Agentic RAG-VLM: Affordance-Aware Retrieval-Augmented Generation with Self-Reflective Planning for Robotic Grasping
Pith reviewed 2026-07-01 05:59 UTC · model grok-4.3
The pith
Agentic RAG-VLM reaches 78.3 percent success in robotic grasping by retrieving strategies based on physical affordances and adding self-reflective recovery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
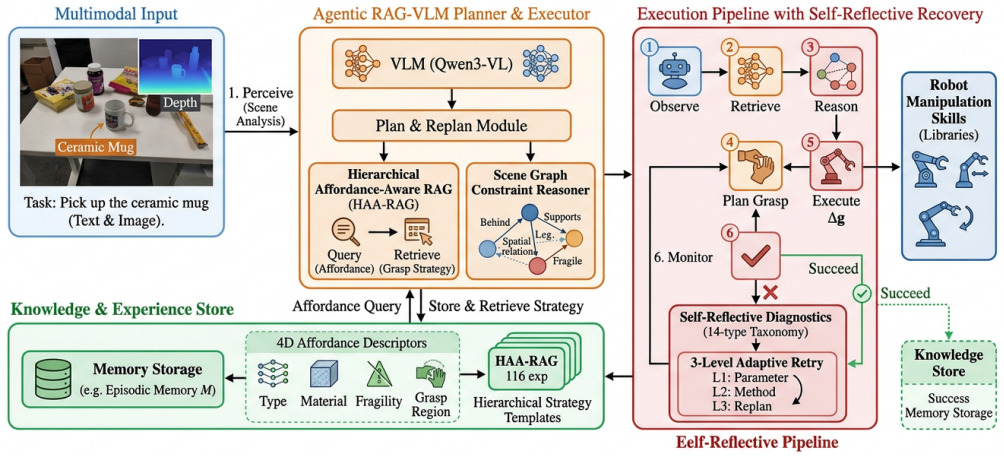
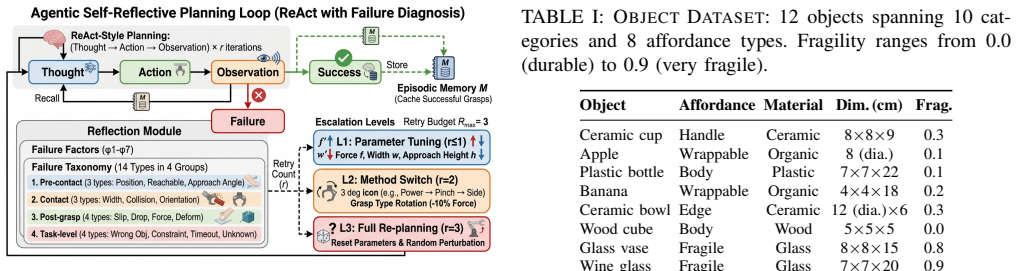
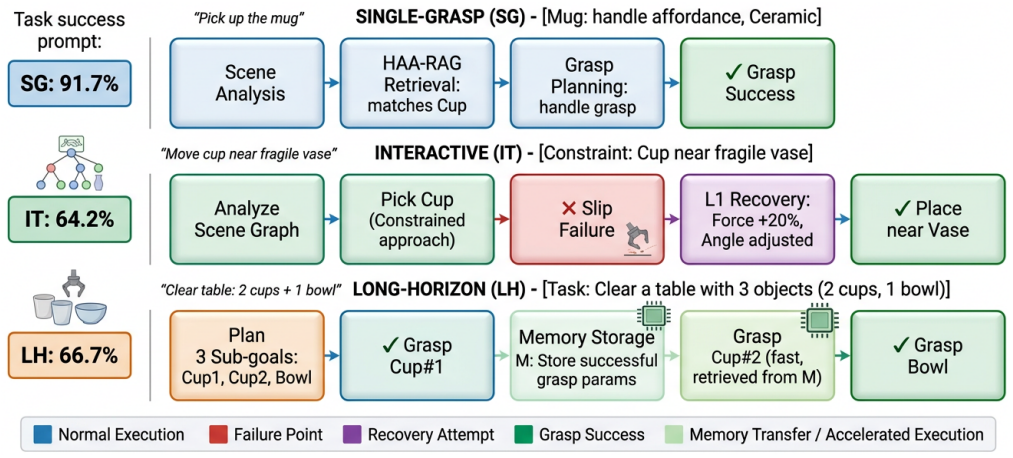
Agentic RAG-VLM integrates hierarchical affordance-aware retrieval-augmented generation with vision-language models and agentic self-reflective planning. It encodes four-dimensional affordance descriptors for retrieval by functional compatibility, constructs scene graphs to translate proximity, occlusion, and support constraints into grasp parameters, and applies a fourteen-type failure taxonomy with three-level adaptive retry for closed-loop refinement, producing 78.3 percent overall success across single-grasp, interactive, and long-horizon scenarios.
What carries the argument
Hierarchical Affordance-Aware RAG (HAA-RAG) that retrieves grasp strategies by matching four-dimensional affordance descriptors (type, material, fragility, graspable region) rather than visual appearance, together with the Scene Graph Constraint Reasoner and the Agentic Self-Reflective Pipeline.
If this is right
- Affordance-based retrieval enables grasp planning for objects that look different but share functional properties.
- Scene-graph constraints allow grasp parameter changes when objects are occluded or stacked.
- The fourteen-type failure taxonomy and adaptive retry support recovery in long-horizon sequences.
- Joint use of retrieval, spatial reasoning, and closed-loop recovery is presented as necessary for reliable performance in dense scenes.
Where Pith is reading between the lines
- If the affordance descriptors prove portable, the method could lower the data volume needed to adapt grasping systems to new households or factories.
- The same retrieval-plus-reflection structure may apply to other contact-rich tasks such as tool use or assembly.
- Performance differences highlight that adding explicit physical categories can compensate for gaps in current vision-language model spatial reasoning.
Load-bearing premise
The four-dimensional affordance descriptors and the fourteen-type failure taxonomy are assumed to be both sufficient and transferable to new objects and environments without post-hoc adjustment or domain-specific retraining.
What would settle it
Running the full system on a fresh collection of objects whose materials, fragility levels, or graspable regions lie outside the four predefined descriptor categories, or whose failure modes exceed the fourteen-type taxonomy, would show whether overall success falls back toward the VLM-only baseline.
Figures

read the original abstract
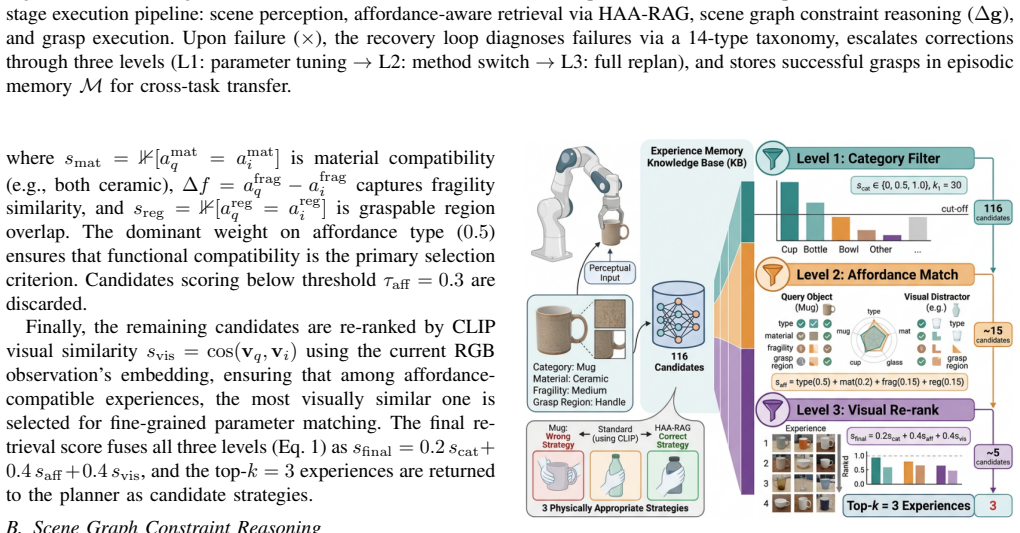
Generalizable robotic grasping in cluttered environments is essential for deploying manipulators in unstructured human spaces, yet existing VLM-based methods rely on visual similarity for object matching, neglecting physical affordances such as handle graspability and material fragility, and operate open-loop without spatial reasoning or failure recovery, limiting their effectiveness when objects are densely packed or physically diverse. We present Agentic RAG-VLM, a unified framework that bridges VLM-based semantic understanding and physically grounded grasp execution by integrating retrieval-augmented generation (RAG) with vision-language models (VLMs) and agentic self-reflective planning. Agentic RAG-VLM introduces three tightly coupled components: (1) a Hierarchical Affordance-Aware RAG (HAA-RAG) that encodes four-dimensional affordance descriptors, including type, material, fragility, and graspable region, and retrieves strategies by functional affordance compatibility rather than visual appearance; (2) a Scene Graph Constraint Reasoner that constructs spatial relationship graphs from VLM perception and translates proximity, occlusion, and support constraints into concrete grasp parameter adjustments; and (3) an Agentic Self-Reflective Pipeline with a 14-type failure taxonomy and three-level adaptive retry for closed-loop grasp refinement. Evaluated on a 12-task benchmark spanning single-grasp, interactive, and long-horizon scenarios with 360 trials per configuration, Agentic RAG-VLM achieves 78.3 percent overall success, a 53.3 percentage-point absolute gain over VLM-only baselines, demonstrating that affordance-aware retrieval, scene graph reasoning, and agentic recovery are jointly essential for robust manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Agentic RAG-VLM, a framework integrating retrieval-augmented generation with vision-language models for robotic grasping in cluttered environments. It proposes three components: Hierarchical Affordance-Aware RAG (HAA-RAG) encoding four-dimensional affordance descriptors (type, material, fragility, graspable region) for functional retrieval; a Scene Graph Constraint Reasoner translating spatial relations into grasp adjustments; and an Agentic Self-Reflective Pipeline using a 14-type failure taxonomy with three-level adaptive retry. Evaluated on a 12-task benchmark (single-grasp, interactive, long-horizon) with 360 trials per configuration, it reports 78.3% overall success, a 53.3 percentage-point gain over VLM-only baselines.
Significance. If the performance gains hold after controlling for baseline details and are shown to stem from the affordance descriptors and failure taxonomy rather than in-distribution tuning, the work could advance physically grounded VLM-based manipulation by addressing limitations in visual-similarity matching and open-loop execution. The explicit integration of RAG for strategy retrieval and closed-loop recovery offers a concrete path toward generalizable grasping in unstructured settings.
major comments (2)
- [Abstract/Evaluation] Abstract and Evaluation section: the headline claim of a 53.3 pp absolute gain depends on the 4D affordance descriptors and 14-type taxonomy being sufficient and transferable, yet the manuscript supplies no ablation removing individual descriptor dimensions nor OOD tests on held-out objects/materials, leaving the central assumption unsecured.
- [Evaluation] Evaluation section: no information is given on VLM-only baseline implementations, statistical significance testing, or controls for simulation fidelity and object selection, which is required to attribute the 78.3% success rate to the proposed mechanisms rather than confounding factors.
minor comments (2)
- [Abstract] The abstract could more precisely state the total number of configurations and whether the 360 trials are per task or aggregated.
- [Methods] Notation for the four-dimensional descriptors and the 14-type taxonomy could be introduced with a table or explicit list in the methods for clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment below, acknowledging where the manuscript requires expansion and outlining the revisions we will make.
read point-by-point responses
-
Referee: [Abstract/Evaluation] Abstract and Evaluation section: the headline claim of a 53.3 pp absolute gain depends on the 4D affordance descriptors and 14-type taxonomy being sufficient and transferable, yet the manuscript supplies no ablation removing individual descriptor dimensions nor OOD tests on held-out objects/materials, leaving the central assumption unsecured.
Authors: We agree that the manuscript does not contain ablations that isolate the contribution of each of the four affordance dimensions (type, material, fragility, graspable region) or out-of-distribution tests on held-out objects and materials. The reported 53.3 pp gain reflects the integrated Agentic RAG-VLM system rather than component-wise validation. While the hierarchical design of HAA-RAG and the 14-type taxonomy are directly motivated by the limitations of visual-similarity matching and open-loop execution, we accept that explicit ablations would more rigorously support the central claims. We will add targeted ablations on descriptor dimensions in the revised Evaluation section; however, new OOD experiments on held-out objects/materials would require additional data collection beyond the original 12-task benchmark. revision: partial
-
Referee: [Evaluation] Evaluation section: no information is given on VLM-only baseline implementations, statistical significance testing, or controls for simulation fidelity and object selection, which is required to attribute the 78.3% success rate to the proposed mechanisms rather than confounding factors.
Authors: The referee is correct that the current manuscript provides insufficient detail on the VLM-only baseline implementations, any statistical significance testing, and explicit controls for simulation fidelity or object selection. We will revise the Evaluation section to include: (1) precise descriptions of how the VLM-only baselines were implemented (including prompting strategy and output parsing), (2) results of statistical significance tests (e.g., paired t-tests or Wilcoxon tests across the 360 trials per configuration), and (3) documentation of simulation parameters, object selection criteria, and scene generation procedures to demonstrate that performance differences are attributable to the proposed mechanisms rather than experimental confounds. revision: yes
- New out-of-distribution experiments on held-out objects and materials, as these were not performed in the original study and would require substantial additional experimental effort.
Circularity Check
No circularity: empirical system evaluation with no derivations or fitted predictions
full rationale
The paper describes a robotic grasping framework (HAA-RAG with 4D descriptors, scene graph reasoner, 14-type failure taxonomy) and reports direct experimental outcomes (78.3% success on 12-task benchmark with 360 trials). No equations, parameter fits presented as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text. Central claims rest on benchmark measurements rather than any reduction to inputs by construction, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Antipodal robotic grasping using generative residual convolutional neural network,
S. Kumra, S. Joshi, and F. Sahin, “Antipodal robotic grasping using generative residual convolutional neural network,” inIEEE/RSJ Inter- national Conference on Intelligent Robots and Systems (IROS), 2020
2020
-
[2]
AnyGrasp: Robust and efficient grasp perception in spatial and temporal domains,
H.-S. Fang, C. Wang, H. Fang, M. Gou, J. Liu, H. Yan, W. Liu, Y . Xie, and C. Lu, “AnyGrasp: Robust and efficient grasp perception in spatial and temporal domains,”IEEE Transactions on Robotics (T-RO), 2023
2023
-
[3]
CLIPort: What and where pathways for robotic manipulation,
M. Shridhar, L. Manuelli, and D. Fox, “CLIPort: What and where pathways for robotic manipulation,” inConference on Robot Learning (CoRL), 2022
2022
-
[4]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choro- manskiet al., “RT-2: Vision-language-action models transfer web knowledge to robotic control,”arXiv preprint arXiv:2307.15818, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Do as i can, not as i say: Grounding language in robotic affordances,
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Corteset al., “Do as i can, not as i say: Grounding language in robotic affordances,” in Conference on Robot Learning (CoRL), 2022
2022
-
[6]
V oxPoser: Composable 3d value maps for robotic manipulation with language models,
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei, “V oxPoser: Composable 3d value maps for robotic manipulation with language models,” inConference on Robot Learning (CoRL), 2023
2023
-
[7]
Code as policies: Language model programs for embodied control,
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng, “Code as policies: Language model programs for embodied control,” inIEEE International Conference on Robotics and Automation (ICRA), 2023
2023
-
[8]
ManipLLM: Embodied multimodal large language model for object- centric robotic manipulation,
X. Li, M. Zhang, Y . Geng, H. Geng, Y . Long, Y . Shen, H. Wanget al., “ManipLLM: Embodied multimodal large language model for object- centric robotic manipulation,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[9]
Learn- ing transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Gohet al., “Learn- ing transferable visual models from natural language supervision,” in International Conference on Machine Learning (ICML), 2021
2021
-
[10]
The theory of affordances,
J. J. Gibson, “The theory of affordances,”Hilldale, USA, vol. 1, no. 2, pp. 67–82, 1977
1977
-
[11]
Transporter networks: Rearranging the visual world for robotic manipulation,
A. Zeng, P. Florence, J. Tompson, S. Welker, J. Chien, M. Attarian et al., “Transporter networks: Rearranging the visual world for robotic manipulation,” inConference on Robot Learning (CoRL), 2020
2020
-
[12]
B. Chen, Z. Xu, S. Kirmani, B. Ichter, D. Driess, P. Florence, D. Sadigh, L. Guibas, and F. Xia, “SpatialVLM: Endowing vision- language models with spatial reasoning capabilities,”arXiv preprint arXiv:2401.12168, 2024
-
[13]
Contact- GraspNet: Efficient 6-dof grasp generation in cluttered scenes,
M. Sundermeyer, A. Mousavian, R. Triebel, and D. Fox, “Contact- GraspNet: Efficient 6-dof grasp generation in cluttered scenes,” in IEEE International Conference on Robotics and Automation (ICRA), 2021
2021
-
[14]
Inner monologue: Embodied reasoning through planning with language models,
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng et al., “Inner monologue: Embodied reasoning through planning with language models,” inConference on Robot Learning (CoRL), 2022
2022
-
[15]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” in Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[16]
arXiv preprint arXiv:2503.01616 , year=
H. Liuet al., “RoboDexVLM: Visual language model-enabled task planning and motion control for dexterous robot manipulation,”arXiv preprint arXiv:2503.01616, 2025
-
[17]
GPT-4V(ision) for robotics: Multimodal task planning from human demonstration,
N. Wake, A. Kanehira, K. Sasabuchi, J. Takamatsu, and K. Ikeuchi, “GPT-4V(ision) for robotics: Multimodal task planning from human demonstration,”IEEE Robotics and Automation Letters (RA-L), 2024
2024
-
[18]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyalet al., “Retrieval-augmented generation for knowledge-intensive NLP tasks,” inAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[19]
REFLECT: Summarizing robot experiences for failure explanation and correction,
Z. Liu, A. Bahety, and S. Song, “REFLECT: Summarizing robot experiences for failure explanation and correction,” inConference on Robot Learning (CoRL), 2023
2023
-
[20]
DexVIP: Learning dexterous grasp- ing with human hand pose priors from video,
P. Mandikal and K. Grauman, “DexVIP: Learning dexterous grasp- ing with human hand pose priors from video,”arXiv preprint arXiv:2202.00164, 2022
-
[21]
Where2Act: From pixels to actions for articulated 3d objects,
K. Mo, L. J. Guibas, M. Mukadam, A. Gupta, and S. Mittal, “Where2Act: From pixels to actions for articulated 3d objects,” in IEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[22]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” in International Conference on Learning Representations (ICLR), 2023
2023
-
[23]
S. Bai, J. Bai, A. Yang, P. Wang, J. Lin, and C. Zhou, “Qwen3-VL technical report,”arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
QLoRA: Efficient finetuning of quantized language models,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “QLoRA: Efficient finetuning of quantized language models,” inAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.