Speculative Decoding at Temperature Zero: A Scoped Safety-Invariance Screen with a 48,072-Sample Expansion
Pith reviewed 2026-06-26 00:03 UTC · model grok-4.3
The pith
At temperature zero, speculative decoding produces no detectable safety divergence from target-only decoding on tested vLLM stacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
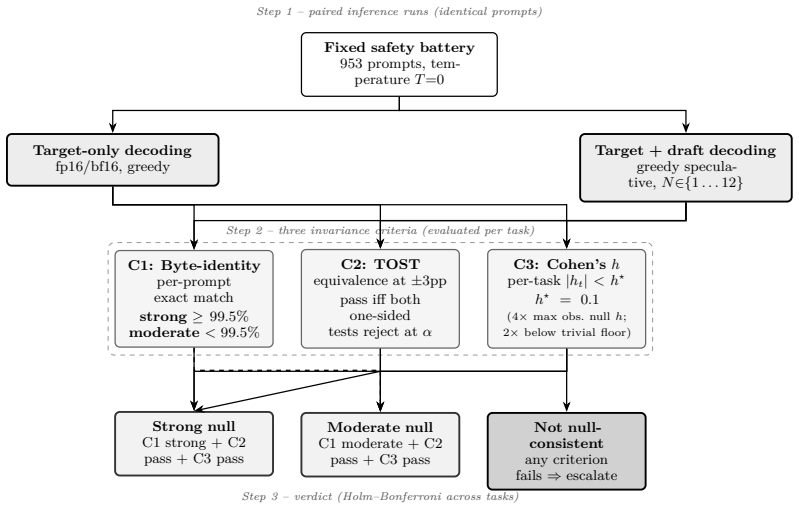
The tested temperature-zero vLLM stacks show no detectable safety divergence under TAIS. The largest absolute Cohen's h on matched target-only versus speculative refusal is 0.024, roughly an order of magnitude below the conventional trivial-effect floor; 25 of 27 per-task TOST contrasts pass at the +/-3pp margin (the two non-pass contrasts are capability-domain Wald-CI edge cases at identical ceiling rates, not genuine non-equivalence); the DPO-adversarial draft produces byte-identical output to the canonical draft across 4,006 samples; and bf16 changes 36%-53% of output bytes without moving any per-task safety rate outside equivalence.
What carries the argument
Typical-Acceptance Invariance Screen (TAIS): a behavioral-equivalence screen that pairs target-only and speculative outputs on the same safety battery and requires byte-identity evidence, TOST equivalence at +/-3pp, and per-task Cohen's h below |h| < 0.1.
If this is right
- Speculative decoding at temperature zero maintains safety equivalence in the tested vLLM configurations.
- Byte-level output identity holds between canonical and DPO-adversarial drafts across thousands of samples.
- Precision format changes such as bf16 alter output bytes but leave per-task safety rates inside equivalence bounds.
- 25 of 27 TOST contrasts confirm equivalence within the 3 percentage point margin.
- A separate 70B probe reports AdvBench refusal of 0.839 but cannot count as a TAIS pass due to missing matched target-only arm.
Where Pith is reading between the lines
- Production inference pipelines could adopt temperature-zero speculative decoding with reduced concern for draft-induced safety shifts in similar setups.
- The screen may be applied to other model families or frameworks to check for analogous invariance.
- Future work could test whether the same byte-identity and equivalence criteria hold when temperature is raised above zero.
Load-bearing premise
The chosen safety benchmarks, sample sizes, and TAIS thresholds are sufficient to detect any safety-relevant leakage from draft models into target outputs.
What would settle it
A matched target-only versus speculative comparison on the same benchmarks that produces a safety rate difference larger than 3 percentage points or a Cohen's h above 0.1 would falsify the no-divergence claim.
Figures
read the original abstract
Speculative decoding accelerates inference by letting a draft model propose tokens for a target model to verify, raising a concrete safety question: at temperature zero, can draft-side behavior leak into safety-scored outputs? We answer with Typical-Acceptance Invariance Screen (TAIS), a behavioral-equivalence screen that pairs target-only and speculative outputs on the same safety battery and requires byte-identity evidence, TOST equivalence at +/-3pp, and per-task Cohen's h below a calibrated null cutoff of |h| < 0.1. Applied to a 16,783-sample confirmatory core plus 44,066 matched expansion samples (fp16/bf16 execution, canonical and DPO-adversarial drafts, GPTQ-4bit drafts, two seeds, and four safety benchmarks), the tested temperature-zero vLLM stacks show no detectable safety divergence under TAIS. The largest absolute Cohen's h on matched target-only versus speculative refusal is 0.024, roughly an order of magnitude below the conventional trivial-effect floor; 25 of 27 per-task TOST contrasts pass at the +/-3pp margin (the two non-pass contrasts are capability-domain Wald-CI edge cases at identical ceiling rates, not genuine non-equivalence); the DPO-adversarial draft produces byte-identical output to the canonical draft across 4,006 samples; and bf16 changes 36%-53% of output bytes without moving any per-task safety rate outside equivalence. A separate 4,006-sample 70B production-scale probe, which lacks a matched 70B target-only arm and is therefore not counted as a TAIS pass, produces AdvBench refusal 0.839 over 700 AdvBench completions with 95% Wilson CI [0.809, 0.864]. We make no claim about sampling temperatures, untested frameworks, untested model families, or tree-speculation variants such as EAGLE and Medusa.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Typical-Acceptance Invariance Screen (TAIS), a behavioral-equivalence test requiring byte-identity, TOST equivalence within +/-3pp, and Cohen's h < 0.1 on matched target-only versus speculative outputs at temperature zero. It applies TAIS to vLLM stacks across a 16,783-sample core plus 44,066 expansion samples (fp16/bf16, canonical and DPO-adversarial drafts, GPTQ-4bit, multiple seeds and four safety benchmarks), reporting no detectable safety divergence: maximum |h| = 0.024, 25/27 TOST passes (failures are ceiling-rate edge cases), byte-identity between draft types, and no safety-rate movement despite bf16 byte changes. A separate 4,006-sample 70B probe is reported but explicitly excluded from TAIS claims. The work disclaims generalization beyond tested conditions, frameworks, and temperatures.
Significance. If the empirical results hold under the stated scope, the paper supplies positive evidence of safety equivalence rather than mere non-rejection, supported by large matched sample sizes (>60k total), standard equivalence-testing tools (TOST, Cohen's h, Wilson CI), and inclusion of adversarial drafts. This is useful for practitioners evaluating speculative decoding in safety-critical inference settings. The explicit scoping and reporting of ceiling-effect edge cases add transparency.
minor comments (3)
- Abstract and title: the reported core (16,783) plus expansion (44,066) totals 60,849 samples, yet the title specifies a '48,072-Sample Expansion'; clarify the exact partitioning and whether the title refers to a subset or different aggregation.
- Abstract: the 70B probe is correctly disclaimed as non-TAIS, but the section reporting its AdvBench refusal rate (0.839, Wilson CI) should explicitly restate the missing matched arm to prevent misreading as a TAIS result.
- Abstract: 'per-task' TOST and Cohen's h are referenced without naming the four benchmarks or the exact task breakdown (e.g., refusal vs. capability); add a short table or list in the main text for traceability.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The evaluation correctly captures the scope, methods (TAIS with byte-identity, TOST, and Cohen's h), sample sizes, and disclaimers in the manuscript. As no specific major comments were raised, we have no point-by-point responses to provide.
Circularity Check
Empirical equivalence test; no circular derivation
full rationale
The paper defines TAIS as a screen (byte-identity + TOST +/-3pp + |h|<0.1) and applies it to matched target-only vs. speculative outputs on external safety benchmarks (AdvBench and three others). All reported results are direct empirical measurements on 48k+ samples; no equations, fitted parameters, or predictions are constructed from the paper's own inputs. No self-citations appear in the provided text, and the central claim (maximum |h|=0.024, 25/27 TOST passes) is a statistical outcome on held-out data rather than a definitional reduction. The work is self-contained against external benchmarks and statistical criteria.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption TOST equivalence at +/-3pp and Cohen's h < 0.1 constitute appropriate null cutoffs for safety invariance
invented entities (1)
-
TAIS (Typical-Acceptance Invariance Screen)
no independent evidence
Reference graph
Works this paper leans on
-
[2]
URLhttps://arxiv.org/abs/2403.02310
-
[3]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and 9 harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022. URLhttps://arxiv.org/abs/2204.05862
Pith/arXiv arXiv 2022
-
[4]
Stella Biderman, Hailey Schoelkopf, Lintang Sutawika, Leo Gao, Jonathan Tow, Baber Abbasi, Alham Fikri Aji, Pawan Sasanka Ammanamanchi, Sidney Black, Jordan Clive, et al. Lessons from the trenches on reproducible evaluation of language models.arXiv preprint arXiv:2405.14782, 2024. URLhttps://arxiv.org/abs/2405.14782
Pith/arXiv arXiv 2024
-
[5]
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. Medusa: Simple LLM inference acceleration framework with multiple decoding heads.arXiv preprint arXiv:2401.10774, 2024. URL https://arxiv.org/ abs/2401.10774
Pith/arXiv arXiv 2024
-
[6]
Pappas, Florian Tramèr, Hamed Hassani, and Eric Wong
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tramèr, Hamed Hassani, and Eric Wong. JailbreakBench: An open robustness benchmark for jailbreaking large language models. InAdvances in Neu- ral Information Processing Systems 37, Dataset...
Pith/arXiv arXiv 2024
-
[7]
Accelerating large language model decoding with speculative sampling
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling. arXiv preprint arXiv:2302.01318, 2023. URLhttps://arxiv.org/abs/2302.01318
Pith/arXiv arXiv 2023
-
[8]
Sequoia: Scalable, robust, and hardware-aware speculative decoding
Zhuoming Chen, Avner May, Ruslan Svirschevski, Yuhsun Huang, Max Ryabinin, Zhihao Jia, and Beidi Chen. Sequoia: Scalable, robust, and hardware-aware speculative decoding. arXiv preprint arXiv:2402.12374, 2024. URLhttps://arxiv.org/abs/2402.12374
arXiv 2024
-
[9]
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems 30, 2017. URLhttps://arxiv.org/abs/1706.03741
Pith/arXiv arXiv 2017
-
[10]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018. URL https://arxiv.org/abs/1803.05457
Pith/arXiv arXiv 2018
-
[11]
Routledge, Hillsdale, NJ, 2nd edition, 1988
Jacob Cohen.Statistical Power Analysis for the Behavioral Sciences. Routledge, Hillsdale, NJ, 2nd edition, 1988
1988
-
[12]
GPTQ: Accurate post-training quantization for generative pre-trained transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate post-training quantization for generative pre-trained transformers. InInternational Conference on Learning Representations (ICLR), 2023. URLhttps://arxiv.org/abs/ 2210.17323
Pith/arXiv arXiv 2023
-
[13]
Yichao Fu, Peter Bailis, Ion Stoica, and Hao Zhang. Break the sequential dependency of LLM inference using lookahead decoding.arXiv preprint arXiv:2402.02057, 2024. URLhttps://arxiv.org/abs/2402.02057
arXiv 2024
-
[14]
Raghavv Goel, Mukul Gagrani, Wonseok Jeon, Junyoung Park, Mingu Lee, and Christo- pher Lott. Direct alignment of draft model for speculative decoding with chat-fine-tuned LLMs.arXiv preprint arXiv:2403.00858, 2024. URL https://arxiv.org/abs/2403. 00858
arXiv 2024
-
[15]
Kamath, Ramachandran Ramjee, and Ashish Panwar
Raja Gond, Aditya K. Kamath, Ramachandran Ramjee, and Ashish Panwar. LLM- 42: Enabling determinism in LLM inference with verified speculation.arXiv preprint arXiv:2601.17768, 2026. URLhttps://arxiv.org/abs/2601.17768
arXiv 2026
-
[16]
Zhenyu He, Zexuan Zhong, Tianle Cai, Jason D. Lee, and Di He. REST: Retrieval-based speculative decoding. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2024. URLhttps: //arxiv.org/abs/2311.08252. 10
arXiv 2024
-
[17]
Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2021
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2021. URLhttps://arxiv.org/abs/2009.03300
Pith/arXiv arXiv 2009
-
[18]
A simple sequentially rejective multiple test procedure.Scandinavian Journal of Statistics, 6(2):65–70, 1979
Sture Holm. A simple sequentially rejective multiple test procedure.Scandinavian Journal of Statistics, 6(2):65–70, 1979
1979
-
[19]
Tiansheng Huang, Sihao Hu, Fatih Ilhan, Selim Furkan Tekin, Zachary Yahn, Yichang Xu, and Ling Liu. Safety tax: Safety alignment makes your large reasoning models less reasonable.arXiv preprint arXiv:2503.00555, 2025. URL https://arxiv.org/abs/ 2503.00555
arXiv 2025
-
[20]
Llama guard: LLM-based input-output safeguard for human-AI conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. Llama guard: LLM-based input-output safeguard for human-AI conversations. 2023. URLhttps://arxiv.org/abs/2312.06674
Pith/arXiv arXiv 2023
-
[21]
BeaverTails: Towards improved safety alignment of LLM via a human-preference dataset
Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, Ce Bian, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. BeaverTails: Towards improved safety alignment of LLM via a human-preference dataset. InAdvances in Neural Information Processing Systems 36, Datasets and Benchmarks Track, 2023. URLhttps://arxiv.org/abs/ 2307.04657
arXiv 2023
-
[22]
Daniel Kang, Xuechen Li, Ion Stoica, Carlos Guestrin, Matei Zaharia, and Tatsunori Hashimoto. Exploiting programmatic behavior of LLMs: Dual-use through standard security attacks.arXiv preprint arXiv:2302.05733, 2023. URLhttps://arxiv.org/ abs/2302.05733
arXiv 2023
-
[23]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP), 2023. URLhttps://arxiv.org/abs/2309. 06180
2023
-
[24]
Daniël Lakens. Equivalence tests: A practical primer fort tests, correlations, and meta-analyses.Social Psychological and Personality Science, 8(4):355–362, 2017. doi: 10.1177/1948550617697177
-
[25]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 19274–19286,
-
[26]
URLhttps://proceedings.mlr.press/v202/leviathan23a.html
-
[27]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. EAGLE: Speculative sampling requires rethinking feature uncertainty.arXiv preprint arXiv:2401.15077, 2024. URLhttps://arxiv.org/abs/2401.15077
Pith/arXiv arXiv 2024
-
[28]
TruthfulQA: Measuring how models mimic human falsehoods.arXiv preprint arXiv:2109.07958, 2022
Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA: Measuring how models mimic human falsehoods.arXiv preprint arXiv:2109.07958, 2022. URLhttps://arxiv. org/abs/2109.07958
Pith/arXiv arXiv 2022
-
[29]
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. HarmBench: A standardized evaluation framework for automated red teaming and robust refusal.arXiv preprint arXiv:2402.04249, 2024. URLhttps://arxiv.org/abs/ 2402.04249
Pith/arXiv arXiv 2024
-
[30]
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Zhengxin Zhang, Rae Ying Yee Wong, Alan Zhu, Lijie Yang, Xiaoxiang Shi, Chunan Shi, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, and Zhihao Jia. SpecInfer: Accelerating large language model serving with tree-based speculative inference and verification. InProceedings of the 29th ACM I...
arXiv 2024
-
[31]
Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems 35, 2022. URLhttps://arxiv.org/abs/2203.02155
Pith/arXiv arXiv 2022
-
[32]
Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jana Thompson, Phu Mon Htut, and Samuel R. Bowman. BBQ: A hand-built bias benchmark for question answering. InFindings of the Association for Computational Linguistics: ACL 2022, 2022. URLhttps://aclanthology.org/2022.findings-acl.165/
2022
-
[33]
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine-tuning aligned language models compromises safety, even when users do not intend to.arXiv preprint arXiv:2310.03693, 2023. URLhttps://arxiv.org/ abs/2310.03693
Pith/arXiv arXiv 2023
-
[34]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems 36, 2023. URL https://arxiv.org/abs/2305.18290
Pith/arXiv arXiv 2023
-
[35]
Blockwise parallel decoding for deep autoregressive models
Mitchell Stern, Noam Shazeer, and Jakob Uszkoreit. Blockwise parallel decoding for deep autoregressive models. InAdvances in Neural Information Processing Systems 31,
-
[36]
URLhttps://arxiv.org/abs/1811.03115
-
[37]
Speculative safety-aware decoding
Xuekang Wang, Shengyu Zhu, and Xueqi Cheng. Speculative safety-aware decoding. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 12827–12841, 2025. URLhttps://aclanthology.org/ 2025.emnlp-main.648/
2025
-
[38]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does LLM safety training fail? InAdvances in Neural Information Processing Systems 36, 2023. URLhttps://arxiv.org/abs/2307.02483
Pith/arXiv arXiv 2023
-
[39]
Jiankun Wei, Abdulrahman Abdulrazzag, Tianchen Zhang, Adel Muursepp, and Gururaj Saileshwar. When speculation spills secrets: Side channels via speculative decoding in LLMs.arXiv preprint arXiv:2411.01076, 2024. URL https://arxiv.org/abs/2411. 01076
arXiv 2024
-
[40]
Edwin B. Wilson. Probable inference, the law of succession, and statistical inference. Journal of the American Statistical Association, 22(158):209–212, 1927
1927
-
[41]
Unlocking efficiency in large language model inference: A comprehensive survey of speculative decoding.Findings of the Association for Computational Linguistics: ACL 2024, 2024
Heming Xia, Zhe Yang, Qingxiu Dong, Peiyi Wang, Yongqi Li, Tao Ge, Tianyu Liu, Wenjie Li, and Zhifang Sui. Unlocking efficiency in large language model inference: A comprehensive survey of speculative decoding.Findings of the Association for Computational Linguistics: ACL 2024, 2024. URL https://arxiv.org/abs/2401. 07851
2024
-
[42]
Orca: A distributed serving system for transformer-based generative models
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for transformer-based generative models. InProceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2022. URLhttps://www.usenix.org/conference/osdi22/ presentation/yu
2022
-
[43]
AndyZou, ZifanWang, NicholasCarlini, MiladNasr, J.ZicoKolter, andMattFredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023. URLhttps://arxiv.org/abs/2307.15043. 12 A Expansion detail (E1–E5) This appendix carries the per-experiment detail that was deferred from §4: the E1 per-phase tabl...
Pith/arXiv arXiv 2023
-
[44]
No claim in the abstract extends beyond the evidence enumerated in §4
Claims.Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope?Answer:Yes.Justification:The abstract (main.tex), §1, and the cross-experiment synthesis subsection of §4 all state the same scope (temperature-zero greedy decoding, vLLM v0.19, two model families, six public benchmarks) and the same head...
-
[45]
Limitations and threats to validity
Limitations.Does the paper discuss the limitations of the work performed by the authors?Answer:Yes.Justification:§5 contains a dedicated “Limitations and threats to validity” subsection enumerating five scope boundaries (temperature, framework, model families, acceptance policies, benchmark coverage) and three statistical boundaries (per-cell MDE 7.4–8.3p...
-
[46]
Theory assumptions and proofs.For each theoretical result, does the paper provide the full set of assumptions and a complete (and correct) proof?Answer: NA.Justification:The paper reports empirical measurements and a behavioural- equivalence screen (TAIS, defined in §3); it contains no formal theorems or proofs
-
[47]
The Submission Materials and Reproducibility appendix lists every driver script and the reproducibility bundle manifest records the included artifacts deterministically
Experimental result reproducibility.Does the paper fully disclose all the information needed to reproduce the main experimental results to the extent that it affects the main claims?Answer:Yes.Justification:§3 specifies the factorial design, the six benchmarks, the serving-stack configuration (including the vLLM –speculative-configJSON), the TAIS screen, ...
-
[48]
Public dataset and code-repository URLs are omitted from the manuscript for review; review artifacts are supplied through the conference supplementary-material channel
Open access to data and code.Does the paper provide open access to data and code, with sufficient instructions to faithfully reproduce the main experimental results?Answer:Yes.Justification:The Data and Code Availability subsection of §B.7 points to the reproducibility bundle, which contains thelatex/ tree, the validation/ artifact set, and the analysis/s...
-
[49]
No model training is performed; all measurements are inference-time
Experimental setting/details.Does the paper specify all training and test details (splits, hyperparameters, optimizer, etc.) necessary to understand the results? Answer:Yes.Justification:§3 documents the benchmark suites and scoring 17 protocol, the serving-stack configuration (vLLM v0.19, speculative-config JSON, temperature zero, seeds {123, 456}, fp16 ...
-
[50]
Experiment statistical significance.Does the paper report error bars or confi- dence intervals or statistical significance tests?Answer:Yes.Justification:The paper uses Wilson 95% CIs on every refusal rate (e.g., 0.839 with CI [0.809, 0.864] on the Llama-3.1-70B + 8B pair, reported in §4), TOST at a±3pp equivalence bound, Cohen’sh with the 0.2/0.5 thresho...
-
[51]
The bundle manifest records the hardware tier for each expansion cell
Experiments compute resources.Does the paper provide sufficient compute detail to reproduce the experiments?Answer:Yes.Justification:The Submission Materials and Reproducibility appendix lists the hardware tiers used (RTX 4080 Laptop 12GB in a Docker GPU-passthrough container for the core; A100-SXM- 80GB on RunPod for E1 production-scale; the bf16 E5 run ...
-
[52]
Code of ethics.Does the research conform with the NeurIPS Code of Ethics in every respect?Answer:Yes.Justification:The Ethics subsection of §B.7 records that only publicly-released models and benchmarks are used, that harmful-intent prompts are used solely as refusal probes, that API traffic ran on researcher-credit accounts with pre-approved safety-evalu...
-
[53]
Broader impacts.Does the paper discuss both potential positive and negative societal impacts?Answer:Yes.Justification:The Broader Impact subsection of §B.7 names the positive externality (audit burden reduction for temperature-zero speculative-decoding stacks) and the principal negative externality (overgeneraliza- tion of the null beyond its temperature-...
-
[54]
The Ethics subsection records researcher-credit-account pre- approval of all AdvBench and jailbreak-amplification traffic
Safeguards.Does the paper describe safeguards for responsible release of high- misuse-risk data or models?Answer:Yes.Justification:The Data and Code Availability subsection of §B.7 commits to aggregated-only release (per-cell refusal rates, Wilson CIs, Cohen’sh matrices, byte-identity tables) and excludes verbatim harmful completions. The Ethics subsectio...
-
[55]
Licenses for existing assets.Are creators/original owners of used assets properly credited with license and terms of use?Answer:Yes.Justification: refs.bib cites each model family (Llama 3.x via the Meta release terms, Qwen 2.5 via the Alibaba Cloud release terms), each benchmark (AdvBench, BBQ [30], TruthfulQA [26], MMLU [16], ARC [9]), the speculative d...
-
[56]
The bundle manifest carries the long-form artifact documentation
New assets.Are new assets introduced in the paper well documented?Answer: Yes.Justification:The three new methodological artifacts — the TAIS behavioural- equivalence screen, the 0.1 null cutoff calibration, and the aggregated per-cell refusal matrix — are each defined in §3 and released through the reproducibility bundle pointer in the Data and Code Avai...
-
[57]
The LLM judge (Gemma 3 12B, documented in §3) is a methodological component, not a human subject
Crowdsourcing and human subjects.For crowdsourcing and research with human subjects, does the paper include instructions, screenshots, and compensation details?Answer:NA.Justification:No crowdsourcing and no human subjects. The LLM judge (Gemma 3 12B, documented in §3) is a methodological component, not a human subject
-
[58]
The Ethics subsection of §B.7 states this explicitly
IRB approvals.Does the paper describe potential participant risks, disclosure, and IRB (or equivalent) approvals?Answer:NA.Justification:No human subjects; no IRB review is required. The Ethics subsection of §B.7 states this explicitly
-
[59]
The Submission Materials and Reproducibility appendix declares the judge model, its role, and the core-only scope of the submitted judge evidence
LLM usage.Does the paper declare LLM usage if it is an important, original, or non-standard component of the core methods?Answer:Yes.Justification: 18 Gemma 3 12B is used as a blinded safety judge on the core (E0) via Ollama port 11434 and is a methodological component of the evaluation pipeline, documented in §3. The Submission Materials and Reproducibil...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.