Scaling Multi-Reference Image Generation with Dynamic Reward Optimization
Pith reviewed 2026-06-26 05:04 UTC · model grok-4.3
The pith
A two-stage framework with dynamic reward techniques improves open-source models on complex multi-reference image generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
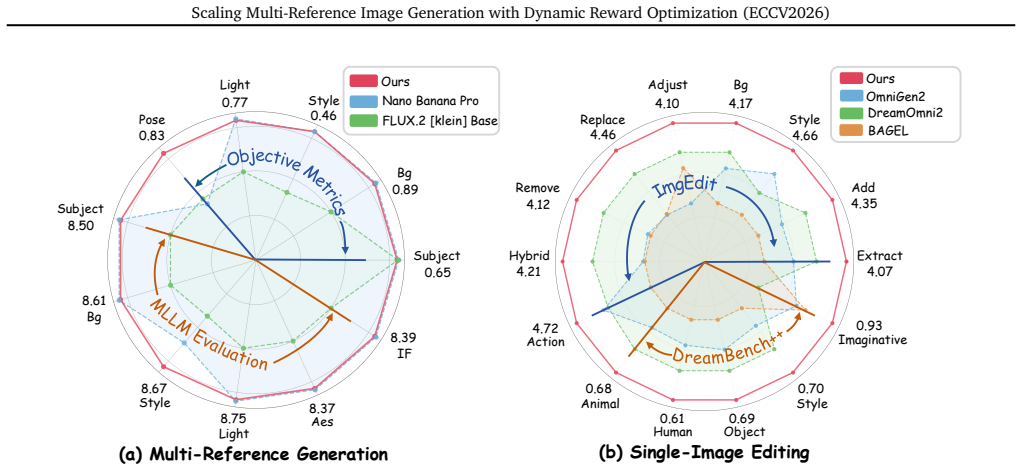
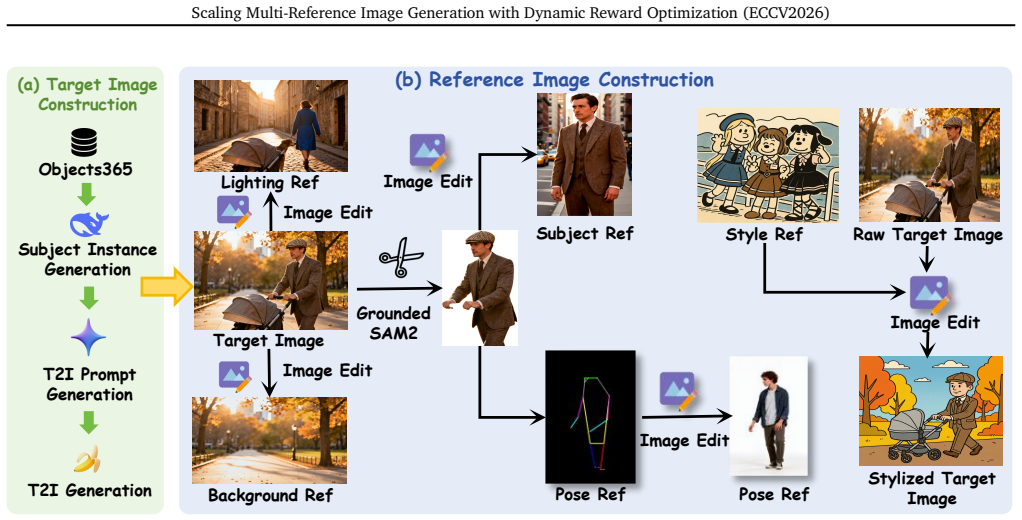
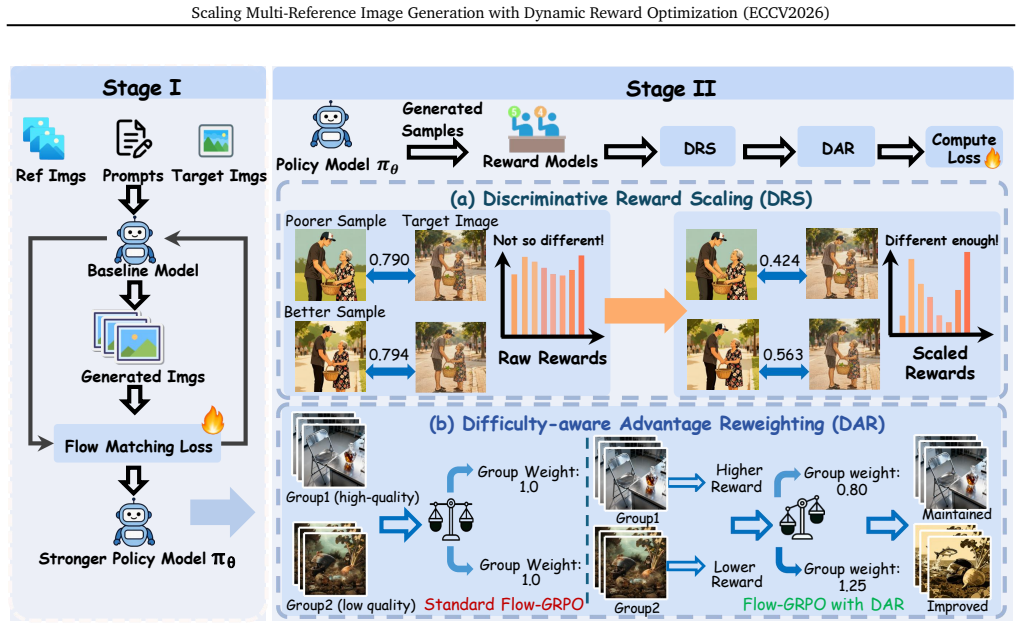
DyRef is a two-stage training framework where supervised fine-tuning provides basic MRIG capability and a second stage with Difficulty-aware Advantage Reweighting (DAR) and Discriminative Reward Scaling (DRS) dynamically adjusts optimization to improve handling of many mixed-type reference images, leading to better performance on OmniRef-Bench and single-image editing benchmarks.
What carries the argument
DyRef two-stage framework with Difficulty-aware Advantage Reweighting (DAR) that adjusts the optimization objective and Discriminative Reward Scaling (DRS) that enlarges intra-group reward differences.
If this is right
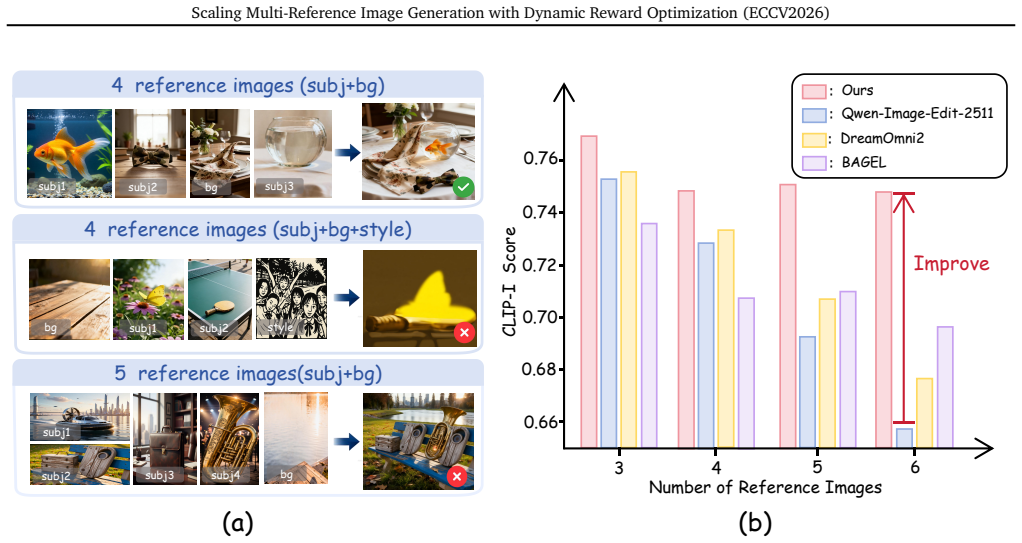
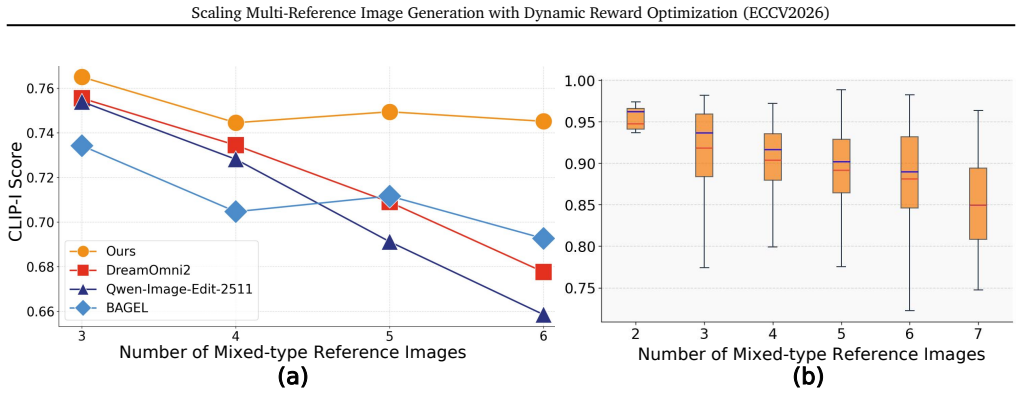
- Mainstream open-source models can better handle complex MRIG scenarios with increasing numbers of mixed-type reference images.
- The framework generalizes to improve performance on single-image editing benchmarks.
- DAR enables dynamic adjustment for large numbers of references.
- DRS supports more effective policy optimization through larger reward differences.
Where Pith is reading between the lines
- Applying similar dynamic reward methods could benefit other multi-input generation tasks in vision.
- The introduction of OmniRef-Bench may drive development of models that maintain performance with more references.
- Testing on even larger reference sets could reveal scalability limits of the approach.
Load-bearing premise
The performance improvements are caused by the DAR and DRS techniques rather than other unmentioned changes in training or evaluation.
What would settle it
An experiment that applies the same first-stage fine-tuning but omits DAR and DRS, then measures if performance on OmniRef-Bench still improves compared to the base model.
Figures















read the original abstract
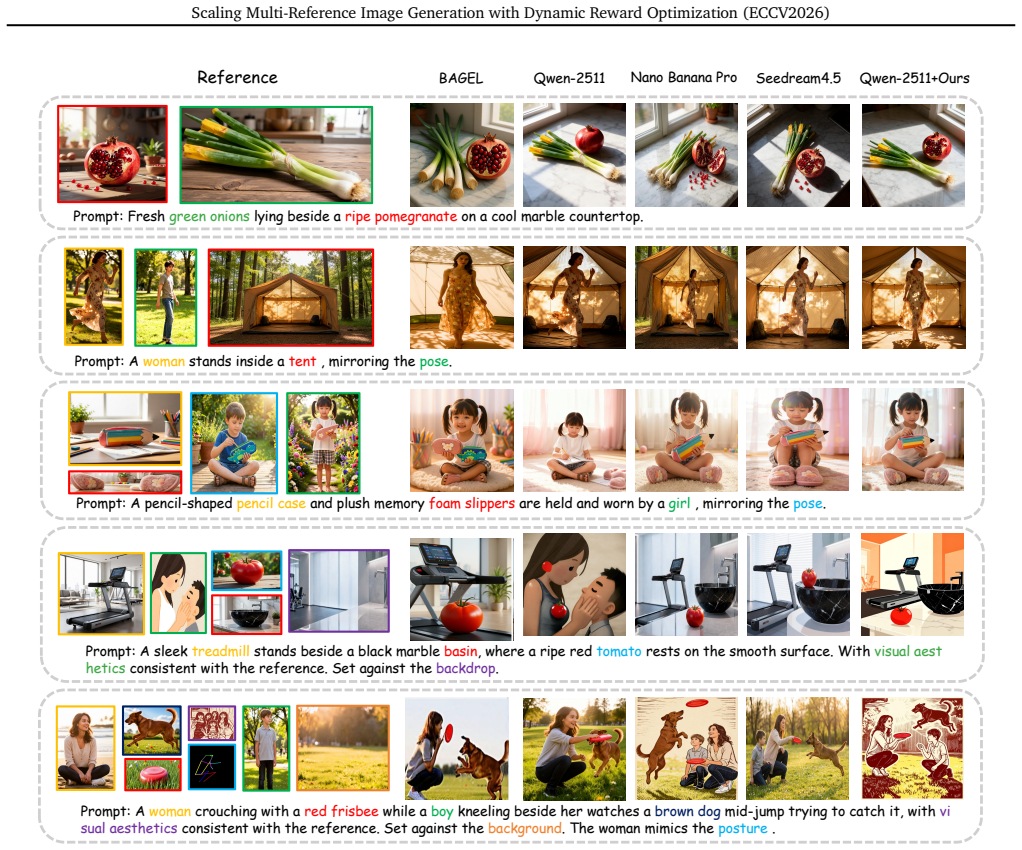
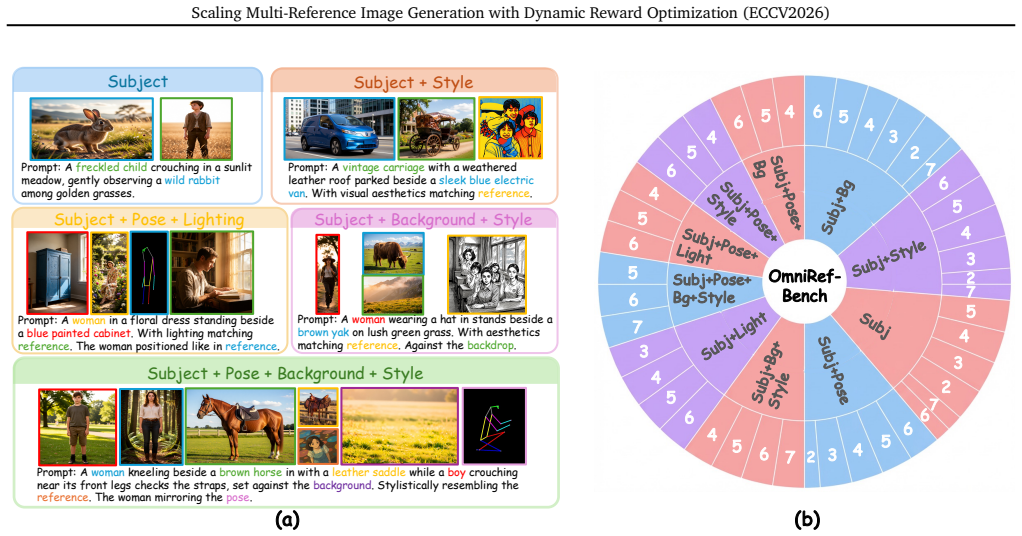
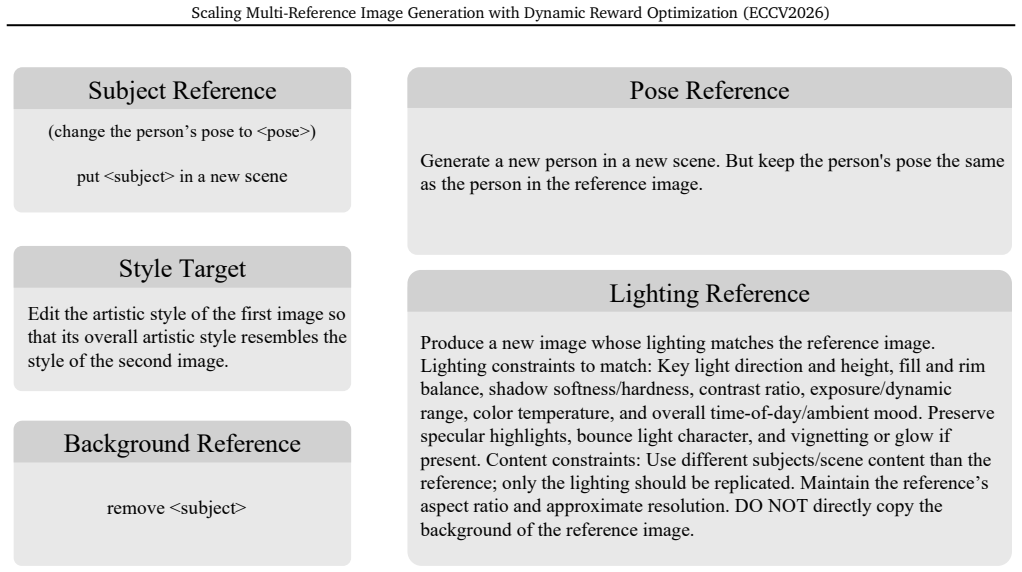
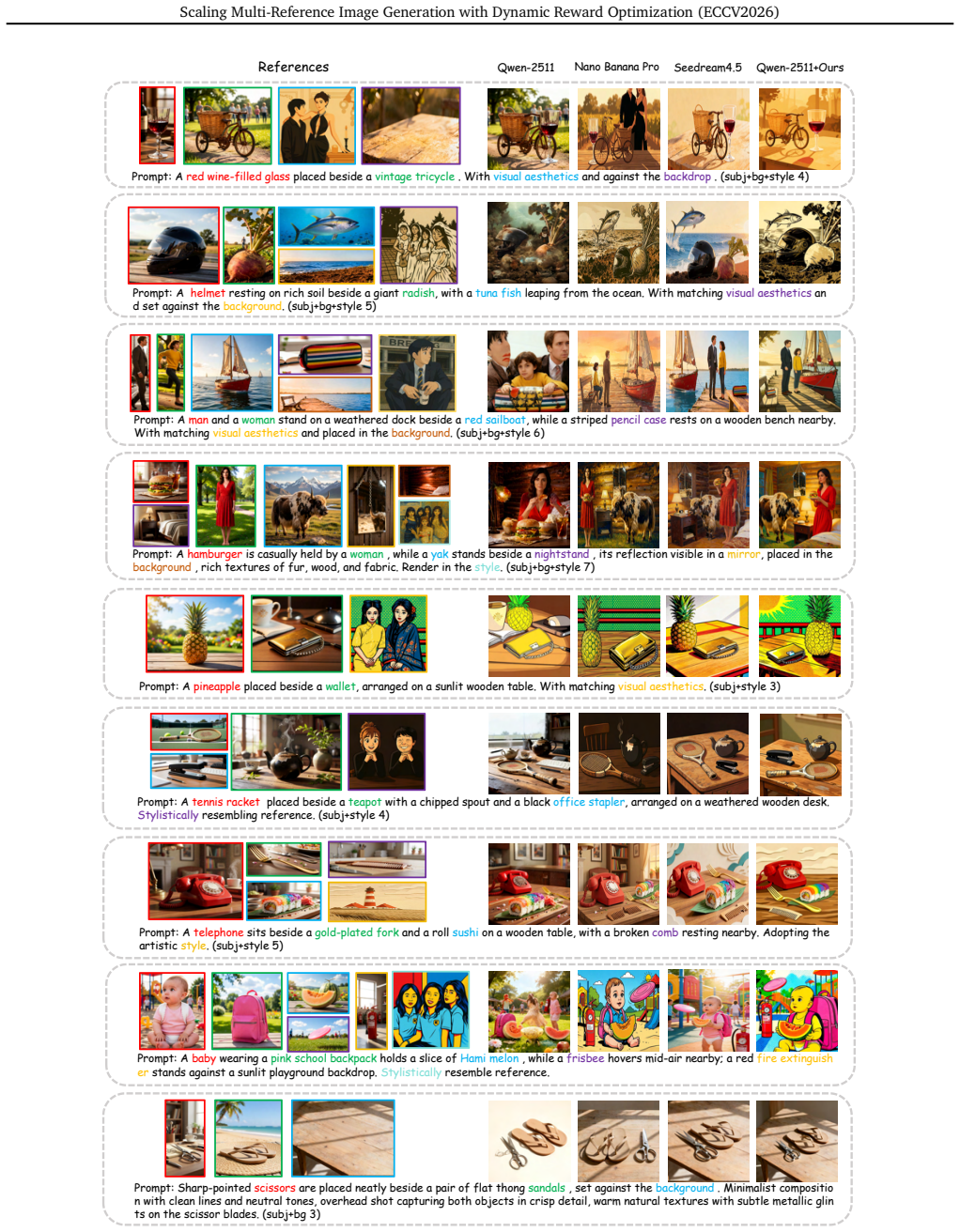
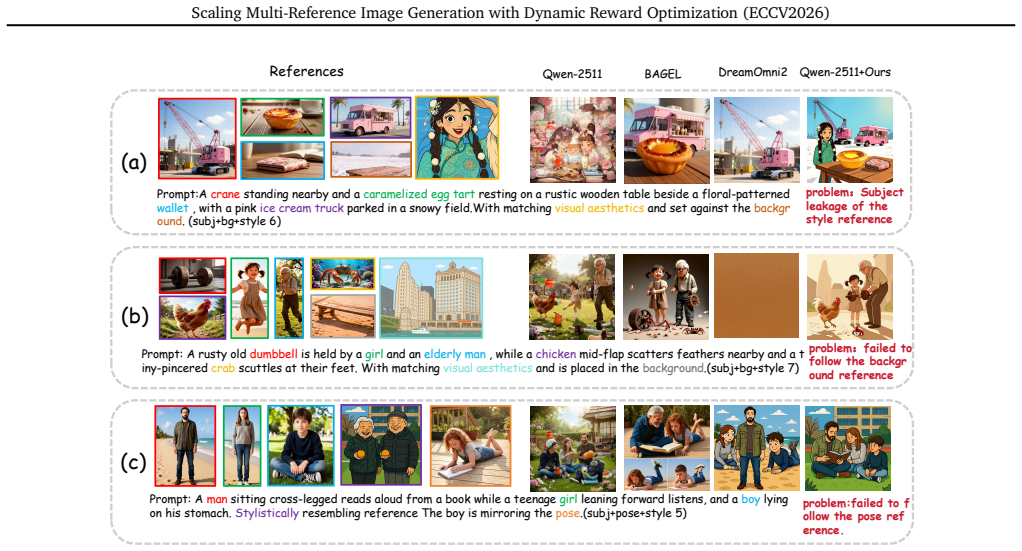
While personalized image generation has achieved remarkable progress, multi-reference image generation (MRIG) remains a challenging task. Most existing benchmarks fail to adequately evaluate complex MRIG scenarios, hindering further progress in this area. To better assess model performance on complex MRIG tasks, we introduce OmniRef-Bench, a benchmark that covers complex combinations of reference image types and a large number of reference images. Evaluations on OmniRef-Bench show that mainstream open-source models struggle in complex MRIG scenarios, and their performance deteriorates significantly as the number of mixed-type reference images increases. To address this issue, we propose DyRef, a two-stage training framework. In the first stage, supervised fine-tuning equips the model with the basic capability to handle complex MRIG tasks. In the second stage, we introduce Difficulty-aware Advantage Reweighting (DAR) and Discriminative Reward Scaling (DRS). DAR dynamically adjusts the optimization objective to improve performance when handling a large number of mixed-type reference images. DRS enlarges intra-group reward differences for more effective policy optimization. Experiments demonstrate that DyRef significantly improves the performance of open-source models on OmniRef-Bench and single-image editing benchmarks, demonstrating the effectiveness and generalization capability of our approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OmniRef-Bench to evaluate complex multi-reference image generation (MRIG) with mixed reference types and large reference counts. It reports that existing open-source models degrade as reference complexity increases. The authors propose DyRef, a two-stage framework: supervised fine-tuning (SFT) to acquire basic MRIG capability, followed by Difficulty-aware Advantage Reweighting (DAR) and Discriminative Reward Scaling (DRS) for dynamic optimization. Experiments are stated to show that DyRef yields significant gains on OmniRef-Bench and single-image editing benchmarks, with claims of effectiveness and generalization.
Significance. A new benchmark targeting under-evaluated complex MRIG scenarios would be useful if accompanied by reproducible baselines. If the reported gains are shown to arise specifically from DAR and DRS rather than additional training or data exposure, the two-stage dynamic-reward approach could offer a practical route to scaling open-source models on multi-reference tasks. The manuscript does not yet supply the quantitative tables, error bars, or controlled ablations needed to evaluate this potential.
major comments (2)
- [Experiments] Experiments section: The central claim that DAR and DRS produce the observed gains on OmniRef-Bench is load-bearing, yet no ablation is reported that holds total training steps, data, and base model fixed while toggling only the second-stage reward components. Without such controls it remains possible that gains arise from extra optimization rather than the proposed dynamic mechanisms.
- [Experiments] §4 (or equivalent results section): No quantitative metrics, standard deviations, or per-reference-count breakdowns are referenced to support the abstract statement that performance 'deteriorates significantly' with increasing mixed-type references; the absence of these numbers prevents verification of the deterioration trend that motivates DyRef.
minor comments (2)
- [Abstract] The abstract would benefit from at least one concrete metric (e.g., FID or CLIP score delta) and the number of references at which deterioration is observed.
- [Method] Notation for DAR and DRS reward terms should be defined explicitly with equations in the method section to allow readers to assess whether the reweighting is parameter-free or introduces new hyperparameters.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the experimental section. We address the major comments point by point below and will revise the manuscript to incorporate the requested controls and quantitative details.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The central claim that DAR and DRS produce the observed gains on OmniRef-Bench is load-bearing, yet no ablation is reported that holds total training steps, data, and base model fixed while toggling only the second-stage reward components. Without such controls it remains possible that gains arise from extra optimization rather than the proposed dynamic mechanisms.
Authors: We agree that a controlled ablation isolating the contribution of DAR and DRS is essential. In the revised manuscript, we will add an ablation where total training steps, data volume, and base model are held fixed, directly comparing SFT alone against SFT followed by the DAR/DRS stage to demonstrate that the gains derive specifically from the dynamic reward mechanisms. revision: yes
-
Referee: [Experiments] §4 (or equivalent results section): No quantitative metrics, standard deviations, or per-reference-count breakdowns are referenced to support the abstract statement that performance 'deteriorates significantly' with increasing mixed-type references; the absence of these numbers prevents verification of the deterioration trend that motivates DyRef.
Authors: We acknowledge the absence of these supporting numbers in the current version. The revised results section will include detailed quantitative tables reporting metrics with standard deviations and per-reference-count breakdowns across mixed reference types to substantiate the deterioration trend on OmniRef-Bench. revision: yes
Circularity Check
No circularity: empirical claims rest on benchmark comparisons without self-referential derivations
full rationale
The paper describes a two-stage empirical training procedure (SFT followed by DAR/DRS reward optimization) and reports performance gains on OmniRef-Bench and editing tasks. No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce any claimed result to its own inputs by construction. The central claims are falsifiable via external benchmarks and are not tautological, so the derivation chain is self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[2]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[3]
Qwen-image technical report, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingkun...
Pith/arXiv arXiv 2025
-
[4]
Step1x-edit: A practical framework for general image editing.arXiv preprint arXiv:2504.17761, 2025
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chunrui Han, et al. Step1x-edit: A practical framework for general image editing.arXiv preprint arXiv:2504.17761, 2025
Pith/arXiv arXiv 2025
-
[5]
FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
Black Forest Labs. FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
2025
-
[6]
Dreamo: A unified framework for image customization
Chong Mou, Yanze Wu, Wenxu Wu, Zinan Guo, Pengze Zhang, Yufeng Cheng, Yiming Luo, Fei Ding, Shiwen Zhang, Xinghui Li, et al. Dreamo: A unified framework for image customization. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–12, 2025
2025
-
[7]
Ominicontrol: Minimal and universal control for diffusion transformer
Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang. Ominicontrol: Minimal and universal control for diffusion transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14940–14950, 2025
2025
-
[8]
Dreamomni3: Scribble-basededitingandgeneration.arXivpreprintarXiv:2512.22525, 2025
Bin Xia, Bohao Peng, Jiyang Liu, Sitong Wu, Jingyao Li, Junjia Huang, Xu Zhao, Yitong Wang, Ruihang Chu,BeiYu,etal. Dreamomni3: Scribble-basededitingandgeneration.arXivpreprintarXiv:2512.22525, 2025
arXiv 2025
-
[9]
Hongyang Wei, Bin Wen, Yancheng Long, Yankai Yang, Yuhang Hu, Tianke Zhang, Wei Chen, Haonan Fan, Kaiyu Jiang, Jiankang Chen, et al. Uniref-image-edit: Towards scalable and consistent multi- reference image editing.arXiv preprint arXiv:2602.14186, 2026
arXiv 2026
-
[10]
Dreamomni2: Multimodalinstruction-basededitingandgeneration
Bin Xia, Bohao Peng, Yuechen Zhang, Junjia Huang, Jiyang Liu, Jingyao Li, Haoru Tan, Sitong Wu, ChengyaoWang, YitongWang, etal. Dreamomni2: Multimodalinstruction-basededitingandgeneration. arXiv preprint arXiv:2510.06679, 2025
arXiv 2025
-
[11]
Xinyang Song, Libin Wang, Weining Wang, Zhiwei Li, Jianxin Sun, Dandan Zheng, Jingdong Chen, Qi Li, and Zhenan Sun. 3sgen: Unified subject, style, and structure-driven image generation with adaptive task-specific memory.arXiv preprint arXiv:2512.19271, 2025
arXiv 2025
-
[12]
Multibanana: A challenging benchmark for multi-reference text-to-image generation
Yuta Oshima, Daiki Miyake, Kohsei Matsutani, Yusuke Iwasawa, Masahiro Suzuki, Yutaka Matsuo, and Hiroki Furuta. Multibanana: A challenging benchmark for multi-reference text-to-image generation. arXiv preprint arXiv:2511.22989, 2025. 14 Scaling Multi-Reference Image Generation with Dynamic Reward Optimization (ECCV2026)
arXiv 2025
-
[13]
Generative ai aids personalized product aesthetic generation and evaluation based on style themes.Advanced Engineering Informatics, 68:103756, 2025
Yao Wang, Jingsen Zhang, Chengyi Shen, Huiling Yu, and Shijian Luo. Generative ai aids personalized product aesthetic generation and evaluation based on style themes.Advanced Engineering Informatics, 68:103756, 2025
2025
-
[14]
Ctr-driven advertising image generation with multimodal large language models
Xingye Chen, Wei Feng, Zhenbang Du, Weizhen Wang, Yanyin Chen, Haohan Wang, Linkai Liu, Yaoyu Li, Jinyuan Zhao, Yu Li, et al. Ctr-driven advertising image generation with multimodal large language models. InProceedings of the ACM on Web Conference 2025, pages 2262–2275, 2025
2025
-
[15]
Bowen Chen, Mengyi Zhao, Haomiao Sun, Li Chen, Xu Wang, Kang Du, and Xinglong Wu. Xverse: Consistent multi-subject control of identity and semantic attributes via dit modulation.arXiv preprint arXiv:2506.21416, 2025
arXiv 2025
-
[16]
Multiref: Controllable image generation with multiple visual references
Ruoxi Chen, Dongping Chen, Siyuan Wu, Sinan Wang, Shiyun Lang, Peter Sushko, Gaoyang Jiang, Yao Wan, and Ranjay Krishna. Multiref: Controllable image generation with multiple visual references. In Proceedings of the 33rd ACM International Conference on Multimedia, pages 13325–13331, 2025
2025
-
[17]
Ruihang Xu, Dewei Zhou, Fan Ma, and Yi Yang. Contextgen: Contextual layout anchoring for identity- consistent multi-instance generation.arXiv preprint arXiv:2510.11000, 2025
arXiv 2025
-
[19]
Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.18871, 2025
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, Ze Liu, Ziyi Xia, Chaofan Li, Haoge Deng, Jiahao Wang, Kun Luo, Bo Zhang, Defu Lian, Xinlong Wang, Zhongyuan Wang, Tiejun Huang, and Zheng Liu. Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.18871, 2025
Pith/arXiv arXiv 2025
-
[20]
Nanobanana: Gemini 2.5 flash image model
Google DeepMind. Nanobanana: Gemini 2.5 flash image model. https://developers. googleblog.com/en/introducing-gemini-2-5-flash-image/, 2025
2025
-
[21]
Team Seedream, Yunpeng Chen, Yu Gao, Lixue Gong, Meng Guo, Qiushan Guo, Zhiyao Guo, Xiaoxia Hou, Weilin Huang, Yixuan Huang, et al. Seedream 4.0: Toward next-generation multimodal image generation.arXiv preprint arXiv:2509.20427, 2025
Pith/arXiv arXiv 2025
-
[22]
Shulei Wang, Longhui Wei, Xin He, Jianbo Ouyang, Hui Lu, Zhou Zhao, and Qi Tian. Psr: Scaling multi-subject personalized image generation with pairwise subject-consistency rewards.arXiv preprint arXiv:2512.01236, 2025
Pith/arXiv arXiv 2025
-
[23]
Dreambench++: A human-aligned benchmark for personalized image generation
Yuang Peng, Yuxin Cui, Haomiao Tang, Zekun Qi, Runpei Dong, Jing Bai, Chunrui Han, Zheng Ge, Xiangyu Zhang, and Shu-Tao Xia. Dreambench++: A human-aligned benchmark for personalized image generation. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://dreambenchplus.github.io/
2025
-
[24]
Imgedit: A unified image editing dataset and benchmark.arXiv preprint arXiv:2505.20275, 2025
Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. Imgedit: A unified image editing dataset and benchmark.arXiv preprint arXiv:2505.20275, 2025
Pith/arXiv arXiv 2025
-
[25]
Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278–25294, 2022
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278–25294, 2022. 15 Scaling Multi-Reference Image G...
2022
-
[26]
Less-to-more gen- eralization: Unlocking more controllability by in-context generation
Shaojin Wu, Mengqi Huang, Wenxu Wu, Yufeng Cheng, Fei Ding, and Qian He. Less-to-more gen- eralization: Unlocking more controllability by in-context generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18682–18692, 2025
2025
-
[27]
Objects365: A large-scale, high-quality dataset for object detection
Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. Objects365: A large-scale, high-quality dataset for object detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 8430–8439, 2019
2019
-
[28]
Deepseek-v3technicalreport.arXivpreprintarXiv:2412.19437, 2024
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng,ChenyuZhang,ChongRuan,etal. Deepseek-v3technicalreport.arXivpreprintarXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[29]
Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
Pith/arXiv arXiv 2023
-
[30]
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection.arXiv preprint arXiv:2303.05499, 2023
Pith/arXiv arXiv 2023
-
[31]
Sam 2: Segment anything in images and videos, 2024
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, and Christoph Feichtenhofer. Sam 2: Segment anything in images and videos, 2024. URLhttps://arxiv.org/a...
Pith/arXiv arXiv 2024
-
[32]
Omniconsistency: Learning style-agnostic consis- tency from paired stylization data
Yiren Song, Cheng Liu, and Mike Zheng Shou. Omniconsistency: Learning style-agnostic consis- tency from paired stylization data. 2025. URLhttps://api.semanticscholar.org/CorpusID: 278905729
2025
-
[33]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[34]
Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[35]
Measuring style similarity in diffusion models.arXiv preprint arXiv:2404.01292, 2024
Gowthami Somepalli, Anubhav Gupta, Kamal Gupta, Shramay Palta, Micah Goldblum, Jonas Geiping, Abhinav Shrivastava, and Tom Goldstein. Measuring style similarity in diffusion models.arXiv preprint arXiv:2404.01292, 2024
arXiv 2024
-
[36]
Vbench: Comprehensive benchmark suite for video generativemodels
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generativemodels. InProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecognition, pages 21807–21818, 2024
2024
-
[37]
Monocular human pose estimation: A survey of deep learning-based methods.Computer vision and image understanding, 192:102897, 2020
Yucheng Chen, Yingli Tian, and Mingyi He. Monocular human pose estimation: A survey of deep learning-based methods.Computer vision and image understanding, 192:102897, 2020
2020
-
[38]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022. 16 Scaling Multi-Reference Image Generation with Dynamic Reward Optimization (ECCV2026)
2022
-
[39]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[40]
Flow-grpo: Trainingflowmatchingmodelsviaonlinerl.arXivpreprintarXiv:2505.05470, 2025
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and WanliOuyang. Flow-grpo: Trainingflowmatchingmodelsviaonlinerl.arXivpreprintarXiv:2505.05470, 2025
Pith/arXiv arXiv 2025
-
[42]
URLhttps://arxiv.org/abs/2602.12529
-
[43]
Shaojin Wu, Mengqi Huang, Yufeng Cheng, Wenxu Wu, Jiahe Tian, Yiming Luo, Fei Ding, and Qian He. Uso: Unified style and subject-driven generation via disentangled and reward learning.arXiv preprint arXiv:2508.18966, 2025
arXiv 2025
-
[44]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features. arXiv preprint arXiv:2502.14786, 2025
Pith/arXiv arXiv 2025
-
[45]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. InProceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017
2017
-
[46]
Yufeng Cheng, Wenxu Wu, Shaojin Wu, Mengqi Huang, Fei Ding, and Qian He. Umo: Scaling multi- identity consistency for image customization via matching reward.arXiv preprint arXiv:2509.06818, 2025
arXiv 2025
-
[47]
Dong She, Siming Fu, Mushui Liu, Qiaoqiao Jin, Hualiang Wang, Mu Liu, and Jidong Jiang. Mosaic: Multi-subject personalized generation via correspondence-aware alignment and disentanglement.arXiv preprint arXiv:2509.01977, 2025
arXiv 2025
-
[48]
Null-text inversion for editing real images using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6038–6047, 2023
2023
-
[49]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023
2023
-
[50]
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721, 2023
Pith/arXiv arXiv 2023
-
[51]
Zechuan Zhang, Ji Xie, Yu Lu, Zongxin Yang, and Yi Yang. In-context edit: Enabling instructional image editing with in-context generation in large scale diffusion transformer.arXiv preprint arXiv:2504.20690, 2025
Pith/arXiv arXiv 2025
-
[52]
Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025. 17 Scaling Multi-Reference Image Generation with Dynamic Reward Optimization (ECCV2026)
Pith/arXiv arXiv 2025
-
[53]
Unireal: Universal image generation and editing via learning real- world dynamics
Xi Chen, Zhifei Zhang, He Zhang, Yuqian Zhou, Soo Ye Kim, Qing Liu, Yijun Li, Jianming Zhang, Nanxuan Zhao, Yilin Wang, et al. Unireal: Universal image generation and editing via learning real- world dynamics. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12501–12511, 2025
2025
-
[54]
Qiaoqiao Jin, Siming Fu, Dong She, Weinan Jia, Hualiang Wang, Mu Liu, and Jidong Jiang. Focusdpo: Dynamic preference optimization for multi-subject personalized image generation via adaptive focus. arXiv preprint arXiv:2509.01181, 2025
arXiv 2025
-
[55]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[56]
Hongyang Wei, Baixin Xu, Hongbo Liu, Size Wu, Jie Liu, Yi Peng, Peiyu Wang, Zexiang Liu, Jingwen He, Yidan Xietian, et al. Skywork unipic 2.0: Building kontext model with online rl for unified multimodal model.arXiv preprint arXiv:2509.04548, 2025
arXiv 2025
-
[57]
Alphapose: Whole-body regional multi-person pose estimation and tracking in real-time.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022
Hao-Shu Fang, Jiefeng Li, Hongyang Tang, Chao Xu, Haoyi Zhu, Yuliang Xiu, Yong-Lu Li, and Cewu Lu. Alphapose: Whole-body regional multi-person pose estimation and tracking in real-time.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022
2022
-
[58]
Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Pith/arXiv arXiv 2017
-
[59]
Adam: A method for stochastic optimization.(No Title), 2014
Kingma Diederik. Adam: A method for stochastic optimization.(No Title), 2014
2014
-
[60]
Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chiang Frank Wang, Kwang-Ting Cheng, et al. Gdpo: Group reward-decoupled normalization policy optimization for multi-reward rl optimization.arXiv preprint arXiv:2601.05242, 2026
Pith/arXiv arXiv 2026
-
[61]
Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, JunTang, HumenZhong, YuanzhiZhu, MingkunYang, ZhaohaiLi, JianqiangWan, PengfeiWang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report.arXiv pre...
Pith/arXiv arXiv 2025
-
[62]
Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
Pith/arXiv arXiv 2013
-
[63]
Omnigen: Unified image generation
Shitao Xiao, Yueze Wang, Junjie Zhou, Huaying Yuan, Xingrun Xing, Ruiran Yan, Chaofan Li, Shuting Wang, Tiejun Huang, and Zheng Liu. Omnigen: Unified image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13294–13304, 2025
2025
-
[64]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[65]
using the scene of image X as background
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024. 18 Scaling Multi-Reference Image Generation with Dynamic Reward Optimization (ECCV2026) Appendix Overview This material provides supplementary details to the main paper, including the following sections: A Related Work. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ...
2024
-
[66]
You will be given an<asset category> , you need to create an asset (brief subject prompt) based on the <asset category>
-
[67]
Elon Musk in pajamas
These descriptions can refer only to appearance descriptions/or to certain brands. e.g., “Elon Musk in pajamas”, “a tiger in a black hat”, “A Mercedes sports car”, “A blonde”, “A door red on the left and green on the right”
-
[68]
Avoid adding separate accessories or objects
Focus on the given<asset category>ONLY. Avoid adding separate accessories or objects
-
[69]
Do not repeat each asset, you need to use your logic and common sense of life to create
-
[70]
love and power
No more than 12 words for each asset. Example [asset category]:Book Output: [asset1]:A book with a green cover [asset2]:comic book [asset3]:math book [asset4]:An open book [asset5]:Rotten books [asset6]:The book with “love and power” on the cover [asset7]:A book with a blue key on it ... (Up to[asset20]) User: [asset category]:{category} Figure 18:System ...
-
[71]
Merge and prioritize attributes across all subjects; resolve conflicts logically
-
[72]
secondary)
Clarify relationships, composition, and focal hierarchy (primary subject vs. secondary)
-
[73]
Add tasteful art direction: lighting, environment, background, camera, lens, shot type, color palette, mood, time of day, material details, and post-processing
-
[74]
Preserve each subject’s core identity; distribute attributes sensibly (don’t duplicate or contradict)
-
[75]
For each person subject, specify adiversifiedpose ranging from static to dynamic (e.g., sitting with legs crossed, jumping with arms outstretched)
-
[76]
A woman with neon pink hair
Input format: •subject_phrases: a list of short noun phrases describing subjects or objects. •variants: number of alternative prompts to produce (default: 1). Output format:Produce exactly N variants (N = variants). For each variant, output a single cohesive prompt ready for a text-to-image model. Output requirements:Return ONLY the prompt text itself. Ex...
-
[77]
Scoring(0–10,Conservative Scoring): •0: Completely irrelevant to the text prompt, or completely ignores the core reference requirement
A failure to match a Reference Image (Style, Subject, Background, Lighting) should result in a score lower than 6. Scoring(0–10,Conservative Scoring): •0: Completely irrelevant to the text prompt, or completely ignores the core reference requirement. •2: The main subject is present, but the content or reference requirement is seriously violated. • 4: The ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.