Beyond Penalizing Mistakes: Stabilizing Efficiency Training in Large Reasoning Models via Adaptive Correct-Only Rewards
Pith reviewed 2026-06-26 10:09 UTC · model grok-4.3
The pith
ACOER restricts length penalties to correct answers and adds dynamic normalization to prevent reward collapse while cutting tokens over 60 percent and raising accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
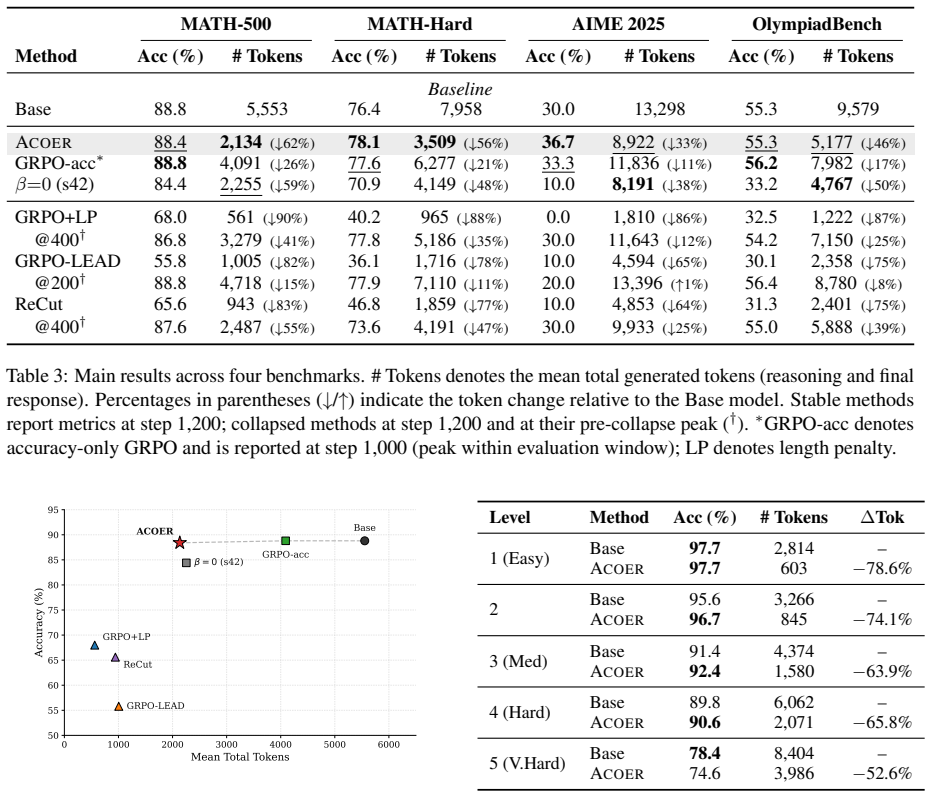
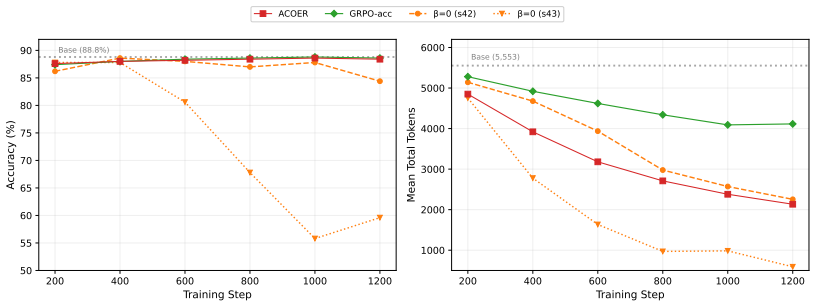
ACOER eliminates the structural penalty loop by isolating brevity bonuses to correct completions and prevents stochastic compression via dynamic budget normalization and control-loop penalty adjustments, yielding stable efficiency-aware optimization that improves accuracy and reduces token generation by over 60 percent across math benchmarks.
What carries the argument
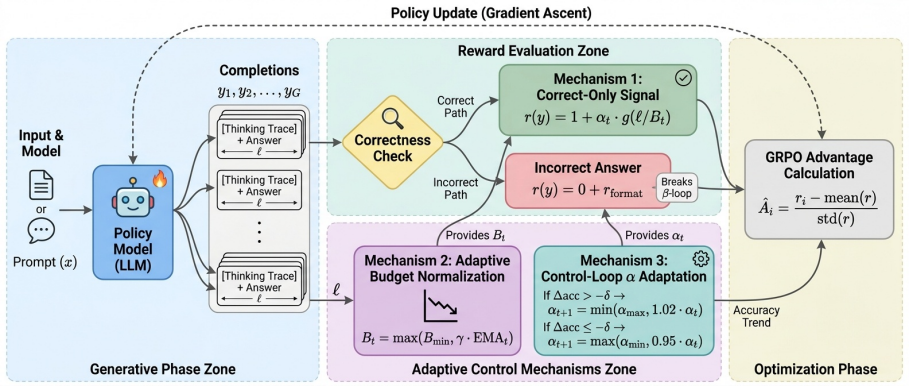
ACOER (Adaptive Correct-Only Efficiency Reward), which isolates length penalties exclusively to correct answers and applies dynamic budget normalization plus control-loop adjustments to block both collapse modes.
If this is right
- Models trained with ACOER generate over 60 percent fewer tokens than the base model on mathematical reasoning benchmarks.
- Overall accuracy on those benchmarks rises above the accuracy of the base model.
- Training avoids both the structural collapse seen when incorrect answers receive length penalties and the stochastic collapse from unchecked over-compression.
- Any reward configuration that penalizes length of incorrect answers remains structurally unstable under continued optimization.
Where Pith is reading between the lines
- The same correct-only isolation pattern could be tested on non-mathematical tasks where response length also trades off against quality.
- Control-loop adjustments might be generalized to other reward components that risk over-optimization in policy-gradient methods.
- Longer training horizons would be needed to confirm that the dynamic normalization continues to bound compression without external intervention.
Load-bearing premise
That isolating length penalties to correct answers plus dynamic budget normalization and control-loop adjustments is sufficient to eliminate both the structural penalty loop and stochastic over-compression across sustained optimization runs.
What would settle it
A sustained GRPO training run using ACOER in which accuracy on a held-out math benchmark drops below the base model after the token reduction is achieved.
Figures
read the original abstract
Training large language models to reason efficiently is a critical challenge. While integrating length-penalizing rewards into Group Relative Policy Optimization (GRPO) aims to reduce verbosity, it frequently triggers reward collapse, severely degrading reasoning capabilities. Through a systematic evaluation of various reward configurations, we identify the root mechanism: GRPO's group normalization creates divergent advantages when incorrect answers receive continuous length penalties. Consequently, methods penalizing the length of incorrect answers are structurally prone to collapse under sustained optimization. Furthermore, restricting penalties exclusively to correct answers avoids this primary failure, but leaves the model susceptible to a stochastic collapse driven by response over-compression. To robustly prevent both failure modes, we propose ACOER (Adaptive Correct-Only Efficiency Reward). ACOER eliminates the structural penalty loop by isolating brevity bonuses to correct completions and prevents stochastic compression via dynamic budget normalization and control-loop penalty adjustments. Evaluated across diverse mathematical reasoning benchmarks, ACOER improves overall accuracy compared to the base model while reducing token generation by over 60%, establishing a fundamentally stable approach for efficiency-aware optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that length-penalizing rewards in GRPO cause reward collapse when applied to incorrect answers because group normalization produces divergent advantages; restricting penalties to correct answers avoids the structural failure but risks stochastic over-compression. ACOER is proposed to isolate brevity bonuses to correct completions and add dynamic budget normalization plus control-loop penalty adjustments. The method is reported to raise accuracy over the base model while cutting token generation by more than 60% across mathematical reasoning benchmarks, yielding a stable efficiency-aware optimization procedure.
Significance. If the empirical results hold under scrutiny, the work supplies a concrete, easily implemented fix for a recurring instability in RL-based efficiency training of reasoning models. The explicit diagnosis of the group-normalization mechanism and the restriction to correct-only penalties constitute a useful contribution to reward design; the reported accuracy gains alongside large token savings would be practically relevant for deployment.
major comments (2)
- [Abstract] Abstract: the central claim of >60% token reduction together with accuracy improvement is presented without any quantitative benchmark scores, ablation tables, or per-task breakdowns; these data are load-bearing for the assertion that ACOER 'establishes a fundamentally stable approach.'
- [Abstract] The weakest assumption—that isolating length penalties to correct answers plus dynamic normalization suffices to eliminate both structural and stochastic collapse—is stated but not accompanied by sustained-run statistics or failure-mode frequency tables that would confirm the assumption holds across optimization trajectories.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each major point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of >60% token reduction together with accuracy improvement is presented without any quantitative benchmark scores, ablation tables, or per-task breakdowns; these data are load-bearing for the assertion that ACOER 'establishes a fundamentally stable approach.'
Authors: The abstract provides a concise summary of the claims, while the full manuscript includes the supporting quantitative benchmark scores, ablation studies, and per-task breakdowns in Section 4 and the appendix. To make the central claim more self-contained in the abstract, we will revise it to incorporate representative numerical results from the primary benchmarks. revision: yes
-
Referee: [Abstract] The weakest assumption—that isolating length penalties to correct answers plus dynamic normalization suffices to eliminate both structural and stochastic collapse—is stated but not accompanied by sustained-run statistics or failure-mode frequency tables that would confirm the assumption holds across optimization trajectories.
Authors: The reported experiments across multiple mathematical reasoning benchmarks demonstrate consistent accuracy improvements and token reductions with no observed collapse, providing empirical support for the stability of ACOER. We agree that explicit sustained-run statistics and failure-mode frequency tables would strengthen the presentation and will add such analysis of multiple independent runs in the revised manuscript. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical training method (ACOER) for stabilizing efficiency rewards in GRPO-based LLM reasoning optimization. The abstract and description frame the contribution as identification of failure modes in existing reward configurations followed by a proposed fix (correct-only penalties plus dynamic normalization), validated on mathematical benchmarks showing accuracy gains and >60% token reduction. No equations, closed-form derivations, or first-principles claims are provided that reduce the outcome to a fitted parameter or self-citation by construction. The work is self-contained as an experimental intervention with external benchmark evaluation; no load-bearing step equates the claimed result to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2024 , howpublished =
2024
-
[2]
2025 , howpublished =
2025
-
[3]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
- [4]
-
[5]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[6]
QwQ-32B: Embracing the Power of Reinforcement Learning , url =
Qwen Team , month =. QwQ-32B: Embracing the Power of Reinforcement Learning , url =
-
[7]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[8]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, Y. K. and Wu, Y. and Guo, Daya , year=. 2402.03300 , archivePrefix=
-
[9]
arXiv preprint arXiv:2503.04697 , year=
L1: Controlling how long a reasoning model thinks with reinforcement learning , author=. arXiv preprint arXiv:2503.04697 , year=
-
[10]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
Dast: Difficulty-adaptive slow-thinking for large reasoning models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
2025
-
[11]
arXiv preprint arXiv:2510.08026 , year=
PEAR: Phase Entropy Aware Reward for Efficient Reasoning , author=. arXiv preprint arXiv:2510.08026 , year=
-
[12]
arXiv preprint arXiv:2505.21178 , year=
Walk before you run! concise llm reasoning via reinforcement learning , author=. arXiv preprint arXiv:2505.21178 , year=
-
[13]
Hao Wen and Xinrui Wu and Yi Sun and Feifei Zhang and Liye Chen and Jie Wang and Yunxin Liu and Yunhao Liu and Ya-Qin Zhang and Yuanchun Li , year =. 2508.17196 , archivePrefix =
-
[14]
Guosheng Liang and Longguang Zhong and Ziyi Yang and Xiaojun Quan , year =. 2505.14183 , archivePrefix =
-
[15]
Chenlong Wang and Yuanning Feng and Dongping Chen and Zhaoyang Chu and Ranjay Krishna and Tianyi Zhou , year =. 2506.08343 , archivePrefix =
-
[16]
arXiv preprint arXiv:2506.10446 , year=
Fast on the easy, deep on the hard: Efficient reasoning via powered length penalty , author=. arXiv preprint arXiv:2506.10446 , year=
-
[17]
arXiv preprint arXiv:2506.05256 , year=
Just enough thinking: Efficient reasoning with adaptive length penalties reinforcement learning , author=. arXiv preprint arXiv:2506.05256 , year=
-
[18]
arXiv preprint arXiv:2505.15612 , year=
Learn to reason efficiently with adaptive length-based reward shaping , author=. arXiv preprint arXiv:2505.15612 , year=
-
[19]
Bin, Yi and Jiang, Tianyi and Ding, Yujuan and Zhu, Kainian and Ma, Fei and Song, Jingkuan and Yang, Yang and Shen, Heng Tao , year=. 2510.02249 , archivePrefix=
-
[20]
Jinyan Su and Claire Cardie , year =. 2505.18298 , archivePrefix =
-
[21]
arXiv preprint arXiv:2512.21540 , year=
Leash: Adaptive Length Penalty and Reward Shaping for Efficient Large Reasoning Model , author=. arXiv preprint arXiv:2512.21540 , year=
-
[22]
Yang Sui and Yu-Neng Chuang and Guanchu Wang and Jiamu Zhang and Tianyi Zhang and Jiayi Yuan and Hongyi Liu and Andrew Wen and Shaochen Zhong and Na Zou and Hanjie Chen and Xia Hu , year =. 2503.16419 , archivePrefix =
-
[23]
Yuan, Danlong and Xie, Tian and Huang, Shaohan and Gong, Zhuocheng and Zhang, Huishuai and Luo, Chong and Wei, Furu and Zhao, Dongyan , year=. 2505.12284 , archivePrefix=
-
[24]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Grpo-lead: A difficulty-aware reinforcement learning approach for concise mathematical reasoning in language models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=. 2025 , address=. doi:10.18653/v1/2025.emnlp-main.287 , url=
-
[25]
Jin, Zhensheng and Li, Xinze and Ji, Yifan and Peng, Chunyi and Liu, Zhenghao and Shi, Qi and Yan, Yukun and Wang, Shuo and Peng, Furong and Yu, Ge , year=. 2506.10822 , archivePrefix=
-
[26]
arXiv preprint arXiv:2510.04474 , year=
DRPO: Efficient Reasoning via Decoupled Reward Policy Optimization , author=. arXiv preprint arXiv:2510.04474 , year=
-
[27]
arXiv preprint arXiv:2504.05185 , year=
Concise reasoning via reinforcement learning , author=. arXiv preprint arXiv:2504.05185 , year=
-
[28]
arXiv preprint arXiv:2506.06941 , year=
The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity , author=. arXiv preprint arXiv:2506.06941 , year=
-
[29]
Yue, Yang and Chen, Zhiqi and Lu, Rui and Zhao, Andrew and Wang, Zhaokai and Yue, Yang and Song, Shiji and Huang, Gao , year=. 2504.13837 , archivePrefix=
-
[30]
Proceedings of the Sixteenth International Conference on Machine Learning (ICML 1999) , pages=
Policy invariance under reward transformations: Theory and application to reward shaping , author=. Proceedings of the Sixteenth International Conference on Machine Learning (ICML 1999) , pages=. 1999 , publisher=
1999
-
[31]
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , year =. 2106.09685 , archivePrefix =
-
[32]
von Werra, Leandro and Belkada, Younes and Tunstall, Lewis and Beeching, Edward and Thrush, Tristan and Lambert, Nathan and Huang, Shengyi and Rasul, Kashif and Gallouédec, Quentin , license =
-
[33]
Samyam Rajbhandari and Jeff Rasley and Olatunji Ruwase and Yuxiong He , year =. 1910.02054 , archivePrefix =
Pith/arXiv arXiv 1910
-
[34]
Gonzalez and Hao Zhang and Ion Stoica , year =
Woosuk Kwon and Zhuohan Li and Siyuan Zhuang and Ying Sheng and Lianmin Zheng and Cody Hao Yu and Joseph E. Gonzalez and Hao Zhang and Ion Stoica , year =. 2309.06180 , archivePrefix =
-
[35]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[36]
arXiv preprint arXiv:2103.03874 , year=
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
-
[37]
Li, Jia and Beeching, Edward and Tunstall, Lewis and Lipkin, Ben and Soletskyi, Roman and Huang, Shengyi Costa and Rasul, Kashif and Yu, Longhui and Jiang, Albert and Shen, Ziju and Qin, Zihan and Dong, Bin and Zhou, Li and Fleureau, Yann and Lample, Guillaume and Polu, Stanislas , year=
-
[38]
Haotian Luo and Li Shen and Haiying He and Yibo Wang and Shiwei Liu and Wei Li and Naiqiang Tan and Xiaochun Cao and Dacheng Tao , year =. 2501.12570 , archivePrefix =
-
[39]
Bairu Hou and Yang Zhang and Jiabao Ji and Yujian Liu and Kaizhi Qian and Jacob Andreas and Shiyu Chang , year =. 2504.01296 , archivePrefix =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.