Micro-Swarm Locomotion Optimization in Dynamic Flow using Multi-Objective Multi-Agent Reinforcement Learning
Pith reviewed 2026-06-30 00:27 UTC · model grok-4.3
The pith
A hybrid CFD and multi-objective multi-agent RL framework lets sixteen micro-robots navigate pulsatile arterial flow while balancing upstream progress, energy efficiency, and motion smoothness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
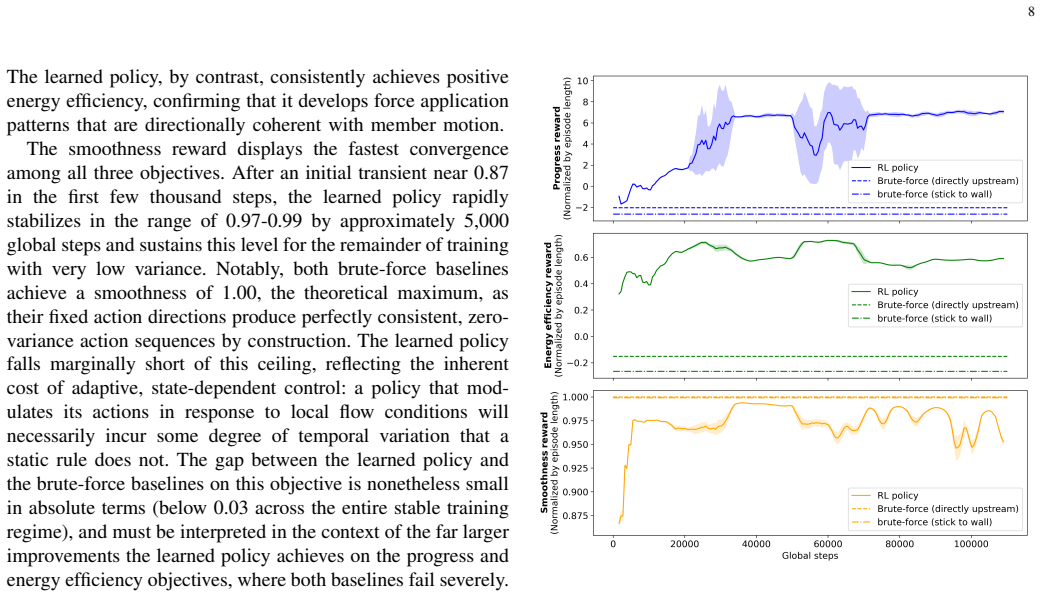
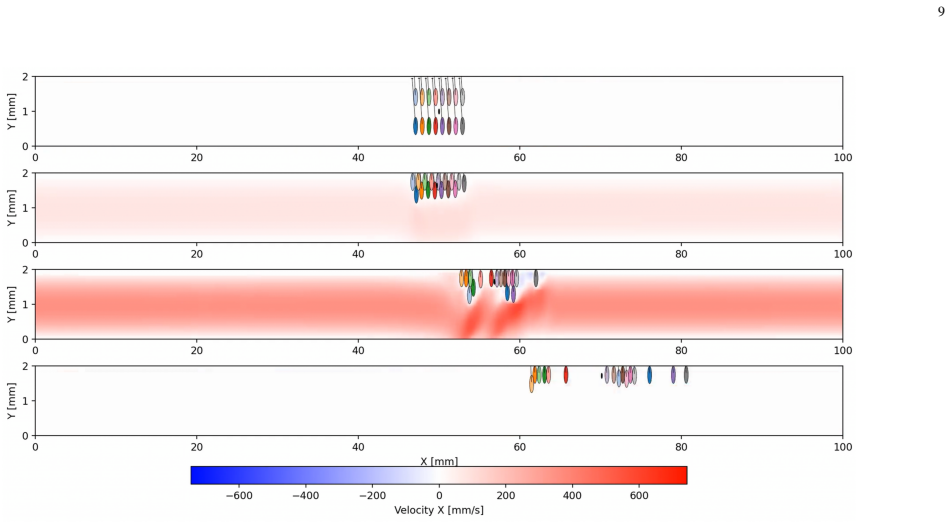
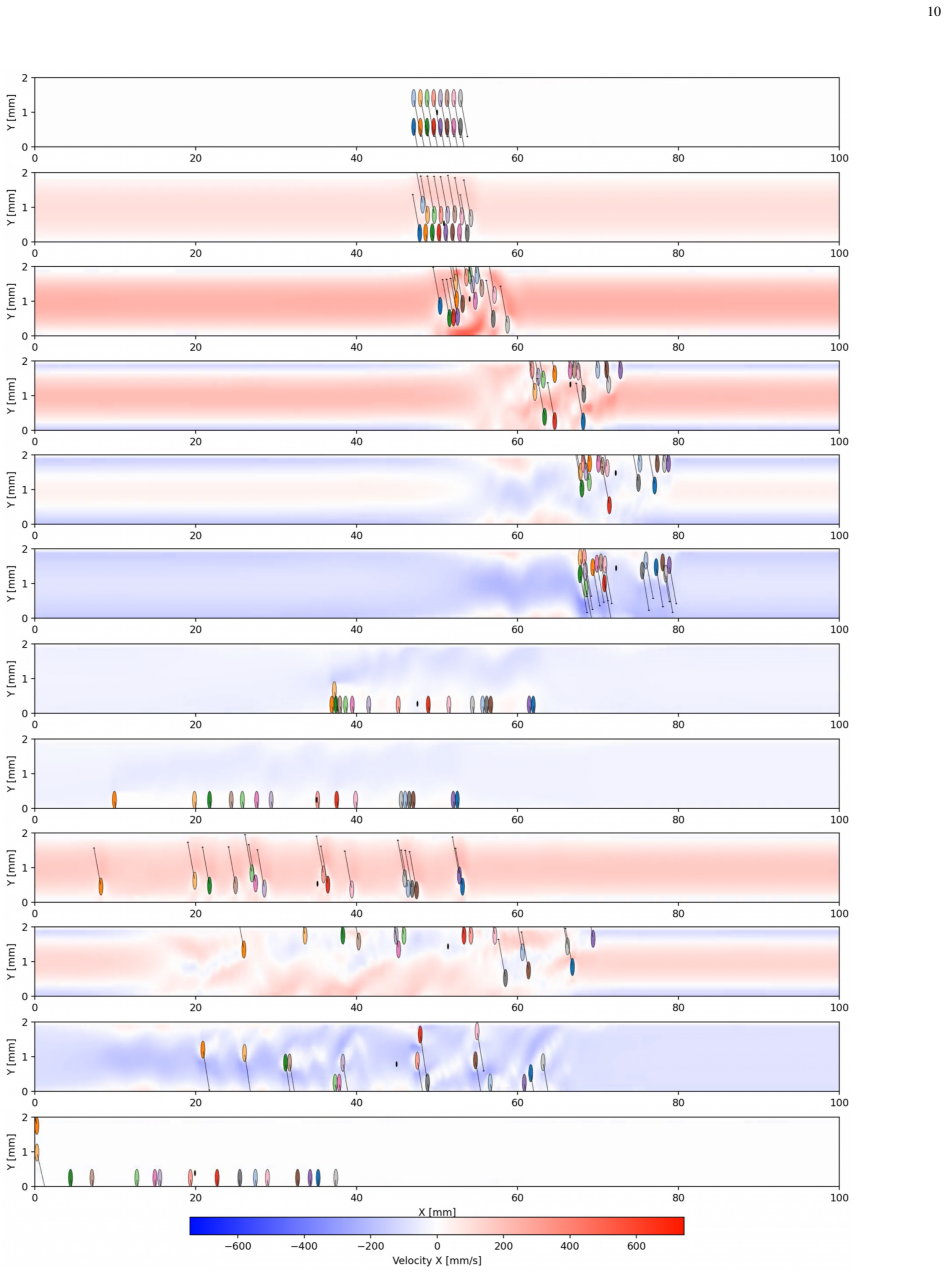
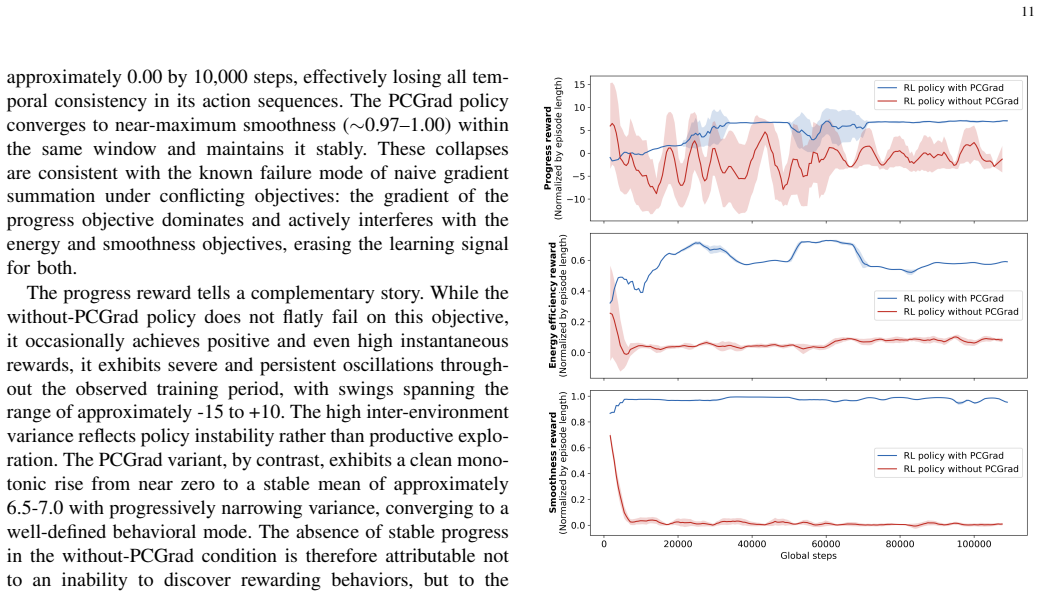
Time-dependent fluid-agent interactions can be captured directly within multi-objective reinforcement learning loops; the converged decentralized PPO policy with PCGrad achieves a progress reward of 6.5–7.0, energy efficiency of 0.63–0.65, and smoothness of 0.97–0.99 while navigating a pulsatile arterial waveform, and produces three emergent phases (two-layer throttling formation, cycle-synchronized ratchet, individualized terminal approach) that brute-force baselines cannot match.
What carries the argument
Hybrid CFD-MOMARL loop that couples an incompressible Navier-Stokes solver to decentralized PPO agents whose gradients are reconciled by PCGrad to resolve conflicts among progress, energy, and smoothness rewards.
If this is right
- Collective two-layer hydrodynamic throttling suppresses peak channel velocities during forward flow.
- Cycle-synchronized ratchet exploits flow reversals for upstream repositioning without extra energy cost.
- Individualized final approach emerges once agents near the success boundary.
- Brute-force baselines produce negative energy efficiency while the learned policy remains positive.
- Absence of PCGrad causes energy and smoothness rewards to collapse within 10,000 steps.
Where Pith is reading between the lines
- The same loop could be tested on other time-periodic flows such as respiratory or microfluidic channels to check whether the three-phase emergence is general.
- If the simulated policies transfer to hardware, the approach could reduce reliance on manual trajectory design for in-vivo micro-robot navigation.
- The necessity of PCGrad suggests that multi-objective fluid problems systematically produce gradient conflicts that single-objective RL cannot resolve.
Load-bearing premise
The incompressible Navier-Stokes solver accurately represents the physiologically realistic time-dependent fluid environments and the learned policies remain physically consistent without additional real-world validation.
What would settle it
Deploy the trained policy on physical magnetically actuated micro-robots inside a pulsatile-flow channel that matches the simulated waveform and measure whether the observed energy efficiency and smoothness match the simulated values of 0.63–0.65 and 0.97–0.99.
Figures
read the original abstract
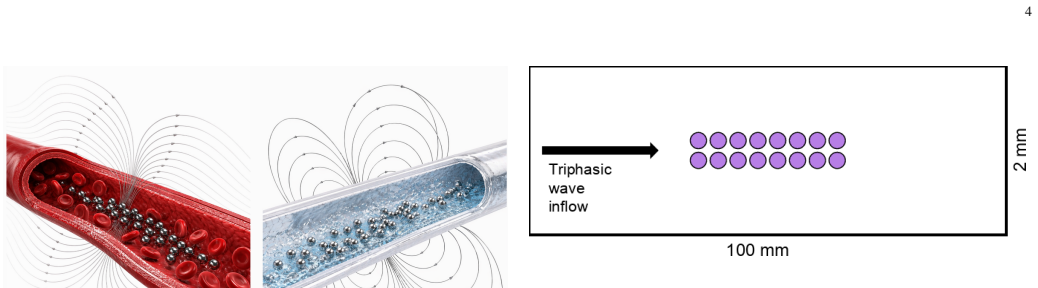
Coordinating micro-robotic swarms in physiologically realistic, time-dependent fluid environments remains an unsolved challenge for biomedical and environmental applications. We present a hybrid Computational Fluid Dynamics - Multi-Objective Multi-Agent Reinforcement Learning framework that directly couples a high-fidelity incompressible Navier-Stokes solver with decentralized proximal policy optimization to learn physically consistent swarm control strategies in oscillatory flow. Sixteen magnetically actuated micro-robots navigate a pulsatile arterial waveform, simultaneously optimizing upstream progression, energy conservation, and motion smoothness, reconciled using PCGrad surgery. Without PCGrad, energy efficiency and smoothness rewards collapse to near zero within 10,000 training steps while progress exhibits persistent large-amplitude oscillations, confirming that gradient conflict resolution is a structural requirement rather than an optional refinement in this domain. The converged policy achieves a progress reward of 6.5-7.0, a sustained energy efficiency of 0.63-0.65, and near-maximum smoothness (0.97-0.99), representing improvements over brute-force baselines on the primary objective while both baselines yield negative energy efficiency throughout. Training reveals three emergent behavioral phases: a collective two-layer hydrodynamic throttling formation that suppresses peak channel velocities during forward flow, a cycle-synchronized ratchet mechanism that exploits flow reversals for upstream repositioning, and an individualized final approach as agents near the success boundary. These results establish that time-dependent fluid-agent interactions can be captured directly within multi-objective reinforcement learning loops, offering a physically grounded paradigm for micro-swarm control in biomedical navigation, environmental monitoring, and industrial microfluidics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a hybrid CFD-MARL framework coupling a high-fidelity incompressible Navier-Stokes solver with decentralized PPO and PCGrad gradient surgery to optimize upstream progression, energy efficiency, and smoothness for 16 magnetically actuated micro-robots in a pulsatile arterial waveform. It reports that the converged policy attains progress rewards of 6.5-7.0, energy efficiency of 0.63-0.65, and smoothness of 0.97-0.99, outperforming brute-force baselines on the primary objective (while baselines yield negative energy efficiency), demonstrates that PCGrad is required to prevent reward collapse, and identifies three emergent phases: two-layer hydrodynamic throttling, cycle-synchronized ratchet repositioning, and individualized final approach.
Significance. If the simulation results are robust, the work demonstrates that multi-objective MARL can directly incorporate time-dependent fluid-agent interactions to produce coordinated swarm behaviors, with the explicit demonstration that PCGrad is structurally necessary (rather than optional) constituting a useful methodological contribution for conflicting-objective domains. The provision of concrete reward ranges and training-step dynamics strengthens reproducibility within simulation studies.
major comments (2)
- [Abstract] Abstract: The central claim that the learned policies are 'physically consistent' and that the framework offers a 'physically grounded paradigm' for biomedical navigation rests on the untested premise that the chosen incompressible NS solver with rigid-domain pulsatile waveform faithfully reproduces dominant forces; no sensitivity analysis to compliant-wall FSI, non-Newtonian rheology, or laboratory PIV data is supplied, rendering the reported reward values and emergent formations (two-layer throttling, ratchet) potentially solver-specific artifacts.
- [Abstract] Abstract (training results paragraph): The necessity of PCGrad is shown only via collapse within this single fluid model after 10,000 steps; without ablations across varied waveforms, Reynolds numbers, or alternative solvers, it remains unclear whether gradient conflict resolution is a general structural requirement or an artifact of the specific environment and reward scaling.
minor comments (1)
- [Abstract] Abstract: The brute-force baseline implementation details (e.g., whether it optimizes the same multi-objective reward or only progress) are not stated, complicating direct comparison of the reported improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and propose targeted revisions to the abstract and discussion to better qualify the scope of our claims while preserving the core contribution of the hybrid CFD-MOMARL framework.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the learned policies are 'physically consistent' and that the framework offers a 'physically grounded paradigm' rests on the untested premise that the chosen incompressible NS solver with rigid-domain pulsatile waveform faithfully reproduces dominant forces; no sensitivity analysis to compliant-wall FSI, non-Newtonian rheology, or laboratory PIV data is supplied, rendering the reported reward values and emergent formations (two-layer throttling, ratchet) potentially solver-specific artifacts.
Authors: We agree that the phrasing 'physically consistent' and 'physically grounded paradigm' can be read as implying broader physical fidelity than the chosen model supports. In the manuscript these terms denote direct coupling to the incompressible Navier-Stokes equations (as opposed to reduced-order or surrogate dynamics) within a standard rigid-wall Newtonian setup. We will revise the abstract to replace these phrases with 'consistent with the incompressible NS model' and 'simulation-based paradigm,' and we will add a limitations subsection explicitly noting the rigid-wall and Newtonian assumptions together with the absence of FSI, non-Newtonian, or PIV validation. This revision clarifies the intended scope without altering the reported results. revision: yes
-
Referee: [Abstract] Abstract (training results paragraph): The necessity of PCGrad is shown only via collapse within this single fluid model after 10,000 steps; without ablations across varied waveforms, Reynolds numbers, or alternative solvers, it remains unclear whether gradient conflict resolution is a general structural requirement or an artifact of the specific environment and reward scaling.
Authors: The PCGrad ablation demonstrates that, in the presence of the three conflicting objectives and the time-varying fluid forces of this environment, gradient surgery is required to avoid reward collapse. The manuscript does not claim universality across all MARL settings; the statement 'structural requirement rather than an optional refinement in this domain' is intended to be environment-specific. We will revise the abstract and the corresponding methods paragraph to read 'required to prevent collapse in this multi-objective fluid-interaction setting' and will add a short discussion paragraph acknowledging that broader ablations across waveforms and solvers would be valuable future work. revision: partial
Circularity Check
No circularity detected; results are empirical outputs from RL training
full rationale
The paper reports performance metrics and emergent behaviors obtained by running decentralized PPO with PCGrad inside an external incompressible Navier-Stokes solver, then comparing against separate brute-force baselines. No mathematical derivation chain exists that reduces a claimed prediction or first-principles result to its own inputs by construction. Claims about PCGrad being required are supported by direct training observations (collapse without it), not by self-definition, fitted parameters renamed as predictions, or load-bearing self-citations. The framework is self-contained as simulation-based optimization with external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Incompressible Navier-Stokes equations govern the fluid flow
- domain assumption Decentralized proximal policy optimization can learn swarm control strategies
Reference graph
Works this paper leans on
-
[1]
E. M. Purcell, “Life at low reynolds number,”American Journal of Physics, vol. 45, no. 1, pp. 3–11, 01 1977. [Online]. Available: https://doi.org/10.1119/1.10903
-
[2]
Self-induced oscillations in an open water-channel with slotted walls,
P. L. Betts, “Self-induced oscillations in an open water-channel with slotted walls,”Journal of Fluid Mechanics, vol. 55, no. 3, p. 401–417, 1972
1972
-
[3]
Numerical simulation of blood flow in venous networks,
M. Cermatori, “Numerical simulation of blood flow in venous networks,” Ph.D. dissertation, Imperial College London, 04 2014
2014
-
[4]
Versatile microrobotics using simple modular subunits,
U. K. Cheang, F. Meshkati, H. Kim, K. Lee, H. C. Fu, and M. J. Kim, “Versatile microrobotics using simple modular subunits,” Scientific Reports, vol. 6, no. 1, p. 30472, 2016. [Online]. Available: https://doi.org/10.1038/srep30472
-
[5]
The Self-Propulsion of Microscopic Organisms through Liquids,
G. J. Hancock, “The Self-Propulsion of Microscopic Organisms through Liquids,”Proceedings of the Royal Society of London Series A, vol. 217, no. 1128, pp. 96–121, Mar. 1953
1953
-
[6]
Bio-inspired magnetic swimming microrobots for biomedical applications,
K. E. Peyer, L. Zhang, and B. J. Nelson, “Bio-inspired magnetic swimming microrobots for biomedical applications,”Nanoscale, vol. 5, pp. 1259–1272, 2013. [Online]. Available: http://dx.doi.org/10.1039/ C2NR32554C
2013
-
[7]
Recent process in microrobots: From propulsion to swarming for biomedical applications,
R. Wu, Y . Zhu, X. Cai, S. Wu, L. Xu, and T. Yu, “Recent process in microrobots: From propulsion to swarming for biomedical applications,”Micromachines, vol. 13, no. 9, 2022. [Online]. Available: https://www.mdpi.com/2072-666X/13/9/1473
2022
-
[8]
Propulsion mecha- nisms and applications of multiphysics- driven micro- and nanomotors,
X. Chang, T. Li, D. Zhou, G. Zhang, and L. LI, “Propulsion mecha- nisms and applications of multiphysics- driven micro- and nanomotors,” Chinese Science Bulletin, vol. 62, pp. 122–135, 01 2017
2017
-
[9]
Self-learning how to swim at low reynolds number,
A. C. H. Tsang, P. W. Tong, S. Nallan, and O. S. Pak, “Self-learning how to swim at low reynolds number,”Phys. Rev. Fluids, vol. 5, p. 074101, Jul 2020. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevFluids.5.074101
-
[10]
Finite element model of a helical swimming robot in comsol,
M. A. L ´opez, C. Nuevo-Gallardo, J. E. Traver, I. Tejado, and B. M. Vinagre, “Finite element model of a helical swimming robot in comsol,” inCOMSOL Conference 2024, 2024
2024
-
[11]
A survey on swarm microrobotics,
L. Yang, J. Yu, S. Yang, B. Wang, B. J. Nelson, and L. Zhang, “A survey on swarm microrobotics,”IEEE Transactions on Robotics, vol. 38, no. 3, pp. 1531–1551, 2022
2022
-
[12]
Magnetic microrobotic swarms in fluid suspensions,
H. Chen and J. Yu, “Magnetic microrobotic swarms in fluid suspensions,”Current Robotics Reports, vol. 3, no. 3, pp. 127–137,
-
[13]
Available: https://doi.org/10.1007/s43154-022-00085-6
[Online]. Available: https://doi.org/10.1007/s43154-022-00085-6
-
[14]
Navigation of magnetic microrobotic swarms with maintained structural integrity in fluidic flow,
J. Law, X. Du, W. Tang, J. Yu, and Y . Sun, “Navigation of magnetic microrobotic swarms with maintained structural integrity in fluidic flow,” IEEE/ASME Transactions on Mechatronics, vol. 29, no. 1, pp. 74–84, 2024
2024
-
[15]
Opportunities and challenges with autonomous micro aerial vehicles,
V . Kumar and N. Michael, “Opportunities and challenges with autonomous micro aerial vehicles,”Int. J. Rob. Res., vol. 31, no. 11, p. 1279–1291, Sep. 2012. [Online]. Available: https: //doi.org/10.1177/0278364912455954
-
[16]
Oscillatory gravity waves in flowing water,
T. Sarpkaya, “Oscillatory gravity waves in flowing water,”Transactions of the American Society of Civil Engineers, vol. 122, no. 1, pp. 564–586, 1957. [Online]. Available: https://ascelibrary.org/doi/abs/10. 1061/TACEAT.0007497
1957
-
[17]
Information theoretic mpc for model-based reinforcement learning,
G. Williams, N. Wagener, B. Goldfain, P. Drews, J. M. Rehg, B. Boots, and E. A. Theodorou, “Information theoretic mpc for model-based reinforcement learning,” in2017 IEEE International Conference on Robotics and Automation (ICRA), 2017, pp. 1714–1721
2017
-
[18]
Independent control of multiple magnetic microrobots in three dimensions,
E. Diller, J. Giltinan, and M. Sitti, “Independent control of multiple magnetic microrobots in three dimensions,”The International Journal of Robotics Research, vol. 32, no. 5, pp. 614–631, 2013
2013
-
[19]
Aircraft trajectory planning with collision avoidance using mixed integer linear programming,
A. Richards and J. P. How, “Aircraft trajectory planning with collision avoidance using mixed integer linear programming,” inProceedings of the 2002 American control conference (IEEE Cat. No. CH37301), vol. 3. IEEE, 2002, pp. 1936–1941
2002
-
[20]
Magnetic therapeutic delivery using navigable agents,
S. Martel, “Magnetic therapeutic delivery using navigable agents,” Therapeutic delivery, vol. 5, no. 2, pp. 189–204, 2014
2014
-
[21]
Mesbahi and M
M. Mesbahi and M. Egerstedt,Graph theoretic methods in multiagent networks. Princeton University Press, 2010
2010
-
[22]
Foundations of swarm robotic chemical plume tracing from a fluid dynamics perspective,
D. F. Spears, D. R. Thayer, and D. V . Zarzhitsky, “Foundations of swarm robotic chemical plume tracing from a fluid dynamics perspective,”International Journal of Intelligent Computing and Cybernetics, vol. 2, no. 4, pp. 745–785, Jan. 2009. [Online]. Available: https://doi.org/10.1108/17563780911005863
-
[23]
Disruption of vertical motility by shear triggers formation of thin phytoplankton layers,
W. M. Durham, J. O. Kessler, and R. Stocker, “Disruption of vertical motility by shear triggers formation of thin phytoplankton layers,” science, vol. 323, no. 5917, pp. 1067–1070, 2009
2009
-
[24]
Swarm robotics,
M. Dorigo, M. Birattari, and M. Brambilla, “Swarm robotics,”Scholar- pedia, vol. 9, no. 1, p. 1463, 2014
2014
-
[25]
R. S. Sutton, A. G. Bartoet al.,Reinforcement learning: An introduction. MIT press Cambridge, 1998, vol. 1, no. 1
1998
-
[26]
Pilco: A model-based and data-efficient approach to policy search,
M. Deisenroth and C. E. Rasmussen, “Pilco: A model-based and data-efficient approach to policy search,” inProceedings of the 28th International Conference on machine learning (ICML-11), 2011, pp. 465–472
2011
-
[27]
Dream to Control: Learning Behaviors by Latent Imagination
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi, “Dream to control: Learn- ing behaviors by latent imagination,”arXiv preprint arXiv:1912.01603, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[28]
Model regularization for stable sample rollouts
E. Talvitie, “Model regularization for stable sample rollouts.” inUAI, 2014, pp. 780–789
2014
-
[29]
Multi-agent reinforce- ment learning: An overview,
L. Bus ¸oniu, R. Babu ˇska, and B. De Schutter, “Multi-agent reinforce- ment learning: An overview,”Innovations in multi-agent systems and applications-1, pp. 183–221, 2010
2010
-
[30]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,” inInternational conference on machine learning. Pmlr, 2018, pp. 1861–1870
2018
-
[32]
Controlled gliding and perching through deep-reinforcement-learning,
G. Novati, L. Mahadevan, and P. Koumoutsakos, “Controlled gliding and perching through deep-reinforcement-learning,”Physical Review Fluids, vol. 4, no. 9, p. 093902, 2019
2019
-
[33]
Scaling macroscopic aquatic locomotion,
M. Gazzola, M. Argentina, and L. Mahadevan, “Scaling macroscopic aquatic locomotion,”Nature Physics, vol. 10, no. 10, pp. 758–761, 2014. 13
2014
-
[34]
A comprehensive survey of multiagent reinforcement learning,
L. Busoniu, R. Babuska, and B. De Schutter, “A comprehensive survey of multiagent reinforcement learning,”IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), vol. 38, no. 2, pp. 156–172, 2008
2008
-
[35]
Multi-agent reinforcement learning: A selective overview of theories and algorithms,
K. Zhang, Z. Yang, and T. Bas ¸ar, “Multi-agent reinforcement learning: A selective overview of theories and algorithms,”Handbook of rein- forcement learning and control, pp. 321–384, 2021
2021
-
[36]
Multi-agent actor-critic for mixed cooperative-competitive environ- ments,
R. Lowe, Y . I. Wu, A. Tamar, J. Harb, O. Pieter Abbeel, and I. Mordatch, “Multi-agent actor-critic for mixed cooperative-competitive environ- ments,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[37]
Counterfactual multi-agent policy gradients,
J. Foerster, G. Farquhar, T. Afouras, N. Nardelli, and S. Whiteson, “Counterfactual multi-agent policy gradients,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, no. 1, 2018
2018
-
[38]
Multi-agent reinforcement learning: Independent vs. cooper- ative agents,
M. Tan, “Multi-agent reinforcement learning: Independent vs. cooper- ative agents,” inProceedings of the tenth international conference on machine learning, 1993, pp. 330–337
1993
-
[39]
Optimal and approxi- mate q-value functions for decentralized pomdps,
F. A. Oliehoek, M. T. Spaan, and N. Vlassis, “Optimal and approxi- mate q-value functions for decentralized pomdps,”Journal of Artificial Intelligence Research, vol. 32, pp. 289–353, 2008
2008
-
[40]
Monotonic value function factorisation for deep multi- agent reinforcement learning,
T. Rashid, M. Samvelyan, C. S. De Witt, G. Farquhar, J. Foerster, and S. Whiteson, “Monotonic value function factorisation for deep multi- agent reinforcement learning,”Journal of Machine Learning Research, vol. 21, no. 178, pp. 1–51, 2020
2020
-
[41]
The surprising effectiveness of ppo in cooperative multi-agent games,
C. Yu, A. Velu, E. Vinitsky, J. Gao, Y . Wang, A. Bayen, and Y . Wu, “The surprising effectiveness of ppo in cooperative multi-agent games,” Advances in neural information processing systems, vol. 35, pp. 24 611– 24 624, 2022
2022
-
[42]
Learning multiagent communication with backpropagation,
S. Sukhbaatar, R. Ferguset al., “Learning multiagent communication with backpropagation,”Advances in neural information processing sys- tems, vol. 29, 2016
2016
-
[43]
Graph convolutional reinforce- ment learning,
J. Jiang, C. Dun, T. Huang, and Z. Lu, “Graph convolutional reinforce- ment learning,”arXiv preprint arXiv:1810.09202, 2018
-
[44]
A survey of multi-objective sequential decision-making,
D. M. Roijers, P. Vamplew, S. Whiteson, and R. Dazeley, “A survey of multi-objective sequential decision-making,”Journal of Artificial Intelligence Research, vol. 48, pp. 67–113, 2013
2013
-
[45]
A practical guide to multi-objective reinforcement learning and planning,
C. F. Hayes, R. R ˘adulescu, E. Bargiacchi, J. K ¨allstr¨om, M. Macfarlane, M. Reymond, T. Verstraeten, L. M. Zintgraf, R. Dazeley, F. Heintz, E. Howley, A. A. Irissappane, P. Mannion, A. Now ´e, G. Ramos, M. Restelli, P. Vamplew, and D. M. Roijers, “A practical guide to multi-objective reinforcement learning and planning,”Autonomous Agents and Multi-Agen...
-
[46]
Empirical evaluation methods for multiobjective reinforcement learning algorithms,
P. Vamplew, R. Dazeley, A. Berry, R. Issabekov, and E. Dekker, “Empirical evaluation methods for multiobjective reinforcement learning algorithms,”Machine learning, vol. 84, no. 1, pp. 51–80, 2011
2011
-
[47]
Scalarized multi- objective reinforcement learning: Novel design techniques,
K. Van Moffaert, M. M. Drugan, and A. Now ´e, “Scalarized multi- objective reinforcement learning: Novel design techniques,” in2013 IEEE symposium on adaptive dynamic programming and reinforcement learning (ADPRL). IEEE, 2013, pp. 191–199
2013
-
[48]
Prediction- guided multi-objective reinforcement learning for continuous robot con- trol,
J. Xu, Y . Tian, P. Ma, D. Rus, S. Sueda, and W. Matusik, “Prediction- guided multi-objective reinforcement learning for continuous robot con- trol,” inInternational conference on machine learning. PMLR, 2020, pp. 10 607–10 616
2020
-
[49]
Multi-task learning as multi-objective opti- mization,
O. Sener and V . Koltun, “Multi-task learning as multi-objective opti- mization,”Advances in neural information processing systems, vol. 31, 2018
2018
-
[50]
Gra- dient surgery for multi-task learning,
T. Yu, S. Kumar, A. Gupta, S. Levine, K. Hausman, and C. Finn, “Gra- dient surgery for multi-task learning,”Advances in neural information processing systems, vol. 33, pp. 5824–5836, 2020
2020
-
[51]
Scalable multi-objective robot reinforcement learning through gradient conflict resolution,
H. Munn, B. Tidd, P. B ¨ohm, M. Gallagher, and D. Howard, “Scalable multi-objective robot reinforcement learning through gradient conflict resolution,”arXiv preprint arXiv:2509.14816, 2025
-
[52]
Multi-objective multi-agent decision making: a utility-based analysis and survey,
R. R ˘adulescu, P. Mannion, D. M. Roijers, and A. Now´e, “Multi-objective multi-agent decision making: a utility-based analysis and survey,” Autonomous Agents and Multi-Agent Systems, vol. 34, no. 1, p. 10,
-
[53]
Available: https://doi.org/10.1007/s10458-019-09433-x
[Online]. Available: https://doi.org/10.1007/s10458-019-09433-x
-
[54]
Sample-efficient multi-objective learning via generalized policy improvement prioritization,
L. N. Alegre, A. L. Bazzan, D. M. Roijers, A. Now ´e, and B. C. da Silva, “Sample-efficient multi-objective learning via generalized policy improvement prioritization,”arXiv preprint arXiv:2301.07784, 2023
-
[55]
Meta-gradient reinforcement learning with an objective discovered online,
Z. Xu, H. P. van Hasselt, M. Hessel, J. Oh, S. Singh, and D. Silver, “Meta-gradient reinforcement learning with an objective discovered online,”Advances in Neural Information Processing Systems, vol. 33, pp. 15 254–15 264, 2020
2020
-
[56]
Pac: Assisted value factorization with counterfactual predictions in multi-agent reinforcement learning,
H. Zhou, T. Lan, and V . Aggarwal, “Pac: Assisted value factorization with counterfactual predictions in multi-agent reinforcement learning,” Advances in Neural Information Processing Systems, vol. 35, pp. 15 757–15 769, 2022
2022
-
[57]
Multi-objective deep reinforcement learning for mobile edge computing,
N. Yang, J. Wen, M. Zhang, and M. Tang, “Multi-objective deep reinforcement learning for mobile edge computing,” in2023 21st in- ternational symposium on modeling and optimization in mobile, ad hoc, and wireless networks (WiOpt). IEEE, 2023, pp. 1–8
2023
-
[58]
Machine learning for fluid mechanics,
S. L. Brunton, B. R. Noack, and P. Koumoutsakos, “Machine learning for fluid mechanics,”Annual review of fluid mechanics, vol. 52, no. 1, pp. 477–508, 2020
2020
-
[59]
Accelerating deep reinforcement learn- ing strategies of flow control through a multi-environment approach,
J. Rabault and A. Kuhnle, “Accelerating deep reinforcement learn- ing strategies of flow control through a multi-environment approach,” Physics of Fluids, vol. 31, no. 9, 2019
2019
-
[60]
Direct shape optimization through deep reinforcement learning,
J. Viquerat, J. Rabault, A. Kuhnle, H. Ghraieb, A. Larcher, and E. Hachem, “Direct shape optimization through deep reinforcement learning,”Journal of Computational Physics, vol. 428, p. 110080, 2021
2021
-
[61]
Learning to control pdes with differentiable physics,
P. Holl, V . Koltun, and N. Thuerey, “Learning to control pdes with differentiable physics,”arXiv preprint arXiv:2001.07457, 2020
-
[62]
Machine learning–accelerated computational fluid dynamics,
D. Kochkov, J. A. Smith, A. Alieva, Q. Wang, M. P. Brenner, and S. Hoyer, “Machine learning–accelerated computational fluid dynamics,” Proceedings of the National Academy of Sciences, vol. 118, no. 21, p. e2101784118, 2021
2021
-
[63]
Artificial neural networks trained through deep reinforcement learning discover control strategies for active flow control,
J. Rabault, M. Kuchta, A. Jensen, U. R ´eglade, and N. Cerardi, “Artificial neural networks trained through deep reinforcement learning discover control strategies for active flow control,”Journal of fluid mechanics, vol. 865, pp. 281–302, 2019
2019
-
[64]
A review on deep reinforcement learning for fluid me- chanics,
P. Garnier, J. Viquerat, J. Rabault, A. Larcher, A. Kuhnle, and E. Hachem, “A review on deep reinforcement learning for fluid me- chanics,”Computers & Fluids, vol. 225, p. 104973, 2021
2021
-
[65]
Robust flow control and optimal sensor placement using deep reinforcement learning,
R. Paris, S. Beneddine, and J. Dandois, “Robust flow control and optimal sensor placement using deep reinforcement learning,”Journal of Fluid Mechanics, vol. 913, p. A25, 2021
2021
-
[66]
Recent advances in applying deep reinforcement learning for flow control: Perspectives and future directions,
C. Vignon, J. Rabault, and R. Vinuesa, “Recent advances in applying deep reinforcement learning for flow control: Perspectives and future directions,”Physics of fluids, vol. 35, no. 3, p. 031301, 2023
2023
-
[67]
Applying deep reinforcement learning to active flow control in weakly turbulent conditions,
F. Ren, J. Rabault, and H. Tang, “Applying deep reinforcement learning to active flow control in weakly turbulent conditions,”Physics of Fluids, vol. 33, no. 3, 2021
2021
-
[68]
Reinforcement learning of control strategies for reducing skin friction drag in a fully developed turbulent channel flow,
T. Sonoda, Z. Liu, T. Itoh, and Y . Hasegawa, “Reinforcement learning of control strategies for reducing skin friction drag in a fully developed turbulent channel flow,”Journal of Fluid Mechanics, vol. 960, p. A30, 2023
2023
-
[69]
Flow navi- gation by smart microswimmers via reinforcement learning,
S. Colabrese, K. Gustavsson, A. Celani, and L. Biferale, “Flow navi- gation by smart microswimmers via reinforcement learning,”Physical review letters, vol. 118, no. 15, p. 158004, 2017
2017
-
[70]
Zermelo’s problem: optimal point-to-point navigation in 2d turbulent flows using reinforcement learning,
L. Biferale, F. Bonaccorso, M. Buzzicotti, P. Clark Di Leoni, and K. Gustavsson, “Zermelo’s problem: optimal point-to-point navigation in 2d turbulent flows using reinforcement learning,”Chaos: An Inter- disciplinary Journal of Nonlinear Science, vol. 29, no. 10, 2019
2019
-
[71]
Machine learning strategies for path-planning microswimmers in turbulent flows,
J. K. Alageshan, A. K. Verma, J. Bec, and R. Pandit, “Machine learning strategies for path-planning microswimmers in turbulent flows,”Physical Review E, vol. 101, no. 4, p. 043110, 2020
2020
-
[72]
Learning efficient navigation in vortical flow fields,
P. Gunnarson, I. Mandralis, G. Novati, P. Koumoutsakos, and J. O. Dabiri, “Learning efficient navigation in vortical flow fields,”Nature communications, vol. 12, no. 1, p. 7143, 2021
2021
-
[73]
Frequency selection by feedback control in a turbulent shear flow,
V . Parezanovi´c, L. Cordier, A. Spohn, T. Duriez, B. R. Noack, J.-P. Bon- net, M. Segond, M. Abel, and S. L. Brunton, “Frequency selection by feedback control in a turbulent shear flow,”Journal of Fluid Mechanics, vol. 797, pp. 247–283, 2016
2016
-
[74]
Blood flow in arteries,
D. N. Ku, “Blood flow in arteries,”Annual review of fluid mechanics, vol. 29, no. 1, pp. 399–434, 1997
1997
-
[75]
Phiflow: Differentiable simulations for pytorch, tensorflow and jax,
P. Holl and N. Thuerey, “Phiflow: Differentiable simulations for pytorch, tensorflow and jax,” inInternational Conference on Machine Learning. PMLR, 2024
2024
-
[76]
Development of high-efficiency superparamagnetic drug delivery system with mpi imaging capability,
S. Bai, X.-d. Zhang, Y .-q. Zou, Y .-x. Lin, Z.-y. Liu, K.-w. Li, P. Huang, T. Yoshida, Y .-l. Liu, M.-s. Li, W. Zhang, X.-j. Wang, M. Zhang, and C. Du, “Development of high-efficiency superparamagnetic drug delivery system with mpi imaging capability,” Frontiers in Bioengineering and Biotechnology, vol. V olume 12 - 2024, 2024. [Online]. Available: https...
-
[77]
Stable-baselines3: Reliable reinforcement learning implementations,
A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, and N. Dormann, “Stable-baselines3: Reliable reinforcement learning implementations,”Journal of Machine Learning Research, vol. 22, no. 268, pp. 1–8, 2021. [Online]. Available: http://jmlr.org/papers/v22/ 20-1364.html 14
2021
-
[78]
Gradient surgery for multi-task learning, 2020
T. Yu, S. Kumar, A. Gupta, S. Levine, K. Hausman, and C. Finn, “Gradient surgery for multi-task learning,” 2020. [Online]. Available: https://arxiv.org/abs/2001.06782
-
[79]
J. Berman. (2025) Fluxswarm: Micro-swarm locomotion using mo-marl, github repository. GitHub repository. [Online]. Available: https://github.com/josefberman/FluxSwarm
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.