Z-FLoc: Zero-Shot Floorplan Localization via Geometric Primitives
Pith reviewed 2026-06-28 06:48 UTC · model grok-4.3
The pith
Zero-shot floorplan localization matches lines and circles extracted from monocular 3D reconstructions to the map.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
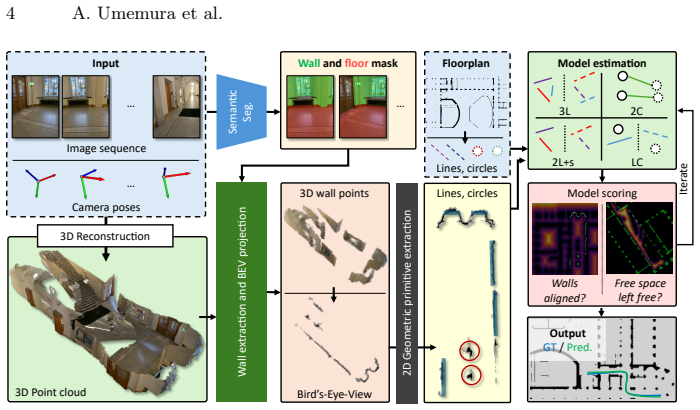
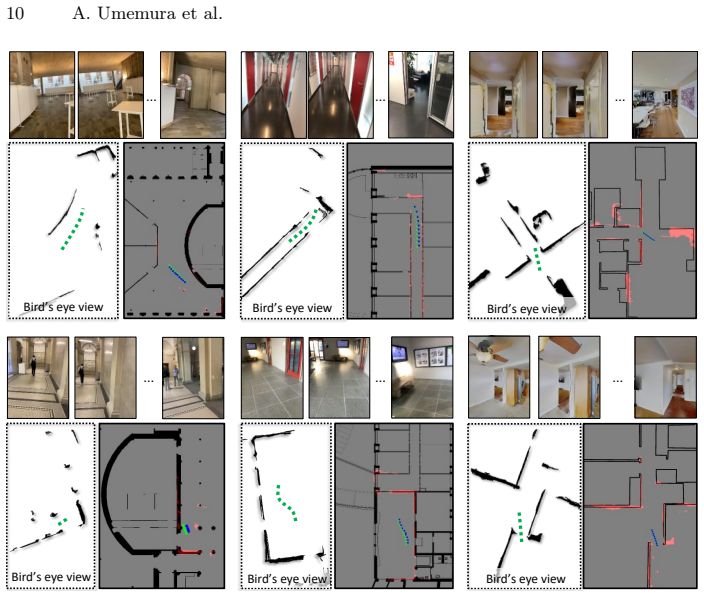
Dominant geometric primitives—lines and circles—are extracted from a bird's-eye-view projection of a monocular 3D reconstruction and matched to the corresponding elements in the floorplan using dedicated minimal solvers inside a robust estimation framework, producing accurate localization in environments never seen during development and with one fixed set of hyperparameters.
What carries the argument
Minimal solvers that align lines and circles between the bird's-eye-view primitives and the floorplan geometry inside a robust estimator.
If this is right
- The method generalizes to novel environments without any retraining.
- It outperforms state-of-the-art learning-based methods on unseen environments.
- A single fixed set of hyperparameters works across simulated and real-world datasets.
- Localization succeeds using only the geometric primitives present in the floorplan and the reconstruction.
Where Pith is reading between the lines
- The same primitive-matching strategy could be tested on other compact map representations such as building footprints or CAD models if similar lines and circles are present.
- Environments with strong structural regularity may need far less data than feature-learning approaches, reducing the cost of deploying localization in new buildings.
- Combining the geometric solver with a learned prior only for ambiguous cases could be a direct next step without changing the core zero-shot claim.
Load-bearing premise
Lines and circles remain the dominant, reliably extractable geometric primitives in the bird's-eye view of monocular 3D reconstructions across most human-made indoor spaces.
What would settle it
A set of real indoor environments whose floorplans contain few straight lines or circles, or whose monocular reconstructions yield inaccurate bird's-eye-view primitives, such that localization success rate falls below 30 percent on average.
Figures

read the original abstract
Visual localization -- estimating a camera pose within a pre-existing map -- is a fundamental problem in computer vision. Floorplans are an attractive map representation: they are readily available for most buildings, compact, and inherently invariant to visual appearance changes. However, bridging the severe domain gap between camera observations and floorplan geometry remains challenging. Existing methods address this gap through data-driven learning, yet they require large-scale training data and environment-specific retraining, limiting their practical deployment. We propose a zero-shot floorplan localization method that generalizes to novel environments without any retraining. Our key insight is that dominant geometric primitives -- lines and circles -- are ubiquitous in human-made environments and provide appearance-invariant structural constraints. We extract these primitives from a bird's-eye-view (BEV) projection of monocular 3D reconstructions and match them to the floorplan via dedicated minimal solvers within a robust estimation framework. Experiments on both simulated and real-world datasets show that our approach outperforms state-of-the-art learning-based methods on unseen environments, while using a single fixed set of hyperparameters across all experiments. The source code will be made publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Z-FLoc, a zero-shot floorplan localization method. It extracts dominant geometric primitives (lines and circles) from a bird's-eye-view projection of monocular 3D reconstructions and matches them to the floorplan using dedicated minimal solvers inside a robust estimation framework. The method is claimed to generalize to novel environments without retraining or environment-specific data and to outperform state-of-the-art learning-based methods on both simulated and real-world datasets while using a single fixed set of hyperparameters across all experiments.
Significance. If the extraction and matching pipeline proves reliable, the result would be significant: it offers a practical, training-free alternative to data-driven methods for a core robotics/CV task, leveraging the ubiquity of geometric primitives and the ready availability of floorplans. The fixed-hyperparameter design and planned public code release are additional strengths for reproducibility.
major comments (1)
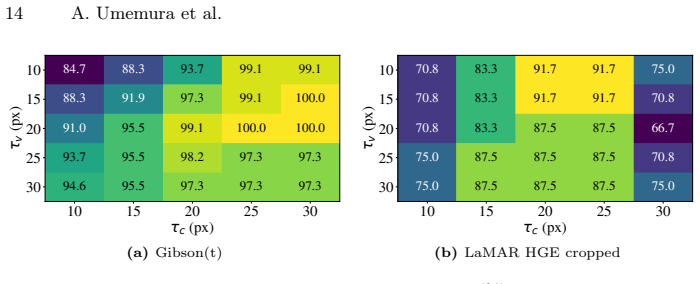
- [Experiments] The central claim requires reliable extraction of lines and circles from BEV projections of monocular reconstructions (which are scale-ambiguous and noisy in texture-poor scenes). The manuscript provides no quantitative metrics (precision, recall, or error distribution) for this extraction stage on the real-world datasets, leaving the load-bearing assumption unverified.
minor comments (1)
- The abstract states that source code will be made publicly available, but the manuscript contains no repository link, license information, or reproducibility checklist.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment below.
read point-by-point responses
-
Referee: [Experiments] The central claim requires reliable extraction of lines and circles from BEV projections of monocular reconstructions (which are scale-ambiguous and noisy in texture-poor scenes). The manuscript provides no quantitative metrics (precision, recall, or error distribution) for this extraction stage on the real-world datasets, leaving the load-bearing assumption unverified.
Authors: We agree that the manuscript would benefit from direct quantitative evaluation of the line and circle extraction stage on real-world data. The current evaluation focuses on end-to-end localization accuracy, which serves as an indirect measure of extraction reliability because failures in primitive detection would prevent successful matching to the floorplan. To address the concern directly, the revised manuscript will include precision, recall, and error distribution metrics for the extraction pipeline on the real-world datasets, computed against available ground-truth annotations or a manually verified subset. revision: yes
Circularity Check
No circularity: geometric pipeline is self-contained and independent of fitted predictions or self-citations.
full rationale
The paper presents an algorithmic pipeline that extracts lines and circles from BEV projections of monocular reconstructions and matches them to floorplans using minimal solvers inside a robust estimator. No equations or steps are shown that define a quantity in terms of itself, rename a fitted parameter as a prediction, or rely on load-bearing self-citations whose validity is internal to the authors. The zero-shot claim rests on the fixed-hyperparameter geometric matching procedure itself, which is externally verifiable against standard minimal-solver literature and does not reduce to any input data by construction. The provided abstract and description contain no self-referential reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dominant geometric primitives such as lines and circles are ubiquitous in human-made environments and provide appearance-invariant structural constraints.
Reference graph
Works this paper leans on
-
[1]
In: CVPR (2023)
Brachmann, E., Cavallari, T., Prisacariu, V.A.: Accelerated coordinate encoding: Learning to relocalize in minutes using rgb and poses. In: CVPR (2023)
2023
-
[2]
In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition
Brahmbhatt, S., Gu, J., Kim, K., Hays, J., Kautz, J.: Geometry-aware learning of maps for camera localization. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2616–2625 (2018)
2018
-
[3]
In: CVPR (2018)
Camposeco, F., Cohen, A., Pollefeys, M., Sattler, T.: Hybrid camera pose estima- tion. In: CVPR (2018)
2018
-
[4]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Chen, C., Wang, R., Vogel, C., Pollefeys, M.: F3 loc: Fusion and filtering for floor- plan localization. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[5]
In: CVPR (2022)
Cheng, B., Misra, I., Schwing, A.G., Kirillov, A., Girdhar, R.: Masked-attention mask transformer for universal image segmentation. In: CVPR (2022)
2022
-
[6]
Cheng, Y., Princen, B., Manduchi, R.: Palms+: Modular image-based floor plan localization leveraging depth foundation model. arXiv preprint arXiv:2511.09724 (2025),https://arxiv.org/abs/2511.09724, accepted to IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2026, Application Track
-
[7]
In: CVPR Deep Learning for Visual SLAM Work- shop (2018)
DeTone, D., Malisiewicz, T., Rabinovich, A.: Superpoint: Self-supervised interest point detection and description. In: CVPR Deep Learning for Visual SLAM Work- shop (2018)
2018
-
[8]
In: 2014 IEEE Conference on Computer Vision and Pattern Recognition
Donoser, M., Schmalstieg, D.: Discriminative feature-to-point matching in image- based localization. In: 2014 IEEE Conference on Computer Vision and Pattern Recognition. pp. 516–523 (2014)
2014
-
[9]
arXiv (2025)
Edstedt, J., Nordström, D., Zhang, Y., Bökman, G., Astermark, J., Larsson, V., Heyden,A.,Kahl,F.,Wadenbäck,M.,Felsberg,M.:RoMav2:HarderBetterFaster Denser Feature Matching. arXiv (2025)
2025
-
[10]
IEEE Robotics and Automation Letters9(4), 3932–3939 (2024)
Ewe, Z.L., Chang, F.H., Huang, Y.S., Fu, L.C.: Spatial graph-based localization and navigation on scaleless floorplan. IEEE Robotics and Automation Letters9(4), 3932–3939 (2024)
2024
-
[11]
In: 2023 IEEE International Conference on Robotics and Automation (ICRA)
Feng, D., He, Z., Hou, J., Schwertfeger, S., Zhang, L.: Floorplannet: Learning topometric floorplan matching for robot localization. In: 2023 IEEE International Conference on Robotics and Automation (ICRA). pp. 6168–6174 (2023)
2023
-
[12]
In: ECCV (2024)
Gard, N., Hilsmann, A., Eisert, P.: SPVLoc: Semantic panoramic viewport match- ing for 6D camera localization in unseen environments. In: ECCV (2024)
2024
-
[13]
In: European Conference on Computer Vision
Garg, K., Puligilla, S.S., Kolathaya, S., Krishna, M., Garg, S.: Revisit anything: Visual place recognition via image segment retrieval. In: European Conference on Computer Vision. pp. 326–343. Springer (2024)
2024
-
[14]
Autonomous Robots43(06 2019).https://doi.org/10.1007/s10514-018- 9785-7
Gholami Shahbandi, S., Magnusson, M.: 2d map alignment with region decomposi- tion. Autonomous Robots43(06 2019).https://doi.org/10.1007/s10514-018- 9785-7
-
[15]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2024)
Giang, K.T., Song, S., Jo, S.: Learning to produce semi-dense correspondences for visual localization. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2024)
2024
-
[16]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Grader, Y., Averbuch-Elor, H.: Supercharging floorplan localization with semantic rays. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 27116–27125 (2025) 16 A. Umemura et al
2025
-
[17]
Hou, J., Yuan, Y., He, Z., Schwertfeger, S.: Matching maps based on the area graph. Intell. Serv. Robot.15(1), 69–94 (Mar 2022)
2022
-
[18]
In: ECCV (2022)
Howard-Jenkins, H., Prisacariu, V.A.: Lalaloc++: Global floor plan comprehension for layout localisation in unvisited environments. In: ECCV (2022)
2022
-
[19]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Howard-Jenkins, H., Ruiz-Sarmiento, J.R., Prisacariu, V.A.: Lalaloc: Latent layout localisation in dynamic, unvisited environments. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10107–10116 (2021)
2021
-
[20]
In: Advances in Neural Information Pro- cessing Systems
Huang, K.W., Li, B., Hariharan, B., Snavely, N.: C3po: Cross-view cross-modality correspondence by pointmap prediction. In: Advances in Neural Information Pro- cessing Systems. vol. 38 (2025)
2025
-
[21]
Philosophical Transactions of the Royal Society A: Mathematical, Phys- ical and Engineering Sciences374(2016)
Jolliffe, I.T., Cadima, J.: Principal component analysis: a review and recent devel- opments. Philosophical Transactions of the Royal Society A: Mathematical, Phys- ical and Engineering Sciences374(2016)
2016
-
[22]
In: Conference on Robot Learning (2018)
Karkus, P., Hsu, D., Lee, W.S.: Particle filter networks with application to visual localization. In: Conference on Robot Learning (2018)
2018
-
[23]
IEEE Robotics and Automation Letters (2023)
Keetha, N., Mishra, A., Karhade, J., Jatavallabhula, K.M., Scherer, S., Krishna, M., Garg, S.: Anyloc: Towards universal visual place recognition. IEEE Robotics and Automation Letters (2023)
2023
-
[24]
In: International Con- ference on 3D Vision (3DV)
Keetha, N., Müller, N., Schönberger, J., Porzi, L., Zhang, Y., Fischer, T., Knapitsch, A., Zauss, D., Weber, E., Antunes, N., Luiten, J., Lopez-Antequera, M., Bulò, S.R., Richardt, C., Ramanan, D., Scherer, S., Kontschieder, P.: MapA- nything: Universal feed-forward metric 3D reconstruction. In: International Con- ference on 3D Vision (3DV). IEEE (2026)
2026
-
[25]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2024)
Kim, J., Jeong, J., Kim, Y.M.: Fully geometric panoramic localization. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2024)
2024
-
[26]
Lepetit, V., Moreno-Noguer, F., Fua, P.: Epnp: An accurate o(n) solution to the pnp problem. Int. J. Comput. Vision81(2), 155–166 (Feb 2009)
2009
-
[27]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J.H., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
In: ICCV (2023)
Lindenberger, P., Sarlin, P.E., Pollefeys, M.: LightGlue: Local Feature Matching at Light Speed. In: ICCV (2023)
2023
-
[30]
Lowe, D.G.: Distinctive image features from scale-invariant keypoints. Int. J. Com- put. Vision60(2), 91–110 (Nov 2004)
2004
-
[31]
The Journal of Open Source Software2(11), 205 (2017)
McInnes, L., Healy, J., Astels, S.: hdbscan: Hierarchical density based clustering. The Journal of Open Source Software2(11), 205 (2017)
2017
-
[32]
Interna- tional Journal of Computer Vision128(5), 1286–1310 (2020)
Mendez, O., Hadfield, S., Pugeault, N., Bowden, R.: SeDAR: Reading floorplans like a human – using deep learning to enable human-inspired localisation. Interna- tional Journal of Computer Vision128(5), 1286–1310 (2020)
2020
-
[33]
In: CVPR
Min, Z., Khosravan, N., Bessinger, Z., Narayana, M., Kang, S.B., Dunn, E., Boy- adzhiev, I.: Laser: Latent space rendering for 2d visual localization. In: CVPR. pp. 11112–11121. IEEE (2022)
2022
-
[34]
In: CVPR (2019)
Sarlin, P.E., Cadena, C., Siegwart, R., Dymczyk, M.: From coarse to fine: Robust hierarchical localization at large scale. In: CVPR (2019)
2019
-
[35]
In: CVPR (2023) Z-FLoc: Zero-Shot Floorplan Localization via Geometric Primitives 17
Sarlin, P.E., DeTone, D., Yang, T.Y., Avetisyan, A., Straub, J., Malisiewicz, T., Rota Bulò, S., Newcombe, R., Kontschieder, P., Balntas, V.: OrienterNet: Visual localization in 2D public maps with neural matching. In: CVPR (2023) Z-FLoc: Zero-Shot Floorplan Localization via Geometric Primitives 17
2023
-
[36]
In: ECCV (2022)
Sarlin, P.E., Dusmanu, M., Schönberger, J.L., Speciale, P., Gruber, L., Larsson, V., Miksik, O., Pollefeys, M.: LaMAR: Benchmarking Localization and Mapping for Augmented Reality. In: ECCV (2022)
2022
-
[37]
In: CVPR (2021)
Sarlin, P.E., Unagar, A., Larsson, M., Germain, H., Toft, C., Larsson, V., Pollefeys, M., Lepetit, V., Hammarstrand, L., Kahl, F., Sattler, T.: Back to the Feature: Learning Robust Camera Localization from Pixels to Pose. In: CVPR (2021)
2021
-
[38]
In: 2007 IEEE Conference on Computer Vision and Pattern Recognition
Schindler, G., Brown, M., Szeliski, R.: City-scale location recognition. In: 2007 IEEE Conference on Computer Vision and Pattern Recognition. pp. 1–7 (2007). https://doi.org/10.1109/CVPR.2007.383150
-
[39]
In: 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Shen, B., Xia, F., Li, C., Martín-Martín, R., Fan, L., Wang, G., Pérez-D’Arpino, C., Buch, S., Srivastava, S., Tchapmi, L.P., Tchapmi, M.E., Vainio, K., Wong, J., Fei-Fei, L., Savarese, S.: igibson 1.0: a simulation environment for interactive tasks in large realistic scenes. In: 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IR...
2021
-
[40]
arXiv preprint arXiv:2306.12547 (2023)
Wang, S., Kannala, J., Barath, D.: Dgc-gnn: Leveraging geometry and color cues for visual descriptor-free 2d-3d matching. arXiv preprint arXiv:2306.12547 (2023)
-
[41]
In: CVPR (2024)
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: Dust3r: Geometric 3d vision made easy. In: CVPR (2024)
2024
-
[42]
In: The Fourteenth International Conference on Learning Representations (2026)
Wüest,M.,Engelmann,F.,Miksik,O.,Pollefeys,M.,Barath,D.:Unloc:Leveraging depth uncertainties for floorplan localization. In: The Fourteenth International Conference on Learning Representations (2026)
2026
-
[43]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Yin, Y., Lyu, J., Wang, Y., Liu, H., Wang, H., Chen, B.: Towards robust proba- bilistic modeling on so (3) via rotation laplace distribution. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.