Yang, H. Ouwen, S. Wang, M. Chen, C. Yin, and T. Q. S. Quek, “Wireless federated multi-task LLM fine-tuning via sparse-and- orthogonal LoRA,”arXiv preprint arXiv:2602.20492, 2026
arXiv 2026
-
[19]
FedEraser: Enabling efficient client-level data removal from federated learning models,
G. Liu, X. Ma, Y . Yang, C. Wang, and J. Liu, “FedEraser: Enabling efficient client-level data removal from federated learning models,” Proc. IEEE/ACM IWQoS, 2021
2021
-
[20]
Heterogeneous decentralized machine unlearning with seed model distillation,
G. Ye, T. Chen, Q. V . H. Nguyen, and H. Yin, “Heterogeneous decentralized machine unlearning with seed model distillation,” 2023
2023
-
[21]
Rethinking machine unlearning for large language models,
S. Liu, Y . Yao, J. Jia, S. Casper, N. Baracaldo, P. Hase, Y . Yao, C. Y . Liu, X. Xu, H. Li, K. R. Varshney, M. Bansal, S. Koyejo, and Y . Liu, “Rethinking machine unlearning for large language models,” 2024
2024
-
[22]
FedU: Federated unlearning via user-side influence approximation forgetting,
X. Chenet al., “FedU: Federated unlearning via user-side influence approximation forgetting,”IEEE Transactions on Dependable and Secure Computing, 2024
2024
-
[23]
Federated unlearning with knowledge distillation,
C. Wu, S. Zhu, and P. Mitra, “Federated unlearning with knowledge distillation,”arXiv preprint arXiv:2201.09441, 2022
arXiv 2022
-
[24]
Certified unlearning in decentralized federated learning,
Z. Zhong, W. Bao, J. Wang, S. Zhang, J. Zhou, L. Lyu, and W. Y . B. Lim, “Certified unlearning in decentralized federated learning,”arXiv preprint arXiv:2601.06436, 2026
arXiv 2026
-
[25]
Unlearning through knowledge overwriting: Reversible feder- ated unlearning via selective sparse adapter,
——, “Unlearning through knowledge overwriting: Reversible feder- ated unlearning via selective sparse adapter,” 2025
2025
-
[26]
FedRecover: Recovering from poisoning attacks in federated learning using historical informa- tion,
X. Cao, J. Jia, Z. Zhang, and N. Z. Gong, “FedRecover: Recovering from poisoning attacks in federated learning using historical informa- tion,”Proc. IEEE S&P, 2023
2023
-
[27]
Federated weighted inter- client transfer for heterogeneous federated learning,
J. Jang, S. Kang, S. Kim, and H. Yoon, “Federated weighted inter- client transfer for heterogeneous federated learning,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[28]
FCCL: Federated continual learning via inter-client distillation,
Q. Yang, F. Zhou, Z. Wang, P. Zhang, X. Liang, Y . Liang, and J. Huang, “FCCL: Federated continual learning via inter-client distillation,” in International Conference on Machine Learning (ICML), 2023
2023
-
[29]
Fed- erated learning with cold-start: A client-level initialization approach,
Y . Chen, Y . Gu, X. Qin, J. Wang, W. Lu, H. Yu, and Q. Yang, “Fed- erated learning with cold-start: A client-level initialization approach,” inAAAI Conference on Artificial Intelligence, 2022
2022
-
[30]
Towards flexible federated learning: Client joining and leaving,
T. Wei, C.-M. Lai, Y . Chen, and L. Huang, “Towards flexible federated learning: Client joining and leaving,” inIEEE Transactions on Neural Networks and Learning Systems, 2023
2023
-
[31]
Distributed learning with dynamic client participation,
K. Ozkara, A. Venkitaraman, and D. G ¨und¨uz, “Distributed learning with dynamic client participation,”IEEE Journal on Selected Areas in Communications, 2023
2023
-
[32]
LoRAHub: Efficient cross-task generalization via dynamic LoRA composition,
C. Huang, Q. Liu, B. Y . Lin, T. Pang, C. Du, and M. Lin, “LoRAHub: Efficient cross-task generalization via dynamic LoRA composition,” arXiv preprint arXiv:2307.10970, 2023
arXiv 2023
-
[33]
Merging LoRA into foundation models via orthogonal subspace methods,
Z. Zhou, C. Gong, Y . Li, S. Zhai, S. Han, and Y . Wu, “Merging LoRA into foundation models via orthogonal subspace methods,”arXiv preprint arXiv:2404.10425, 2024
Pith/arXiv arXiv 2024
-
[34]
Decentralized federated learning: Funda- mentals, state of the art, frameworks, trends, and challenges,
E. T. M. Beltranet al., “Decentralized federated learning: Funda- mentals, state of the art, frameworks, trends, and challenges,”IEEE Communications Surveys & Tutorials, 2023
2023
-
[35]
Can decentralized algorithms outperform centralized algorithms? A case study for decentralized parallel stochastic gradient descent,
X. Lian, C. Zhang, H. Zhang, C.-J. Hsieh, W. Zhang, and J. Liu, “Can decentralized algorithms outperform centralized algorithms? A case study for decentralized parallel stochastic gradient descent,”Proc. NeurIPS, 2017
2017
-
[36]
Beyond spectral gap: The role of the topology in decentralized learning,
T. V ogels, H. Hendrikx, and M. Jaggi, “Beyond spectral gap: The role of the topology in decentralized learning,”Proc. NeurIPS, 2022
2022
-
[37]
On the benefits of multiple gossip steps in communication- constrained decentralized federated learning,
A. Hashemi, A. Acharya, R. Das, H. Vikalo, S. Sanghavi, and I. Dhillon, “On the benefits of multiple gossip steps in communication- constrained decentralized federated learning,”IEEE Transactions on Parallel and Distributed Systems, vol. 33, no. 11, pp. 2727–2739, 2022
2022
-
[38]
Diameter- constrained topology orchestration for communication-convergence tradeoffs in decentralized federated learning,
C. Zhang, X. Lyu, Z. Liang, C. Ren, Y . T. Hou, and Q. Cui, “Diameter- constrained topology orchestration for communication-convergence tradeoffs in decentralized federated learning,”IEEE Transactions on Cognitive Communications and Networking, vol. 12, pp. 5393–5407, 2026
2026
-
[40]
Available: https://arxiv.org/abs/2505.00333
[Online]. Available: https://arxiv.org/abs/2505.00333
-
[41]
Data Divergence-aware Client Selection via Knowledge Graph for Federated LLM Fine- tuning,
B. Zhang, D. Wang, Y . Zhu, and Z. Han, “Data Divergence-aware Client Selection via Knowledge Graph for Federated LLM Fine- tuning,”IEEE Transactions on Mobile Computing, 2025
2025
-
[42]
Zeroth-order over-the-air federated large model tuning over edge networks,
Z. Chen, H. H. Yang, Z. Li, J. Park, and T. Q. Quek, “Zeroth-order over-the-air federated large model tuning over edge networks,”IEEE Wireless Commun. Lett., vol. 14, no. 9, pp. 3002–3006, 2025
2025
-
[43]
Adf-lora: Alternating low-rank aggregation for decentralized federated fine-tuning,
X. Wang, X. Li, Z. Zhou, C. Li, and Y . Liu, “Adf-lora: Alternating low-rank aggregation for decentralized federated fine-tuning,”arXiv, vol. 2511.18291, 2025
arXiv 2025
-
[44]
FedQLoRA: Federated Quantization-Aware LoRA for Large Language Models,
Z. Hu, L. Zhang, S. Dai, S. Gong, and Q. Shi, “FedQLoRA: Federated Quantization-Aware LoRA for Large Language Models,” inInterna- tional Conference on Learning Representations (ICLR), Singapore, Apr. 2025
2025
-
[45]
Adaptive federated LoRA in heterogeneous wireless networks with independent sampling,
Y . Hou, J. Geng, B. Li, X. Tao, J. Wang, X. Xu, and B. Luo, “Adaptive federated LoRA in heterogeneous wireless networks with independent sampling,”arXiv preprint arXiv:2505.23555, 2025
arXiv 2025
-
[46]
LoRA-FAIR: Federated LoRA fine-tuning with aggregation and initialization refinement,
J. Bian, L. Wang, L. Zhang, and J. Xu, “LoRA-FAIR: Federated LoRA fine-tuning with aggregation and initialization refinement,”Proc. ICCV, 2025
2025
-
[47]
H. Zou, Y . Zang, W. Xu, Y . Zhu, and X. Ji, “FlyLoRA: Boosting Task Decoupling and Parameter Efficiency via Implicit Rank-Wise Mixture- of-Experts,”ArXiv, vol. 2510.08396, Oct. 2025
arXiv 2025
-
[48]
ThanoRA: Task Heterogeneity-Aware Multi-Task Low-Rank Adaptation,
J. Liang, W. Huang, X. Guo, G. Wan, B. Du, and M. Ye, “ThanoRA: Task Heterogeneity-Aware Multi-Task Low-Rank Adaptation,”ArXiv, vol. 2505.18640, Sep. 2025. [Online]. Available: https://arxiv.org/abs/ 2505.18640
arXiv 2025
-
[49]
LoRI: Reducing Cross- Task Interference in Multi-Task Low-Rank Adaptation,
J. Zhang, J. You, A. Panda, and T. Goldstein, “LoRI: Reducing Cross- Task Interference in Multi-Task Low-Rank Adaptation,” inConference on Language Modeling (COLM), Montreal, Canada, Oct. 2025
2025
-
[50]
OMoE: Diversifying Mixture of Low-Rank Adaptation by Orthogonal Finetuning,
J. Feng, Z. Pu, T. Hu, D. Li, X. Ai, and H. Wang, “OMoE: Diversifying Mixture of Low-Rank Adaptation by Orthogonal Finetuning,”ArXiv, vol. 2501.10062, Jul. 2025. [Online]. Available: https://arxiv.org/abs/2501.10062
arXiv 2025
-
[51]
G. Hu, Y . Teng, P. Wu, and N. Wang, “FFT-MoE: Efficient Federated Fine-Tuning for Foundation Models via Large-scale Sparse MoE under Heterogeneous Edge,”ArXiv, vol. 2508.18663, Aug. 2025. [Online]. Available: https://arxiv.org/abs/2508.18663
arXiv 2025
-
[52]
Decentralized low-rank fine-tuning of large language models,
S. Ghiasvand, M. Alizadeh, and R. Pedarsani, “Decentralized low-rank fine-tuning of large language models,”arXiv preprint arXiv:2501.15361, 2025
arXiv 2025
-
[53]
Learning to Collaborate: An Orchestrated-Decentralized Framework for Peer-to- Peer LLM Federation,
S. Inderjeet, V .-G. Eleonore, O. Andikan, and S. Motoyoshi, “Learning to Collaborate: An Orchestrated-Decentralized Framework for Peer-to- Peer LLM Federation,”ArXiv, vol. 2601.17133, Jan. 2026. [Online]. Available: https://arxiv.org/abs/2601.17133
arXiv 2026
-
[54]
Token-Level LLM Collaboration via FusionRoute,
N. Xiong, Y . Zhou, H. Zeng, Z. Chen, F. Huang, S. Bi, L. Zhang, and Z. Zhao, “Token-Level LLM Collaboration via FusionRoute,”ArXiv, vol. 2601.05106, Jan. 2026. [Online]. Available: https://arxiv.org/pdf/2601.05106
Pith/arXiv arXiv 2026
-
[55]
Bayesian variational feder- ated learning and unlearning in decentralized networks,
J. Gong, O. Simeone, and J. Kang, “Bayesian variational feder- ated learning and unlearning in decentralized networks,”Proc. IEEE SPAWC, 2021
2021
-
[56]
Fully decentralized certified unlearning,
M. Lamriet al., “Fully decentralized certified unlearning,”arXiv preprint arXiv:2512.08443, 2025
arXiv 2025
-
[57]
Decentralized unlearning for trustworthy ai-generated content ser- vices,
Y . Lin, H. Du, Z. Gao, J. Yao, B. Jiang, D. Niyato, R. Li, and P. Zhang, “Decentralized unlearning for trustworthy ai-generated content ser- vices,”IEEE Network, pp. 1–1, 2024
2024
-
[58]
Hierarchical federated unlearning for large language models,
Y . Zhonget al., “Hierarchical federated unlearning for large language models,”arXiv preprint arXiv:2510.17895, 2025
arXiv 2025
-
[59]
FADE: Selective forgetting via sparse LoRA and self- distillation,
C. R. Kelsch, L. S. B. Pereira, N. Mola, L. H. Arribas, and J. C. S. M. Avedillo, “FADE: Selective forgetting via sparse LoRA and self- distillation,”arXiv preprint arXiv:2602.07058, 2026
arXiv 2026
-
[60]
O3: On large language model continual unlearning,
C. Gao, L. Wang, K. Ding, C. Weng, X. Wang, and Q. Zhu, “O3: On large language model continual unlearning,”Proc. ICLR, 2025
2025
-
[61]
Fast-fedul: A training-free federated unlearning with provable skew resilience,
T. T. Huynh, T. B. Nguyen, P. L. Nguyen, T. T. Nguyen, M. Weidlich, Q. V . H. Nguyen, and K. Aberer, “Fast-fedul: A training-free federated unlearning with provable skew resilience,” 2024
2024
-
[62]
Understanding black-box predictions via influence functions,
P. W. Koh and P. Liang, “Understanding black-box predictions via influence functions,” inProc. ICML, 2017
2017
-
[63]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. Ag ¨uera y Arcas, “Communication-efficient learning of deep networks from decentralized data,”Proc. AISTATS, 2017
2017
-
[64]
Fully decentralized federated learning,
L. Anusha, S. Shubhanshu, J. Tara, and K. Farinaz, “Fully decentralized federated learning,” Montreal, Canada, Dec. 2018
2018
-
[65]
Network topology and communication-computation tradeoffs in decentralized optimization,
A. Nedi ´c, A. Olshevsky, and M. G. Rabbat, “Network topology and communication-computation tradeoffs in decentralized optimization,” Proceedings of the IEEE, vol. 106, no. 5, pp. 953–976, May 2018. 15
2018
-
[66]
Communication-efficient distributed learning: An overview,
X. Cao, T. Bas ¸ar, S. Diggavi, Y . C. Eldar, K. B. Letaief, H. V . Poor, and J. Zhang, “Communication-efficient distributed learning: An overview,” IEEE J. Sel. Areas Commun., vol. 41, no. 4, pp. 851–873, 2023
2023
-
[67]
Decentralized federated learning: Balancing communication and computing costs,
W. Liu, L. Chen, and W. Zhang, “Decentralized federated learning: Balancing communication and computing costs,”IEEE Transactions on Signal and Information Processing over Networks, vol. 8, pp. 131– 143, 2022
2022
-
[68]
Expander graph and communication-efficient decentralized optimization,
Y .-T. Chow, W. Shi, T. Wu, and W. Yin, “Expander graph and communication-efficient decentralized optimization,” inProc. Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, Nov. 2016
2016
-
[69]
Peer-to-peer variational federated learning over arbitrary graphs,
X. Wang, A. Lalitha, T. Javidi, and F. Koushanfar, “Peer-to-peer variational federated learning over arbitrary graphs,”IEEE Journal on Selected Areas in Information Theory, vol. 3, no. 2, pp. 172–182, 2022
2022
-
[70]
Decentralized and model-free federated learning: Consensus-based distillation in function space,
A. Taya, T. Nishio, M. Morikura, and K. Yamamoto, “Decentralized and model-free federated learning: Consensus-based distillation in function space,”IEEE Trans. Signal Inf. Process. Networks, vol. 8, pp. 799–814, Sept. 2022
2022
-
[71]
Bandwidth-aware network topology optimization for decentralized learning,
Y . Chenet al., “Bandwidth-aware network topology optimization for decentralized learning,”arXiv preprint arXiv:2512.07536, 2025
arXiv 2025
-
[72]
X. Liet al., “Towards heterogeneity-aware and energy-efficient topol- ogy optimization for decentralized federated learning,”arXiv preprint arXiv:2508.08278, 2025
arXiv 2025
-
[73]
Feddual: Pair-wise gossip helps federated learning in large decentralized networks,
H. W. Q. Chen, Z. Wang and X. Lin, “Feddual: Pair-wise gossip helps federated learning in large decentralized networks,”IEEE Trans. Inf. Forensics Secur., vol. 18, pp. 335–350, Nov. 2022
2022
-
[74]
Edge-based communication optimization for distributed federated learning,
T. Wang, Y . Liu, X. Zheng, H. N. Dai, W. Jia, and M. Xie, “Edge-based communication optimization for distributed federated learning,”IEEE Transactions on Network Science and Engineering, vol. 9, no. 4, pp. 2015–2024, June. 2022
2015
-
[75]
Accelerating decentralized federated learning in heterogeneous edge computing,
L. Wang, Y . Xu, H. Xu, M. Chen, and L. Huang, “Accelerating decentralized federated learning in heterogeneous edge computing,” IEEE Transactions on Mobile Computing, pp. 1–1, May. 2022
2022
-
[76]
A fairness-aware peer- to-peer decentralized learning framework with heterogeneous devices,
Z. Chen, W. Liao, P. Tian, Q. Wang, and W. Yu, “A fairness-aware peer- to-peer decentralized learning framework with heterogeneous devices,” Future Internet, vol. 8, pp. 23 920–23 935, Apr. 2022
2022
-
[77]
mudfl: A secure microchained decentralized federated learning fabric atop iot networks,
R. Xu and Y . Chen, “mudfl: A secure microchained decentralized federated learning fabric atop iot networks,”IEEE Transactions on Network and Service Management, vol. 19, no. 3, pp. 2677–2688, 2022
2022
-
[78]
Reputation-aware hedonic coalition formation for efficient serverless hierarchical federated learning,
J. S. Ng, W. Y . B. Lim, Z. Xiong, X. Cao, J. Jin, D. Niyato, C. Le- ung, and C. Miao, “Reputation-aware hedonic coalition formation for efficient serverless hierarchical federated learning,”IEEE Transactions on Parallel and Distributed Systems, vol. 33, no. 11, pp. 2675–2686, Dec. 2022
2022
-
[79]
Opportunities of federated learning in connected, cooperative, and au- tomated industrial systems,
S. Savazzi, M. Nicoli, M. Bennis, S. Kianoush, and L. Barbieri, “Opportunities of federated learning in connected, cooperative, and au- tomated industrial systems,”IEEE Communications Magazine, vol. 59, no. 2, pp. 16–21, 2021
2021
-
[80]
Byzantine-resilient decentralized stochastic gradient descent,
S. Guo, T. Zhang, H. Yu, X. Xie, L. Ma, T. Xiang, and Y . Liu, “Byzantine-resilient decentralized stochastic gradient descent,”IEEE Trans. Circuits Syst. Video Technol., vol. 32, no. 6, pp. 4096–4106, June 2022
2022
-
[81]
Towards cooperative federated learning over heterogeneous edge/fog networks,
S. Wang, S. Hosseinalipour, V . B. Aggarwal, C. G. Brinton, D. J. Love, W. Su, and M. Chiang, “Towards cooperative federated learning over heterogeneous edge/fog networks,”IEEE Communications Magazine, vol. 61, no. 12, pp. 54–60, May 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.