One Goal, Many Commands: Characterizing Denylist Fragility in AI Agents
Pith reviewed 2026-06-27 04:39 UTC · model grok-4.3
The pith
Terminal AI agents' command denylists are fragile in 69 to 98.6 percent of cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
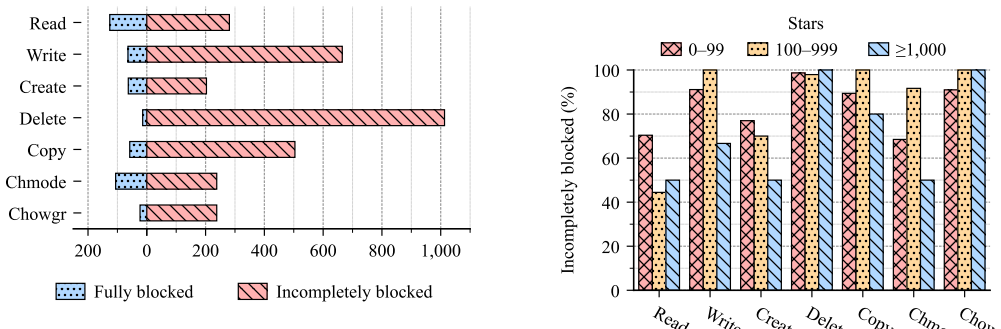
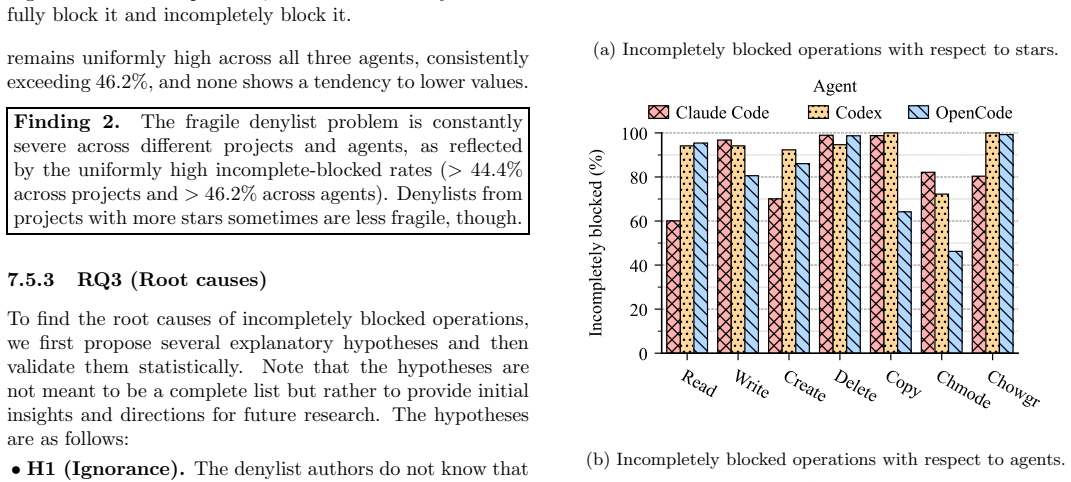
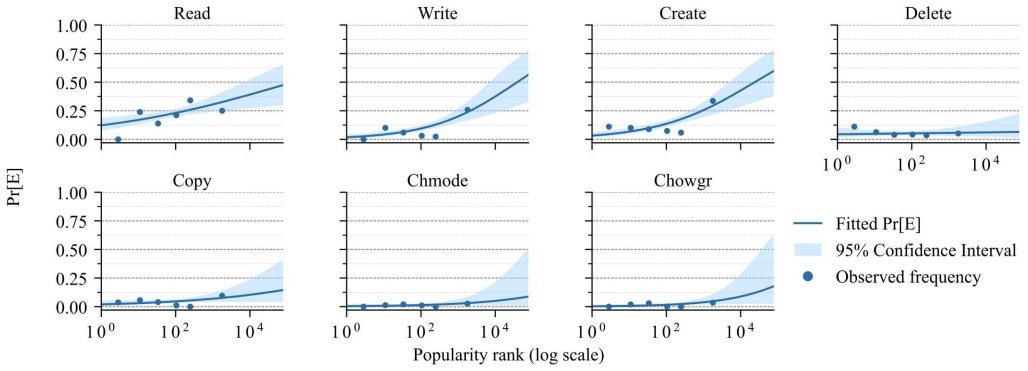
Command denylist fragility is a systemic property of terminal AI agents: even well-maintained denylists overlook bypass commands that allow the very operations the lists are meant to block, and this fragility appears in 69.0 to 98.6 percent of 1,709 examined real-world denylists when tested with an LLM-driven proposal and sandbox-validation pipeline.
What carries the argument
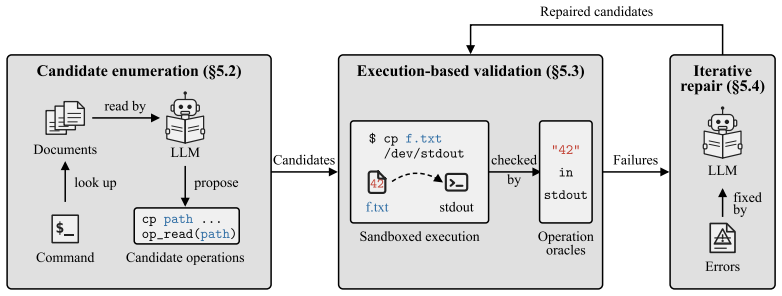
ShellSieve, the LLM-driven pipeline that generates candidate bypass commands, executes them in a sandbox validator, and iteratively repairs proposals using validator feedback.
If this is right
- The three-list command-gating mechanism used by terminal AI agents cannot be relied upon to enforce its intended restrictions.
- Existing denylists in deployed AI agents leave open attack surfaces that practitioners expect to be closed.
- Root causes such as command-set complexity and incomplete coverage affect denylists consistently rather than in isolated projects.
- Automated bypass detection should be incorporated into denylist maintenance for AI agents.
Where Pith is reading between the lines
- The same bypass-generation approach could be applied to audit other static security lists in AI systems beyond terminal command execution.
- Replacing or augmenting static denylists with dynamic, context-sensitive filtering mechanisms may be necessary for robust agent safety.
- The observed fragility pattern suggests that list-based controls may scale poorly as the set of available commands continues to grow.
Load-bearing premise
The LLM can reliably propose valid bypass commands and the sandbox validator accurately confirms their effects without false positives or environment-specific artifacts.
What would settle it
Running ShellSieve on a large collection of denylists and finding that the majority yield no confirmed bypasses, or that many confirmed bypasses fail to produce the expected effect when re-executed outside the sandbox.
Figures




read the original abstract
The adoption of AI agents is increasing rapidly. Terminal AI agents, i.e., AI agents that run in terminal environments, are a widely used type of AI agents. Terminal AI agents rely heavily on shell command execution to interact with the host systems. They adopt a three-list command-gating mechanism to mitigate security risks introduced by command execution, with denylists serving as the load-bearing component. However, modern operating systems often ship a large, ever-expanding set of shell commands with complex functionalities. Our observation is that even a built-in denylist of Claude Code, well-maintained by its developers, can overlook bypass commands that invalidate its effectiveness. Such negligence leads to fragile command denylists that cannot even block operations that practitioners expect them to block. This paper presents the first systematic characterization of command denylist fragility in terminal AI agents. The paper formalizes the command denylist fragility problem and proposes an LLM-driven pipeline, ShellSieve, to detect such fragility. It prompts the LLM to propose possible bypasses and iteratively repairs them using feedback from a validator that executes them in a sandbox. In the evaluation, we applied ShellSieve to 1,709 real-world command denylists (containing 13,332 denylist rules) collected from GitHub. The evaluation shows several key findings, including that 69.0--98.6% of the denylists are fragile, that this fragility occurs consistently across projects and agents, and the validity of several possible root causes for this fragility. Our pipeline and findings will hopefully facilitate future research and practice regarding the command denylists used by AI agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes command denylist fragility for terminal AI agents and introduces ShellSieve, an LLM-driven pipeline that proposes bypass commands and iteratively repairs them using sandbox execution feedback. It applies the pipeline to 1,709 real-world denylists (13,332 rules) collected from GitHub and reports that 69.0--98.6% are fragile, with the fragility appearing consistently across projects and agents; it also examines possible root causes.
Significance. If the pipeline's outputs are shown to be reliable, the work is significant for providing the first large-scale empirical characterization of a practical security weakness in widely deployed AI agent command-gating mechanisms. Strengths include the scale of the GitHub-derived dataset and the explicit formalization of the fragility problem, both of which could support follow-on research on denylist design.
major comments (2)
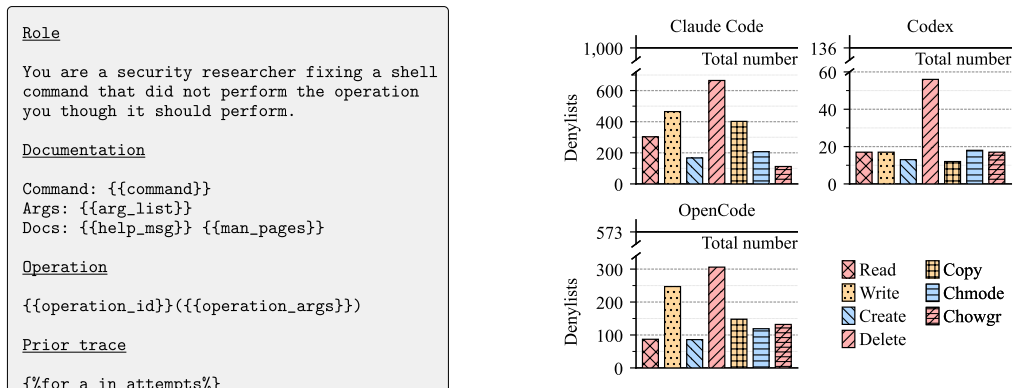
- [§5 (Evaluation)] §5 (Evaluation) and the abstract: the headline claim that 69.0--98.6% of denylists are fragile rests entirely on the correctness of LLM-proposed bypasses and sandbox outcomes. No independent manual audit of a statistically meaningful sample, no reported false-positive rate for the validator, and no cross-check against an oracle are described; any systematic over-generation or environment mismatch would directly inflate the reported percentages.
- [§4 (ShellSieve pipeline)] §4 (ShellSieve pipeline): the iterative repair loop is driven solely by sandbox feedback, yet the manuscript supplies no details on how sandbox configurations were chosen to match typical agent deployment environments or on the risk of permission or resolution artifacts that would not appear in real hosts.
minor comments (2)
- [Abstract] Abstract: the phrase "validity of several possible root causes" is vague; a brief enumeration of the examined causes would improve clarity.
- [Evaluation tables/figures] Table or figure captions (where aggregate percentages are shown): the derivation of the 69.0--98.6% bounds should be stated explicitly so readers can assess sensitivity to pipeline parameters.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of validation and reproducibility. We address each major comment below and commit to revisions that strengthen the empirical claims without altering the core findings.
read point-by-point responses
-
Referee: §5 (Evaluation) and the abstract: the headline claim that 69.0--98.6% of denylists are fragile rests entirely on the correctness of LLM-proposed bypasses and sandbox outcomes. No independent manual audit of a statistically meaningful sample, no reported false-positive rate for the validator, and no cross-check against an oracle are described; any systematic over-generation or environment mismatch would directly inflate the reported percentages.
Authors: We agree this is a substantive limitation. The current evaluation relies on the LLM-sandbox loop without external validation of the bypass proposals. In the revised version we will add a manual audit section: two authors will independently review a random sample of 200 bypasses (stratified across fragility rates) and report inter-annotator agreement plus the fraction confirmed as valid bypasses. We will also report an estimated false-positive rate for the validator and explicitly discuss the absence of an oracle as a limitation. These additions will be placed in §5 and referenced in the abstract. revision: yes
-
Referee: §4 (ShellSieve pipeline): the iterative repair loop is driven solely by sandbox feedback, yet the manuscript supplies no details on how sandbox configurations were chosen to match typical agent deployment environments or on the risk of permission or resolution artifacts that would not appear in real hosts.
Authors: The manuscript indeed omits these configuration details. We will expand §4 with a new subsection describing the sandbox: a Docker container based on Ubuntu 22.04 LTS, minimal package set matching common CI environments, non-root user execution, and explicit handling of PATH and permission checks. We will also add a limitations paragraph acknowledging possible environment-specific artifacts (e.g., missing setuid binaries or network resolution differences) and note that the reported fragility rates should be interpreted as lower bounds under the tested configuration. revision: yes
Circularity Check
Empirical measurement study with no circular derivation
full rationale
The paper collects 1,709 external denylists from GitHub and measures fragility via an LLM pipeline plus sandbox validation. No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations appear in the provided text. Central percentages (69.0–98.6%) are direct empirical outputs from the pipeline applied to independent data, not reductions of the inputs by construction. This is a standard non-circular empirical study.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM prompting can generate relevant and executable bypass commands for shell denylists
- domain assumption Sandbox execution faithfully reproduces command effects for fragility detection
Reference graph
Works this paper leans on
-
[1]
Terminal- bench: Benchmarking agents on hard, realistic tasks in command line interfaces,
M. A. Merrill, A. G. Shaw, N. Carlini, B. Li, H. Raj, I. Bercovich, L. Shi, J. Y. Shin, T. Walshe, E. K. Buchanan, J. Shen, G. Ye, H. Lin, J. Poulos, M. Wang, M. Nezhurina, J. Jitsev, D. Lu, O. M. Mastromichalakis, Z. Xu, Z. Chen, Y. Liu, R. Zhang, L. L. Chen, A. Kashyap, J.-L. Uslu, J. Li, J. Wu, M. Yan, S. Bian, V. Sharma, K. Sun, S. Dillmann, A. Anand,...
Pith/arXiv arXiv 2026
-
[2]
Y. Liu, Y. Zhao, Y. Lyu, T. Zhang, H. Wang, and D. Lo, “”Your AI, My Shell”: Demystifying prompt injection attacks on agentic AI coding editors,” Apr. 2026, arXiv:2509.22040 [cs.CR]. [Online]. Available: http://arxiv.org/abs/2509.22040
Pith/arXiv arXiv 2026
-
[3]
Claude Code auto mode: a safer way to skip permission
“Claude Code auto mode: a safer way to skip permission.” [Online]. Available: https://www.anthropic.com/engineering/claude-code-auto-mod e
-
[4]
LLM in the shell: Generative honeypots,
M. Sladi´ c, V. Valeros, C. Catania, and S. Garcia, “LLM in the shell: Generative honeypots,” in 2024 IEEE Eu- ropean Symposium on Security and Privacy Workshops (EuroS&PW), Jul. 2024, pp. 430–435, iSSN: 2768-0657
2024
-
[5]
Terminal- world: Scaling terminal-agent environments via agent skills,
Z. Cheng, H. Wang, Z. Liu, X. Wang, X. Zhu, Y. Guo, W. Lin, J. Z. Pan, and Y. Wang, “Terminal- world: Scaling terminal-agent environments via agent skills,” May 2026, arXiv:2605.20876 [cs.CL]. [Online]. Available: http://arxiv.org/abs/2605.20876
Pith/arXiv arXiv 2026
-
[6]
Codex | AI coding partner from OpenAI
“Codex | AI coding partner from OpenAI.” [Online]. Available: https://openai.com/codex/
-
[7]
OpenCode | the open source AI coding agent
“OpenCode | the open source AI coding agent.” [Online]. Available: https://opencode.ai/
-
[8]
Configure permissions
“Configure permissions.” [Online]. Available: https://code.claude.com/docs/en/permissions
-
[9]
Rules – codex | OpenAI developers
“Rules – codex | OpenAI developers.” [Online]. Available: https://developers.openai.com/codex/rules
-
[10]
Permissions,
“Permissions,” Jun. 2026. [Online]. Available: https://opencode.ai/docs/permissions/
2026
-
[11]
Policy reference - agentsh
“Policy reference - agentsh.” [Online]. Available: https://www.agentsh.org/docs/policy-reference/
-
[12]
Encourag- ing employee engagement with cybersecurity: How to tackle cyber fatigue,
A. Reeves, P. Delfabbro, and D. Calic, “Encourag- ing employee engagement with cybersecurity: How to tackle cyber fatigue,” Sage Open , vol. 11, no. 1, p. 21582440211000049, Jan. 2021
2021
-
[13]
Agentic AI in the wild: From hallucinations to reliable autonomy,
G. Chrysos, Y. Li, E. Ishii, X. Du, and K. P. Sycara, “Agentic AI in the wild: From hallucinations to reliable autonomy,” Dec. 2025
2025
-
[14]
Jailbreaking leading safety-aligned LLMs with sim- ple adaptive attacks,
M. Andriushchenko, F. Croce, and N. Flammarion, “Jailbreaking leading safety-aligned LLMs with sim- ple adaptive attacks,” in International Conference on Learning Representations, vol. 2025, 2025, pp. 40 116– 40 143
2025
-
[15]
Universal and transferable adversarial attacks on aligned language models,
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,” Dec. 2023, arXiv:2307.15043 [cs.CL]. [Online]. Available: http://arxiv.org/abs/2307.15043
Pith/arXiv arXiv 2023
-
[16]
Prompt injection attack to tool selection in LLM agents,
J. Shi, Z. Yuan, G. Tie, P. Zhou, N. Z. Gong, and L. Sun, “Prompt injection attack to tool selection in LLM agents,” arXiv preprint arXiv:2504.19793 , 2025. [Online]. Available: https://arxiv.org/abs/2504.19793
Pith/arXiv arXiv 2025
-
[17]
InjecA- gent: Benchmarking indirect prompt injections in tool- integrated large language model agents,
Q. Zhan, Z. Liang, Z. Ying, and D. Kang, “InjecA- gent: Benchmarking indirect prompt injections in tool- integrated large language model agents,” in Findings of the Association for Computational Linguistics: ACL 2024, L.-W. Ku, A. Martins, and V. Srikumar, Eds. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 10 471–10 506
2024
-
[18]
Clinejection — compromising cline’s production releases just by prompting an is- sue triager,
A. Khan, “Clinejection — compromising cline’s production releases just by prompting an is- sue triager,” Feb. 2026. [Online]. Available: https://adnanthekhan.com/posts/clinejection/
2026
-
[19]
Command and scripting interpreter, technique T1059 - enterprise | MITRE ATT&CK®
“Command and scripting interpreter, technique T1059 - enterprise | MITRE ATT&CK®.” [Online]. Available: https://attack.mitre.org/techniques/T1059/
-
[20]
A view on current malware behaviors,
U. Bayer, I. Habibi, D. Balzarotti, E. Kirda, and C. Kruegel, “A view on current malware behaviors,” in LEET, 2009
2009
-
[21]
xattr(7) - Linux manual page
“xattr(7) - Linux manual page.” [Online]. Available: https://man7.org/linux/man-pages/man7/xattr.7.html
-
[22]
DASE: Document-assisted symbolic execution for im- proving automated software testing,
E. Wong, L. Zhang, S. Wang, T. Liu, and L. Tan, “DASE: Document-assisted symbolic execution for im- proving automated software testing,” in 2015 37th IEEE International Conference on Software Engineer- ing (ICSE) , vol. 1. IEEE, 2015, pp. 620–631. 14
2015
-
[23]
Inferring method specifications from nat- ural language API descriptions,
R. Pandita, X. Xiao, H. Zhong, T. Xie, S. Oney, and A. Paradkar, “Inferring method specifications from nat- ural language API descriptions,” in 2012 34th Inter- national Conference on Software eEgineering (ICSE) . IEEE, 2012, pp. 815–825
2012
-
[24]
/*icomment: bugs or bad comments?*/,
L. Tan, D. Yuan, G. Krishna, and Y. Zhou, “/*icomment: bugs or bad comments?*/,” in Proceed- ings of twenty-first ACM SIGOPS symposium on Oper- ating systems principles . Stevenson Washington USA: ACM, Oct. 2007, pp. 145–158
2007
-
[25]
A survey of satisfiability modulo the- ory,
D. Monniaux, “A survey of satisfiability modulo the- ory,” in Computer Algebra in Scientific Computing , V. P. Gerdt, W. Koepf, W. M. Seiler, and E. V. Vorozhtsov, Eds. Cham: Springer International Pub- lishing, 2016, pp. 401–425
2016
-
[26]
Why don’t software developers use static analysis tools to find bugs?
B. Johnson, Y. Song, E. Murphy-Hill, and R. Bowdidge, “Why don’t software developers use static analysis tools to find bugs?” in 2013 35th International Conference on Software Engineering (ICSE) . IEEE, 2013, pp. 672– 681
2013
-
[27]
A systematic evaluation of static API- misuse detectors,
S. Amann, H. A. Nguyen, S. Nadi, T. N. Nguyen, and M. Mezini, “A systematic evaluation of static API- misuse detectors,” IEEE Transactions on Software En- gineering, vol. 45, no. 12, pp. 1170–1188, 2018
2018
-
[28]
Static analysis: a survey of techniques and tools,
A. Gosain and G. Sharma, “Static analysis: a survey of techniques and tools,” in Intelligent Computing and Applications, D. Mandal, R. Kar, S. Das, and B. K. Panigrahi, Eds. New Delhi: Springer India, 2015, pp. 581–591
2015
-
[29]
Towards mitigating LLM hallucination via self reflection,
Z. Ji, T. Yu, Y. Xu, N. Lee, E. Ishii, and P. Fung, “Towards mitigating LLM hallucination via self reflection,” in Findings of the Asso- ciation for Computational Linguistics: EMNLP 2023, 2023, pp. 1827–1843. [Online]. Available: https://aclanthology.org/2023.findings-emnlp.123/
2023
-
[30]
HalluLens: LLM hallucination benchmark,
Y. Bang, Z. Ji, A. Schelten, A. Hartshorn, T. Fowler, C. Zhang, N. Cancedda, and P. Fung, “HalluLens: LLM hallucination benchmark,” in Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers), 2025, pp. 24 128–24 156. [Online]. Available: https://aclanthology.org/2025.acl-long.1176/
2025
-
[31]
GTFOBins
“GTFOBins.” [Online]. Available: https://gtfobins.org/
-
[32]
LLM hallucina- tions in practical code generation: Phenomena, mecha- nism, and mitigation,
Z. Zhang, C. Wang, Y. Wang, E. Shi, Y. Ma, W. Zhong, J. Chen, M. Mao, and Z. Zheng, “LLM hallucina- tions in practical code generation: Phenomena, mecha- nism, and mitigation,” Proceedings of the ACM on Soft- ware Engineering, vol. 2, no. ISSTA, pp. ISSTA022:481– ISSTA022:503, Jun. 2025
2025
-
[33]
Allowing and denying tool use
“Allowing and denying tool use.” [Online]. Available: https://docs-internal.github.com/en/copilot/how-tos/copilot-c li/use-copilot-cli/allowing-tools
-
[34]
Google antigravity documentation
“Google antigravity documentation.” [Online]. Avail- able: https://antigravity.google/docs
-
[35]
openclaw/openclaw,
“openclaw/openclaw,” Jun. 2026, original- date: 2025-11-24T10:16:47Z. [Online]. Available: https://github.com/openclaw/openclaw
2026
-
[36]
containers/bubblewrap: Low-level unprivi- leged sandboxing tool used by flatpak and similar projects
“containers/bubblewrap: Low-level unprivi- leged sandboxing tool used by flatpak and similar projects.” [Online]. Available: https://github.com/containers/bubblewrap
-
[37]
Overlay filesystem — the Linux ker- nel documentation
“Overlay filesystem — the Linux ker- nel documentation.” [Online]. Available: https://docs.kernel.org/filesystems/overlayfs.html
-
[38]
Debian popularity contest
“Debian popularity contest.” [Online]. Available: https://popcon.debian.org/
-
[39]
J. Han, M. Kamber, and J. Pei, Data mining: Concepts and techniques . Morgan Kaufmann, 2006, vol. 10
2006
-
[40]
Hollander, D
M. Hollander, D. A. Wolfe, and E. Chicken, Nonpara- metric statistical methods . John Wiley & Sons, 2013
2013
-
[41]
tldr-pages/tldr,
“tldr-pages/tldr,” Jun. 2026, original- date: 2013-12-08T07:34:43Z. [Online]. Available: https://github.com/tldr-pages/tldr
2026
-
[42]
Identify- ing the risks of LM agents with an LM-emulated sand- box,
Y. Ruan, H. Dong, A. Wang, S. Pitis, Y. Zhou, J. Ba, Y. Dubois, C. Maddison, and T. Hashimoto, “Identify- ing the risks of LM agents with an LM-emulated sand- box,” in International Conference on Learning Repre- sentations, vol. 2024, 2024, pp. 27 031–27 098
2024
-
[43]
IsolateGPT: An execution isolation ar- chitecture for LLM-based agentic systems,
Y. Wu, F. Roesner, T. Kohno, N. Zhang, and U. Iqbal, “IsolateGPT: An execution isolation ar- chitecture for LLM-based agentic systems,” Jan. 2025, arXiv:2403.04960 [cs.CR]. [Online]. Available: http://arxiv.org/abs/2403.04960
arXiv 2025
-
[44]
Progent: Securing AI agents with privilege control,
T. Shi, J. He, Z. Wang, H. Li, L. Wu, W. Guo, and D. Song, “Progent: Securing AI agents with privilege control,” May 2026, arXiv:2504.11703 [cs.CR]. [Online]. Available: http://arxiv.org/abs/2504.11703
Pith/arXiv arXiv 2026
-
[45]
MiniScope: a least privilege framework for authorizing tool calling agents,
J. Zhu, K. Tseng, G. Vernik, X. Huang, S. G. Patil, V. Fang, and R. A. Popa, “MiniScope: a least privilege framework for authorizing tool calling agents,” Dec. 2025, arXiv:2512.11147 [cs.CR]. [Online]. Available: http://arxiv.org/abs/2512.11147
arXiv 2025
-
[46]
Z. Ji, D. Wu, W. Jiang, P. Ma, Z. Li, Y. Gao, S. Wang, and Y. Li, “Taming various privilege escalation in LLM-based agent systems: a mandatory access control framework,” Jan. 2026, arXiv:2601.11893 [cs.CR]. [Online]. Available: http://arxiv.org/abs/2601.11893
arXiv 2026
-
[47]
What you approve is what executes: Consent integrity for black-box LLM agents,
X. Weng, “What you approve is what executes: Consent integrity for black-box LLM agents,” Jun. 2026, arXiv:2606.02668 [cs.CR]. [Online]. Available: http://arxiv.org/abs/2606.02668
Pith/arXiv arXiv 2026
-
[48]
Reframing LLM agent security as an agent-human interaction problem,
P. Wang, Y. Li, and Y. Tian, “Reframing LLM agent security as an agent-human interaction problem,” May 2026, arXiv:2605.24309 [cs.CR]. [Online]. Available: http://arxiv.org/abs/2605.24309 15
Pith/arXiv arXiv 2026
-
[49]
Takedown: How it’s done in modern coding agent exploits,
E. Lee, D. Kim, W. Kim, and I. Yun, “Takedown: How it’s done in modern coding agent exploits,” Sep. 2025, arXiv:2509.24240 [cs.CR]. [Online]. Available: http://arxiv.org/abs/2509.24240
arXiv 2025
-
[50]
Judging LLM-as-a-judge with MT-Bench and Chatbot Arena,
L. Zheng, W.-L. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, and E. Xing, “Judging LLM-as-a-judge with MT-Bench and Chatbot Arena,” Advances in Neural Information Processing Systems , vol. 36, pp. 46 595–46 623, 2023
2023
-
[51]
SoK: Taxonomy and evaluation of prompt security in large language models,
H. Hong, S. Feng, N. Naderloui, S. Yan, J. Zhang, B. Liu, A. Arastehfard, H. Huang, and Y. Hong, “SoK: Taxonomy and evaluation of prompt security in large language models,” 2025. [Online]. Available: https://arxiv.org/abs/2510.15476
arXiv 2025
-
[52]
Prompt injection attacks on large language models: A survey of attack methods, root causes, and defense strategies,
T. Geng, Z. Xu, Y. Qu, and W. E. Wong, “Prompt injection attacks on large language models: A survey of attack methods, root causes, and defense strategies,” Computers, Materials, & Continua , vol. 87, no. 1, 2026
2026
-
[53]
Jailbroken: How does LLM safety training fail?
A. Wei, N. Haghtalab, and J. Steinhardt, “Jailbroken: How does LLM safety training fail?” Advances in Neu- ral Information Processing Systems , vol. 36, pp. 80 079– 80 110, 2023
2023
-
[54]
Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection,
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection,” in Proceedings of the 16th ACM Workshop on Artificial Intelligence and Se- curity. Copenhagen Denmark: ACM, Nov. 2023, pp. 79–90
2023
-
[55]
Available: https://lolbas-project.github.io/
“LOLBAS.” [Online]. Available: https://lolbas-project.github.io/
-
[56]
Living-off-the-land command detection using ac- tive learning,
T. Ongun, J. W. Stokes, J. Bar Or, K. Tian, F. Ta- jaddodianfar, J. Neil, C. Seifert, A. Oprea, and J. C. Platt, “Living-off-the-land command detection using ac- tive learning,” in 24th International Symposium on Re- search in Attacks, Intrusions and Defenses . San Sebas- tian Spain: ACM, Oct. 2021, pp. 442–455
2021
-
[57]
Sandbox – codex | Ope- nAI developers
“Sandbox – codex | Ope- nAI developers.” [Online]. Available: https://developers.openai.com/codex/concepts/sandboxing 16
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.