Efficient Neural Network Model Selection for Few-Class Application Datasets
Pith reviewed 2026-06-26 18:36 UTC · model grok-4.3
The pith
A data-side measure of classification difficulty lets users select neural network models for few-class datasets without repeated training and testing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
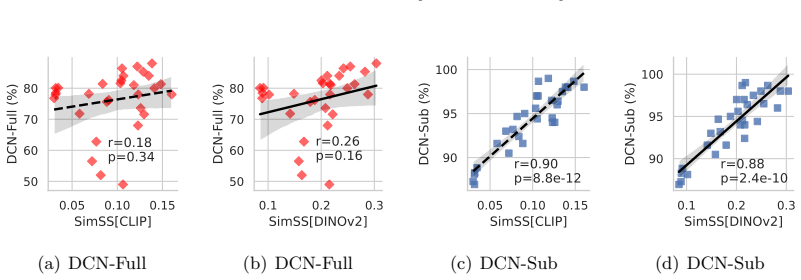
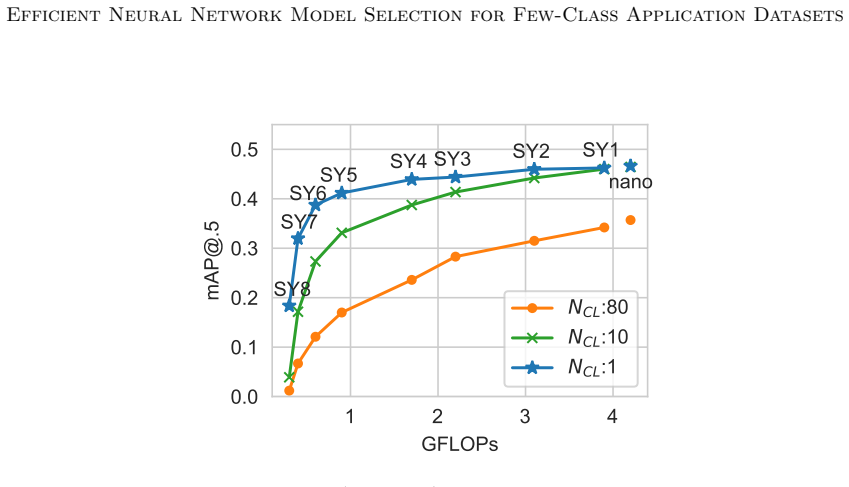
We develop a measure of classification difficulty based on data-side properties and show how it enables more efficient model selection for few-class datasets, where traditional approaches are less effective. We term this phenomenon few-class distinctiveness. Our metric allows comparison of models and datasets 6 to 29× faster than repeated training and testing. Leveraging this insight, we extend scaled model families below the smallest published models, achieving greater efficiency at similar accuracy, for example models up to 42% smaller than YOLOv5-nano for a mobile robot task.
What carries the argument
The few-class distinctiveness metric, a measure of classification difficulty computed directly from data-side properties to rank models without training.
If this is right
- Model comparisons on few-class datasets can skip full training cycles and still identify good candidates.
- Scaled model families can be extended to sizes smaller than published baselines while preserving accuracy.
- Practitioners gain a practical way to choose compact networks for mobile robot, drone, and IoT vision tasks.
- The method favors tailoring models to the frequent case of under-ten-class datasets rather than thousand-class benchmarks.
Where Pith is reading between the lines
- The metric could support continuous search over model width and depth rather than discrete published sizes.
- It might combine with hardware latency models to jointly optimize accuracy, size, and power on edge devices.
- Similar data-only difficulty measures could apply to few-object detection or segmentation problems.
- Validation on datasets with only two to five classes would show the metric's behavior at the lowest class counts.
Load-bearing premise
The data-side properties in the metric reliably predict the relative accuracy of different models on few-class datasets without any training or evaluation.
What would settle it
Apply the metric to rank several models on multiple few-class datasets, then fully train and test those models to check whether the accuracy order matches the metric predictions; repeated mismatches would show the measure does not predict performance.
Figures
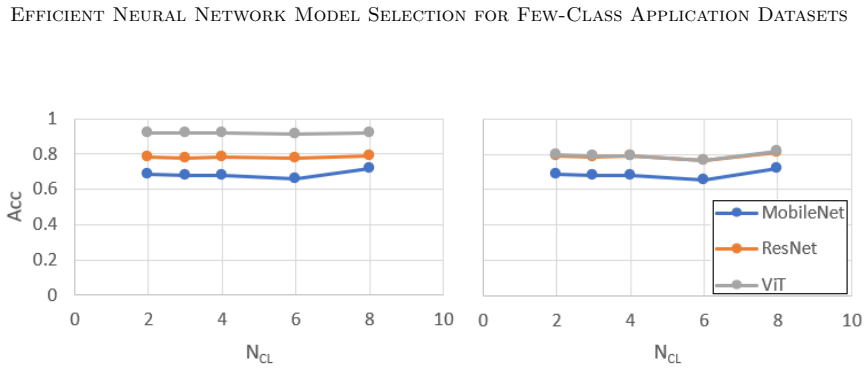


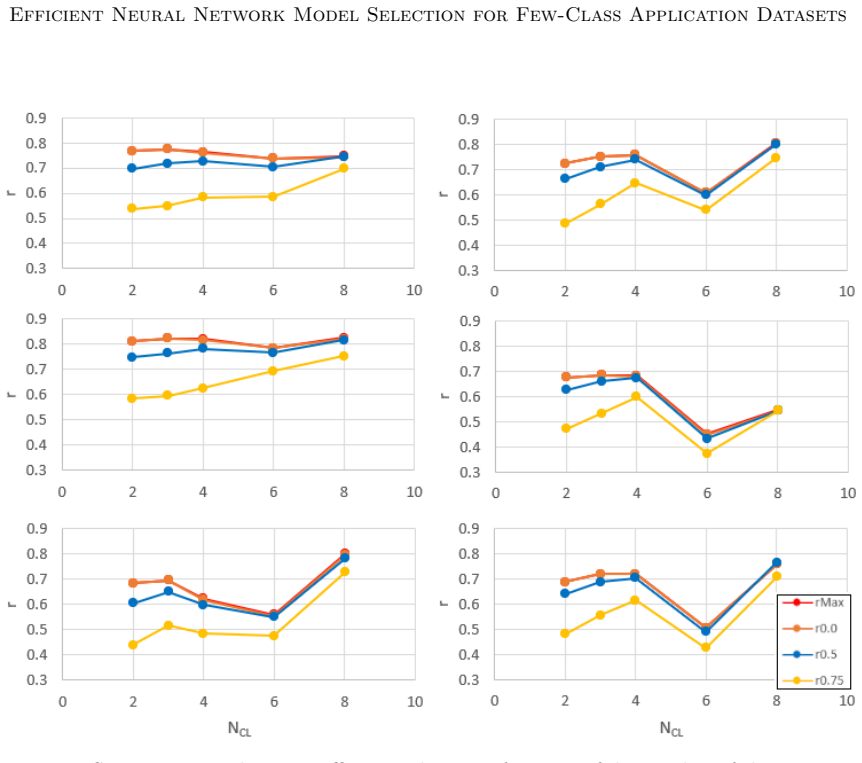
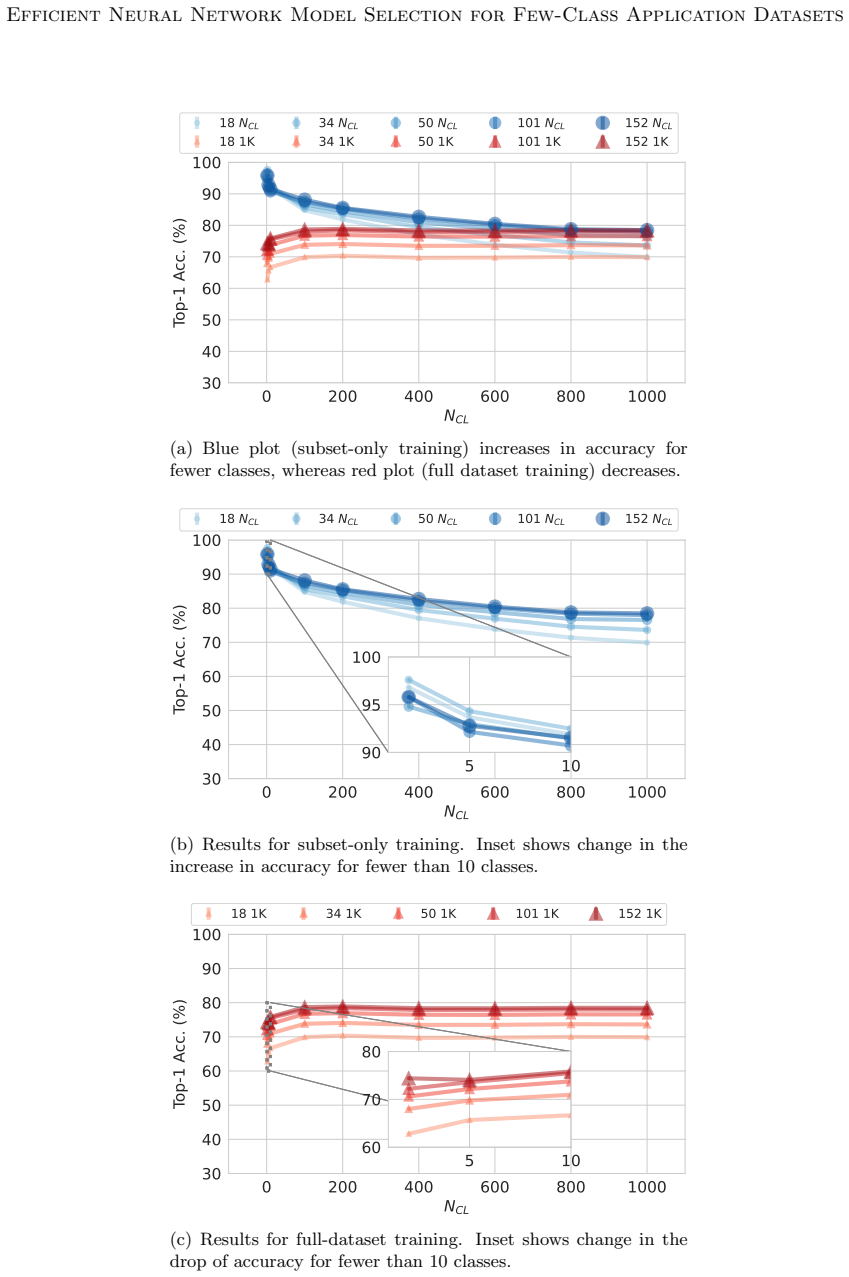
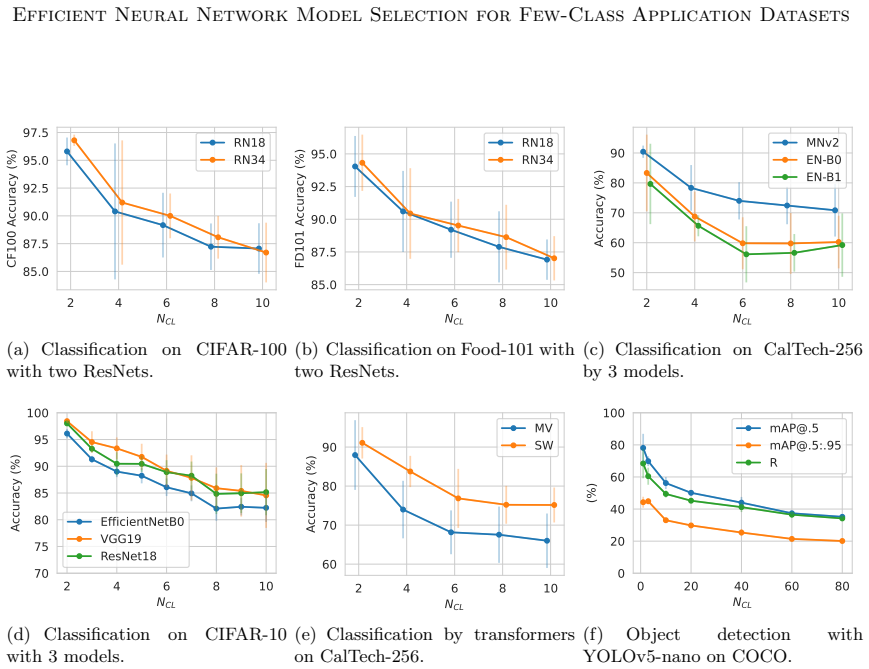

read the original abstract
While much effort has focused on developing and benchmarking high-performance neural networks, less attention has been given to how dataset properties, known to practitioners, can guide efficient model selection. Neural models are typically evaluated on datasets with thousands of classes, yet many real-world applications involve fewer than ten. To address this understudied but common setting, we develop a measure of classification difficulty based on data-side properties and show how it enables more efficient model selection for few-class datasets, where traditional approaches are less effective. We term this phenomenon "few-class distinctiveness". Our metric allows comparison of models and datasets 6 to 29$\times$ faster than repeated training and testing. Leveraging this insight, we extend scaled model families below the smallest published models, achieving greater efficiency at similar accuracy, for example models up to 42% smaller than YOLOv5-nano for a mobile robot task. Targeting resource-constrained applications, we demonstrate few-class model selection across mobile robot, drone, and IoT scenarios, highlighting practical gains in efficiency without sacrificing performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a data-side metric of classification difficulty termed 'few-class distinctiveness,' based on properties such as class-separability statistics and intra-class variance. It claims this metric enables model and dataset comparisons 6–29× faster than repeated training/testing, and leverages the metric to extend scaled model families below published minima, yielding up to 42% smaller models than YOLOv5-nano at comparable accuracy for mobile-robot, drone, and IoT tasks.
Significance. If the metric can be shown to support architecture ranking without training, the work would address an understudied regime (few-class datasets) with clear practical value for resource-constrained deployment. The reported speed-ups and concrete model-size reductions would constitute a useful engineering contribution if the underlying predictive relation holds.
major comments (1)
- [Abstract] Abstract: the metric is defined exclusively from data-side properties, yielding a single scalar per dataset. On any fixed dataset this scalar is therefore identical for every candidate architecture and scale. The central claim that the metric 'allows comparison of models' therefore requires either an unstated model-dependent term or a re-interpretation of 'model selection' as threshold selection rather than architecture ranking; neither is visible in the provided text.
minor comments (1)
- [Abstract] The abstract states that the metric is 'based on data-side properties' but supplies no explicit formula, normalization, or validation against held-out model rankings; a precise definition (ideally with an equation) is needed to assess reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting an important point of potential ambiguity in the abstract. We address the comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the metric is defined exclusively from data-side properties, yielding a single scalar per dataset. On any fixed dataset this scalar is therefore identical for every candidate architecture and scale. The central claim that the metric 'allows comparison of models' therefore requires either an unstated model-dependent term or a re-interpretation of 'model selection' as threshold selection rather than architecture ranking; neither is visible in the provided text.
Authors: We agree that the few-class distinctiveness metric is computed solely from dataset properties and therefore yields an identical scalar for every architecture on a fixed dataset. The metric supports model selection by providing a difficulty score that is mapped, via a small number of reference experiments, to the minimal model scale or capacity needed to reach target accuracy. This mapping allows practitioners to select an appropriate model from a scaled family (or to compare candidate scales) without training each option, producing the reported 6–29× speed-ups. In this sense 'model comparison' refers to rapid identification of the smallest viable model for the observed dataset difficulty rather than direct ranking of architectures on the same dataset. We will revise the abstract to state this mechanism explicitly and to clarify that the metric itself remains data-only while the selection procedure incorporates the empirical difficulty-to-capacity relation. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines its classification difficulty metric exclusively from data-side properties (class-separability statistics, intra-class variance, etc.) that are computed once per dataset and contain no dependence on model architecture, scale, or training outcomes. Because the metric is therefore identical across all candidate models on any fixed dataset, the derivation chain does not reduce any claimed prediction back to its own inputs by construction, nor does it rely on self-citation, fitted parameters renamed as predictions, or ansatzes smuggled via prior work. The central efficiency claim rests on an empirical correlation between the data-only scalar and observed model performance rather than on any definitional identity, leaving the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- unknown parameters in difficulty metric
Reference graph
Works this paper leans on
-
[1]
Image similarity using Deep CNN and Curriculum Learning
Srikar Appalaraju and Vineet Chaoji. Image similarity using deep cnn and curriculum learning.arXiv preprint arXiv:1709.08761,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
A Survey on Metric Learning for Feature Vectors and Structured Data
Aur´ elien Bellet, Amaury Habrard, and Marc Sebban. A survey on metric learning for feature vectors and structured data.arXiv preprint arXiv:1306.6709,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Food-101 – mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101 – mining discriminative components with random forests. InEuropean Conference on Computer Vision, 2014a. Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101 – mining discriminative components with random forests. InEuropean Conference on Computer Vision, 2014b. Hieu Minh Bui, Margar...
2016
-
[4]
Bryan Bo Cao, Lawrence O’Gorman, Michael Coss, and Shubham Jain. Data-side effi- ciencies for lightweight convolutional neural networks.arXiv preprint arXiv:2308.13057,
-
[5]
Improved Baselines with Momentum Contrastive Learning
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple frame- work for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PMLR, 2020a. Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved baselines with momen- tum contrastive learning.arXiv preprint arXiv:2003.04...
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[6]
Sommelier: Curating DNN models for the masses
Peizhen Guo, Bo Hu, and Wenjun Hu. Sommelier: Curating DNN models for the masses. InProc. 2022 Int. Conf. on Management of Data, SIGMOD ’22, page 1876–1890. Asso- ciation for Computing Machinery,
2022
-
[7]
A Neural Representation of Sketch Drawings
29 Efficient Neural Network Model Selection for Few-Class Application Datasets David Ha and Douglas Eck. A neural representation of sketch drawings.arXiv preprint arXiv:1704.03477,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, To- bias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications.arXiv preprint arXiv:1704.04861,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
A zest for LIME: To- ward architecture-independent model distances
Hengrui Jia, Hongyu Chen, Jonas Guan, and Nicolas Papernot. A zest for LIME: To- ward architecture-independent model distances. InICLR 2022, page 1876–1890, Virtual, France, April
2022
-
[10]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[11]
H. Li, Y. andWei, Z. Han, J. Huang, and W. Wang. Deep learning-based safety helmet detection in engineering management based on convolutional neural networks.Advances in Civil Engineering, 2020:88–97,
2020
-
[12]
MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer
Sachin Mehta and Mohammad Rastegari. Mobilevit: light-weight, general-purpose, and mobile-friendly vision transformer.arXiv preprint arXiv:2110.02178,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Eric J Michaud, Asher Parker-Sartori, and Max Tegmark. On the creation of narrow ai: hierarchy and nonlocality of neural network skills.arXiv preprint arXiv:2505.15811,
-
[14]
Jonas Ngnaw´ e, Maxime Heuillet, Sabyasachi Sahoo, Yann Pequignot, Ola Ahmad, Audrey Durand, Fr´ ed´ eric Precioso, and Christian Gagn´ e. Robust fine-tuning from non-robust pretrained models: Mitigating suboptimal transfer with adversarial scheduling.arXiv preprint arXiv:2509.23325,
-
[15]
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
32 Efficient Neural Network Model Selection for Few-Class Application Datasets Jack W Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. Scaling language models: Methods, analysis & insights from training gopher.arXiv preprint arXiv:2112.11446,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Very Deep Convolutional Networks for Large-Scale Image Recognition
33 Efficient Neural Network Model Selection for Few-Class Application Datasets Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
doi: 10.1016/j.neunet.2012.02.016
ISSN 0893-6080. doi: 10.1016/j.neunet.2012.02.016. URLhttp://www.sciencedirect. com/science/article/pii/S0893608012000457. Mohammed A. Subhi and Sawal Md. Ali. A deep convolutional neural network for food detection and recognition. In2018 IEEE-EMBS Conf. on Biomedical Engineering and Sciences (IECBES), pages 284–287,
-
[18]
Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie.The Caltech-UCSD Birds-200-2011 Dataset. Jul
2011
-
[19]
Clip-guided prototype modulating for few-shot action recognition.International Journal of Computer Vision, 132(6):1899–1912,
Xiang Wang, Shiwei Zhang, Jun Cen, Changxin Gao, Yingya Zhang, Deli Zhao, and Nong Sang. Clip-guided prototype modulating for few-shot action recognition.International Journal of Computer Vision, 132(6):1899–1912,
1912
-
[20]
Weak or strong? how to interpret a spearman or kendall correlation.https: //blogs.sas.com/content/iml/2023/04/05/interpret-spearman-kendall-corr
Rick Wicklin. Weak or strong? how to interpret a spearman or kendall correlation.https: //blogs.sas.com/content/iml/2023/04/05/interpret-spearman-kendall-corr. html,
2023
-
[21]
Thomas Wolf, Lysandre Debut, and et al
URLhttps://blogs.sas.com/content/iml/2023/04/05/ interpret-spearman-kendall-corr.html. Thomas Wolf, Lysandre Debut, and et al. Huggingface’s transformers: State-of-the-art natural language processing,
2023
-
[22]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
URLhttps://arxiv.org/abs/1910.03771. Rongcheng Wu, Mingzhe Wang, Zhidong Li, Jianlong Zhou, Fang Chen, Xuan Wang, and Changming Sun. Few-shot stereo matching with high domain adaptability based on adaptive recursive network.International Journal of Computer Vision, 132(5):1484–1501,
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[23]
Learnware: small models do big.Science China Informa- tion Sciences, 67:1869–1919,
35 Efficient Neural Network Model Selection for Few-Class Application Datasets Zhi-Hua Zhou and Zhi-Hao Tan. Learnware: small models do big.Science China Informa- tion Sciences, 67:1869–1919,
1919
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.