Inverting the Bellman Equation: From Q-Values to World Models
Pith reviewed 2026-06-26 14:31 UTC · model grok-4.3
The pith
Value-based agents trained on a rich set of rewards implicitly encode an accurate world model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Value-based agents trained on a sufficiently rich set of reward functions implicitly encode a unique and accurate world model. To extract this model in practice, P-learning samples from an agent's Q-values, policies and rewards to decode its internal model of the environment. Sufficient conditions are given on the type and number of goals for which agents encode the true transition kernel P, covering stochastic and deterministic MDPs over finite or continuous state spaces. Even when assumptions are violated, agents trained on a handful of reward functions encode accurate dynamics, and policies trained on the implicit model perform well on out-of-distribution goals.
What carries the argument
P-learning, the inverse analogue to Q-learning that decodes the transition kernel from sampled Q-values, policies and rewards.
If this is right
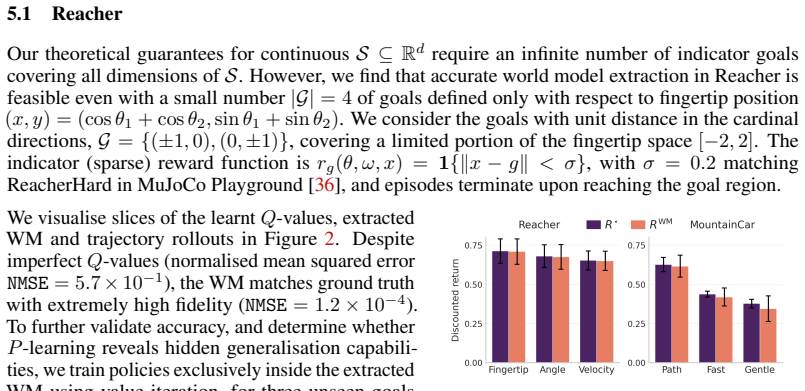
- The extracted model from a position-only trained Reacher agent supports quasi-optimal policies on velocity-based out-of-distribution goals.
- Agents encode accurate dynamics in Reacher, MountainCar and stochastic FourRooms even when the formal sufficient conditions are not fully met.
- Policies trained exclusively on the agent's implicit world model match performance on tasks outside the original training distribution.
- Model-free value functions contain usable transition knowledge that connects them to model-based planning.
Where Pith is reading between the lines
- If the encoding holds across algorithms, training on diverse goals could serve as a practical route to reliable internal simulators without explicit dynamics data.
- The result offers one explanation for why goal-conditioned agents often generalize better than single-reward training.
- Checking whether P-learning recovers consistent models from different value-based methods would test how general the implicit encoding is.
Load-bearing premise
The reward functions or goals used during training must be rich enough in type and number to uniquely determine the true transition kernel.
What would settle it
Apply P-learning to extract a transition kernel from an agent's Q-values and compare it directly to the true environment dynamics on a held-out set of states and actions; mismatch would show the encoding claim does not hold.
Figures



read the original abstract
Model-based and model-free reinforcement learning are traditionally viewed as separate paradigms: instead of learning a model of the transition kernel $P$, model-free agents typically estimate value functions tied to a specific policy and reward. In this paper, we challenge this dichotomy by proving that value-based agents trained on a sufficiently rich set of reward functions, e.g. using goal-conditioned RL, implicitly encode a unique and accurate world model. To extract this model in practice, we introduce \textit{$P$-learning}, an inverse analogue to $Q$-learning that samples from an agent's $Q$-values, policies and rewards to decode its internal model of the environment. We then provide sufficient conditions on the type and number of goals for which agents encode the true kernel $P$, covering both stochastic and deterministic MDPs over finite or continuous state spaces. Even when our assumptions are violated, we empirically demonstrate that agents trained on a handful of reward functions encode accurate dynamics in $\texttt{Reacher}$, $\texttt{MountainCar}$ and stochastic variants of $\texttt{FourRooms}$. Surprisingly, we find that policies trained exclusively on a \texttt{Reacher} agent's implicit world model are quasi-optimal on out-of-distribution, velocity-based goals despite position-only training -- suggesting that agents contain hidden generalisation capabilities and providing a new lens into the connection between model-based, model-free, and goal-conditioned RL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proves that value-based agents trained on a sufficiently rich set of reward functions (e.g. via goal-conditioned RL) implicitly encode a unique and accurate world model of the transition kernel P. It introduces P-learning, an inverse procedure to Q-learning that extracts the model by sampling from the agent's Q-values, policies and rewards. Sufficient conditions on the type and cardinality of goals are stated to guarantee recovery of the true P for both stochastic and deterministic MDPs over finite or continuous state spaces. Empirical results in Reacher, MountainCar and stochastic FourRooms show that agents encode accurate dynamics even when assumptions are mildly violated, and that policies trained exclusively on the implicit model achieve quasi-optimal performance on out-of-distribution velocity-based goals.
Significance. If the central claim and proof hold, the work supplies a concrete mathematical bridge between model-free value-based RL and model-based methods by showing that sufficiently diverse reward training causes agents to contain hidden, extractable world models. The explicit uniqueness proof, the P-learning algorithm, the parameter-free character of the inversion under the stated conditions, and the generalization experiments are all strengths that would be credited in a review. The result offers a new lens on goal-conditioned RL and could motivate new algorithms for model extraction and improved OOD performance.
major comments (2)
- [theoretical results / sufficient conditions] The uniqueness theorem (main theoretical section) asserts that Q-values over a rich reward set determine P uniquely; however, the proof sketch in the abstract and the empirical section do not clarify whether the stated cardinality conditions remain sufficient when the reward functions are linearly dependent or when the policy class is restricted, which is load-bearing for the claim that any goal-conditioned agent encodes the true kernel.
- [P-learning procedure] § on P-learning: the inversion procedure is presented as sampling from Q, π and r to recover P, but the manuscript does not report the sample complexity or the numerical stability of the inversion step when Q-values are estimated from finite data; this directly affects whether the extracted model is accurate enough to support the reported quasi-optimal OOD policies.
minor comments (2)
- [continuous state spaces] Notation for the continuous-state case should explicitly distinguish the measure-theoretic version of the Bellman equation from the finite case to avoid ambiguity in the uniqueness argument.
- [empirical evaluation] The Reacher and MountainCar experiments would benefit from an ablation that varies the number of training goals while holding total samples fixed, to quantify how quickly the implicit model accuracy saturates.
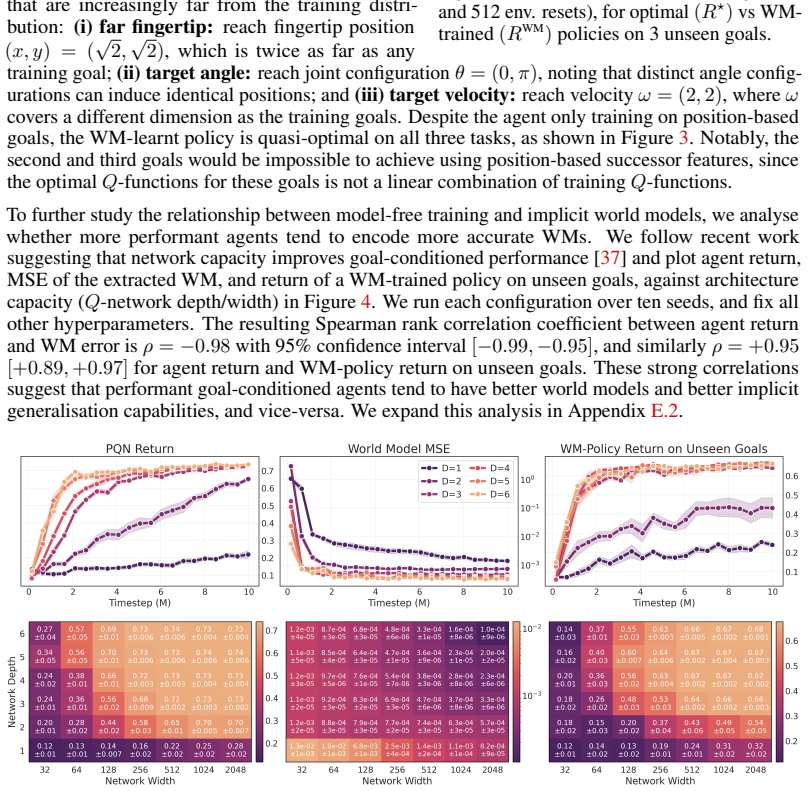
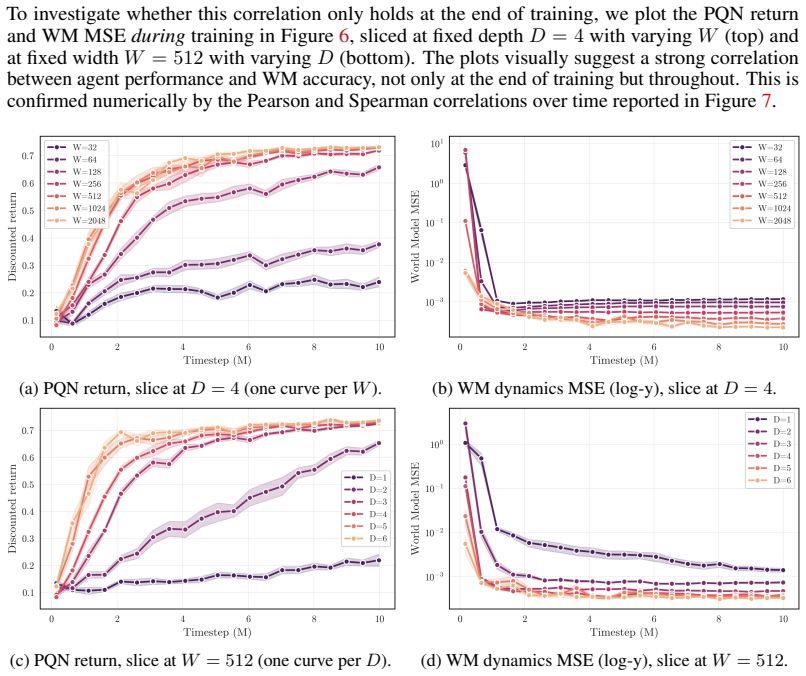
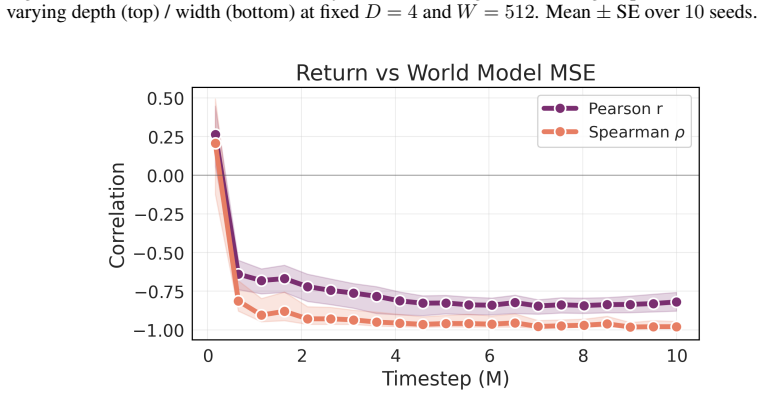
Simulated Author's Rebuttal
We thank the referee for their positive assessment and recommendation of minor revision. The comments highlight important points for clarification, which we address below.
read point-by-point responses
-
Referee: [theoretical results / sufficient conditions] The uniqueness theorem (main theoretical section) asserts that Q-values over a rich reward set determine P uniquely; however, the proof sketch in the abstract and the empirical section do not clarify whether the stated cardinality conditions remain sufficient when the reward functions are linearly dependent or when the policy class is restricted, which is load-bearing for the claim that any goal-conditioned agent encodes the true kernel.
Authors: The uniqueness theorem provides sufficient conditions on the cardinality and type of goals that ensure the reward set allows unique determination of P. These conditions are intended to guarantee that the rewards provide independent information sufficient for inversion; linear dependence among rewards would reduce the effective cardinality below the threshold, thus not satisfying the stated conditions. We will add an explicit remark in the theorem statement and surrounding discussion to clarify this aspect. The theorem applies under the policy class used by the agent for the given rewards, as detailed in the assumptions; no restriction beyond that is claimed. This clarification will be incorporated in the revision. revision: partial
-
Referee: [P-learning procedure] § on P-learning: the inversion procedure is presented as sampling from Q, π and r to recover P, but the manuscript does not report the sample complexity or the numerical stability of the inversion step when Q-values are estimated from finite data; this directly affects whether the extracted model is accurate enough to support the reported quasi-optimal OOD policies.
Authors: The manuscript indeed does not provide theoretical sample complexity analysis for the P-learning inversion or a dedicated study of numerical stability with finite-sample Q-value estimates. The empirical results across the environments demonstrate that the procedure yields models accurate enough for the reported OOD performance. In the revised manuscript, we will include additional discussion on the numerical stability observed in the experiments and note the lack of theoretical sample complexity bounds as a direction for future work. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper presents an explicit mathematical proof that Q-values over a sufficiently rich set of reward functions uniquely determine the transition kernel P (covering finite/continuous and deterministic/stochastic MDPs), grounded in the Bellman equation and stated conditions on reward type and cardinality. The derivation of the inversion procedure (P-learning) follows directly from this uniqueness result rather than from any fitted parameter or self-referential definition. No load-bearing step reduces by construction to the paper's own inputs, and the central claim does not rely on self-citations for its uniqueness theorem or ansatz. The result is therefore self-contained against external mathematical benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math The Bellman optimality equation holds for the learned Q-values
- domain assumption The environment is an MDP (finite or continuous state space, stochastic or deterministic)
invented entities (1)
-
P-learning procedure
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A Bradford Book, 2018
Richard Sutton and Andrew Barto.Reinforcement learning: An introduction. A Bradford Book, 2018
2018
-
[2]
Playing atari with deep reinforcement learning, 2013
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning, 2013
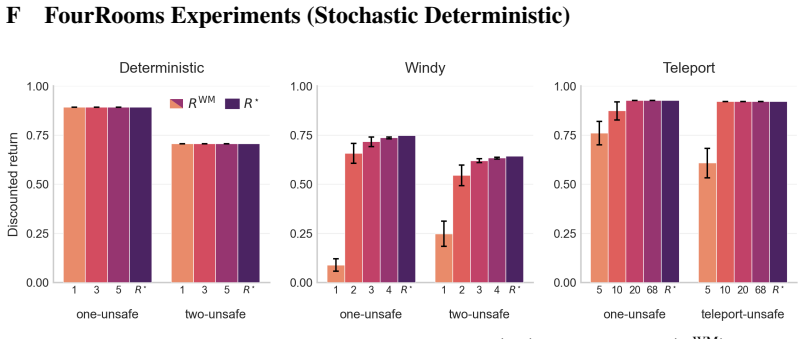
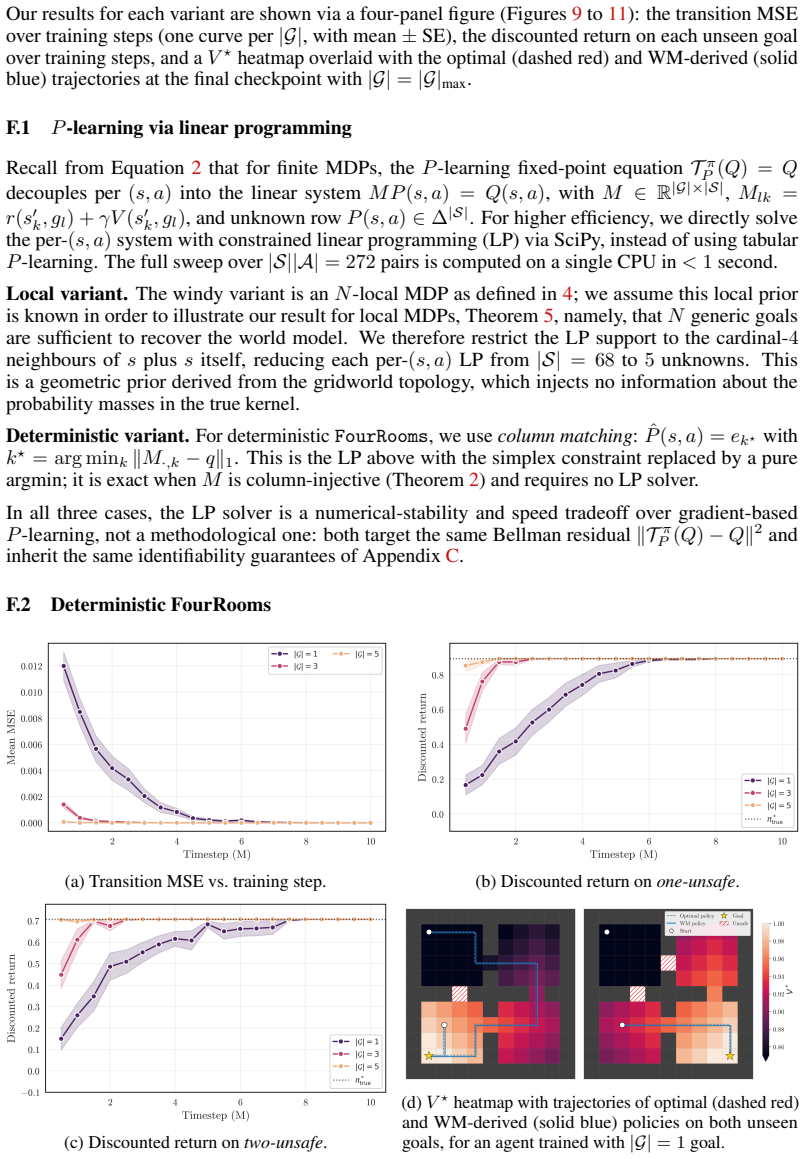
2013
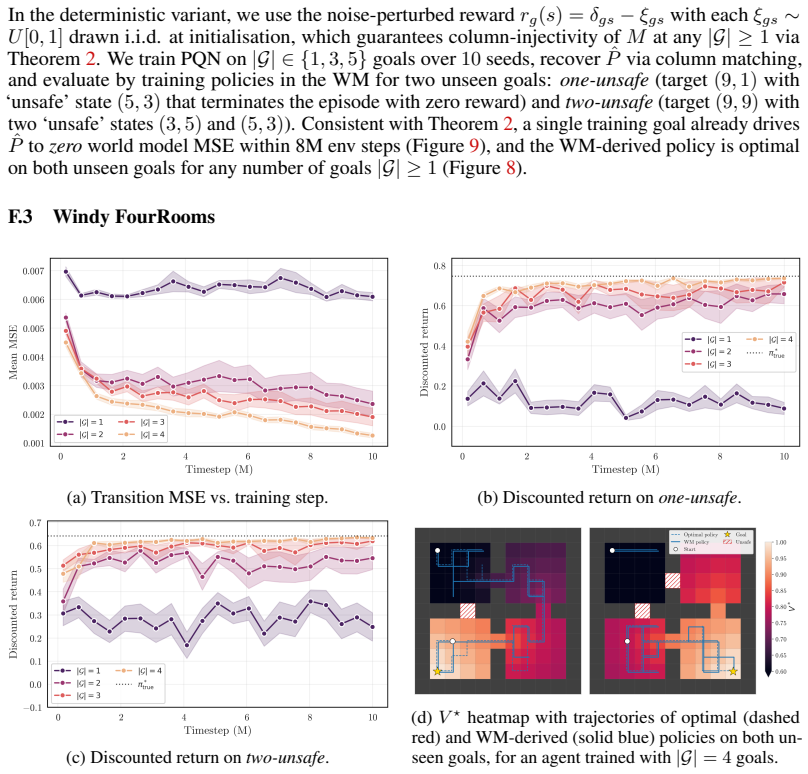
-
[3]
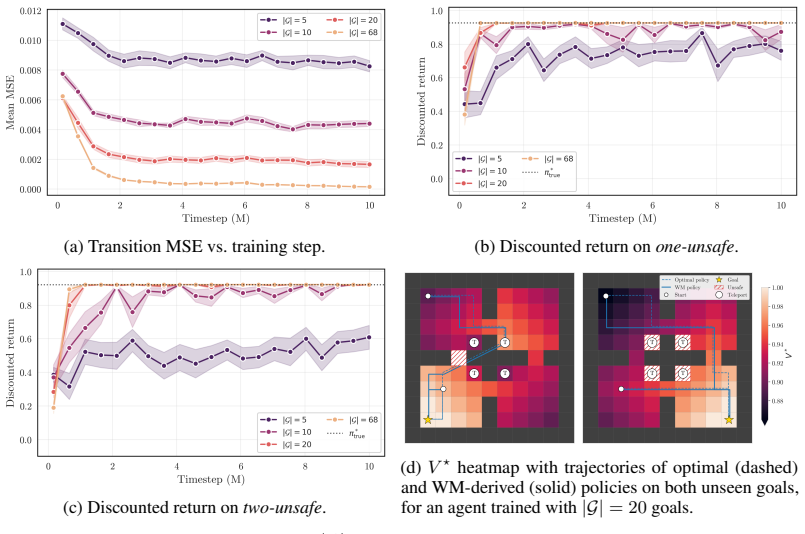
Proximal Policy Optimization Algorithms, August 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal Policy Optimization Algorithms, August 2017
2017
-
[4]
Objective mismatch in model-based reinforcement learning
Nathan Lambert, Brandon Amos, Omry Yadan, and Roberto Calandra. Objective mismatch in model-based reinforcement learning. InProceedings of the 2nd Conference on Learning for Dynamics and Control, Proceedings of Machine Learning Research. PMLR, 2020
2020
-
[5]
Moerland, Joost Broekens, Aske Plaat, and Catholijn M
Thomas M. Moerland, Joost Broekens, Aske Plaat, and Catholijn M. Jonker. Model-based reinforcement learning: A survey.Foundations and Trends in Machine Learning, 2023
2023
-
[6]
The value equivalence principle for model-based reinforcement learning
Christopher Grimm, André Barreto, Satinder Singh, and David Silver. The value equivalence principle for model-based reinforcement learning. InAdvances in Neural Information Processing Systems, 2020
2020
-
[7]
Proper value equivalence
Christopher Grimm, André Barreto, Gregory Farquhar, David Silver, and Satinder Singh. Proper value equivalence. InAdvances in Neural Information Processing Systems, 2021
2021
-
[8]
Hunt, Tom Schaul, Hado van Hasselt, and David Silver
André Barreto, Will Dabney, Rémi Munos, Jonathan J. Hunt, Tom Schaul, Hado van Hasselt, and David Silver. Successor features for transfer in reinforcement learning. InAdvances in Neural Information Processing Systems, 2017
2017
-
[9]
Universal Successor Features Approximators, 2018
Diana Borsa, André Barreto, John Quan, Daniel Mankowitz, Rémi Munos, Hado van Hasselt, David Silver, and Tom Schaul. Universal Successor Features Approximators, 2018
2018
-
[10]
Learning one representation to optimize all rewards
Ahmed Touati and Yann Ollivier. Learning one representation to optimize all rewards. InProceedings of the 35th International Conference on Neural Information Processing Systems, 2021
2021
-
[11]
Universal Value Function Approximators
Tom Schaul, Daniel Horgan, Karol Gregor, and David Silver. Universal Value Function Approximators. In Proceedings of the 32nd International Conference on Machine Learning. PMLR, 2015
2015
-
[12]
Contrastive learning as goal-conditioned reinforcement learning
Benjamin Eysenbach, Tianjun Zhang, Sergey Levine, and Ruslan Salakhutdinov. Contrastive learning as goal-conditioned reinforcement learning. InAdvances in Neural Information Processing Systems, 2022
2022
-
[13]
OGBench: Benchmarking Offline Goal-Conditioned RL
Seohong Park, Kevin Frans, Benjamin Eysenbach, and Sergey Levine. OGBench: Benchmarking Offline Goal-Conditioned RL. InThe Thirteenth International Conference on Learning Representations, 2024
2024
-
[14]
Unifying task specification in reinforcement learning
Martha White. Unifying task specification in reinforcement learning. InProceedings of the 34th Interna- tional Conference on Machine Learning - Volume 70, ICML’17, 2017
2017
-
[15]
Neural fitted q iteration – first experiences with a data efficient neural reinforcement learning method
Martin Riedmiller. Neural fitted q iteration – first experiences with a data efficient neural reinforcement learning method. InMachine Learning: ECML 2005, 2005
2005
-
[16]
Learning to predict by the method of temporal differences.Machine Learning, 08 1988
Richard Sutton. Learning to predict by the method of temporal differences.Machine Learning, 08 1988
1988
-
[17]
PhD thesis, King’s College, University of Cambridge, Cambridge, UK, May 1989
Christopher John Cornish Hellaby Watkins.Learning from Delayed Rewards. PhD thesis, King’s College, University of Cambridge, Cambridge, UK, May 1989
1989
-
[18]
Christopher J. C. H. Watkins and Peter Dayan. Q-learning.Machine learning, 1992
1992
-
[19]
Rusu, Joel Veness, Marc G
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level control through deep reinforcement ...
2015
-
[20]
Simplifying deep temporal difference learning.The International Conference on Learning Representations, 2025
Matteo Gallici, Mattie Fellows, Benjamin Ellis, Bartomeu Pou, Ivan Masmitja, Jakob Nicolaus Foerster, and Mario Martin. Simplifying deep temporal difference learning.The International Conference on Learning Representations, 2025
2025
-
[21]
Kingma and Max Welling
Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. InInternational Conference on Learning Representations, 2014
2014
-
[22]
Stochastic backpropagation and ap- proximate inference in deep generative models
Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra. Stochastic backpropagation and ap- proximate inference in deep generative models. InProceedings of the 31st International Conference on International Conference on Machine Learning - Volume 32, 2014. 11
2014
-
[23]
Leemon C. Baird. Residual algorithms: reinforcement learning with function approximation. InProceed- ings of the International Conference on Machine Learning, 1995
1995
-
[24]
A Stochastic Approximation Method.The Annals of Mathematical Statistics, 1951
Herbert Robbins and Sutton Monro. A Stochastic Approximation Method.The Annals of Mathematical Statistics, 1951
1951
-
[25]
Rechenberg
I. Rechenberg. Evolutionsstrategien. InSimulationsmethoden in der Medizin und Biologie. Springer Berlin Heidelberg, 1978
1978
-
[26]
Evolution strategies at the hyperscale, 2026
Bidipta Sarkar, Mattie Fellows, Juan Agustin Duque, Alistair Letcher, Antonio León Villares, Anya Sims, Clarisse Wibault, Dmitry Samsonov, Dylan Cope, Jarek Liesen, Kang Li, Lukas Seier, Theo Wolf, Uljad Berdica, Valentin Mohl, Alexander David Goldie, Aaron Courville, Karin Sevegnani, Shimon Whiteson, and Jakob Nicolaus Foerster. Evolution strategies at t...
2026
-
[27]
Accelerating Goal-Conditioned RL Algorithms and Research
Michał Bortkiewicz, Władek Pałucki, Vivek Myers, Tadeusz Dziarmaga, Tomasz Arczewski, Łukasz Kuci´nski, and Benjamin Eysenbach. Accelerating Goal-Conditioned RL Algorithms and Research. In International Conference on Learning Representations, 2025
2025
-
[28]
A single goal is all you need: Skills and exploration emerge from contrastive RL without rewards, demonstrations, or subgoals
Grace Liu, Michael Tang, and Benjamin Eysenbach. A single goal is all you need: Skills and exploration emerge from contrastive RL without rewards, demonstrations, or subgoals. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[29]
Learning Successor States and Goal-Dependent Values: A Mathematical Viewpoint, 2021
Léonard Blier, Corentin Tallec, and Yann Ollivier. Learning Successor States and Goal-Dependent Values: A Mathematical Viewpoint, 2021
2021
-
[30]
Bellemare, and Hugo Larochelle
William Fedus, Carles Gelada, Yoshua Bengio, Marc G. Bellemare, and Hugo Larochelle. Hyperbolic discounting and learning over multiple horizons, 2019
2019
-
[31]
Sutton, Joseph Modayil, Michael Delp, Thomas Degris, Patrick M
Richard S. Sutton, Joseph Modayil, Michael Delp, Thomas Degris, Patrick M. Pilarski, Adam White, and Doina Precup. Horde: a scalable real-time architecture for learning knowledge from unsupervised sensorimotor interaction. InThe 10th International Conference on Autonomous Agents and Multiagent Systems, 2011
2011
-
[32]
Gymnasium: A standard interface for reinforcement learning environments.https://gymnasium.farama.org/, 2023
Mark Towers, Ariel Kwiatkowski, and Jordan Terry. Gymnasium: A standard interface for reinforcement learning environments.https://gymnasium.farama.org/, 2023. Farama Foundation
2023
-
[33]
Mujoco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2012
2012
-
[34]
Sutton, Doina Precup, and Satinder Singh
Richard S. Sutton, Doina Precup, and Satinder Singh. Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning.Artificial Intelligence, 1999
1999
-
[35]
Hindsight experience replay
Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, Pieter Abbeel, and Wojciech Zaremba. Hindsight experience replay. InAdvances in Neural Information Processing Systems, 2017
2017
-
[36]
Kahrs, Carlo Sferrazza, Yuval Tassa, and Pieter Abbeel
Kevin Zakka, Baruch Tabanpour, Qiayuan Liao, Mustafa Haiderbhai, Samuel Holt, Jing Yuan Luo, Arthur Allshire, Erik Frey, Koushil Sreenath, Lueder A. Kahrs, Carlo Sferrazza, Yuval Tassa, and Pieter Abbeel. Mujoco playground: An open-source framework for gpu-accelerated robot learning and sim-to-real transfer.,
-
[37]
URLhttps://github.com/google-deepmind/mujoco_playground
-
[38]
1000 layer networks for self-supervised RL: Scaling depth can enable new goal-reaching capabilities
Kevin Wang, Ishaan Javali, Michał Bortkiewicz, Tomasz Trzcinski, and Benjamin Eysenbach. 1000 layer networks for self-supervised RL: Scaling depth can enable new goal-reaching capabilities. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[39]
Mastering Atari, Go, chess and shogi by planning with a learned model.Nature, 2020
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy Lillicrap, and David Silver. Mastering Atari, Go, chess and shogi by planning with a learned model.Nature, 2020
2020
-
[40]
Iterative value-aware model learning
Amir-massoud Farahmand. Iterative value-aware model learning. InAdvances in Neural Information Processing Systems, 2018
2018
-
[41]
Unifying model-based and model-free reinforcement learning with equivalent policy sets
Benjamin Freed, Thomas Wei, Roberto Calandra, Jeff Schneider, and Howie Choset. Unifying model-based and model-free reinforcement learning with equivalent policy sets. InReinforcement Learning Conference, 2024
2024
-
[42]
Bayesian exploration networks
Mattie Fellows, Brandon Gary Kaplowitz, Christian Schroeder De Witt, and Shimon Whiteson. Bayesian exploration networks. InProceedings of the 41st International Conference on Machine Learning, Proceed- ings of Machine Learning Research, 2024. 12
2024
-
[43]
Strehl, Lihong Li, Eric Wiewiora, John Langford, and Michael L
Alexander L. Strehl, Lihong Li, Eric Wiewiora, John Langford, and Michael L. Littman. Pac model-free reinforcement learning. InProceedings of the 23rd International Conference on Machine Learning, 2006
2006
-
[44]
On representation complexity of model-based and model-free reinforcement learning
Hanlin Zhu, Baihe Huang, and Stuart Russell. On representation complexity of model-based and model-free reinforcement learning. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[45]
Learning to achieve goals
Leslie Pack Kaelbling. Learning to achieve goals. InInternational Joint Conference on Artificial Intelligence, 1993
1993
-
[46]
On the Role of Iterative Computation in Reinforcement Learning, February 2026
Raj Ghugare, Michał Bortkiewicz, Alicja Ziarko, and Benjamin Eysenbach. On the Role of Iterative Computation in Reinforcement Learning, February 2026. arXiv:2602.05999 [cs]
arXiv 2026
-
[47]
Goal-conditioned agents that learn everything all at once, 2026
Michael Matthews, Matthew Jackson, Michael Beukman, Thomas Foster, Alistair Letcher, Scott Fujimoto, Cédric Colas, and Jakob Foerster. Goal-conditioned agents that learn everything all at once, 2026
2026
-
[48]
General agents need world models
Jonathan Richens, Tom Everitt, and David Abel. General agents need world models. InForty-Second International Conference on Machine Learning, 2025
2025
-
[49]
Inferring transition dynamics from value functions
Jacob Adamczyk. Inferring transition dynamics from value functions. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[50]
On avoiding power-seeking by artificial intelligence, 2022
Alexander Matt Turner. On avoiding power-seeking by artificial intelligence, 2022
2022
-
[51]
Interpreting emergent planning in model-free reinforcement learning
Thomas Bush, Stephen Chung, Usman Anwar, Adrià Garriga-Alonso, and David Krueger. Interpreting emergent planning in model-free reinforcement learning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[52]
Improving generalization for temporal difference learning: The successor representation
Peter Dayan. Improving generalization for temporal difference learning: The successor representation. Neural Computation, 1993
1993
-
[53]
Lucas Lehnert and Michael L. Littman. Successor features combine elements of model-free and model- based reinforcement learning.Journal of Machine Learning Research, 2020
2020
-
[54]
Reward-free exploration for reinforcement learning
Chi Jin, Akshay Krishnamurthy, Max Simchowitz, and Tiancheng Yu. Reward-free exploration for reinforcement learning. InProceedings of the 37th International Conference on Machine Learning, Proceedings of Machine Learning Research, 2020
2020
-
[55]
Haoyang Cao and Samuel N. Cohen. Identifiability in inverse reinforcement learning. InAdvances in Neural Information Processing Systems, 2021
2021
-
[56]
Oliver E Richardson, Mandana Samiei, Mehran Shakerinava, Joseph D Viviano, Abdessamad El Kabid, Ali Parviz, and Yoshua Bengio. Local inconsistency resolution: The interplay between attention and control in probabilistic models.Proceedings of the 29th International Conference on Artificial Intelligence and Statistics, 2026
2026
-
[57]
Monte carlo gradient estimation in machine learning.J
Shakir Mohamed, Mihaela Rosca, Michael Figurnov, and Andriy Mnih. Monte carlo gradient estimation in machine learning.J. Mach. Learn. Res., 2020
2020
-
[58]
A. J. Wilkie. Model completeness results for expansions of the ordered field of real numbers by restricted pfaffian functions and the exponential function.Journal of the American Mathematical Society, 1996
1996
-
[59]
Krantz and Harold R
Steven G. Krantz and Harold R. Parks.A Primer of Real Analytic Functions. Birkhäuser Boston, 2nd edition, 2002
2002
-
[60]
Folland.Real Analysis: Modern Techniques and Their Applications
Gerald B. Folland.Real Analysis: Modern Techniques and Their Applications. Pure and Applied Mathematics: A Wiley-Interscience Series of Texts, Monographs and Tracts. John Wiley & Sons, 1999
1999
-
[61]
Lee.Introduction to Smooth Manifolds
John M. Lee.Introduction to Smooth Manifolds. Springer, 2nd edition, 2013
2013
-
[62]
University of California Press, 1955
Salomon Bochner.Harmonic Analysis and the Theory of Probability. University of California Press, 1955
1955
-
[63]
Stein and Guido Weiss.Introduction to Fourier Analysis on Euclidean Spaces
Elias M. Stein and Guido Weiss.Introduction to Fourier Analysis on Euclidean Spaces. Princeton Mathematical Series. Princeton University Press, 1971
1971
-
[64]
gymnax: A JAX-based reinforcement learning environment library, 2022
Robert Tjarko Lange. gymnax: A JAX-based reinforcement learning environment library, 2022. URL http://github.com/RobertTLange/gymnax
2022
-
[65]
JAX: compos- able transformations of Python+NumPy programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: compos- able transformations of Python+NumPy programs, 2018. URLhttp://github.com/jax-ml/jax. 13 A Proofs forP-Learning A.1 Derivation ofP-Learning We provide pseudocode f...
2018
-
[66]
test functions
to form an unbiased estimate ˆδ1 of the outer factor δφ, and an independent(s ′ 2, a′ 2)to estimate the inner expectation. Independence ensures unbiased estimation: ∇φL(φ) =E (g,s,a)∼d δφ(s, a, g)E s′∼Pφ(s,a),a′∼π(s′,g) [ˆδφ∇φ logP φ(s′ |s, a)] =E (g,s,a)∼d,s1,2∼Pφ(s,a),a1,2∼π(s1,2,g) h ˆδ1ˆδ2∇φ logP φ(s2 |s, a) i . This derivation leads to the pseudocode...
-
[67]
exceptionally rare
= 0 and thus det(M π) = 0. However, note that the matrix is full-rank for all γ̸= 1/ √ 2, and for any perturbation of the policies, making singularities “exceptionally rare” as guaranteed by Theorem 3. C.6 ArbitraryQ-Values Theorems 2 and 3 give conditions under which the true kernel P is identified uniquely by exact Q-values, or approximately by ϵ-approx...
2048
-
[68]
Deterministic(Figures 8 and 9). Each action moves the agent one cell in the chosen cardinal direction; walls keep the agent in place.A single training goal( |G|= 1 ) already drives ˆP to zero world-model MSE within 8M env steps and the WM-derived policy is exactly optimal on both unseen goals, in line with Theorem 2
-
[69]
The chosen action is realised w.p
Windy(Figures 8 and 10). The chosen action is realised w.p. 1 2, perturbed 90◦ counter- clockwise or clockwise each w.p. 1
-
[70]
Here, |G|= 4 training goals already drive the WM- derived policy to within∼1%of optimal return on both unseen goals
-
[71]
Four cells (4,4),(4,6),(6,4),(6,6) teleport the agent uniformlyinto the 16 cells of the diagonally opposite 4×4 room
Teleporting(Figures 8 and 11). Four cells (4,4),(4,6),(6,4),(6,6) teleport the agent uniformlyinto the 16 cells of the diagonally opposite 4×4 room. Here, |G|= 20 training goals – well short of the |G|=|S|= 68 worst case of Theorem 3 – already drive the WM-derived policy to within∼0.1%of optimal return on both unseen goals. For each variant, the training ...
-
[72]
We train PQN on |G| ∈ {1,2,3,4} training goals over 10 seeds, recover ˆP via the local LP, and evaluate on the same two unseen goals as the deterministic variant
This places the variant in the local-stochastic regime of Theorem 5. We train PQN on |G| ∈ {1,2,3,4} training goals over 10 seeds, recover ˆP via the local LP, and evaluate on the same two unseen goals as the deterministic variant. As expected for stochastic dynamics, the single-goal regime is under-determined, but |G| ≥3 already drives the WM-derived pol...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.