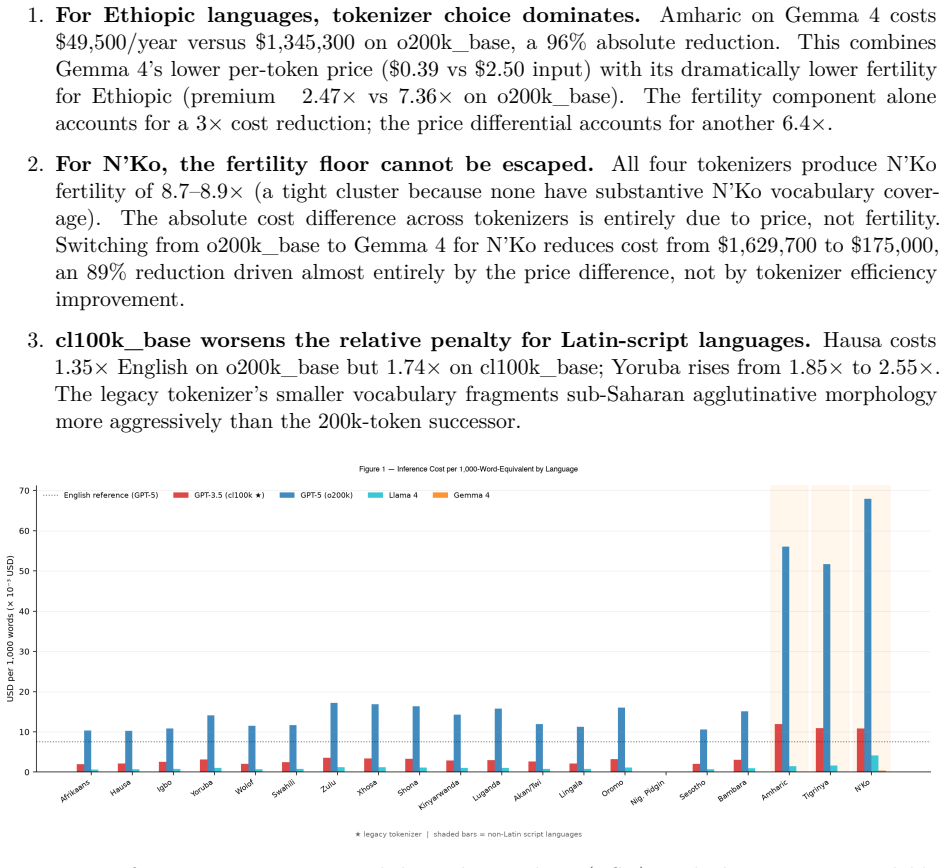
The African Language Tax: Quantifying the Cost, Latency, and Context Penalty of Tokenizing African Languages in Frontier LLMs
Pith reviewed 2026-06-26 00:18 UTC · model grok-4.3
The pith
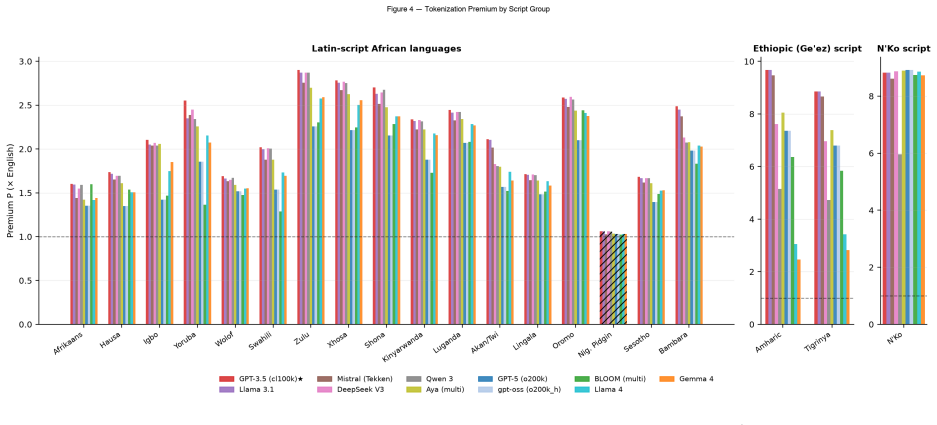
Every African language requires more tokens than English in frontier LLMs, with premiums up to 8.92 times for N'Ko.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
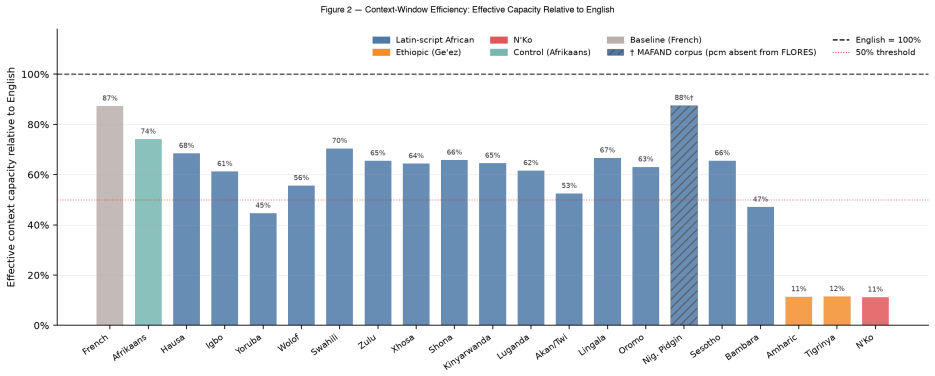
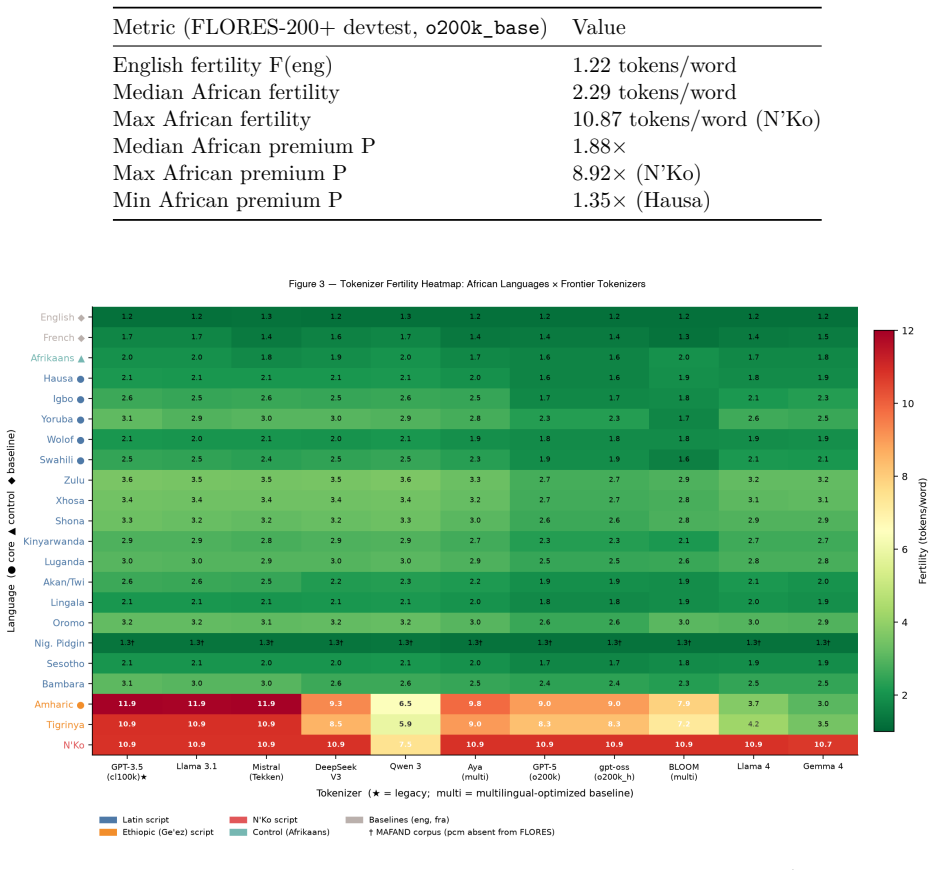
Across 20 African languages spanning five families and three scripts, and across 11 frontier and open tokenizers, every language shows a tokenization premium above English. The median premium is 1.88 times on GPT-5/o200k_base, reaching 8.92 times for N'Ko and 7.4 times for Amharic. The ratios remain nearly identical across different parallel corpora and translate directly into up to 8.9 times higher inference cost, matching latency multipliers, and effective context windows as small as 11 percent of English capacity. No current tokenizer removes the penalty, though Gemma 4 reduces the mean from 3.31 times to 2.38 times.
What carries the argument
The tokenization premium, the ratio of tokens required to encode a sentence in a given language versus the same sentence in English on parallel text.
If this is right
- Inference costs for N'Ko reach up to 8.9 times those for English on the same content.
- Generation latency scales directly with the token premium.
- Effective context capacity drops to as little as 11 percent of the English window for the worst-affected languages.
- The best available tokenizer reduces but does not eliminate the average premium.
Where Pith is reading between the lines
- Application builders targeting these languages must either accept higher API spend or invest in custom tokenizers.
- The token penalty may interact with other multilingual performance gaps to widen effective access differences.
- Public release of the measurement tool allows repeated checks as tokenizers improve.
Load-bearing premise
Parallel corpora such as FLORES-200+ isolate language-specific tokenization effects from any content or translation differences.
What would settle it
Re-tokenizing the same English sentences after fresh translations by multiple independent native speakers and checking whether the resulting token ratios match those from the standard parallel corpus.
Figures
read the original abstract
Commercial large language models bill, scale latency, and budget context per token. Yet tokenizers assign more subword tokens to the same meaning in some languages than in others, so speakers of languages with high token-fertility pay a structural penalty before a model is ever invoked. This penalty is documented for multilingual settings in general, but it has not been measured systematically for African languages at the level of enterprise deployment economics and cognitive context capacity. We measure it across 20 African languages spanning five language families and three scripts (Latin, Ge'ez/Ethiopic, N'Ko; 19 appear in the primary FLORES-200+ corpus, with Nigerian Pidgin measured via MAFAND-MT only), using parallel corpora so that the language effect is isolated from content. Across 11 frontier and open tokenizers on FLORES-200+, every African language carries a tokenization premium above English (median 1.88x on GPT-5 / o200k_base, up to 8.92x for N'Ko); the penalty is largest for Ethiopic and N'Ko scripts (reaching 7-9x) and is near-invariant across corpora (FLORES vs SIB-200 Pearson r = 0.9998). Translated into deployment terms, this results in up to 8.9x inference cost and an equivalent generation-latency multiplier (N'Ko vs English on GPT-5; 7.4x for Amharic), and as little as 11% of English's effective context window. The best currently available tokenizer for African languages, Gemma 4, reduces the mean premium from 3.31x (cl100k_base) to 2.38x, but no tokenizer eliminates the penalty. We release an open measurement tool (afri-fertility), a public leaderboard, a results dataset, and mitigation guidance for African builders. The penalty falls hardest on the languages whose speakers can least afford it, a digital divide encoded directly into the subword vocabulary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that 20 African languages incur consistent tokenization premiums (median 1.88×, up to 8.92× for N'Ko) relative to English across 11 frontier/open tokenizers on the parallel FLORES-200+ and SIB-200 corpora. These premiums translate directly into up to 8.9× higher inference cost, equivalent latency multipliers, and as little as 11% effective context window; the effect is largest for Ethiopic and N'Ko scripts, near-invariant across the two corpora (r=0.9998), and only partially mitigated by the best current tokenizer (Gemma 4). The authors release afri-fertility, a public leaderboard, results dataset, and mitigation guidance.
Significance. If the empirical counts hold, the work provides a concrete, deployment-relevant quantification of a structural penalty that falls hardest on the languages whose speakers can least afford it. Strengths include direct counts on parallel corpora (no fitted parameters), release of an open measurement tool and leaderboard that enable reproduction and extension, and the high cross-corpus correlation that supports robustness of the observed ordering.
major comments (2)
- [§3 Methods] §3 (Methods) and the abstract: the exact token-counting procedure, handling of script-specific edge cases (N'Ko, Ethiopic), and any statistical tests or error bars on the reported premiums are not described. Without these details the numerical ratios (1.88× median, 8.92× max) cannot be independently verified.
- [Introduction and §4 Results] Introduction and §4 (Results): the central attribution of all observed premiums to language–tokenizer interaction rests on the assumption that parallel translations fully isolate language effects from translation-induced differences in verbosity, compounding, or orthographic conventions. The reported r=0.9998 between FLORES-200+ and SIB-200 does not rule out a shared translation artifact; a direct comparison against non-translated African-language text would be required to confirm isolation.
minor comments (2)
- [Abstract] Abstract: clarify whether the Nigerian Pidgin results (measured on MAFAND-MT rather than FLORES-200+) are included in the overall median or only reported separately.
- [Tables and Figures] Table/figure captions: ensure every reported multiplier is explicitly tied to a specific tokenizer and corpus so readers can trace the 1.88× and 8.92× figures without cross-referencing the text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [§3 Methods] §3 (Methods) and the abstract: the exact token-counting procedure, handling of script-specific edge cases (N'Ko, Ethiopic), and any statistical tests or error bars on the reported premiums are not described. Without these details the numerical ratios (1.88× median, 8.92× max) cannot be independently verified.
Authors: We agree that additional detail is needed for reproducibility. In the revised manuscript we will expand §3 to describe the exact procedure (tokenization via the Hugging Face tokenizers library on the listed models, with sentence-level aggregation), specify handling for N'Ko (full Unicode normalization, no Latin fallback) and Ethiopic/Ge'ez (character inventory and subword segmentation patterns), and add bootstrap-derived 95% confidence intervals on all reported premiums. These changes will allow independent verification of the 1.88× median and 8.92× maximum figures. revision: yes
-
Referee: [Introduction and §4 Results] Introduction and §4 (Results): the central attribution of all observed premiums to language–tokenizer interaction rests on the assumption that parallel translations fully isolate language effects from translation-induced differences in verbosity, compounding, or orthographic conventions. The reported r=0.9998 between FLORES-200+ and SIB-200 does not rule out a shared translation artifact; a direct comparison against non-translated African-language text would be required to confirm isolation.
Authors: We acknowledge that parallel corpora cannot entirely exclude shared translation artifacts. However, the near-perfect correlation (r=0.9998) between two independently constructed parallel corpora provides strong evidence that the premiums are driven by language–tokenizer properties rather than translation conventions. The language ordering is also consistent with independent linguistic factors (script type and morphological structure). We will add an explicit limitations paragraph discussing this assumption and the value of future native-text comparisons, but we do not believe a new non-translated corpus is required to support the current claims. revision: partial
Circularity Check
No circularity: results are direct empirical token counts on parallel corpora
full rationale
The paper computes tokenization premiums as simple ratios of subword counts (e.g., median 1.88x, up to 8.92x) measured directly on FLORES-200+ and SIB-200 parallel sentences across 11 tokenizers. No equations, fitted parameters, predictions, or derivations are present that reduce these quantities to inputs by construction. The reported Pearson r=0.9998 is an observed correlation between two independent corpora, not a tautological outcome. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify the central claims; the work is self-contained empirical measurement.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Parallel corpora isolate language-specific tokenization effects from content differences.
Reference graph
Works this paper leans on
-
[1]
I roko B ench: A New Benchmark for A frican Languages in the Age of Large Language Models
Ahia, O., Kumar, S., Gonen, H., Kasai, J., Mortensen, D. R., Smith, N. A., & Tsvetkov, Y. (2023). Do All Languages Cost the Same? Tokenization in the Era of Commercial Language Models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (pp. 9904–9923). Association for Computational Linguistics. https://aclanthology.o...
-
[2]
(pp. 103–112). Association for Computational Linguistics. https://doi.org/10.18653/v1/2026.africanlp-main.10 (arXiv: https://arxiv.org/abs/2509.05486) Corpora and datasets Adelani, D. I., Alabi, J. O., Fan, A., Kreutzer, J., Shen, X., Reid, M., Ruiter, D., Klakow, D., Nabende, P., Chang, E., Gwadabe, T. G., Sackey, F., Dossou, B. F. P., Emezue, C. C., Leo...
-
[3]
(pp. 3053–3070). Association for Computational Linguistics. https://aclanthology.org/2022.naacl-main.223 Adelani, D. I., Liu, H., Shen, X., Vassilyev, N., Alabi, J. O., Mao, Y., Gao, H., & Lee, E.-S. A. (2024). SIB-200: A Simple, Inclusive, and Big Evaluation Dataset for Topic Classification in 200+ Languages and Dialects. In Proceedings of the 18th Confe...
arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.