Hallucination as Context Drift: Synchronization Protocols for Multi-Agent LLM Systems
Pith reviewed 2026-06-26 14:00 UTC · model grok-4.3
The pith
Context drift between agents drives hallucinations in multi-agent LLM systems, and a verification protocol using compressed state summaries reduces them without the contamination seen in full broadcast.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
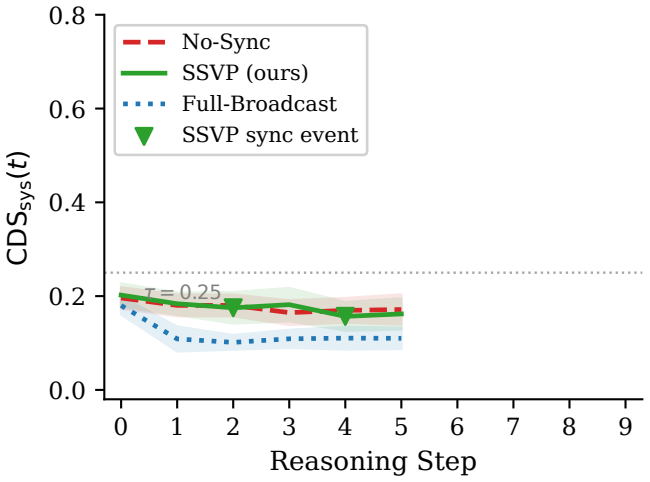
Hallucination in multi-agent LLM systems frequently results from divergence of knowledge states across agents; the Shared State Verification Protocol enables periodic exchange of compressed state summaries to detect high-divergence pairs before joint reasoning, delivering lower hallucination rates than full-broadcast synchronization, avoiding error contamination, and requiring 58% fewer API calls.
What carries the argument
Shared State Verification Protocol (SSVP) that computes Context Divergence Score (CDS) on agent pairs to flag mismatched states before collaborative reasoning.
If this is right
- Naive full-broadcast synchronization raises hallucination rate by 34% above baseline through propagation of erroneous states.
- SSVP produces lower hallucination than full broadcast at p=0.0005 while using 58% fewer API calls.
- The contamination effect from full broadcast appears only in domains where one wrong shared belief cascades across evaluation dimensions.
- Context synchronization should be treated as a core design primitive for multi-agent LLM systems.
Where Pith is reading between the lines
- The same divergence measurement could be applied to detect drift in longer-running or open-ended agent interactions.
- Hierarchical or selective verification rules might further reduce calls while preserving the benefits shown for SSVP.
- Tasks with high inter-agent dependency may benefit most from early divergence checks before any joint output is generated.
Load-bearing premise
That measured differences in hallucination rates between synchronization conditions are caused by context drift rather than other variables in prompting, model behavior, or evaluation.
What would settle it
An experiment that forces all agents to maintain identical internal states throughout the task and still records high hallucination rates would show context drift is not required for the observed failures.
Figures
read the original abstract
Multi-agent LLM systems routinely produce hallucinated outputs that cannot be explained by model deficiencies alone. A significant class of these failures arises not from model incapacity but from context drift: the divergence of internal knowledge states between concurrent agents. When agents enter a collaborative task with mismatched or stale representations of shared world state, their joint reasoning produces contradictions that manifest as hallucination. We define the Context Divergence Score (CDS), a lightweight scalar metric quantifying knowledge-state discrepancy between agent pairs across spatial, temporal, and task dimensions, and propose the Shared State Verification Protocol (SSVP), which lets agents periodically exchange compressed state summaries and flag high-divergence conditions before joint reasoning. We evaluate SSVP across two domains (multi-agent travel and software project planning) using Claude Haiku. In controlled experiments (n=30 per condition, travel; n=10, software) across 8 scenarios, naive full-broadcast synchronization increases hallucination rate by 34% above the no-sync baseline (HR: 0.658 vs. 0.492, p=0.0022, d=1.18), a contamination effect from propagating erroneous agent states. SSVP avoids this failure mode while showing modest, consistent reduction (HR: 0.463, d=0.30) and achieves significantly lower hallucination than full-broadcast (p=0.0005, d=1.47) using 58% fewer API calls. The contamination effect does not replicate in the software domain, where all conditions converge to low HR (<0.2), confirming it is specific to tasks where one erroneous shared belief cascades across evaluation dimensions. Our results reframe hallucination mitigation as a distributed systems problem and establish context synchronization as a first-class primitive in multi-agent LLM design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that hallucinations in multi-agent LLM systems frequently result from context drift (divergence of internal knowledge states between agents) rather than model deficiencies alone. It introduces the Context Divergence Score (CDS) as a scalar metric for knowledge-state discrepancy across spatial, temporal, and task dimensions, and the Shared State Verification Protocol (SSVP) for periodic exchange of compressed state summaries to flag high-divergence conditions. Controlled experiments (n=30 per condition in travel planning; n=10 in software planning) with Claude Haiku across 8 scenarios show that naive full-broadcast synchronization increases hallucination rate (HR) by 34% over baseline (0.658 vs. 0.492), while SSVP achieves lower HR (0.463) with 58% fewer API calls and avoids the contamination effect; the effect does not replicate in the software domain.
Significance. If the attribution to context drift holds and the protocols are reproducible, the work offers a distributed-systems reframing of hallucination mitigation and positions context synchronization as a first-class primitive for multi-agent LLM design. The use of effect sizes, p-values, and domain-specific replication adds value over purely qualitative claims. The absence of CDS definition, annotation protocol, and raw data, however, prevents immediate assessment of whether the quantitative results (p=0.0005, d=1.47) isolate the proposed mechanism.
major comments (3)
- [Abstract and §3 (method)] Abstract and §3 (method): The manuscript references but does not supply the definition or computation details for the Context Divergence Score (CDS), including how discrepancy is quantified across the three dimensions or how state summaries are compressed; without this, the link between CDS and the reported HR reductions cannot be verified or replicated.
- [Abstract and Experimental Setup] Abstract and Experimental Setup: Hallucination rates are reported with p-values and effect sizes (HR: 0.658 vs. 0.492 vs. 0.463; p=0.0005, d=1.47) but no annotation protocol, inter-rater reliability, or controls for prompt phrasing, temperature, or role instructions are described, so the central claim that differences arise specifically from context drift (rather than uncontrolled prompting/evaluation factors) cannot be evaluated.
- [Results] Results: The domain-specific replication failure (contamination absent in software planning) is presented as evidence that the effect is task-dependent, yet without raw data, full scenario descriptions, or the exact evaluation dimensions, it is impossible to determine whether this supports the mechanism or reflects scoring confounds.
minor comments (2)
- [Abstract] The abstract states n=30/10 per condition but does not clarify whether these are independent runs or scenarios; adding this would improve clarity.
- Notation for CDS and SSVP is introduced without an initial equation or pseudocode block; a compact formal definition would aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important issues for reproducibility. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and §3 (method)] Abstract and §3 (method): The manuscript references but does not supply the definition or computation details for the Context Divergence Score (CDS), including how discrepancy is quantified across the three dimensions or how state summaries are compressed; without this, the link between CDS and the reported HR reductions cannot be verified or replicated.
Authors: We agree that the CDS definition and computation details were insufficiently elaborated in the original submission. The revised manuscript will include a complete specification of the CDS formula, explicitly detailing the quantification of discrepancies in spatial, temporal, and task dimensions, along with the compression method for state summaries. This addition will directly enable verification of the connection to the observed hallucination rate reductions. revision: yes
-
Referee: [Abstract and Experimental Setup] Abstract and Experimental Setup: Hallucination rates are reported with p-values and effect sizes (HR: 0.658 vs. 0.492 vs. 0.463; p=0.0005, d=1.47) but no annotation protocol, inter-rater reliability, or controls for prompt phrasing, temperature, or role instructions are described, so the central claim that differences arise specifically from context drift (rather than uncontrolled prompting/evaluation factors) cannot be evaluated.
Authors: The annotation was performed using a predefined protocol based on identifying factual inconsistencies with the provided ground-truth scenario descriptions. We used a single annotator with repeated self-consistency checks rather than multiple raters, which is why inter-rater reliability was not reported. Temperature was fixed at 0.7, and role instructions were standardized across conditions. We will add a new subsection to the Experimental Setup detailing the full annotation protocol, controls for prompt phrasing, temperature settings, and role instructions to allow evaluation of whether the differences are attributable to context drift. revision: yes
-
Referee: [Results] Results: The domain-specific replication failure (contamination absent in software planning) is presented as evidence that the effect is task-dependent, yet without raw data, full scenario descriptions, or the exact evaluation dimensions, it is impossible to determine whether this supports the mechanism or reflects scoring confounds.
Authors: We will expand the Results and Appendix sections to include full scenario descriptions, the exact evaluation dimensions used for hallucination scoring, and additional analysis explaining the task-dependency. For raw data, the full logs are voluminous; we will release anonymized aggregated results and key excerpts in a supplementary repository linked in the revised paper. This should allow assessment of whether the replication failure supports the proposed mechanism. revision: partial
Circularity Check
No circularity: definitions and empirical evaluation are independent
full rationale
The paper introduces CDS and SSVP as explicit definitions of context divergence and a synchronization protocol, then reports separate experimental measurements of hallucination rates across domains with no equations, fitted parameters, or predictions that reduce to those definitions by construction. No self-citations, uniqueness theorems, or ansatzes appear in the provided text, and the central claims rest on controlled comparisons (n=30/10, p-values) rather than any load-bearing reduction to inputs. The derivation chain is therefore self-contained as a definitional-plus-empirical structure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A significant class of hallucinations arises from context drift between agents rather than model incapacity.
invented entities (2)
-
Context Divergence Score (CDS)
no independent evidence
-
Shared State Verification Protocol (SSVP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Le and Denny Zhou , title =
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Brian Ichter and Fei Xia and Ed Chi and Quoc V. Le and Denny Zhou , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[2]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Long Ouyang and Jeffrey Wu and Xu Jiang and Diogo Almeida and Carroll Wainwright and Pamela Mishkin and Chong Zhang and Sandhini Agarwal and Katarina Slama and Alex Ray and others , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[4]
Proceedings of the Conference on Language Modeling (COLM) , year =
Qingyun Wu and Gagan Bansal and Jieyu Zhang and Yiran Wu and Beibin Li and Erkang Zhu and Li Jiang and Xiaoyun Zhang and Shaokun Zhang and Jiale Liu and others , title =. Proceedings of the Conference on Language Modeling (COLM) , year =
-
[5]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Sirui Hong and Mingchen Zhuge and Jonathan Chen and Xiawu Zheng and Yuheng Cheng and Ceyao Zhang and Jinlin Wang and Zili Wang and Steven Ka Shing Yau and Zijuan Lin and others , title =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[6]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Weize Chen and Yusheng Su and Jingwei Zuo and Cheng Yang and Chenfei Yuan and Chi-Min Chan and Heyang Yu and Yaxi Lu and Yi-Hsin Hung and Chen Qian and others , title =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[7]
O'Brien and Carrie Jun Cai and Meredith Ringel Morris and Percy Liang and Michael S
Joon Sung Park and Joseph C. O'Brien and Carrie Jun Cai and Meredith Ringel Morris and Percy Liang and Michael S. Bernstein , title =. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST) , pages =
-
[8]
Ashley and Ruslan Shu
Mingchen Zhuge and Haozhe Liu and Francesco Faccio and Dylan R. Ashley and Ruslan Shu. Mindstorms in Natural Language-Based Societies of Mind , journal =
-
[9]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
Joshua Maynez and Shashi Narayan and Bernd Bohnet and Ryan McDonald , title =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
-
[10]
Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , pages =
Vikas Raunak and Arul Menezes and Marcin Junczys-Dowmunt , title =. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , pages =
2021
-
[11]
Potsawee Manakul and Adian Liusie and Mark J. F. Gales , title =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
2023
-
[12]
Retrieval-Augmented Generation for Knowledge-Intensive
Patrick Lewis and Ethan Perez and Aleksandra Piktus and Fabio Petroni and Vladimir Karpukhin and Naman Goyal and Heinrich K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[13]
Le and Ed H
Xuezhi Wang and Jason Wei and Dale Schuurmans and Quoc V. Le and Ed H. Chi and Sharan Narang and Aakanksha Chowdhery and Denny Zhou , title =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[14]
Advances in Neural Information Processing Systems (NeurIPS) Workshop on Trustworthy and Socially Responsible Machine Learning , year =
Saurav Kadavath and Tom Conerly and Amanda Askell and Tom Henighan and Dawn Drain and Ethan Perez and Nicholas Schiefer and Zac Hatfield-Dodds and Nova DasSarma and Eli Tran-Johnson and others , title =. Advances in Neural Information Processing Systems (NeurIPS) Workshop on Trustworthy and Socially Responsible Machine Learning , year =
-
[15]
Communications of the ACM , volume =
Leslie Lamport , title =. Communications of the ACM , volume =
-
[16]
Friedemann Mattern , title =
-
[17]
Proceedings of the 19th Annual ACM Symposium on Principles of Distributed Computing (PODC) , pages =
Eric Brewer , title =. Proceedings of the 19th Annual ACM Symposium on Principles of Distributed Computing (PODC) , pages =
-
[18]
Collaborative Multi-Robot Search and Rescue: Planning, Coordination, Perception, and Active Vision , journal =
Jorge Pe. Collaborative Multi-Robot Search and Rescue: Planning, Coordination, Perception, and Active Vision , journal =
-
[19]
Liu and Kevin Lin and John Hewitt and Ashwin Paranjape and Michele Bevilacqua and Fabio Petroni and Percy Liang , title =
Nelson F. Liu and Kevin Lin and John Hewitt and Ashwin Paranjape and Michele Bevilacqua and Fabio Petroni and Percy Liang , title =. Transactions of the Association for Computational Linguistics , volume =
-
[20]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Wanjun Zhong and Lianghong Guo and Qiqi Gao and He Ye and Yanlin Wang , title =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
-
[21]
ACM Transactions on Programming Languages and Systems , volume =
Leslie Lamport and Robert Shostak and Marshall Pease , title =. ACM Transactions on Programming Languages and Systems , volume =
-
[23]
Tenenbaum and Igor Mordatch , title =
Yilun Du and Shuang Li and Antonio Torralba and Joshua B. Tenenbaum and Igor Mordatch , title =. Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
-
[29]
Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems (NeurIPS), volume 35, pages 24824--24837, 2022
2022
-
[30]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems (NeurIPS), volume 35, pages 27730--27744, 2022
2022
-
[31]
Constitutional AI : Harmlessness from AI feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional AI : Harmlessness from AI feedback. arXiv preprint arXiv:2212.08073, 2022
Pith/arXiv arXiv 2022
-
[32]
O'Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S
Joon Sung Park, Joseph C. O'Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST), pages 1--22, 2023
2023
-
[33]
AutoGen : Enabling next-gen LLM applications via multi-agent conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. AutoGen : Enabling next-gen LLM applications via multi-agent conversation. In Proceedings of the Conference on Language Modeling (COLM), 2024. arXiv:2308.08155
Pith/arXiv arXiv 2024
-
[34]
MetaGPT : Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. MetaGPT : Meta programming for a multi-agent collaborative framework. In Proceedings of the International Conference on Learning Representations (ICLR), 2024
2024
-
[35]
LangGraph : Building stateful, multi-actor applications with LLM s
LangChain Team . LangGraph : Building stateful, multi-actor applications with LLM s. https://github.com/langchain-ai/langgraph, 2023
2023
-
[36]
CrewAI : Framework for orchestrating role-playing autonomous AI agents
Jo \ a o Moura. CrewAI : Framework for orchestrating role-playing autonomous AI agents. https://github.com/joaomdmoura/crewAI, 2023
2023
-
[37]
AgentVerse : Facilitating multi-agent collaboration and exploring emergent behaviors
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, et al. AgentVerse : Facilitating multi-agent collaboration and exploring emergent behaviors. In Proceedings of the International Conference on Learning Representations (ICLR), 2024
2024
-
[38]
Ashley, Ruslan Shu s ter, Jonas Bayer, and Jürgen Schmidhuber
Mingchen Zhuge, Haozhe Liu, Francesco Faccio, Dylan R. Ashley, Ruslan Shu s ter, Jonas Bayer, and Jürgen Schmidhuber. Mindstorms in natural language-based societies of mind. arXiv preprint arXiv:2305.17066, 2023
arXiv 2023
-
[39]
Mert Cemri, Melissa Z. Pan, Shuyi Yang, Lakshya A. Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, Matei Zaharia, Joseph E. Gonzalez, and Shishir G. Patil. Why do multi-agent LLM systems fail? arXiv preprint arXiv:2503.13657, 2025. NeurIPS 2025 Datasets and Benchmarks Track
Pith/arXiv arXiv 2025
-
[40]
u ttler, Mike Lewis, Wen tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen tau Yih, Tim Rockt \"a schel, et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems (NeurIPS), volume 33, pages 9459--9474, 2020
2020
-
[41]
Le, Ed H
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. In Proceedings of the International Conference on Learning Representations (ICLR), 2023
2023
-
[42]
Language models (mostly) know what they know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know. In Advances in Neural Information Processing Systems (NeurIPS) Workshop on Trustworthy and Socially Responsible Machine Learning, 2022
2022
-
[43]
Tenenbaum, and Igor Mordatch
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. In Proceedings of the 41st International Conference on Machine Learning (ICML), 2024
2024
-
[44]
AgentHallu : Benchmarking automated hallucination attribution of LLM -based agents
Xuannan Liu, Xiao Yang, Zekun Li, Peipei Li, and Ran He. AgentHallu : Benchmarking automated hallucination attribution of LLM -based agents. arXiv preprint arXiv:2601.06818, 2026
arXiv 2026
-
[45]
LLM -based agents suffer from hallucinations: A survey of taxonomy, methods, and directions
Xixun Lin, Yucheng Ning, Jingwen Zhang, Yan Dong, Yilong Liu, Yongxuan Wu, Xiaohua Qi, Nan Sun, Yanmin Shang, Kun Wang, Pengfei Cao, Qingyue Wang, Lixin Zou, Xu Chen, Chuan Zhou, Jia Wu, Peng Zhang, Qingsong Wen, Shirui Pan, Bin Wang, Yanan Cao, Kai Chen, Songlin Hu, and Li Guo. LLM -based agents suffer from hallucinations: A survey of taxonomy, methods, ...
arXiv 2025
-
[46]
Time, clocks, and the ordering of events in a distributed system
Leslie Lamport. Time, clocks, and the ordering of events in a distributed system. Communications of the ACM, 21 0 (7): 0 558--565, 1978
1978
-
[47]
Virtual time and global states of distributed systems
Friedemann Mattern. Virtual time and global states of distributed systems. Technical report, Department of Computer Science, University of Kaiserslautern, 1988
1988
-
[48]
Towards robust distributed systems (keynote)
Eric Brewer. Towards robust distributed systems (keynote). In Proceedings of the 19th Annual ACM Symposium on Principles of Distributed Computing (PODC), page 7, 2000
2000
-
[49]
Collaborative multi-robot search and rescue: Planning, coordination, perception, and active vision
Jorge Pe \ n a Queralta, Jussi Taipalmaa, Bilge Can Pullinen, Victor Kathan Sarker, Tuan Nguyen Gia, Hannu Tenhunen, Moncef Gabbouj, Jenni Raitoharju, and Tomi Westerlund. Collaborative multi-robot search and rescue: Planning, coordination, perception, and active vision. volume 8, pages 191617--191643, 2020
2020
-
[50]
Abhishek Rath. Agent drift: Quantifying behavioral degradation in multi-agent LLM systems over extended interactions. arXiv preprint arXiv:2601.04170, 2026
arXiv 2026
-
[51]
Rossi, Viet Dac Lai, David Seunghyun Yoon, Dilek Hakkani-T \"u r, and Trung Bui
Vardhan Dongre, Ryan A. Rossi, Viet Dac Lai, David Seunghyun Yoon, Dilek Hakkani-T \"u r, and Trung Bui. Drift no more? context equilibria in multi-turn LLM interactions. arXiv preprint arXiv:2510.07777, 2025
arXiv 2025
-
[52]
MemoryBank : Enhancing large language models with long-term memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. MemoryBank : Enhancing large language models with long-term memory. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19724--19731, 2024
2024
-
[53]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12: 0 157--173, 2024
2024
-
[54]
The byzantine generals problem
Leslie Lamport, Robert Shostak, and Marshall Pease. The byzantine generals problem. ACM Transactions on Programming Languages and Systems, 4 0 (3): 0 382--401, 1982
1982
-
[55]
Jen tse Huang, Jiaxu Zhou, Tailin Jin, Xuhui Zhou, Zixi Chen, Wenxuan Wang, Youliang Yuan, Michael R. Lyu, and Maarten Sap. On the resilience of LLM -based multi-agent collaboration with faulty agents. arXiv preprint arXiv:2408.00989, 2024
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.