ReviewGuard: Aligning LLM-Assisted Peer Review with Long-Term Scientific Impact
Pith reviewed 2026-06-28 20:14 UTC · model grok-4.3
The pith
ReviewGuard aligns LLM peer reviews to future citation counts instead of human preferences, reaching 0.776 correlation on rejected-then-published papers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
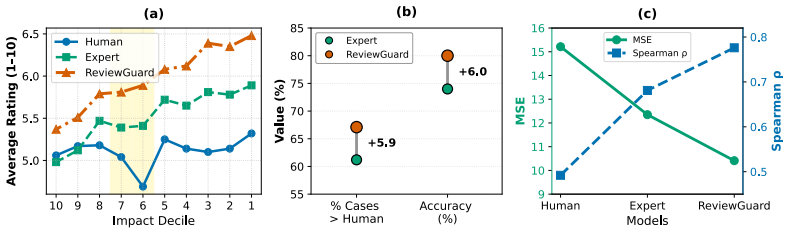
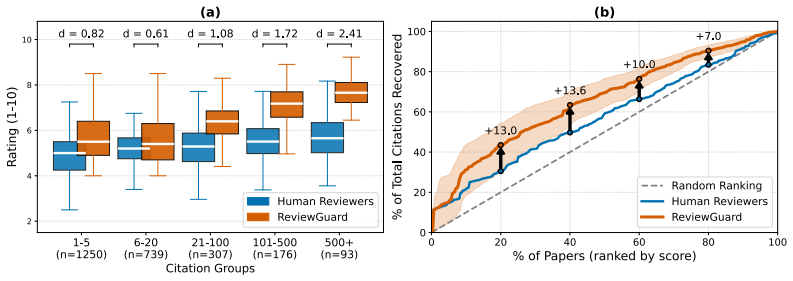
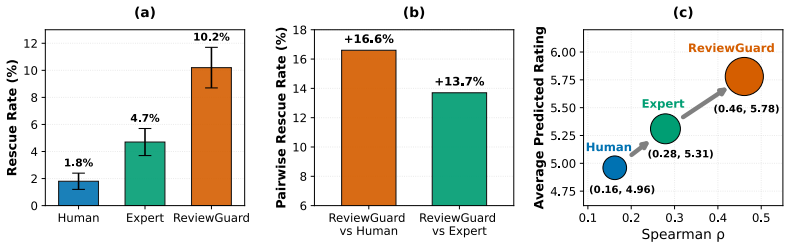
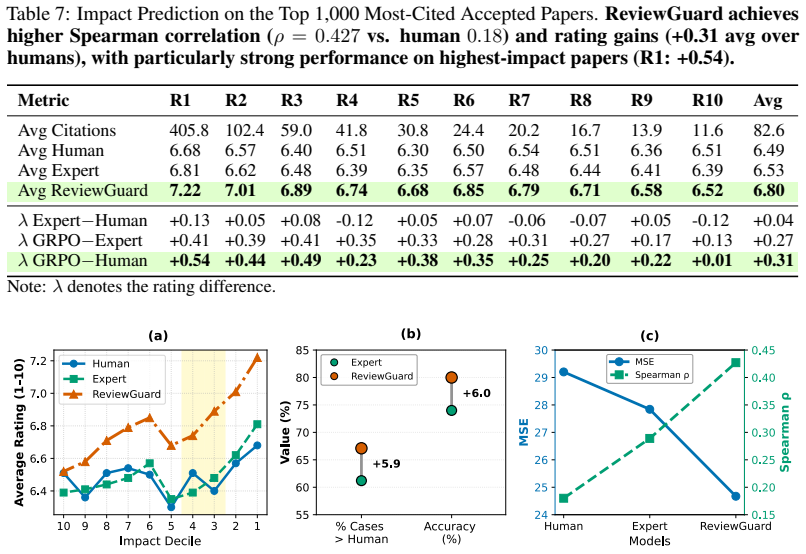
ReviewGuard achieves a Spearman correlation of 0.776 with future citations on rejected-then-published papers, outperforming human reviewers at 0.492 and a supervised expert model at 0.681, while flagging 10.2 percent of high-impact rejected papers versus 1.8 percent for humans.
What carries the argument
Two-stage framework that first generates reviews and then applies impact-aligned reinforcement learning to shift outputs toward citation-based estimates of long-term value.
If this is right
- Editors gain a complementary signal that identifies more than five times as many high-impact rejected papers under the same threshold.
- LLM review systems can be steered away from simply imitating current human preferences toward predicting downstream influence.
- The performance gap appears on the subset of papers that were rejected by humans yet later published, suggesting a concrete use case for catching overlooked work.
Where Pith is reading between the lines
- If citation alignment proves stable, similar reinforcement stages could be added to other LLM-assisted evaluation tasks such as grant review or journal triage.
- The approach may reduce certain forms of reviewer bias by anchoring judgments in observable long-term outcomes rather than contemporaneous opinions.
- Testing transfer to domains with slower citation cycles, such as theoretical physics or humanities, would clarify how far the current results extend.
Load-bearing premise
Future citation counts on this AI/ML dataset form a reliable proxy for long-term scientific impact that generalizes beyond the tested papers and domains.
What would settle it
Measure whether ReviewGuard retains its correlation advantage when applied to papers from non-AI fields or when impact is scored by metrics other than citations, such as field-specific awards or follow-on patents.
Figures
read the original abstract
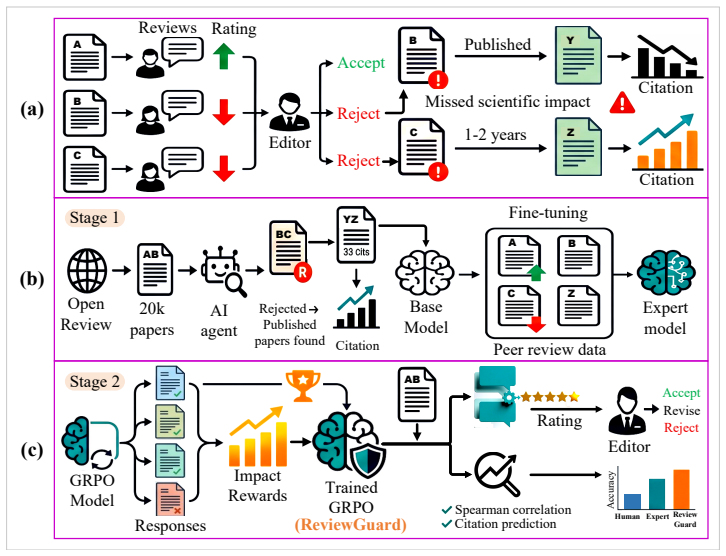
Peer review is central to scientific quality control, yet it can undervalue papers that later achieve substantial citation impact. While frontier large language models have shown promise in automating aspects of peer review, they primarily mimic human reviewer preferences rather than predict long-term scientific value. We introduce ReviewGuard, a two-stage framework that aligns LLM-generated reviews with citation-based estimates of long-term scientific impact rather than contemporaneous reviewer judgments. On 20,861 AI/ML papers from OpenReview augmented with Semantic Scholar citation data, ReviewGuard achieves a Spearman correlation of \r{ho} = 0.776 with future citations on rejected-then-published papers, outperforming human reviewers (\r{ho} = 0.492) and a supervised Expert model (\r{ho} = 0.681). Under the same decision threshold, ReviewGuard flags 10.2% of high-impact rejected papers, compared with 1.8% for human reviewers, corresponding to a 5.6x improvement. Our results demonstrate that impact-aligned reinforcement learning can provide editors with a complementary signal for identifying high-potential work, without replacing human judgment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReviewGuard, a two-stage LLM framework that aligns generated reviews with future citation counts (as a proxy for long-term scientific impact) via reinforcement learning rather than mimicking human reviewer preferences. On 20,861 AI/ML papers from OpenReview augmented with Semantic Scholar data, it reports Spearman ρ = 0.776 correlation with future citations on the rejected-then-published subset, outperforming human reviewers (ρ = 0.492) and a supervised Expert baseline (ρ = 0.681); under a fixed threshold it flags 10.2% of high-impact rejected papers vs. 1.8% for humans (5.6× improvement).
Significance. If the central empirical results can be verified with complete evaluation details, the work would provide a concrete demonstration that RL-based alignment to an external impact signal can surface high-citation papers missed by standard review. The scale of the OpenReview + Semantic Scholar dataset and the direct comparison to both human and supervised baselines are strengths that ground the contribution in observable outcomes.
major comments (3)
- [Abstract] Abstract: the headline claims (ρ = 0.776, 5.6× improvement) are presented without any information on train/test splits, RL reward scaling details, hyper-parameters, or error bars, preventing assessment of statistical reliability or reproducibility of the central correlation result.
- [Abstract] Abstract and evaluation description: all reported metrics are computed exclusively on the rejected-then-published subpopulation; this conditioning on eventual publication elsewhere introduces selection bias that is not quantified or corrected, undermining transfer claims to the initial review decision.
- [Abstract] Abstract: both the RL stage and the supervised Expert baseline are trained toward citation-derived targets, so the reported outperformance may partly reflect in-sample fitting to the same noisy signal rather than genuine out-of-sample prediction of long-term impact.
minor comments (1)
- [Abstract] Abstract: the notation \r{ho} is a typesetting artifact and should be corrected to ρ.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments on our work. Below we address each of the major comments point by point.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claims (ρ = 0.776, 5.6× improvement) are presented without any information on train/test splits, RL reward scaling details, hyper-parameters, or error bars, preventing assessment of statistical reliability or reproducibility of the central correlation result.
Authors: Details regarding the train/test splits, RL reward scaling, hyper-parameters, and error bars are fully specified in Sections 3 and 4 of the manuscript, along with the experimental protocol. The abstract is intended to provide a high-level overview of the results. revision: no
-
Referee: [Abstract] Abstract and evaluation description: all reported metrics are computed exclusively on the rejected-then-published subpopulation; this conditioning on eventual publication elsewhere introduces selection bias that is not quantified or corrected, undermining transfer claims to the initial review decision.
Authors: We agree that the focus on the rejected-then-published subpopulation introduces a form of selection bias, as these papers were ultimately published elsewhere. This subpopulation is specifically chosen to evaluate the ability to detect high-impact work missed by initial human review. We will revise the manuscript to include a quantitative discussion of this bias and its implications in the Limitations section. revision: yes
-
Referee: [Abstract] Abstract: both the RL stage and the supervised Expert baseline are trained toward citation-derived targets, so the reported outperformance may partly reflect in-sample fitting to the same noisy signal rather than genuine out-of-sample prediction of long-term impact.
Authors: The training of both the RL policy and the Expert baseline is performed exclusively on the training portion of the data, with all reported correlations and flagging rates evaluated on a disjoint held-out test set. This setup ensures out-of-sample assessment. The comparison to human reviewers, who lack access to future citation information, further highlights the benefit of the impact alignment. revision: no
Circularity Check
Model aligned to citation signals; correlation with future citations reported as performance metric
specific steps
-
fitted input called prediction
[Abstract]
"We introduce ReviewGuard, a two-stage framework that aligns LLM-generated reviews with citation-based estimates of long-term scientific impact rather than contemporaneous reviewer judgments. On 20,861 AI/ML papers from OpenReview augmented with Semantic Scholar citation data, ReviewGuard achieves a Spearman correlation of ρ = 0.776 with future citations on rejected-then-published papers, outperforming human reviewers (ρ = 0.492) and a supervised Expert model (ρ = 0.681)."
The alignment objective is defined directly in terms of citation-based estimates; the primary reported performance number is the correlation of the resulting reviews with (future) citation counts on a subset of the same dataset. The high ρ and the 5.6× improvement are therefore the expected statistical outcome of successful fitting to the citation signal rather than an independent test of alignment with long-term impact.
full rationale
The paper trains ReviewGuard via RL to align reviews with citation-based impact estimates and then reports Spearman correlation with future citations (plus 5.6× flag rate) on the rejected-then-published subset as the headline result. This constitutes fitted-input-called-prediction on the central metric. The comparison to human reviewers (ρ=0.492) supplies some independent content, so the circularity is partial rather than total; no self-citation chains or self-definitional reductions appear in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL reward scaling parameters
axioms (1)
- domain assumption Future citation counts are a valid proxy for long-term scientific impact
invented entities (1)
-
ReviewGuard two-stage framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Scientific peer review.Annual Review of Information Science and Technology, 45(1):197–245, 2011
Lutz Bornmann. Scientific peer review.Annual Review of Information Science and Technology, 45(1):197–245, 2011
2011
-
[2]
Peer review: a flawed process at the heart of science and journals.Journal of the Royal Society of Medicine, 99(4):178–182, 2006
Richard Smith. Peer review: a flawed process at the heart of science and journals.Journal of the Royal Society of Medicine, 99(4):178–182, 2006
2006
-
[3]
Measuring the effectiveness of scientific gatekeeping
Kyle Siler, Kirby Lee, and Lisa Bero. Measuring the effectiveness of scientific gatekeeping. Proceedings of the National Academy of Sciences, 112(2):360–365, 2015. doi: 10.1073/pnas.1 418218112
-
[4]
Predicting highly cited papers: A method for early detection of candidate breakthroughs
Ilya V Ponomarev, Duane E Williams, Charles J Hackett, Joshua D Schnell, and Laurel L Haak. Predicting highly cited papers: A method for early detection of candidate breakthroughs. Technological F orecasting and Social Change, 81:49–55, 2014
2014
-
[6]
Does it take too long to publish research?Nature, 530(7589):148–151, 2016
Kendall Powell. Does it take too long to publish research?Nature, 530(7589):148–151, 2016
2016
-
[7]
Corinna Cortes and Neil D Lawrence. Inconsistency in conference peer review: Revisiting the 2014 neurips experiment.arXiv preprint arXiv:2109.09774, 2021
-
[8]
Quantifying long-term scientific impact.Science, 342(6154):127–132, 2013
Dashun Wang, Chaoming Song, and Albert-László Barabási. Quantifying long-term scientific impact.Science, 342(6154):127–132, 2013
2013
-
[9]
Quantifying the evolution of individual scientific impact.Science, 354(6312):aaf5239, 2016
Roberta Sinatra, Dashun Wang, Pierre Deville, Chaoming Song, and Albert-László Barabási. Quantifying the evolution of individual scientific impact.Science, 354(6312):aaf5239, 2016
2016
-
[10]
Analyzing the machine learning conference review process, 2020
David Tran, Alex Valtchanov, Keshav Ganapathy, Raymond Feng, Eric Slud, Micah Goldblum, and Tom Goldstein. Analyzing the machine learning conference review process, 2020
2020
-
[11]
Rachel Bruce, Anthony Chauvin, Ludovic Trinquart, Philippe Ravaud, and Isabelle Boutron. Im- pact of interventions to improve the quality of peer review of biomedical journals: a systematic review and meta-analysis.BMC Medicine, 14:85, 2016. doi: 10.1186/s12916-016-0631-5
-
[12]
Effects of training on quality of peer review: randomised controlled trial.BMJ, 328:673–675,
Sara Schroter, Nick Black, Stephen Evans, James Carpenter, Fiona Godlee, and Richard Smith. Effects of training on quality of peer review: randomised controlled trial.BMJ, 328:673–675,
-
[13]
doi: 10.1136/bmj.38023.700775.AE
-
[14]
Bias in peer review.Journal of the American Society for Information Science and Technology, 64(1):2–17, 2013
Carole J Lee, Cassidy R Sugimoto, Guo Zhang, and Blaise Cronin. Bias in peer review.Journal of the American Society for Information Science and Technology, 64(1):2–17, 2013
2013
-
[15]
Are reviewer scores consistent with citations?Scientometrics, 129(8):4721–4740, 2024
Weixi Xie, Pengfei Jia, Guangyao Zhang, and Xianwen Wang. Are reviewer scores consistent with citations?Scientometrics, 129(8):4721–4740, 2024. doi: 10.1007/s11192-024-05103-2
-
[16]
Attention is all you need.Advances in Neural Information Processing Systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[17]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Mohammad Hosseini and Serge P. J. M. Horbach. Fighting reviewer fatigue or amplifying bias? considerations and recommendations for use of chatgpt and other large language models in scholarly peer review.Research Integrity and Peer Review, 8:4, 2023. doi: 10.1186/s41073-023 -00133-5
-
[19]
Ryan Liu and Nihar B. Shah. Reviewergpt? an exploratory study on using large language models for paper reviewing, 2023. 10
2023
-
[20]
Is llm a reliable reviewer? a comprehensive evaluation of llm on automatic paper reviewing tasks
Ruiyang Zhou, Lu Chen, and Kai Yu. Is llm a reliable reviewer? a comprehensive evaluation of llm on automatic paper reviewing tasks. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation, pages 9340– 9351, Torino, Italia, 2024. ELRA and ICCL. URL https://aclanthology.org/2024.lr ec-main.816/
2024
-
[21]
Minjun Zhu et al. Deepreview: Improving llm-based paper review with human-like deep thinking process.Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025
2025
-
[22]
Agentreview: Exploring peer review dynamics with llm agents,
Yixing Jiang and Andrew Ng. Agentreview: Exploring peer review dynamics with llm agents,
-
[23]
Stanford Agentic Reviewer
-
[24]
Marg: Multi-agent review generation for scientific papers, 2024
Mike D’Arcy, Tom Hope, Larry Birnbaum, and Doug Downey. Marg: Multi-agent review generation for scientific papers, 2024
2024
-
[25]
Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022
2022
-
[26]
Direct preference optimization: Your language model is secretly a reward model.Advances in Neural Information Processing Systems, 37, 2024
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in Neural Information Processing Systems, 37, 2024
2024
-
[27]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Deepseekmath-v2: Towards self-verifiable mathematical reasoning.arXiv preprint arXiv:2511.22570,
Zhihong Shao, Yuxiang Luo, Chengda Lu, et al. Deepseekmath-v2: Towards self-verifiable mathematical reasoning.arXiv preprint arXiv:2511.22570, 2025
-
[29]
A general theory of bibliometric and other cumulative advantage processes.Journal of the American Society for Information Science, 27(5):292–306, 1976
Derek J de Solla Price. A general theory of bibliometric and other cumulative advantage processes.Journal of the American Society for Information Science, 27(5):292–306, 1976
1976
-
[30]
Data-driven predictions in the science of science.Science, 355(6324):477–480, 2017
Aaron Clauset, Daniel B Larremore, and Roberta Sinatra. Data-driven predictions in the science of science.Science, 355(6324):477–480, 2017
2017
-
[31]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InInternational Conference on Learning Representations (ICLR), 2022. URL https://openreview.net/forum?id=nZ eVKeeFYf9
2022
-
[32]
Qlora: Efficient finetuning of quantized llms.Advances in Neural Information Processing Systems, 36, 2024
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[33]
Qwen2 technical report, 2024
Qwen Team. Qwen2 technical report, 2024
2024
-
[34]
The proof and measurement of association between two things.The American Journal of Psychology, 15(1):72–101, 1904
Charles Spearman. The proof and measurement of association between two things.The American Journal of Psychology, 15(1):72–101, 1904
1904
-
[35]
MIT Press, 2 edition, 2018
Richard S Sutton and Andrew G Barto.Reinforcement Learning: An Introduction. MIT Press, 2 edition, 2018
2018
-
[36]
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.Nature, 518(7540):529–533, 2015. doi: 10.1038/nature14236
-
[37]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
From ranknet to lambdarank to lambdamart: An overview.Learning, 11 (23-581):81, 2010
Christopher J Burges. From ranknet to lambdarank to lambdamart: An overview.Learning, 11 (23-581):81, 2010. 11
2010
-
[39]
On information and sufficiency.The Annals of Mathematical Statistics, 22(1):79–86, 1951
Solomon Kullback and Richard A Leibler. On information and sufficiency.The Annals of Mathematical Statistics, 22(1):79–86, 1951
1951
-
[40]
The relationship between precision-recall and roc curves
Jesse Davis and Mark Goadrich. The relationship between precision-recall and roc curves. InProceedings of the 23rd International Conference on Machine Learning (ICML), pages 233–240, 2006. doi: 10.1145/1143844.1143874
-
[41]
Evaluation: from precision, recall and f-measure to roc, informedness, markedness and correlation.Journal of Machine Learning Technologies, 2(1):37–63, 2011
David MW Powers. Evaluation: from precision, recall and f-measure to roc, informedness, markedness and correlation.Journal of Machine Learning Technologies, 2(1):37–63, 2011
2011
-
[42]
The relationship between interdisciplinarity and citation impact—a novel perspective on citation accumulation.Humanities and Social Sciences Communications, 10(1):945, 2023
Xiaojing Cai, Xiaozan Lyu, and Ping Zhou. The relationship between interdisciplinarity and citation impact—a novel perspective on citation accumulation.Humanities and Social Sciences Communications, 10(1):945, 2023
2023
-
[43]
Prediction of citation dynamics of individual papers
Michael Golosovsky. Prediction of citation dynamics of individual papers. InCitation Analysis and Dynamics of Citation Networks, SpringerBriefs in Complexity, pages 69–80. Springer,
-
[44]
doi: 10.1007/978-3-030-28169-4_7
-
[45]
Claude 3.5 sonnet
Anthropic. Claude 3.5 sonnet. https://www.anthropic.com/news/claude-3-5-sonnet , 2024
2024
-
[46]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Routledge, 2 edition, 1988
Jacob Cohen.Statistical Power Analysis for the Behavioral Sciences. Routledge, 2 edition, 1988. 12 A Ethical Considerations and Future Work Ethical Considerations.While ReviewGuard is designed to assist editors, misuse could incentivize citation-chasing behavior or reinforce existing citation biases. We recommend deployment only within human-in-the-loop w...
1988
-
[48]
First critical point or suggested improvement
-
[49]
Second critical point or suggested improvement
-
[50]
equivalent to minimizing a convex combination
Overall rating (1-10):[integer between 1 and 10] Be specific, rigorous, evidence-based, and forward-looking in your analysis. Focus on long- term scientific impact rather than short-term conference acceptance criteria. Your review should be of the quality expected at a top-tier venue such as NeurIPS. B.3 Theoretical Derivations Normalization Correction.We...
2018
-
[51]
Exact title match against a corpus of 500k AI/ML papers from Semantic Scholar
-
[52]
For unmatched papers, we computed cosine similarity between TF-IDF vectors of title + abstract (threshold≥0.85)
-
[53]
impactful rejects
Manual verification of 10% random sample achieved 94% accuracy (two independent annotators, Cohen’sκ= 0.89). This yielded 2,365 matched papers (23.1% of rejected papers). Among these, the top 1,000 by future citations form our “impactful rejects” cohort. We verified that none of these 1,000 papers appear in the training split (by paper ID and title), elim...
2024
-
[54]
Reviewers submit their traditional reviews and ratings
-
[55]
ReviewGuard analyzes the submission and produces its ratingrand detailed review
-
[56]
ReviewGuard rating, along with flagged discrepancies (|r− ¯h| ≥1.5)
Editors receive a side-by-side comparison: human average rating vs. ReviewGuard rating, along with flagged discrepancies (|r− ¯h| ≥1.5)
-
[57]
For papers where ReviewGuard assigns a significantly higher rating than reviewers, editors may request additional review or pay closer attention to the model’s reasoning, especially on technical merit and potential future influence. Proxy Signals and Future Improvements.While ReviewGuard currently does not use real-time signals, several practical proxies ...
-
[58]
The CircularEval improvement over random is marginal (∼2-3%) and statistical signifi- cance is not reported
-
[59]
Reliance on ChatGPT for answer normalization may introduce systematic bias; ablation without it is missing
-
[60]
The benchmark focuses heavily on multiple-choice, which does not reflect real-world open-ended VLM use cases
-
[61]
Many ability dimensions (e.g., spatial reasoning, temporal understanding) remain coarsely evaluated
-
[62]
No analysis of test-retest reliability or annotation consistency
-
[63]
The paper does not compare against existing benchmarks (e.g., LVLM-eHub, SEED- Bench) on common subsets
-
[64]
Suggested experiment: Include open-ended generation evaluation and human-correlation analysis. Overall rating:5.0/10 22 ReviewGuard model reviews for high-impact paper Paper:MMBench: Is Your Multimodal Model an All-around Player? (1,618 citations) • Summary (Novelty, Contribution, and Significance):This work introduces MMBench, a large-scale, bilingual be...
-
[65]
Over-reliance on multiple-choice format significantly restricts evaluation of open-ended generation, creativity, and complex multi-step reasoning
-
[66]
Several critical ability dimensions (fine-grained spatial reasoning, temporal under- standing, causal inference, and complex compositional reasoning) remain noticeably under-represented
-
[67]
Dependence on GPT-4 for answer normalization and choice extraction introduces potential bias and reduces full reproducibility of results
-
[68]
CircularEval, while innovative, does not completely eliminate position bias across all question types and difficulty levels
-
[69]
The benchmark lacks strong adversarial examples and out-of-distribution test cases, which are essential for assessing real-world robustness
-
[70]
No systematic analysis or mitigation strategies for cultural, linguistic, or societal biases beyond the English-Chinese bilingual setup
-
[71]
The current protocol does not sufficiently test cross-modal consistency or multi-turn interactive reasoning capabilities
-
[72]
Evaluation of long-context and high-resolution image understanding remains limited
-
[73]
Suggested experiment: Add a dedicated open-ended generation track and adversarial robustness benchmark. Overall rating:7.7/10 23 Expert model review for moderate-impact paper Paper:LLM-QAT: Data-Free Quantization Aware Training for Large Language Models (288 citations) • Summary (Novelty, Contribution, and Significance):This paper introduces LLM-QAT, a pr...
-
[75]
Evaluation is primarily limited to standard perplexity and a small set of zero-shot tasks
-
[76]
Comparison with recent state-of-the-art quantization methods (GPTQ, AWQ, SmoothQuant) is incomplete or outdated in some experiments
-
[78]
Scalability to models significantly larger than 13B parameters is not demonstrated
-
[79]
No analysis of potential negative societal impacts (e.g., easier deployment of quantized models for malicious use)
-
[80]
Lack of ablation on key hyperparameters such as temperature and top-p used for synthetic data generation. Overall rating:6.4/10 24 ReviewGuard model review for moderate-impact paper Paper:LLM-QAT: Data-Free Quantization Aware Training for Large Language Models (288 citations) • Summary (Novelty, Contribution, and Significance):This work presents LLM-QAT, ...
-
[81]
The quality, diversity, and distributional fidelity of the synthetic data generated by the teacher model are not rigorously analyzed or ablated
-
[82]
Evaluation is heavily focused on standard perplexity and a limited set of zero-shot tasks; robustness to distribution shift and long-context scenarios is under-explored
-
[83]
Comparison with recent state-of-the-art quantization methods (GPTQ, AWQ, SmoothQuant, etc.) is incomplete or outdated in several experiments
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.