Understanding Evaluation Illusion in Diffusion Large Language Models
Pith reviewed 2026-06-30 07:51 UTC · model grok-4.3
The pith
Parallel decoding methods for diffusion LLMs underperform single-token decoding once prompt templates vary.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
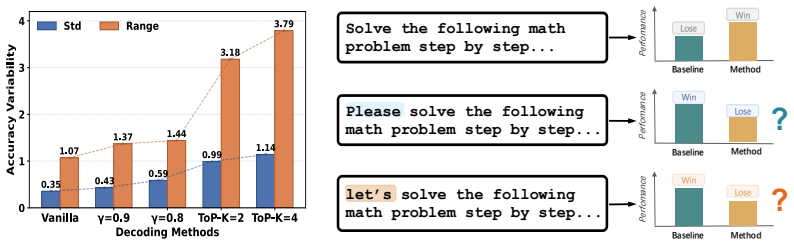
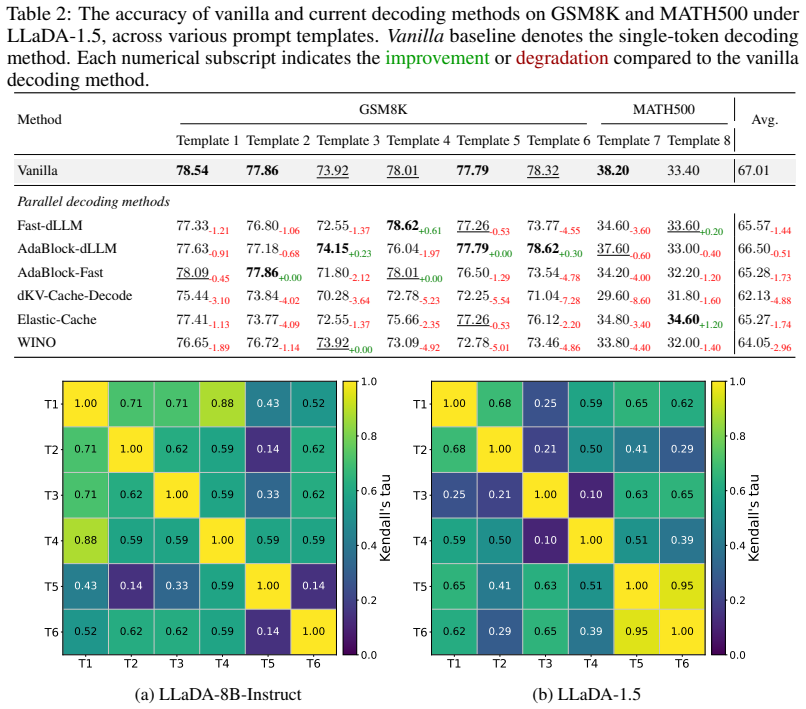
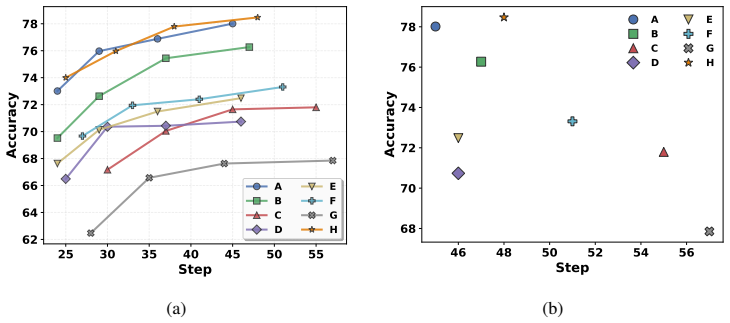
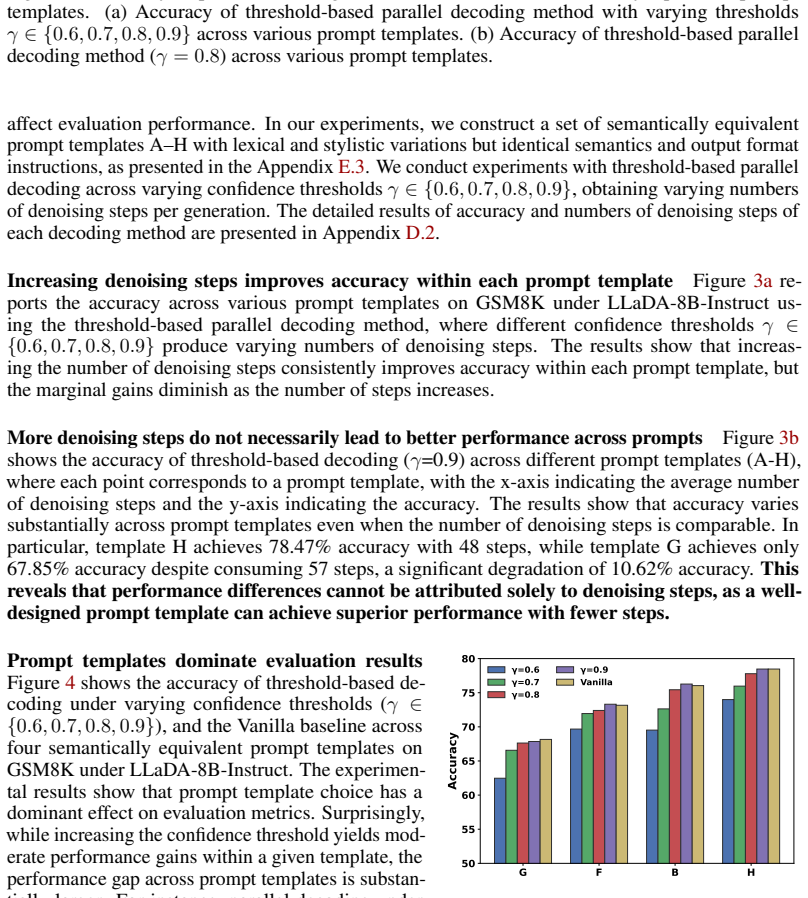
The ranking of decoding methods is highly sensitive to the choice of prompt templates. Single-template evaluation can lead to an illusion that decoding methods improve inference efficiency without performance degradation. Current parallel decoding methods consistently underperform the single-token decoding baseline, failing to overcome the speed-quality trade-off. This inconsistency stems from the high sensitivity of parallel decoding methods to minor variations in prompt templates. An effective prompt template can achieve strong results even with fewer denoising steps, outperforming the gain from adding more steps.
What carries the argument
Prompt template sensitivity in parallel decoding methods, which produces inconsistent performance rankings across evaluation settings.
If this is right
- Single-template tests can falsely indicate that a decoding method improves efficiency with no quality loss.
- Changing the prompt template can produce larger gains than increasing the number of denoising steps.
- Other overlooked evaluation settings also change how decoding methods are judged.
- Reliable assessment of dLLM decoding requires testing across multiple prompt templates and settings.
Where Pith is reading between the lines
- Future decoding research should measure robustness to prompt wording as a core requirement rather than an afterthought.
- The same sensitivity may appear in evaluations of other sampling-based generation techniques outside diffusion models.
- Standard practice could shift toward reporting results over a small set of fixed prompt templates to reduce hidden variance.
Load-bearing premise
The models, tasks, and prompt variations tested are representative enough to show that prompt sensitivity is a general property of parallel decoding rather than an artifact of particular choices.
What would settle it
A parallel decoding method that outperforms the single-token baseline on the same tasks when evaluated with at least three distinct prompt templates would falsify the central claim.
Figures
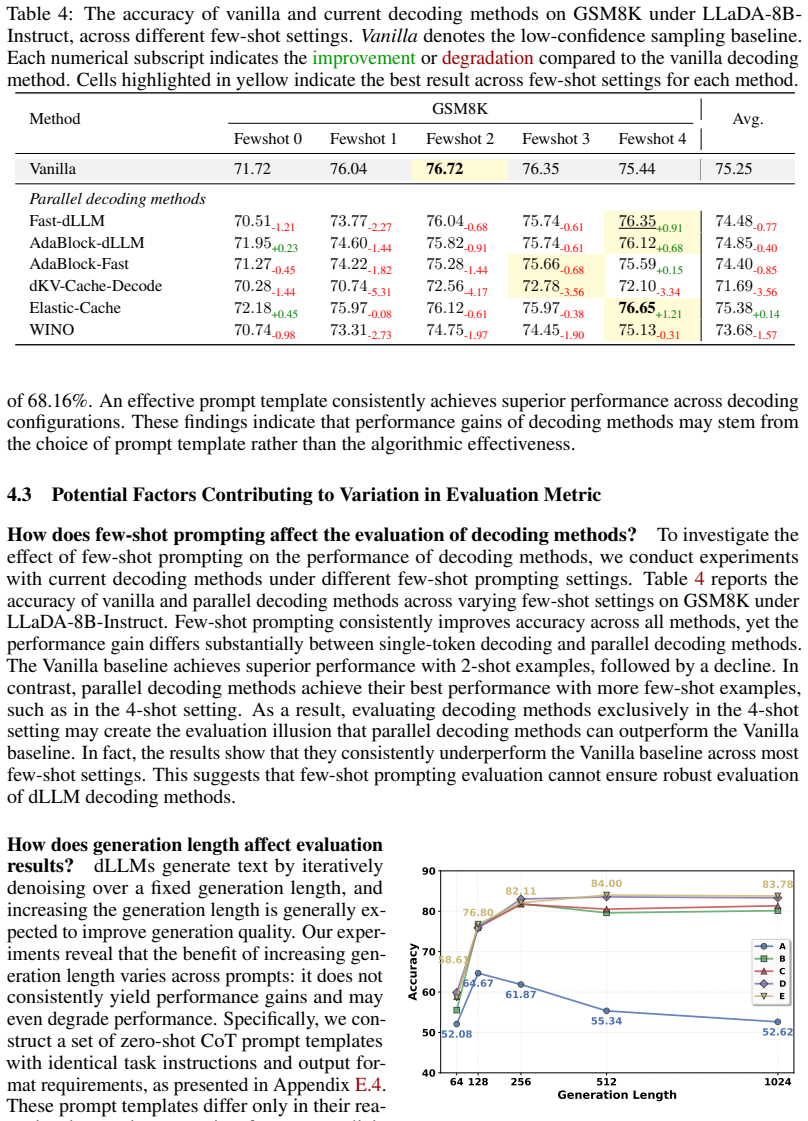
read the original abstract
Despite the capability of parallel decoding, diffusion large language models (dLLMs) require many denoising steps to maintain generation quality, motivating recent research on efficient decoding strategies. However, existing studies have reported inconsistent evaluation results even under seemingly identical evaluation settings, risking biased conclusions about dLLM decoding methods. To understand this evaluation concern, we conduct a rigorous evaluation of current decoding methods for dLLMs across diverse evaluation settings. Surprisingly, our analysis reveals that the ranking of decoding methods is highly sensitive to the choice of prompt templates. Single-template evaluation can lead to an illusion that decoding methods improve inference efficiency without performance degradation. Through comprehensive experiments, we find that current parallel decoding methods consistently underperform the single-token decoding baseline, failing to overcome the speed-quality trade-off. We further identify this evaluation inconsistency as the high sensitivity of parallel decoding methods to minor variations in prompt templates. Our experiments show that an effective prompt template can achieve strong evaluation results even with fewer denoising steps, markedly outperforming the marginal gain from increasing denoising steps. Beyond prompt templates, our experiments indicate that overlooked evaluation settings can also notably affect the assessment of decoding methods. Based on these findings, we propose practical guidelines for the reliable evaluation of decoding methods in dLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines inconsistencies in evaluating parallel decoding methods for diffusion large language models (dLLMs). It argues that method rankings are highly sensitive to prompt template choice, creating an 'evaluation illusion' where methods appear to improve speed without quality loss under single-template tests. Through experiments across diverse settings, it concludes that current parallel methods consistently underperform the single-token decoding baseline and fail to resolve the speed-quality trade-off; it attributes this to high prompt sensitivity and offers practical evaluation guidelines.
Significance. If the empirical findings hold, the work is significant for clarifying sources of inconsistent results in dLLM decoding literature and for establishing prompt sensitivity as a core property that undermines claims of efficient parallel decoding. The strength lies in the direct empirical comparisons across multiple settings that support the sensitivity and underperformance claims without circular derivations.
major comments (2)
- [Abstract] Abstract and the main experimental claims: the assertion that parallel methods 'consistently underperform' the single-token baseline is load-bearing, yet the paper's coverage of dLLMs, tasks, and templates (while described as diverse) leaves open whether the observed ranking instability generalizes beyond the tested instances; an explicit statement of the full set of models/tasks/templates and a limitations discussion on representativeness would strengthen this.
- [Results sections (e.g., §4-5)] The weakest assumption noted in the evaluation (generality of prompt sensitivity) directly affects the 'consistently' qualifier; if the tested settings are not representative, the underperformance conclusion risks being an artifact rather than intrinsic, requiring either broader experiments or clearer scoping in the results sections.
minor comments (1)
- [Experimental setup] Ensure all experimental settings (exact templates, model variants, task definitions) are fully tabulated or linked to allow reproduction and assessment of diversity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We agree that explicitly documenting the experimental coverage and adding a limitations discussion on representativeness will strengthen the manuscript without altering its core empirical findings on prompt sensitivity and underperformance in the tested settings.
read point-by-point responses
-
Referee: [Abstract] Abstract and the main experimental claims: the assertion that parallel methods 'consistently underperform' the single-token baseline is load-bearing, yet the paper's coverage of dLLMs, tasks, and templates (while described as diverse) leaves open whether the observed ranking instability generalizes beyond the tested instances; an explicit statement of the full set of models/tasks/templates and a limitations discussion on representativeness would strengthen this.
Authors: We agree that an explicit enumeration of the evaluated models, tasks, and templates, along with a limitations discussion, will better scope the 'consistently underperform' claim. In the revision we will add a dedicated table or subsection listing all dLLMs, tasks, and prompt templates used in the experiments. We will also insert a limitations paragraph in the discussion section that addresses representativeness, noting that while our settings span multiple models and tasks, broader generalization remains an open question for future work. This clarifies that the underperformance conclusion is tied to the evaluated instances rather than claiming universality. revision: yes
-
Referee: [Results sections (e.g., §4-5)] The weakest assumption noted in the evaluation (generality of prompt sensitivity) directly affects the 'consistently' qualifier; if the tested settings are not representative, the underperformance conclusion risks being an artifact rather than intrinsic, requiring either broader experiments or clearer scoping in the results sections.
Authors: We accept the need for clearer scoping. The revision will add explicit statements at the start of the results sections (§4-5) that qualify the 'consistently' qualifier to the tested settings and reiterate the prompt-sensitivity findings within those bounds. We maintain that the direct comparisons across the diverse settings in the paper support the observed underperformance relative to single-token decoding, but we will not expand the experimental scope at this stage; instead, the added scoping language will prevent overgeneralization while preserving the empirical contribution. revision: yes
Circularity Check
No significant circularity in empirical evaluation study
full rationale
This is an empirical paper whose central claims rest on experimental comparisons of decoding methods across prompt templates, tasks, and models. No derivation chain, equations, or fitted parameters are present that could reduce to self-definition or self-citation by construction. The findings on prompt sensitivity and consistent underperformance are presented as observed outcomes from comprehensive tests, which remain externally falsifiable and independent of any internal redefinition of inputs as predictions. Self-citations, if any, are not load-bearing for the core results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Common single-template evaluation practices are representative of how the community assesses dLLM decoding methods
Reference graph
Works this paper leans on
-
[1]
Structuring The Future: Diffusion LLM Speculative Decoding via Calibrated Draft Graphs
Sudhanshu Agrawal, Risheek Garrepalli, Raghavv Goel, Mingu Lee, Christopher Lott, and Fatih Porikli. Spiffy: Multiplying diffusion llm acceleration via lossless speculative decoding. arXiv preprint arXiv:2509.18085, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Learning to parallel: Accelerating diffusion large language models via learnable parallel decoding
Wenrui Bao, Zhiben Chen, Dan Xu, and Yuzhang Shang. Learning to parallel: Accelerating diffusion large language models via learnable parallel decoding. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[3]
Accelerated sampling from masked diffusion models via entropy bounded unmasking
Heli Ben-Hamu, Itai Gat, Daniel Severo, Niklas Nolte, and Brian Karrer. Accelerated sampling from masked diffusion models via entropy bounded unmasking. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[4]
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, et al. Llada2. 0: Scaling up diffusion language models to 100b.arXiv preprint arXiv:2512.15745, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
DPad: Efficient diffusion language models with suffix dropout
Xinhua Chen, Sitao Huang, Cong Guo, Chiyue Wei, Yintao He, Jianyi Zhang, Hai Helen Li, and Yiran Chen. DPad: Efficient diffusion language models with suffix dropout. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[6]
dparallel: Learn- able parallel decoding for dLLMs
Zigeng Chen, Gongfan Fang, Xinyin Ma, Ruonan Yu, and Xinchao Wang. dparallel: Learn- able parallel decoding for dLLMs. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[7]
Self Speculative Decoding for Diffusion Large Language Models
Yifeng Gao, Ziang Ji, Yuxuan Wang, Biqing Qi, Hanlin Xu, and Linfeng Zhang. Self speculative decoding for diffusion large language models.arXiv preprint arXiv:2510.04147, 2025
-
[8]
Gemini diffusion
Google DeepMind. Gemini diffusion. https://deepmind.google/models/ gemini-diffusion/, 2025. Accessed: 2026-05-04
2025
-
[9]
Wide-in, narrow-out: Revokable decoding for efficient and effective DLLMs
Feng Hong, Geng Yu, Yushi Ye, Haicheng Huang, Huangjie Zheng, Ya Zhang, Yanfeng Wang, and Jiangchao Yao. Wide-in, narrow-out: Revokable decoding for efficient and effective DLLMs. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[10]
Zhanqiu Hu, Jian Meng, Yash Akhauri, Mohamed S Abdelfattah, Jae-sun Seo, Zhiru Zhang, and Udit Gupta. Flashdlm: Accelerating diffusion language model inference via efficient kv caching and guided diffusion.arXiv preprint arXiv:2505.21467, 2025
-
[11]
Flaw or artifact? rethinking prompt sensitivity in evaluating llms
Andong Hua, Kenan Tang, Chenhe Gu, Jindong Gu, Eric Wong, and Yao Qin. Flaw or artifact? rethinking prompt sensitivity in evaluating llms. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 19900–19910, 2025
2025
-
[12]
d$^2$cache: Accelerating diffusion-based LLMs via dual adaptive caching
Yuchu Jiang, Yue Cai, Xiangzhong Luo, Jiale Fu, Jiarui Wang, Chonghan Liu, and Xu Yang. d$^2$cache: Accelerating diffusion-based LLMs via dual adaptive caching. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[13]
How can we know what language models know?Transactions of the Association for Computational Linguistics, 8:423–438, 2020
Zhengbao Jiang, Frank F Xu, Jun Araki, and Graham Neubig. How can we know what language models know?Transactions of the Association for Computational Linguistics, 8:423–438, 2020
2020
-
[14]
Parallelbench: Understanding the trade-offs of parallel decoding in diffusion LLMs
Wonjun Kang, Kevin Galim, Seunghyuk Oh, Minjae Lee, Yuchen Zeng, Shuibai Zhang, Cole- man Richard Charles Hooper, Yuezhou Hu, Hyung Il Koo, Nam Ik Cho, and Kangwook Lee. Parallelbench: Understanding the trade-offs of parallel decoding in diffusion LLMs. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[15]
Mercury: Ultra-fast language models based on diffusion.arXiv e-prints, pages arXiv–2506, 2025
Samar Khanna, Siddhant Kharbanda, Shufan Li, Harshit Varma, Eric Wang, Sawyer Birnbaum, Ziyang Luo, Yanis Miraoui, Akash Palrecha, Stefano Ermon, et al. Mercury: Ultra-fast language models based on diffusion.arXiv e-prints, pages arXiv–2506, 2025
2025
-
[16]
Diffusion language model knows the answer before it decodes
Pengxiang Li, Yefan Zhou, Dilxat Muhtar, Lu Yin, Shilin Yan, Li Shen, Yi Liang, Soroush V osoughi, and Shiwei Liu. Diffusion language model knows the answer before it decodes. In The Fourteenth International Conference on Learning Representations, 2026. 10
2026
-
[17]
Jiachang Liu, Dinghan Shen, Yizhe Zhang, William B Dolan, Lawrence Carin, and Weizhu Chen. What makes good in-context examples for gpt-3? InProceedings of Deep Learning Inside Out (DeeLIO 2022): The 3rd workshop on knowledge extraction and integration for deep learning architectures, pages 100–114, 2022
2022
-
[18]
Lookahead path likelihood optimization for diffusion llms.arXiv preprint arXiv:2602.03496, 2026
Xuejie Liu, Yap Vit Chun, Yitao Liang, and Anji Liu. Lookahead path likelihood optimization for diffusion llms.arXiv preprint arXiv:2602.03496, 2026
-
[19]
dLLM-Cache: Accelerating Diffusion Large Language Models with Adaptive Caching
Zhiyuan Liu, Yicun Yang, Yaojie Zhang, Junjie Chen, Chang Zou, Qingyuan Wei, Shaobo Wang, and Linfeng Zhang. dllm-cache: Accelerating diffusion large language models with adaptive caching.arXiv preprint arXiv:2506.06295, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Semantic-aware diffusion LLM inference with adaptive block size
Guanxi Lu, Hao Mark Chen, Yuto Karashima, Zhican Wang, Daichi Fujiki, and Hongxiang Fan. Semantic-aware diffusion LLM inference with adaptive block size. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[21]
Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity
Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8086–8098, 2022
2022
-
[22]
dKV-cache: The cache for diffusion language models
Xinyin Ma, Runpeng Yu, Gongfan Fang, and Xinchao Wang. dKV-cache: The cache for diffusion language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[23]
State of what art? a call for multi-prompt llm evaluation.Transactions of the Association for Computational Linguistics, 12:933–949, 2024
Moran Mizrahi, Guy Kaplan, Dan Malkin, Rotem Dror, Dafna Shahaf, and Gabriel Stanovsky. State of what art? a call for multi-prompt llm evaluation.Transactions of the Association for Computational Linguistics, 12:933–949, 2024
2024
-
[24]
Attention is all you need for KV cache in diffusion LLMs
Quan Nguyen-Tri, Mukul Ranjan, and Zhiqiang Shen. Attention is all you need for KV cache in diffusion LLMs. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[25]
Large language diffusion models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, JUN ZHOU, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[26]
True few-shot learning with language models
Ethan Perez, Douwe Kiela, and Kyunghyun Cho. True few-shot learning with language models. Advances in neural information processing systems, 34:11054–11070, 2021
2021
-
[27]
Efficient multi-prompt evaluation of llms.Advances in Neural Information Processing Systems, 37:22483–22512, 2024
Felipe M Polo, Ronald Xu, Lucas Weber, Mírian Silva, Onkar Bhardwaj, Leshem Choshen, Allysson F de Oliveira, Yuekai Sun, and Mikhail Yurochkin. Efficient multi-prompt evaluation of llms.Advances in Neural Information Processing Systems, 37:22483–22512, 2024
2024
-
[28]
Benchmarking prompt sensitivity in large language models
Amirhossein Razavi, Mina Soltangheis, Negar Arabzadeh, Sara Salamat, Morteza Zihayat, and Ebrahim Bagheri. Benchmarking prompt sensitivity in large language models. InEuropean Conference on Information Retrieval, pages 303–313. Springer, 2025
2025
-
[29]
Toward the evaluation of large language models considering score variance across instruction templates
Yusuke Sakai, Adam Nohejl, Jiangnan Hang, Hidetaka Kamigaito, and Taro Watanabe. Toward the evaluation of large language models considering score variance across instruction templates. InProceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pages 499–529, 2024
2024
-
[30]
Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[31]
Sparse-dllm: Accelerating diffusion llms with dynamic cache eviction
Yuerong Song, Xiaoran Liu, Ruixiao Li, Zhigeng Liu, Zengfeng Huang, Qipeng Guo, Ziwei He, and Xipeng Qiu. Sparse-dllm: Accelerating diffusion llms with dynamic cache eviction. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 33038–33046, 2026. 11
2026
-
[32]
Seed Diffusion: A Large-Scale Diffusion Language Model with High-Speed Inference
Yuxuan Song, Zheng Zhang, Cheng Luo, Pengyang Gao, Fan Xia, Hao Luo, Zheng Li, Yuehang Yang, Hongli Yu, Xingwei Qu, et al. Seed diffusion: A large-scale diffusion language model with high-speed inference.arXiv preprint arXiv:2508.02193, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Albert Webson and Ellie Pavlick. Do prompt-based models really understand the meaning of their prompts? InProceedings of the 2022 conference of the north american chapter of the association for computational linguistics: Human language technologies, pages 2300–2344, 2022
2022
-
[34]
Accelerating diffusion large language models with slowfast sam- pling: The three golden principles
Qingyan Wei, Yaojie Zhang, Zhiyuan Liu, Puyu Zeng, Yuxuan Wang, Biqing Qi, Dongrui Liu, and Linfeng Zhang. Accelerating diffusion large language models with slowfast sam- pling: The three golden principles. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[35]
Fast-dLLM: Training-free acceleration of diffusion LLM by enabling KV cache and parallel decoding
Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. Fast-dLLM: Training-free acceleration of diffusion LLM by enabling KV cache and parallel decoding. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[36]
Free draft-and-verification: Toward lossless parallel decoding for diffusion large language models
Shutong Wu and Jiawei Zhang. Free draft-and-verification: Toward lossless parallel decoding for diffusion large language models. InNeurIPS 2025 Workshop on Efficient Reasoning, 2025
2025
-
[37]
Dynamic-dLLM: Dynamic cache-budget and adaptive parallel decoding for training-free acceleration of diffusion LLM
Tianyi Wu, Xiaoxi Sun, Yanhua Jiao, Yulin Li, Yixin Chen, Yun-Hao Cao, Yi-Qi Hu, and Zhuotao Tian. Dynamic-dLLM: Dynamic cache-budget and adaptive parallel decoding for training-free acceleration of diffusion LLM. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[38]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Understanding and mitigating numerical sources of nondeterminism in LLM inference
Jiayi Yuan, Hao Li, Xinheng Ding, Wenya Xie, Yu-Jhe Li, Wentian Zhao, Kun Wan, Jing Shi, Xia Hu, and Zirui Liu. Understanding and mitigating numerical sources of nondeterminism in LLM inference. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[40]
Calibrate before use: Improving few-shot performance of language models
Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. Calibrate before use: Improving few-shot performance of language models. InInternational conference on machine learning, pages 12697–12706. Pmlr, 2021
2021
-
[41]
Tong Zheng, Chengsong Huang, Runpeng Dai, Yun He, Rui Liu, Xin Ni, Huiwen Bao, Kaishen Wang, Hongtu Zhu, Jiaxin Huang, et al. Parallel-probe: Towards efficient parallel thinking via 2d probing.arXiv preprint arXiv:2602.03845, 2026
-
[42]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
Fengqi Zhu, Rongzhen Wang, Shen Nie, Xiaolu Zhang, Chunwei Wu, Jun Hu, Jun Zhou, Jianfei Chen, Yankai Lin, Ji-Rong Wen, et al. Llada 1.5: Variance-reduced preference optimization for large language diffusion models.arXiv preprint arXiv:2505.19223, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Promptrobust: Towards evaluating the robustness of large language models on adversarial prompts
Kaijie Zhu, Jindong Wang, Jiaheng Zhou, Zichen Wang, Hao Chen, Yidong Wang, Linyi Yang, Wei Ye, Yue Zhang, Neil Gong, et al. Promptrobust: Towards evaluating the robustness of large language models on adversarial prompts. InProceedings of the 1st ACM workshop on large AI systems and models with privacy and safety analysis, pages 57–68, 2023
2023
-
[44]
Zijian Zhu, Fei Ren, Zhanhong Tan, and Kaisheng Ma. Es-dllm: Efficient inference for diffusion large language models by early-skipping.arXiv preprint arXiv:2603.10088, 2026. 12 Appendix Table of Contents A Impact Statement and Limitation 13 B Related Work 13 C Experimental Details 14 C.1 Decoding methods for dLLMs . . . . . . . . . . . . . . . . . . . . ....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.