Confidence-Adaptive SwiGLU for Mixture-of-Experts
Pith reviewed 2026-06-28 18:44 UTC · model grok-4.3
The pith
Making SiLU gate sharpness in SwiGLU a learnable function of router logits improves mean CORE performance in MoE Transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
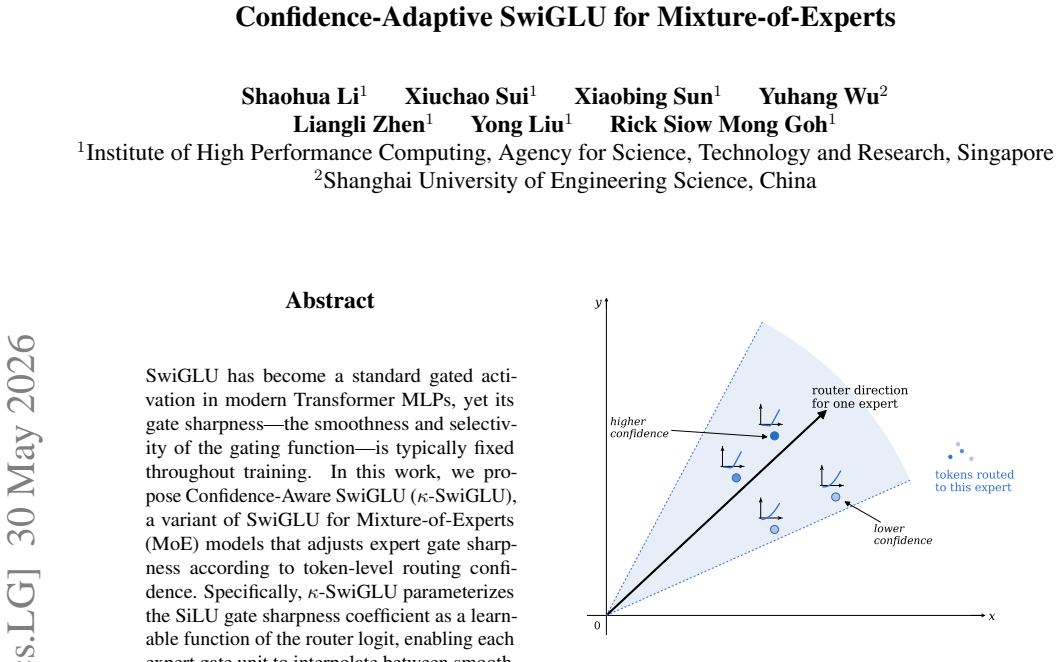
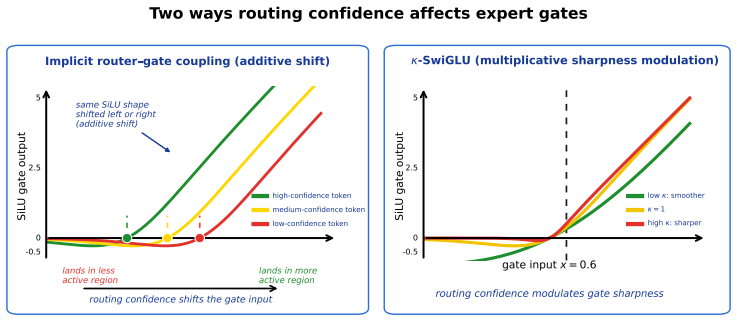
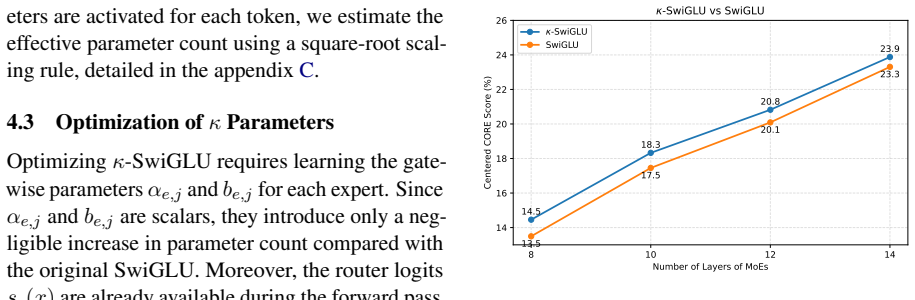
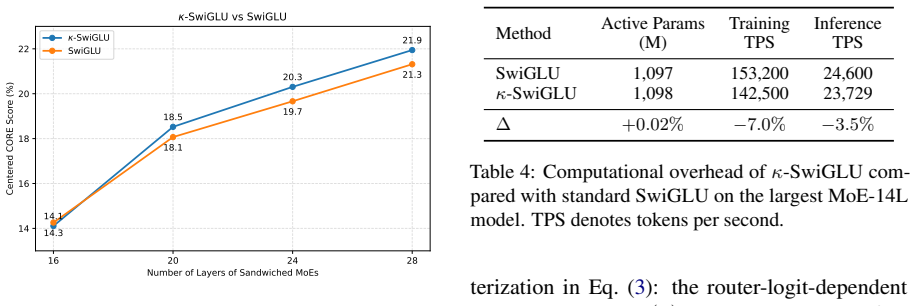
κ-SwiGLU parameterizes the SiLU gate sharpness coefficient as a learnable function of the router logit. This enables each expert gate unit to interpolate between smooth, broadly active gating and sharp, selective gating according to token-level routing confidence. Across MoE Transformer models ranging from 8 to 28 layers on the FineWeb-Edu dataset, κ-SwiGLU improves mean CORE performance while adding negligible parameters and incurring only a small computational overhead.
What carries the argument
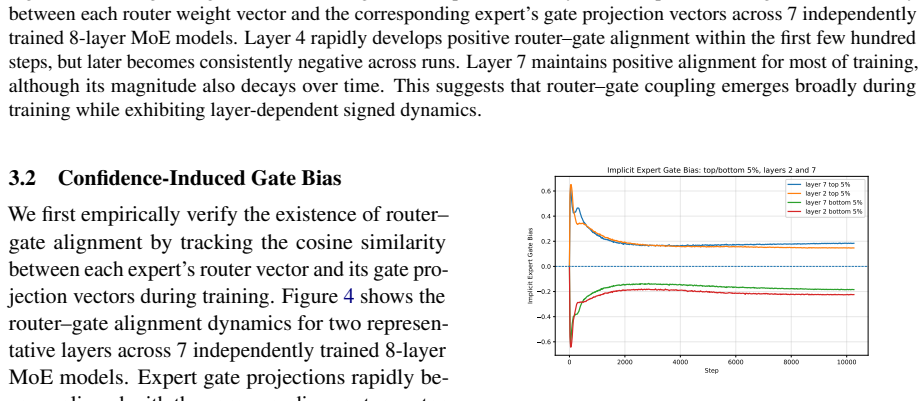
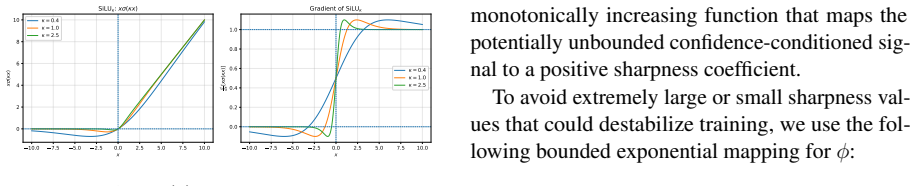
The learnable sharpness coefficient derived from the router logit, which controls selectivity of the SiLU gate inside each expert.
If this is right
- MoE MLPs can obtain performance gains from token-level gate adaptation.
- The benefit appears across model depths from 8 to 28 layers.
- The approach adds almost no parameters while keeping computational cost low.
Where Pith is reading between the lines
- The same idea of router-dependent sharpness might transfer to non-MoE gated networks.
- Adaptive sharpness could reduce expert interference on low-confidence tokens.
- Different mapping functions from router logit to sharpness could be tested for further gains.
Load-bearing premise
That parameterizing the SiLU gate sharpness coefficient as a learnable function of the router logit will produce stable beneficial adaptation without introducing overfitting or routing instability.
What would settle it
Training the same 8-to-28-layer MoE models on FineWeb-Edu with κ-SwiGLU and observing no improvement or a drop in mean CORE performance relative to fixed-sharpness SwiGLU.
Figures
read the original abstract
SwiGLU has become a standard gated activation in modern Transformer MLPs, yet its gate sharpness -- the smoothness and selectivity of the gating function -- is typically fixed throughout training. In this work, we propose Confidence-Aware SwiGLU ($\kappa$-SwiGLU), a variant of SwiGLU for Mixture-of-Experts (MoE) models that adjusts expert gate sharpness according to token-level routing confidence. Specifically, $\kappa$-SwiGLU parameterizes the SiLU gate sharpness coefficient as a learnable function of the router logit, enabling each expert gate unit to interpolate between smooth, broadly active gating and sharp, selective gating. We evaluate $\kappa$-SwiGLU on the FineWeb-Edu dataset across MoE Transformer models ranging from 8 to 28 layers. Across these settings, $\kappa$-SwiGLU improves mean CORE performance while adding negligible parameters and incurring only a small computational overhead, demonstrating that confidence-aware gate sharpness is a promising mechanism for improving MoE MLPs. The code is available at https://github.com/askerlee/kappa-swiglu.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Confidence-Aware SwiGLU (κ-SwiGLU), a variant of the standard SwiGLU activation for Mixture-of-Experts (MoE) Transformers. It parameterizes the SiLU gate sharpness coefficient κ as a learnable function of the router logit, allowing token-level adaptation between smooth and sharp gating based on routing confidence. The method is evaluated on the FineWeb-Edu dataset using MoE models with 8 to 28 layers, with the central claim that it improves mean CORE performance while adding negligible parameters and only small computational overhead. Code is released at the provided GitHub link.
Significance. If the empirical improvements hold under rigorous evaluation, this represents a low-cost, parameter-efficient modification to MoE MLPs that could improve expert gating selectivity without substantial overhead. The approach is simple enough to be widely adopted if shown to be stable across scales and tasks, and the code release supports reproducibility.
major comments (1)
- [Abstract] Abstract: The manuscript states that κ-SwiGLU 'improves mean CORE performance' across 8-28 layer models but provides no quantitative results, specific baselines, error bars, statistical tests, or details on the implementation and regularization of the learnable sharpness function. This absence leaves the central empirical claim without visible support and is load-bearing for the paper's contribution.
minor comments (1)
- [Abstract] The abstract would benefit from a brief equation or pseudocode defining the learnable function for κ to clarify the parameterization before the results claim.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for stronger empirical support in the abstract. We agree that the central claim requires visible quantitative backing and will revise the abstract accordingly while preserving its conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript states that κ-SwiGLU 'improves mean CORE performance' across 8-28 layer models but provides no quantitative results, specific baselines, error bars, statistical tests, or details on the implementation and regularization of the learnable sharpness function. This absence leaves the central empirical claim without visible support and is load-bearing for the paper's contribution.
Authors: We acknowledge the abstract as currently written does not include specific numbers, baselines, or implementation details, which weakens the visibility of the claim. The body of the manuscript (Section 4) reports mean CORE improvements across the 8-28 layer models on FineWeb-Edu, with direct comparisons to standard SwiGLU, and Section 3 details the κ parameterization as a learnable function of router logits (including any regularization). To address the referee's concern directly, we will revise the abstract to incorporate key quantitative results (e.g., average improvement magnitude, parameter overhead, and baseline reference) along with a brief mention of the κ formulation. If error bars or statistical tests are not already reported in the experiments, we will add them in the revision. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes κ-SwiGLU as an empirical architectural change that makes the SiLU sharpness coefficient a learnable function of the router logit. The central claim is an observed performance improvement on FineWeb-Edu across 8-28 layer MoE models, with no equations, derivations, or predictions presented. No self-citations, fitted inputs renamed as predictions, or ansatzes imported via citation appear in the provided text. The result is therefore an independent empirical finding rather than a quantity forced by construction from its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters of the learnable sharpness function
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author=. International Conference on Learning Representations , year=
-
[2]
Dmitry Lepikhin and HyoukJoong Lee and Yuanzhong Xu and Dehao Chen and Orhan Firat and Yanping Huang and Maxim Krikun and Noam Shazeer and Zhifeng Chen , booktitle=
-
[3]
Journal of Machine Learning Research , year =
William Fedus and Barret Zoph and Noam Shazeer , title =. Journal of Machine Learning Research , year =
-
[4]
Rajbhandari, Samyam and Li, Conglong and Yao, Zhewei and Zhang, Minjia and Aminabadi, Reza Yazdani and Awan, Ammar Ahmad and Rasley, Jeff and He, Yuxiong , booktitle =
-
[5]
and Gao, Huazuo and Chen, Deli and Li, Jiashi and Zeng, Wangding and Yu, Xingkai and Wu, Y
Dai, Damai and Deng, Chengqi and Zhao, Chenggang and Xu, R.x. and Gao, Huazuo and Chen, Deli and Li, Jiashi and Zeng, Wangding and Yu, Xingkai and Wu, Y. and Xie, Zhenda and Li, Y.k. and Huang, Panpan and Luo, Fuli and Ruan, Chong and Sui, Zhifang and Liang, Wenfeng. D eep S eek M o E : Towards Ultimate Expert Specialization in Mixture-of-Experts Language...
2024
-
[6]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=
-
[7]
2024 , eprint=
Mixtral of Experts , author=. 2024 , eprint=
2024
-
[8]
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
2025 , eprint=
NVIDIA Nemotron 3: Efficient and Open Intelligence , author=. 2025 , eprint=
2025
-
[10]
A Closer Look into Mixture-of-Experts in Large Language Models
Lo, Ka Man and Huang, Zeyu and Qiu, Zihan and Wang, Zili and Fu, Jie. A Closer Look into Mixture-of-Experts in Large Language Models. NAACL 2025 Findings. 2025
2025
-
[11]
Jeffrey Li and Alex Fang and Georgios Smyrnis and Maor Ivgi and Matt Jordan and Samir Yitzhak Gadre and Hritik Bansal and Etash Kumar Guha and Sedrick Keh and Kushal Arora and Saurabh Garg and Rui Xin and Niklas Muennighoff and Reinhard Heckel and Jean Mercat and Mayee F Chen and Suchin Gururangan and Mitchell Wortsman and Alon Albalak and Yonatan Bitton ...
-
[12]
2024 , eprint=
Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts , author=. 2024 , eprint=
2024
-
[13]
Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models
Qiu, Zihan and Huang, Zeyu and Zheng, Bo and Wen, Kaiyue and Wang, Zekun and Men, Rui and Titov, Ivan and Liu, Dayiheng and Zhou, Jingren and Lin, Junyang. Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models. ACL. 2025
2025
-
[14]
2022 , eprint=
ST-MoE: Designing Stable and Transferable Sparse Expert Models , author=. 2022 , eprint=
2022
-
[15]
S table M o E : Stable Routing Strategy for Mixture of Experts
Dai, Damai and Dong, Li and Ma, Shuming and Zheng, Bo and Sui, Zhifang and Chang, Baobao and Wei, Furu. S table M o E : Stable Routing Strategy for Mixture of Experts. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022
2022
-
[16]
2025 , eprint=
Routing Manifold Alignment Improves Generalization of Mixture-of-Experts LLMs , author=. 2025 , eprint=
2025
-
[17]
2026 , eprint=
Routing by Analogy: kNN-Augmented Expert Assignment for Mixture-of-Experts , author=. 2026 , eprint=
2026
-
[18]
S im SM o E : Toward Efficient Training Mixture of Experts via Solving Representational Collapse
Do, Giang and Le, Hung and Tran, Truyen. S im SM o E : Toward Efficient Training Mixture of Experts via Solving Representational Collapse. Findings of the Association for Computational Linguistics: NAACL 2025. 2025
2025
-
[19]
2025 , eprint=
Coupling Experts and Routers in Mixture-of-Experts via an Auxiliary Loss , author=. 2025 , eprint=
2025
-
[20]
Reviewing Discussion on the Router Orthogonalization Loss Proposed in ERNIE 4.5 , howpublished =
-
[21]
2026 , eprint=
Geometric Regularization in Mixture-of-Experts: The Disconnect Between Weights and Activations , author=. 2026 , eprint=
2026
-
[22]
ERNIE 4.5 Technical Report , author=
-
[23]
2020 , eprint=
GLU Variants Improve Transformer , author=. 2020 , eprint=
2020
-
[24]
and Fan, Angela and Auli, Michael and Grangier, David , title =
Dauphin, Yann N. and Fan, Angela and Auli, Michael and Grangier, David , title =. 2017 , booktitle =
2017
-
[25]
2024 , eprint=
ReLU ^2 Wins: Discovering Efficient Activation Functions for Sparse LLMs , author=. 2024 , eprint=
2024
-
[26]
2025 , eprint=
DeepSeek-V3 Technical Report , author=. 2025 , eprint=
2025
-
[27]
2025 , eprint=
gpt-oss-120b and gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[28]
2025 , eprint=
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models , author=. 2025 , eprint=
2025
-
[29]
2026 , eprint=
GLM-5: from Vibe Coding to Agentic Engineering , author=. 2026 , eprint=
2026
-
[30]
2026 , eprint=
Kimi K2: Open Agentic Intelligence , author=. 2026 , eprint=
2026
-
[31]
2026 , month = may, day =
Aurora: A Leverage-Aware Optimizer for Rectangular Matrices , author =. 2026 , month = may, day =
2026
-
[32]
2026 , eprint=
-Balancing for Mixture-of-Experts Training , author=. 2026 , eprint=
2026
-
[33]
arXiv preprint arXiv:2405.20768 , year=
Expanded gating ranges improve activation functions , author=. arXiv preprint arXiv:2405.20768 , year=
-
[34]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Searching for Activation Functions
Searching for activation functions , author=. arXiv preprint arXiv:1710.05941 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
(2021) with Downstream Evaluation and a Noise Floor , author=
Most Transformer Modifications Still Do Not Transfer at 1-3B: A 2020-2026 Update to Narang et al. (2021) with Downstream Evaluation and a Noise Floor , author=. 2026 , eprint=
2020
-
[37]
doi:10.57967/hf/2497 , publisher =
Lozhkov, Anton and Ben Allal, Loubna and von Werra, Leandro and Wolf, Thomas , title =. doi:10.57967/hf/2497 , publisher =
-
[38]
2016 , eprint=
Gaussian Error Linear Units (GELUs) , author=. 2016 , eprint=
2016
-
[39]
2018 , eprint=
Deep Learning using Rectified Linear Units (ReLU) , author=. 2018 , eprint=
2018
-
[40]
2026 , eprint=
PowLU: An Activation Function for Stable Pre-Training of LLMs , author=. 2026 , eprint=
2026
-
[41]
Token-Adaptive Mixing of Activations , author=
More Expressive Feedforward Layers: Part I. Token-Adaptive Mixing of Activations , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.