Scaling by Diversified Experience for Vision-Language-Action Models
Pith reviewed 2026-06-27 17:11 UTC · model grok-4.3
The pith
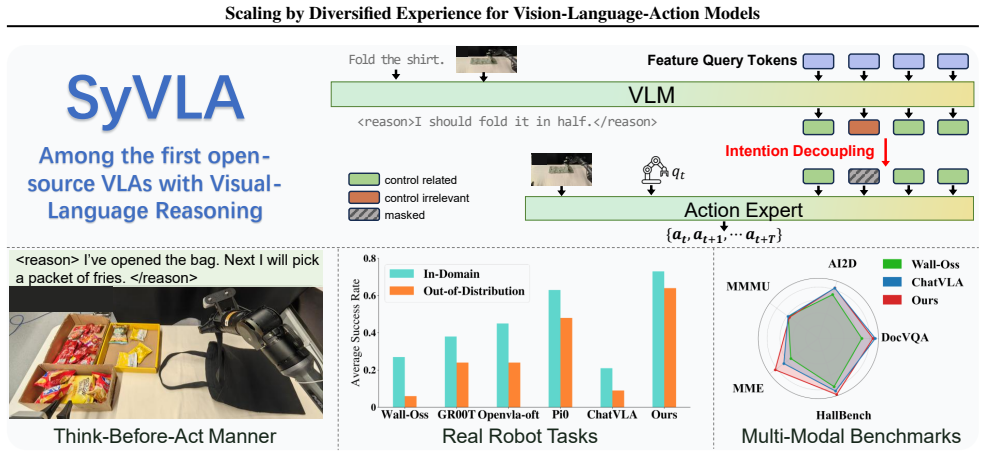
SyVLA uses intention decoupling and guided reinforcement learning on diversified experiences to raise robotic task success and out-of-distribution generalization while keeping vision-language skills intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
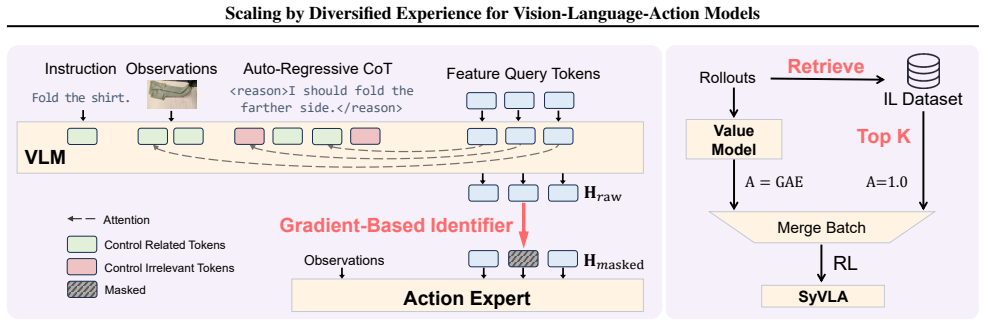
SyVLA is a VLA model trained with diversified experiences. It applies an Intention Decoupling algorithm to isolate control-relevant features from reasoning contexts and a similar-sample guided RL pipeline to stabilize policy updates and mitigate distribution shift, resulting in superior task success rates, stronger out-of-distribution generalization on robotic tasks, and maintained core vision-language capabilities.
What carries the argument
Intention Decoupling algorithm that isolates control-relevant features from reasoning contexts, combined with a similar-sample guided RL pipeline for stable policy updates.
If this is right
- SyVLA records higher success rates on real-world robotic tasks than existing VLA methods.
- The model shows stronger generalization to out-of-distribution conditions.
- Core vision-language capabilities remain intact alongside gains in control.
- Policy optimization becomes more stable with reduced distribution shift during training.
Where Pith is reading between the lines
- The separation of reasoning and control features may prove useful in other multimodal control settings that face similar entanglement.
- Diversified experience collection could support scaling VLA training to more complex or longer-horizon tasks without proportional instability.
Load-bearing premise
The Intention Decoupling algorithm isolates control-relevant features from reasoning contexts and the similar-sample guided RL pipeline stabilizes updates without introducing new distribution issues.
What would settle it
If real-world robotic task success rates show no improvement or decline after applying the Intention Decoupling algorithm and similar-sample guided RL pipeline compared with baseline VLA models, the central performance claim would be falsified.
Figures

read the original abstract
Vision-Language-Action models face significant challenges in real-world deployment due to the entanglement of high-level reasoning with low-level control, and the instability of policy optimization. In this paper, we introduce SyVLA, a robust VLA model trained with diversified experiences. We propose an Intention Decoupling algorithm to isolate control-relevant features from reasoning contexts and a similar-sample guided RL pipeline to stabilize policy updates and mitigate distribution shift. Extensive experiments on real-world robotic tasks and multi-modal benchmarks demonstrate that SyVLA achieves superior task success rates and stronger out-of-distribution generalization compared to existing methods, while effectively preserving core vision-language capabilities. Codes and Datasets is released on \href{https://sy-vla.github.io/}{project page}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SyVLA, a robust VLA model trained with diversified experiences. It proposes an Intention Decoupling algorithm to isolate control-relevant features from reasoning contexts and a similar-sample guided RL pipeline to stabilize policy updates and mitigate distribution shift. Extensive experiments on real-world robotic tasks and multi-modal benchmarks are claimed to demonstrate superior task success rates, stronger out-of-distribution generalization compared to existing methods, while preserving core vision-language capabilities. Codes and datasets are released.
Significance. If the experimental claims hold, this would represent a meaningful advance for vision-language-action models by directly targeting the entanglement of high-level reasoning with low-level control and the instability of policy optimization, potentially improving real-world robustness and OOD generalization without sacrificing VLM capabilities. The public release of code and data is a clear strength for reproducibility.
major comments (1)
- [Abstract] Abstract: the central claim that SyVLA achieves 'superior task success rates and stronger out-of-distribution generalization' is stated without any experimental details, baselines, metrics, error analysis, or quantitative results. This absence makes it impossible to evaluate whether the data support the performance claims that constitute the paper's main contribution.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for more concrete details in the abstract. We address this point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that SyVLA achieves 'superior task success rates and stronger out-of-distribution generalization' is stated without any experimental details, baselines, metrics, error analysis, or quantitative results. This absence makes it impossible to evaluate whether the data support the performance claims that constitute the paper's main contribution.
Authors: We agree that the abstract would be strengthened by including key quantitative results. The full paper reports these details in Sections 4 and 5 (e.g., task success rates on real-world robotic tasks, OOD generalization metrics on multi-modal benchmarks, comparisons to baselines such as RT-2 and OpenVLA, and ablation studies). In the revised version we will add concise numerical highlights to the abstract, such as average success rate improvements and specific OOD metrics, while preserving the word limit. revision: yes
Circularity Check
No significant circularity
full rationale
The provided abstract and context describe two algorithmic contributions (Intention Decoupling and similar-sample guided RL) whose value is asserted via empirical results on robotic tasks and benchmarks. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the text. The central claims rest on experimental outcomes rather than any reduction to inputs by construction. With no load-bearing mathematical steps present, the derivation chain (such as it is) is self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
-
[2]
Beyer, L., Steiner, A., Pinto, A. S., Kolesnikov, A., Wang, X., Salz, D., Neumann, M., Alabdulmohsin, I., Tschan- nen, M., Bugliarello, E., et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726,
-
[3]
Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734,
Bjorck, J., Casta˜neda, F., Cherniadev, N., Da, X., Ding, R., Fan, L., Fang, Y ., Fox, D., Hu, F., Huang, S., et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734,
- [5]
-
[6]
πRL: Online rl fine-tuning for flow-based vision-language-action models
Chen, K., Liu, Z., Zhang, T., Guo, Z., Xu, S., Lin, H., Zang, H., Li, X., Zhang, Q., Yu, Z., et al. πRL: Online rl fine-tuning for flow-based vision-language-action models. arXiv preprint arXiv:2510.25889, 2025a. Chen, Y ., Tian, S., Liu, S., Zhou, Y ., Li, H., and Zhao, D. Conrft: A reinforced fine-tuning method for vla models via consistency policy.arXi...
-
[7]
Diffusion guidance is a controllable policy improvement operator
Frans, K., Park, S., Abbeel, P., and Levine, S. Diffusion guidance is a controllable policy improvement operator. arXiv preprint arXiv:2505.23458,
-
[8]
Hung, C.-Y ., Majumder, N., Deng, H., Renhang, L., Ang, Y ., Zadeh, A., Li, C., Herremans, D., Wang, Z., and Poria, S. Nora-1.5: A vision-language-action model trained using world model-and action-based preference rewards.arXiv preprint arXiv:2511.14659,
-
[9]
π∗ 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025a
Intelligence, P., Amin, A., Aniceto, R., Balakrishna, A., Black, K., Conley, K., Connors, G., Darpinian, J., Dha- balia, K., DiCarlo, J., et al. π∗ 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025a. Intelligence, P., Black, K., Brown, N., Darpinian, J., Dha- balia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., et a...
-
[10]
Kim, M. J., Pertsch, K., Karamcheti, S., Xiao, T., Balakr- ishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., San- keti, P., et al. Openvla: An open-source vision-language- action model.arXiv preprint arXiv:2406.09246,
-
[11]
Kim, M. J., Finn, C., and Liang, P. Fine-tuning vision- language-action models: Optimizing speed and success. arXiv preprint arXiv:2502.19645,
-
[12]
Lei, K., Li, H., Yu, D., Wei, Z., Guo, L., Jiang, Z., Wang, Z., Liang, S., and Xu, H. Rl-100: Performant robotic ma- nipulation with real-world reinforcement learning.arXiv preprint arXiv:2510.14830,
-
[13]
Simplevla-rl: Scaling vla training via reinforcement learning.arXiv preprint arXiv:2509.09674, 2025a
Li, H., Zuo, Y ., Yu, J., Zhang, Y ., Yang, Z., Zhang, K., Zhu, X., Zhang, Y ., Chen, T., Cui, G., et al. Simplevla-rl: Scaling vla training via reinforcement learning.arXiv preprint arXiv:2509.09674, 2025a. Li, Y ., Ma, X., Xu, J., Cui, Y ., Cui, Z., Han, Z., Huang, L., Kong, T., Liu, Y ., Niu, H., et al. Gr-rl: Going dexterous and precise for long-horiz...
-
[14]
T., Ben-Hamu, H., Nickel, M., and Le, M
Lipman, Y ., Chen, R. T., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
-
[15]
Libero: Benchmarking knowledge transfer for lifelong robot learning.arXiv preprint arXiv:2306.03310,
Liu, B., Zhu, Y ., Gao, C., Feng, Y ., Liu, Q., Zhu, Y ., and Stone, P. Libero: Benchmarking knowledge transfer for lifelong robot learning.arXiv preprint arXiv:2306.03310,
-
[16]
Flow-grpo: Training flow matching models via online rl, 2025.URL https://arxiv
Liu, J., Liu, G., Liang, J., Li, Y ., Liu, J., Wang, X., Wan, P., Zhang, D., and Ouyang, W. Flow-grpo: Training flow matching models via online rl, 2025.URL https://arxiv. org/abs/2505.05470, 2:5,
Pith/arXiv arXiv 2025
-
[17]
Luo, J., Xu, C., Wu, J., and Levine, S. Precise and dexterous robotic manipulation via human-inthe-loop reinforcement learning.arXiv preprint arXiv:2410.21845, 2(3),
-
[18]
Pertsch, K., Stachowicz, K., Ichter, B., Driess, D., Nair, S., Vuong, Q., Mees, O., Finn, C., and Levine, S. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747,
-
[19]
Proximal policy optimization algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
-
[20]
dvla: Diffusion vision- language-action model with multimodal chain-of-thought
Wen, J., Zhu, M., Liu, J., Liu, Z., Yang, Y ., Zhang, L., Zhang, S., Zhu, Y ., and Xu, Y . dvla: Diffusion vision- language-action model with multimodal chain-of-thought. arXiv preprint arXiv:2509.25681, 2025a. Wen, J., Zhu, Y ., Li, J., Tang, Z., Shen, C., and Feng, F. Dexvla: Vision-language model with plug-in diffu- sion expert for general robot contro...
-
[21]
Igniting vlms toward the embodied space.arXiv preprint arXiv:2509.11766,
Zhai, A., Liu, B., Fang, B., Cai, C., Ma, E., Yin, E., Wang, H., Zhou, H., Wang, J., Shi, L., et al. Igniting vlms toward the embodied space.arXiv preprint arXiv:2509.11766,
-
[22]
Rein- forcing action policies by prophesying.arXiv preprint arXiv:2511.20633,
Zhang, J., Huang, Z., Gu, C., Ma, Z., and Zhang, L. Rein- forcing action policies by prophesying.arXiv preprint arXiv:2511.20633,
-
[23]
Chatvla-2: Vision-language-action model with open-world reasoning
Zhou, Z., Zhu, Y ., Liu, X., Tang, Z., Wen, J., Peng, Y ., Shen, C., and Xu, Y . Chatvla-2: Vision-language-action model with open-world reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025a. Zhou, Z., Zhu, Y ., Zhu, M., Wen, J., Liu, N., Xu, Z., Meng, W., Peng, Y ., Shen, C., Feng, F., et al. Chatvla: Uni- fied m...
arXiv 2025
-
[24]
More Implementation Details We describe the implementation details of our SyVLA model
12 Scaling by Diversified Experience for Vision-Language-Action Models A. More Implementation Details We describe the implementation details of our SyVLA model. We choose Qwen2.5-VL 3B as the VLM of SyVLA. For the Feature Query Tokens, we use a fixed set of learnable tensors. Across all three experiments, we use 20 Feature Query Tokens with a dimensionali...
2048
-
[25]
This corresponds to what we describe in Section 3.1 and 3.2, i.e., C= Adapter(H)
A point worth emphasizing is that the Feature Query States produced by the VLM are not used directly as the control condition C for the Action Expert; instead, they are first passed through an MLP Adapter. This corresponds to what we describe in Section 3.1 and 3.2, i.e., C= Adapter(H) . We do so for two reasons: (1) to change the dimensionality of the Fe...
2023
-
[26]
We also compare ourSimilar-Sample Guidance RLalgorithm with recent SOTA RL method SimpleVLA-RL (Li et al., 2025a) and Pi-RL (Chen et al., 2025a) onFold Shirttask
Task 2 Task 3 w/o Similar Retrival 0.56 0.571 SyVLA 0.68 0.643 Table 10.Ablation study of RL algorithm on the other 2 Tasks. We also compare ourSimilar-Sample Guidance RLalgorithm with recent SOTA RL method SimpleVLA-RL (Li et al., 2025a) and Pi-RL (Chen et al., 2025a) onFold Shirttask. The results are shown in Table 11 Pi-RL Simple VLA SyVLA 0.714 0.357 ...
2024
-
[27]
synthesize actions through multi-step denoising, enabling finer-grained control and dexterous manipulation; however, they commonly use pretrained VLMs only as initialization, leading to catastrophic forgetting of general vision–language capabilities after VLA training. Recent works (Zhou et al., 2025a;b; Zhai et al., 2025; Intelligence et al., 2025b) mix ...
2025
-
[28]
to represent actions at intermediate layers and adopt a two-stage generation paradigm; such methods are typically sensitive to the scale and alignment quality of pretraining data, and may produce meaningless action token generations when data are insufficient. Our approach leverages Feature Query Token and the Intention Decoupling algorithm to effectively...
2025
-
[29]
improves capability through a two-stage pipeline—offline reinforcement learning followed by online reinforcement learning—but has only been validated on small diffusion models, and its effectiveness for VLA-scale models remains to be established. Some other methods also attempt to improve the data efficiency and safety through residual policies (Xiao et a...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.