ArogyaSutra: A Multi-Agent Framework for Multimodal Medical Reasoning in Indic Languages
Pith reviewed 2026-06-27 06:54 UTC · model grok-4.3
The pith
An actor-critic multi-agent framework paired with a new Indic-language medical dataset raises reasoning accuracy on multimodal queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
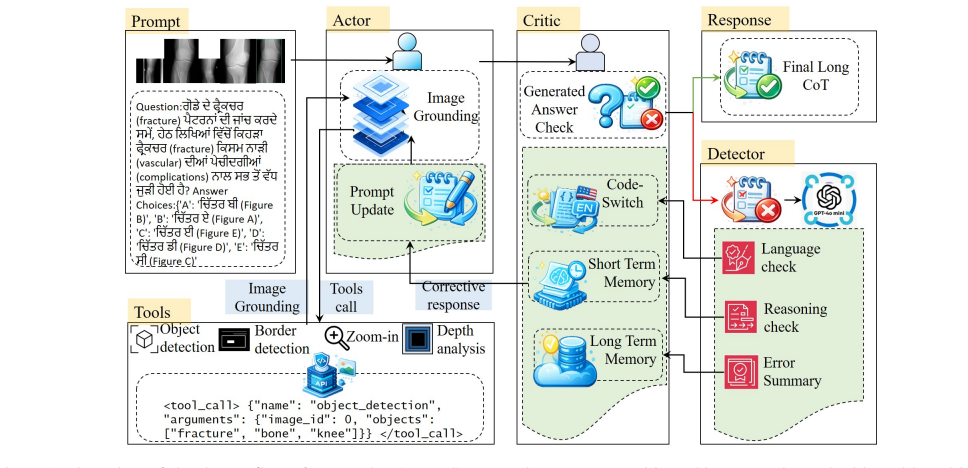
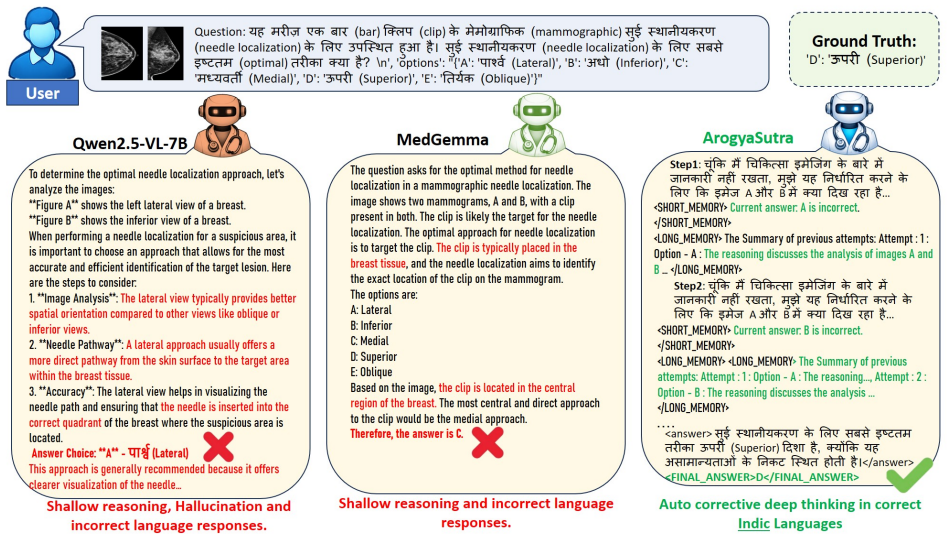
ArogyaBodha is a large-scale multilingual multimodal medical question-answer dataset constructed from eight heterogeneous sources, covering 31 body systems, six imaging modalities, and 21 clinical domains across English and seven major Indian languages. ArogyaSutra is an actor-critic-based multi-agent framework that integrates tool grounding with dual-memory mechanisms for step-wise, reasoning-aware decision making and uses stored actor-critic simulation trajectories for distillation. Experiments show that the dataset and framework together improve multilingual medical reasoning accuracy across all Indic languages, with ablations validating the contribution of each component.
What carries the argument
ArogyaSutra, the actor-critic multi-agent framework that performs tool-grounded, memory-augmented step-wise reasoning and distills trajectories from its own simulations.
If this is right
- Accuracy on medical reasoning tasks rises for every one of the seven Indic languages tested.
- Removing any single component of the actor-critic setup or the dataset produces a measurable drop in performance.
- The framework handles multimodal inputs such as medical images alongside text queries.
- Distillation from stored simulation trajectories transfers the step-wise reasoning behavior into the final model.
Where Pith is reading between the lines
- The same actor-critic plus distillation pattern could be applied to other specialized low-resource language tasks outside medicine.
- Deployment in actual clinics would require separate checks on how the system handles noisy or incomplete real-world queries.
- The approach offers one route for adapting general-purpose multimodal models to new languages without full retraining from scratch.
Load-bearing premise
The measured accuracy gains come from the actor-critic multi-agent design and dataset structure rather than from hidden implementation choices or non-representative source material.
What would settle it
Re-running the full evaluation pipeline on an independently collected set of real Indic-language patient queries with images and finding no accuracy improvement over baseline MLLMs.
Figures
read the original abstract
Multimodal Large Language Models (MLLMs) have shown promising reasoning capabilities in general domains, yet their performance remains limited in specialized settings such as healthcare, especially in multilingual and low-resource scenarios. This gap is critical in regions like rural India, where patients often express complex medical queries in native Indic languages and rely on multimodal inputs such as medical images. Existing English-centric MLLMs struggle to support such use cases, limiting equitable access to AI-driven healthcare assistance. To address this challenge, we introduce ArogyaBodha, a large-scale multilingual multimodal medical question-answer dataset constructed from eight heterogeneous sources, covering 31 body systems, six imaging modalities, and 21 clinical domains across English and seven major Indian languages. We further propose ArogyaSutra, an actor-critic-based multi-agent framework that integrates tool grounding with dual-memory mechanisms for step-wise, reasoning-aware decision making, and uses stored actor-critic simulation trajectories for distillation. Experiments show that our dataset and framework improve multilingual medical reasoning accuracy across all Indic languages, with ablations validating the contribution of each component. The source code and dataset are available at: https://iitp-cse.github.io/ ArogyaSutra/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ArogyaBodha, a large-scale multilingual multimodal medical QA dataset built from eight heterogeneous sources spanning 31 body systems, six modalities, and seven Indic languages plus English, and proposes ArogyaSutra, an actor-critic multi-agent framework that combines tool grounding, dual-memory mechanisms, and distillation from simulation trajectories. It claims that the dataset and framework together improve medical reasoning accuracy across Indic languages, with ablations confirming the value of each component.
Significance. If the experimental isolation of the multi-agent contributions holds, the work would supply both a needed resource for low-resource medical reasoning and evidence for actor-critic designs in specialized multimodal settings; the public release of code and dataset is a clear positive.
major comments (3)
- [§5 (Experiments)] §5 (Experiments): The central claim that accuracy gains are attributable to the actor-critic multi-agent structure, tool grounding, and dual-memory (rather than properties of the new ArogyaBodha dataset) requires explicit single-agent MLLM baselines fine-tuned on the identical training split; without these controls the attribution remains unverified.
- [§3 (Dataset)] §3 (Dataset): The construction from eight heterogeneous sources does not specify whether test queries are drawn from held-out real patient data or from the same sources, nor does it report controls for translation artifacts or domain overlap; this directly affects whether observed gains can be credited to the framework.
- [§5 (Experiments)] §5 (Experiments) and abstract: No numerical metrics, baseline scores, statistical tests, or error analysis are referenced, so the assertion that “ablations validate the contribution of each component” cannot be assessed for magnitude or robustness.
minor comments (1)
- [Abstract] The dataset link in the abstract is truncated ('https://iitp-cse.github.io/ ArogyaSutra/').
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental controls, dataset transparency, and the need for quantitative rigor. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [§5 (Experiments)] The central claim that accuracy gains are attributable to the actor-critic multi-agent structure, tool grounding, and dual-memory (rather than properties of the new ArogyaBodha dataset) requires explicit single-agent MLLM baselines fine-tuned on the identical training split; without these controls the attribution remains unverified.
Authors: We agree that the current experimental design does not fully isolate the multi-agent contributions. The manuscript compares ArogyaSutra primarily against base MLLMs without fine-tuning on ArogyaBodha, which leaves open the possibility that gains stem from the dataset rather than the framework. In the revised manuscript we will add single-agent MLLM baselines that are fine-tuned on the identical ArogyaBodha training split. These controls will allow direct attribution of improvements to the actor-critic structure, tool grounding, and dual-memory components. revision: yes
-
Referee: [§3 (Dataset)] The construction from eight heterogeneous sources does not specify whether test queries are drawn from held-out real patient data or from the same sources, nor does it report controls for translation artifacts or domain overlap; this directly affects whether observed gains can be credited to the framework.
Authors: We will revise §3 to explicitly describe the train/test split construction. The test queries are drawn from held-out portions of the source distributions with no patient-case overlap where identifiable. We will also add details on translation artifact controls (expert review and back-translation verification) and domain-overlap mitigation steps. These clarifications will strengthen the claim that performance gains can be credited to the ArogyaSutra framework. revision: yes
-
Referee: [§5 (Experiments)] and abstract: No numerical metrics, baseline scores, statistical tests, or error analysis are referenced, so the assertion that “ablations validate the contribution of each component” cannot be assessed for magnitude or robustness.
Authors: We acknowledge that the current manuscript version does not include explicit numerical metrics, baseline scores, statistical tests, or error analysis to support the ablation claims. In the revision we will expand §5 with concrete accuracy numbers for all baselines and ablations, add statistical significance testing, and include a dedicated error analysis subsection. The abstract will be updated to reference key quantitative results. revision: yes
Circularity Check
No circularity: empirical claims rest on newly constructed dataset and framework without reducing to fitted inputs or self-citations
full rationale
The paper introduces ArogyaBodha (new dataset from eight sources) and ArogyaSutra (new actor-critic multi-agent framework with tool grounding and dual-memory), then reports experimental accuracy gains with ablations. No equations, fitted parameters, or derivation chain appear in the provided text. Claims do not reduce any prediction to its own inputs by construction, nor rely on load-bearing self-citations for uniqueness or ansatzes. The central attribution of gains to the framework is an empirical question (addressed via ablations) rather than a definitional or self-referential reduction. This is a standard self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M3retrieve: Benchmarking multimodal re- trieval for medicine
[Acharyaet al., 2025 ] Arkadeep Acharya, Akash Ghosh, Pradeepika Verma, Kitsuchart Pasupa, Sriparna Saha, and Priti Singh. M3retrieve: Benchmarking multimodal re- trieval for medicine. InProceedings of the 2025 Confer- ence on Empirical Methods in Natural Language Process- ing, pages 15274–15287,
2025
-
[2]
InternVL: Scal- ing up vision foundation models and aligning for generic visual-linguistic tasks
[Chenet al., 2024 ] Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qing- long Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. InternVL: Scal- ing up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Patt...
2024
-
[3]
Dorfner, Amin Dada, Felix Busch, Marcus R
[Dorfneret al., 2024 ] Felix J. Dorfner, Amin Dada, Felix Busch, Marcus R. Makowski, Tianyu Han, Daniel Truhn, Jens Kleesiek, Madhumita Sushil, Jacqueline Lammert, Lisa C. Adams, and Keno K. Bressem. Biomedical large languages models seem not to be superior to generalist models on unseen medical data.CoRR, abs/2408.13833,
arXiv 2024
-
[4]
Carepilot: A multi-agent framework for long-horizon computer task automation in healthcare
[Ghoshet al., 2026 ] Akash Ghosh, Tajamul Ashraf, Rishu Kumar Singh, Numan Saeed, Sriparna Saha, Xiuy- ing Chen, and Salman Khan. Carepilot: A multi-agent framework for long-horizon computer task automation in healthcare. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9695–9705,
2026
-
[5]
DeepSeek-R1 incen- tivizes reasoning in LLMs through reinforcement learning
[Guoet al., 2025 ] Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. DeepSeek-R1 incen- tivizes reasoning in LLMs through reinforcement learning. Nature, 645(8081):633–638,
2025
-
[6]
Medical multimodal large language models: A systematic review.Intell
[Huet al., 2025 ] Yuan Hu, Chenhan Xu, Bo Lin, Weibin Yang, and Yuan Yan Tang. Medical multimodal large language models: A systematic review.Intell. Oncol., 1(4):308–325, October
2025
-
[7]
Directional reasoning injection for fine-tuning MLLMs,
[Huanget al., 2025 ] Chao Huang, Zeliang Zhang, Jiang Liu, Ximeng Sun, Jialian Wu, Xiaodong Yu, Ze Wang, Chen- liang Xu, Emad Barsoum, and Zicheng Liu. Directional reasoning injection for fine-tuning MLLMs,
2025
-
[8]
MedVLThinker: Sim- ple baselines for multimodal medical reasoning
[Huanget al., 2026 ] Xiaoke Huang, Juncheng Wu, Hui Liu, Xianfeng Tang, and Yuyin Zhou. MedVLThinker: Sim- ple baselines for multimodal medical reasoning. InPro- ceedings of the Fifth Machine Learning for Health Sym- posium, volume 297 ofProceedings of Machine Learning Research, pages 384–398. PMLR, 13–14 Dec
2026
-
[9]
Med-MoE: Mixture of domain-specific experts for lightweight medical vision- language models
[Jianget al., 2024b ] Songtao Jiang, Tuo Zheng, Yan Zhang, Yeying Jin, Li Yuan, and Zuozhu Liu. Med-MoE: Mixture of domain-specific experts for lightweight medical vision- language models. InFindings of the Association for Com- putational Linguistics: EMNLP 2024, pages 3843–3860, Miami, Florida, USA, November
2024
-
[10]
[Jianget al., 2025 ] Yixing Jiang, Kameron C Black, Glo- ria Geng, Danny Park, James Zou, Andrew Y Ng, and Jonathan H Chen
Association for Computational Linguistics. [Jianget al., 2025 ] Yixing Jiang, Kameron C Black, Glo- ria Geng, Danny Park, James Zou, Andrew Y Ng, and Jonathan H Chen. Medagentbench: a virtual ehr en- vironment to benchmark medical llm agents.Nejm Ai, 2(9):AIdbp2500144,
2025
-
[11]
BioMistral: A collection of open-source pretrained large language models for medical domains
[Labraket al., 2024 ] Yanis Labrak, Adrien Bazoge, Em- manuel Morin, Pierre-Antoine Gourraud, Mickael Rou- vier, and Richard Dufour. BioMistral: A collection of open-source pretrained large language models for medical domains. InFindings of the Association for Computational Linguistics: ACL 2024, pages 5848–5864, Bangkok, Thai- land, August
2024
-
[12]
[Laiet al., 2025 ] Yuxiang Lai, Jike Zhong, Ming Li, Shi- tian Zhao, Yuheng Li, Konstantinos Psounis, and Xiaofeng Yang
Association for Computational Lin- guistics. [Laiet al., 2025 ] Yuxiang Lai, Jike Zhong, Ming Li, Shi- tian Zhao, Yuheng Li, Konstantinos Psounis, and Xiaofeng Yang. Med-R1: Reinforcement learning for generalizable medical reasoning in vision-language models.IEEE Jour- nals & Magazine,
2025
-
[13]
Llava- med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564,
[Liet al., 2023 ] Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava- med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564,
2023
-
[14]
MMedAgent: Learning to use medical tools with multi-modal agent
[Liet al., 2024 ] Binxu Li, Tiankai Yan, Yuanting Pan, Jie Luo, Ruiyang Ji, Jiayuan Ding, Zhe Xu, Shilong Liu, Haoyu Dong, Zihao Lin, and Yixin Wang. MMedAgent: Learning to use medical tools with multi-modal agent. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 8745–8760, Stroudsburg, PA, USA,
2024
-
[15]
Association for Computational Linguistics. [Liet al., 2025 ] Feiyang Li, Yingjian Chen, Haoran Liu, Rui Yang, Han Yuan, Yuang Jiang, Tianxiao Li, Edison Mar- rese Taylor, Hossein Rouhizadeh, Yusuke Iwasawa, Dou- glas Teodoro, Yutaka Matsuo, and Irene Li. MKG-Rank: Enhancing large language models with knowledge graph for multilingual medical question answering,
2025
-
[16]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916,
[Liuet al., 2023 ] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916,
2023
-
[17]
Drishtikon: A multi- modal multilingual benchmark for testing language mod- els’ understanding on indian culture
[Majiet al., 2025 ] Arijit Maji, Raghvendra Kumar, Akash Ghosh, Nemil Shah, Abhilekh Borah, Vanshika Shah, Nis- hant Mishra, Sriparna Saha, et al. Drishtikon: A multi- modal multilingual benchmark for testing language mod- els’ understanding on indian culture. InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, page...
2025
-
[18]
The future of MLLM prompting is adaptive: A comprehensive ex- perimental evaluation of prompt engineering methods for robust multimodal performance,
[Mohantyet al., 2025 ] Anwesha Mohanty, Venkatesh Bal- avadhani Parthasarathy, and Arsalan Shahid. The future of MLLM prompting is adaptive: A comprehensive ex- perimental evaluation of prompt engineering methods for robust multimodal performance,
2025
-
[19]
Scaling neural machine translation to 200 languages.Nature, 630(8018):841–846,
[NLLB Team, 2024] NLLB Team. Scaling neural machine translation to 200 languages.Nature, 630(8018):841–846,
2024
-
[20]
Cure-med: Curriculum-informed reinforcement learning for multilingual medical reasoning,
[Onyameet al., 2026 ] Eric Onyame, Akash Ghosh, Sub- hadip Baidya, Sriparna Saha, Xiuying Chen, and Chirag Agarwal. Cure-med: Curriculum-informed reinforcement learning for multilingual medical reasoning,
2026
-
[21]
MedVLM-R1: Incentiviz- ing medical reasoning capability of vision-language mod- els (VLMs) via reinforcement learning
[Panet al., 2025 ] Jiazhen Pan, Che Liu, Junde Wu, Fenglin Liu, Jiayuan Zhu, Hongwei Bran Li, Chen Chen, Cheng Ouyang, and Daniel Rueckert. MedVLM-R1: Incentiviz- ing medical reasoning capability of vision-language mod- els (VLMs) via reinforcement learning. InMedical Image Computing and Computer-Assisted Intervention – MIC- CAI
2025
-
[22]
A survey of multilingual large language models.Patterns, 6(1),
[Qinet al., 2025 ] Libo Qin, Qiguang Chen, Yuhang Zhou, Zhi Chen, Yinghui Li, Lizi Liao, Min Li, Wanxiang Che, and Philip S Yu. A survey of multilingual large language models.Patterns, 6(1),
2025
-
[23]
Towards building multilingual language model for medicine.Nat
[Qiuet al., 2024 ] Pengcheng Qiu, Chaoyi Wu, Xiaoman Zhang, Weixiong Lin, Haicheng Wang, Ya Zhang, Yan- feng Wang, and Weidi Xie. Towards building multilingual language model for medicine.Nat. Commun., 15(1):8384, September
2024
-
[24]
A multilingual multimodal medical examina- tion dataset for visual question answering in healthcare
[Riccioet al., 2025 ] Giuseppe Riccio, Antonio Romano, Mariano Barone, Gian Marco Orlando, Diego Russo, Marco Postiglione, Valerio La Gatta, and Vincenzo Moscato. A multilingual multimodal medical examina- tion dataset for visual question answering in healthcare. In 2025 IEEE 38th International Symposium on Computer- Based Medical Systems (CBMS), pages 435–440,
2025
-
[25]
AgentClinic: A multimodal agent benchmark to evaluate AI in simulated clinical environments,
[Schmidgallet al., 2024 ] Samuel Schmidgall, Rojin Ziaei, Carl Harris, Eduardo Reis, Jeffrey Jopling, and Michael Moor. AgentClinic: A multimodal agent benchmark to evaluate AI in simulated clinical environments,
2024
-
[26]
MedGemma technical report,
[Sellergrenet al., 2025 ] Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, C´ıan Hughes, Charles Lau, et al. MedGemma technical report,
2025
-
[27]
Chiron-o1: Igniting multimodal large language models towards generalizable medical rea- soning via mentor-intern collaborative search
[Sunet al., 2025 ] Haoran Sun, Yankai Jiang, Wenjie Lou, Yujie Zhang, Wenjie Li, Lilong Wang, Mianxin Liu, Lei Liu, and Xiaosong Wang. Chiron-o1: Igniting multimodal large language models towards generalizable medical rea- soning via mentor-intern collaborative search. InAdvances in Neural Information Processing Systems,
2025
-
[28]
Vi- raasat: Traversing novel paths for indian cultural reason- ing,
[Suranaet al., 2026 ] Harshul Raj Surana, Arijit Maji, Aryan Vats, Akash Ghosh, Sriparna Saha, and Amit Sheth. Vi- raasat: Traversing novel paths for indian cultural reason- ing,
2026
-
[29]
Medagents: Large language models as collaborators for zero-shot medical reasoning
[Tanget al., 2024 ] Xiangru Tang, Anni Zou, Zhuosheng Zhang, Ziming Li, Yilun Zhao, Xingyao Zhang, Arman Cohan, and Mark Gerstein. Medagents: Large language models as collaborators for zero-shot medical reasoning. InFindings of the Association for Computational Linguis- tics: ACL 2024, pages 599–621,
2024
-
[30]
Qwen2-vl: Enhanc- ing vision-language model’s perception of the world at any resolution,
[Wanget al., 2024 ] Peng Wang, Shuai Bai, Sinan Tan, Shi- jie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhanc- ing vision-language model’s perception of the world at any resolution,
2024
-
[31]
MMedAgent-RL: Opti- mizing multi-agent collaboration for multimodal medical reasoning
[Xiaet al., 2026 ] Peng Xia, Jinglu Wang, Yibo Peng, Kaide Zeng, Xian Wu, Xiangru Tang, Hongtu Zhu, Yun Li, Shu- jie Liu, Yan Lu, and Huaxiu Yao. MMedAgent-RL: Opti- mizing multi-agent collaboration for multimodal medical reasoning. InInternational Conference on Learning Rep- resentations,
2026
-
[32]
Mul- timodal large language models for medical image diag- nosis: Challenges and opportunities.J
[Zhanget al., 2025 ] Andrew Zhang, Eric Zhao, Ruirui Wang, Xiuqi Zhang, Justin Wang, and Ethan Chen. Mul- timodal large language models for medical image diag- nosis: Challenges and opportunities.J. Biomed. Inform., 169(104895):104895, September
2025
-
[33]
Reinforced visual per- ception with tools, 2025
[Zhouet al., 2025b ] Zetong Zhou, Dongping Chen, Zixian Ma, Zhihan Hu, Mingyang Fu, Sinan Wang, Yao Wan, Zhou Zhao, and Ranjay Krishna. Reinforced visual per- ception with tools, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.