ClarifyCodeBench: Evaluating LLMs on Clarifying Ambiguous Requirements for Code Generation
Pith reviewed 2026-07-02 08:37 UTC · model grok-4.3
The pith
LLMs that generate code well still struggle to clarify ambiguous requirements and get worse with more ambiguities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
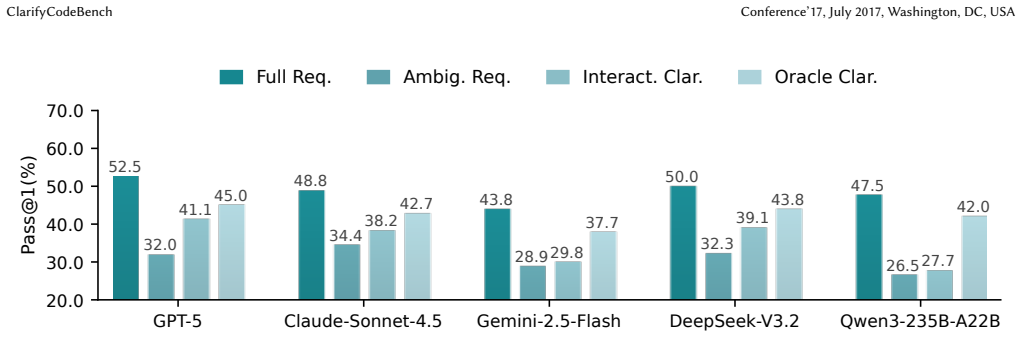
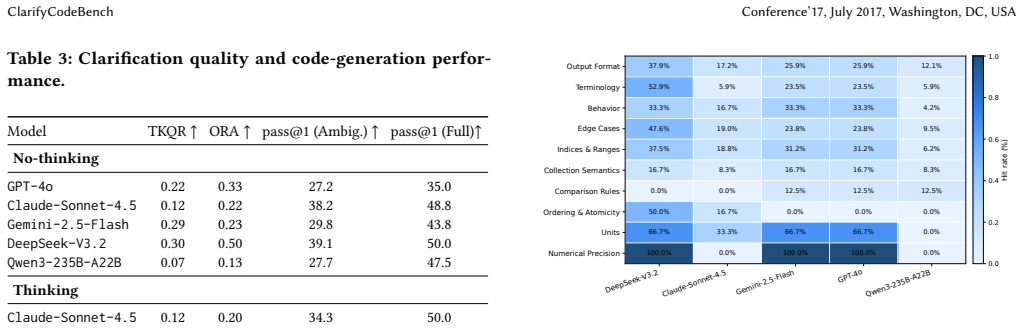
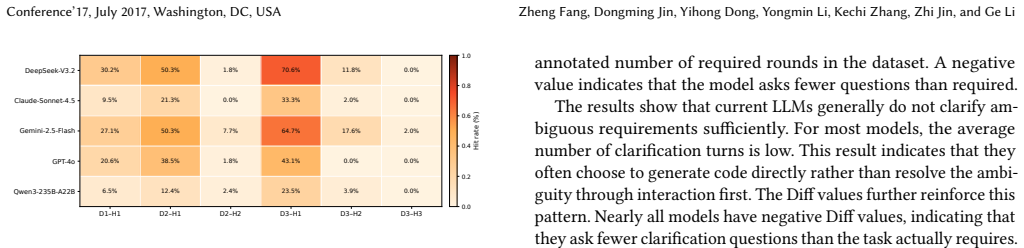
ClarifyCodeBench supplies annotated real-world tasks, N ambiguity types, clarification questions, and ground-truth answers. Its two metrics are Turn-discounted Key Question Rate, which reduces credit for inefficient or redundant questions, and Optimal Round Adherence, which checks whether the model reaches a complete specification in the expected number of turns. Systematic tests of six state-of-the-art LLMs produce three findings: code-generation strength does not imply clarification strength, heavier reasoning improves code correctness but yields only marginal clarification gains, and clarification performance drops sharply as ambiguity density rises.
What carries the argument
ClarifyCodeBench benchmark together with Turn-discounted Key Question Rate and Optimal Round Adherence metrics that quantify interactive clarification quality.
If this is right
- Strong code generation ability does not guarantee effective requirement clarification.
- Extra computational reasoning steps improve code correctness more than they improve ambiguity detection.
- Clarification performance declines sharply once multiple ambiguities appear in a specification.
- AI4SE research must move from static one-shot synthesis toward interactive elicitation methods.
Where Pith is reading between the lines
- Training regimes focused only on code completion may need to be supplemented with explicit clarification dialogue data.
- Hybrid human-AI workflows could remain necessary for projects whose requirements contain many ambiguities.
- Extending the benchmark to longer, open-ended conversations might expose further limits not captured by the current optimal-round metric.
Load-bearing premise
The manually chosen ambiguities and the two proposed metrics correctly capture what matters for clarification quality in real software engineering work.
What would settle it
A controlled study in which an LLM scores high on ClarifyCodeBench yet still produces many incorrect implementations when given the same ambiguous tasks by actual developers would undermine the claim that the benchmark measures relevant capability.
Figures





read the original abstract
Large Language Models have emerged as programming assistants. However, the efficacy of code generation is constrained by the quality of input requirements, which are frequently ambiguous, incomplete, or underspecified. While LLMs excel at one-shot code synthesis, their ability to proactively clarify intent remains underexplored, as a critical trait for robust software engineering. Existing benchmarks largely overlook this interactive bottleneck, assuming perfectly specified prompts that do not reflect the iterative nature of requirement elicitation. To bridge this gap, we introduce ClarifyCodeBench, a novel interactive benchmark for evaluating LLMs' capability in resolving requirement ambiguity. Constructed from real-world programming tasks, ClarifyCodeBench features high-quality manual annotations, including N unique ambiguity types, associated clarification questions, and corresponding ground-truth answers. Furthermore, we formalize two rigorous metrics to assess the interaction quality: Turn-discounted Key Question Rate, which penalizes inefficient questioning, and Optimal Round Adherence, which measures the precision of the elicitation process. We conduct a systematic evaluation of six state-of-the-art LLMs using ClarifyCodeBench. Our empirical results yield three critical insights: 1) Capability Decoupling: Strong code generation performance does not inherently translate to effective requirement clarification; 2) The Reasoning Paradox: While increased computational thinking enhances code correctness, it yields marginal gains in identifying ambiguities; 3) The Multi-ambiguity Ceiling: LLMs' clarification performance degrades sharply as the density of ambiguities increases, revealing a significant bottleneck in handling complex, real-world specifications. Our work underscores the necessity for future AI4SE research to transition from static synthesis to interactive elicitation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ClarifyCodeBench, an interactive benchmark constructed from real-world programming tasks with high-quality manual annotations of ambiguity types, clarification questions, and ground-truth answers. It defines two metrics (Turn-discounted Key Question Rate and Optimal Round Adherence) and evaluates six state-of-the-art LLMs, reporting three insights: capability decoupling between code generation and clarification, a reasoning paradox where more computation aids correctness but not ambiguity detection, and a multi-ambiguity ceiling where performance degrades with higher ambiguity density.
Significance. If the benchmark construction, annotation validity, and metric soundness are rigorously established, the work would be significant for AI4SE by demonstrating that current LLMs have fundamental limitations in interactive requirement elicitation and by motivating a shift from static code synthesis to interactive clarification. The three insights, if supported, would provide actionable guidance on model weaknesses in handling real-world specifications.
major comments (2)
- [ClarifyCodeBench construction] The section describing ClarifyCodeBench construction asserts construction from real-world tasks with 'high-quality manual annotations' including N unique ambiguity types, associated questions, and ground-truth answers, but supplies no protocol details, annotator count, inter-annotator agreement, ambiguity identification method, or ground-truth validation procedure. This is load-bearing for the central claims, as the three insights (capability decoupling, reasoning paradox, multi-ambiguity ceiling) cannot be interpreted without evidence that the benchmark faithfully represents software engineering practice.
- [Evaluation] The evaluation section reports results on six LLMs and the three insights but provides no dataset size, statistical tests, or validation that the two proposed metrics correlate with actual software engineering outcomes. Without these, the reported effects cannot be distinguished from benchmark artifacts.
minor comments (2)
- [Abstract] The abstract uses the placeholder 'N' for the number of ambiguity types; replace with the actual count and ensure consistency throughout the manuscript.
- [Metrics] Ensure all metric definitions and any tables reporting per-model or per-ambiguity results include clear notation and units.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the transparency of the benchmark and evaluation.
read point-by-point responses
-
Referee: [ClarifyCodeBench construction] The section describing ClarifyCodeBench construction asserts construction from real-world tasks with 'high-quality manual annotations' including N unique ambiguity types, associated questions, and ground-truth answers, but supplies no protocol details, annotator count, inter-annotator agreement, ambiguity identification method, or ground-truth validation procedure. This is load-bearing for the central claims, as the three insights (capability decoupling, reasoning paradox, multi-ambiguity ceiling) cannot be interpreted without evidence that the benchmark faithfully represents software engineering practice.
Authors: We agree that the absence of detailed annotation protocols limits the interpretability of the benchmark and the three insights. The submitted manuscript provides only a high-level description. In the revised version we will expand the construction section with the requested information: annotator count and expertise, inter-annotator agreement, the ambiguity identification procedure, and ground-truth validation steps. This addition will directly support claims about fidelity to real-world software engineering practice. revision: yes
-
Referee: [Evaluation] The evaluation section reports results on six LLMs and the three insights but provides no dataset size, statistical tests, or validation that the two proposed metrics correlate with actual software engineering outcomes. Without these, the reported effects cannot be distinguished from benchmark artifacts.
Authors: We agree that the evaluation section requires greater statistical rigor and justification. The manuscript currently omits explicit dataset size and statistical tests. We will revise it to report the dataset size, include statistical significance tests for the observed differences, and add a discussion of how the two metrics align with established software engineering outcomes in the literature on requirement elicitation. A new empirical correlation study is beyond the scope of the current work, but the expanded discussion will address the concern about benchmark artifacts. revision: partial
Circularity Check
No circularity: empirical benchmark evaluation with no derivation chain
full rationale
The paper is a pure empirical study introducing ClarifyCodeBench and reporting LLM evaluation results. No equations, derivations, fitted parameters, or predictions appear in the provided text. The three insights are direct observations from benchmark runs, not reductions of any claimed result to its own inputs. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. The work is self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
2025.Claude Sonnet 4.5 System Card
Anthropic. 2025.Claude Sonnet 4.5 System Card. Technical Report. Anthropic. https://www.anthropic.com/claude-sonnet-4-5-system-card
2025
-
[3]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models.arXiv preprint arXiv:2108.07732(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Sher Badshah and Hassan Sajjad. 2025. Reference-Guided Verdict: LLMs-as-Judges in Automatic Evaluation of Free-Form QA. InProceedings of the 9th Widening NLP Workshop. 251–267
2025
-
[5]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Jacob Cohen. 1960. A coefficient of agreement for nominal scales.Educational and psychological measurement20, 1 (1960), 37–46
1960
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Alan Davis, Scott Overmyer, Kathleen Jordan, Joseph Caruso, Fatma Dandashi, Anhtuan Dinh, Gary Kincaid, Glen Ledeboer, Patricia Reynolds, Pradip Sitaram, et al. 1993. Identifying and measuring quality in a software requirements specifi- cation. In[1993] Proceedings First International Software Metrics Symposium. Ieee, 141–152
1993
-
[9]
Yihong Dong, Xue Jiang, Zhi Jin, and Ge Li. 2024. Self-collaboration code genera- tion via chatgpt.ACM Transactions on Software Engineering and Methodology33, 7 (2024), 1–38
2024
-
[10]
Sarah Fakhoury, Aaditya Naik, Georgios Sakkas, Saikat Chakraborty, and Shu- vendu K Lahiri. 2024. Llm-based test-driven interactive code generation: User study and empirical evaluation.IEEE Transactions on Software Engineering50, 9 (2024), 2254–2268
2024
-
[11]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. 2025. Deepseek-r1: Incen- tivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [12]
-
[13]
A Handbook. 2003. From contract drafting to software specification: Linguistic sources of ambiguity
2003
-
[14]
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, et al. 2021. Mea- suring coding challenge competence with apps.arXiv preprint arXiv:2105.09938 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
2018.IEEE: ISO/IEC/IEEE 29148: 2018-Systems and software engineering- Life cycle processes-Requirements engineering
IEC ISO. 2018.IEEE: ISO/IEC/IEEE 29148: 2018-Systems and software engineering- Life cycle processes-Requirements engineering. Technical Report. Technical report, ISO IEEE IEC
2018
-
[17]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. 2024. Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Kalervo Järvelin and Jaana Kekäläinen. 2002. Cumulated gain-based evaluation of IR techniques.ACM Transactions on Information Systems (TOIS)20, 4 (2002), 422–446
2002
-
[19]
Kalervo Järvelin and Jaana Kekäläinen. 2017. IR evaluation methods for retrieving highly relevant documents. InACM SIGIR Forum, Vol. 51. ACM New York, NY, USA, 243–250
2017
-
[20]
Xue Jiang, Yihong Dong, Lecheng Wang, Zheng Fang, Qiwei Shang, Ge Li, Zhi Jin, and Wenpin Jiao. 2024. Self-planning code generation with large language models.ACM Transactions on Software Engineering and Methodology33, 7 (2024), 1–30
2024
-
[21]
Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. 2025. Llms get lost in multi-turn conversation.arXiv preprint arXiv:2505.06120(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
J Richard Landis and Gary G Koch. 1977. The measurement of observer agreement for categorical data.biometrics(1977), 159–174
1977
- [23]
-
[24]
Jia Li, Ge Li, Yongmin Li, and Zhi Jin. 2025. Structured chain-of-thought prompt- ing for code generation.ACM Transactions on Software Engineering and Method- ology34, 2 (2025), 1–23
2025
-
[25]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al . 2025. Deepseek- v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Fangwen Mu, Lin Shi, Song Wang, Zhuohao Yu, Binquan Zhang, ChenXue Wang, Shichao Liu, and Qing Wang. 2024. Clarifygpt: A framework for enhancing llm-based code generation via requirements clarification.Proceedings of the ACM on Software Engineering1, FSE (2024), 2332–2354
2024
-
[27]
Elise Paradis, Kate Grey, Quinn Madison, Daye Nam, Andrew Macvean, Vahid Meimand, Nan Zhang, Benjamin Ferrari-Church, and Satish Chandra. 2025. How Much Does AI Impact Development Speed? an Enterprise-Based Randomized Controlled Trial. InSEIP@ICSE. IEEE, 618–629
2025
-
[28]
Agnia Sergeyuk, Yaroslav Golubev, Timofey Bryksin, and Iftekhar Ahmed. 2025. Using AI-based coding assistants in practice: State of affairs, perceptions, and ways forward.Inf. Softw. Technol.178 (2025), 107610
2025
-
[29]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al
-
[30]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [31]
- [32]
-
[33]
Sizhe Wang, Zhengren Wang, Dongsheng Ma, Yongan Yu, Rui Ling, Zhiyu Li, Feiyu Xiong, and Wentao Zhang. 2025. Codeflowbench: A multi-turn, iterative benchmark for complex code generation.arXiv preprint arXiv:2504.21751(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Weisz, Shraddha Vijay Kumar, Michael J
Justin D. Weisz, Shraddha Vijay Kumar, Michael J. Muller, Karen-Ellen Browne, Arielle Goldberg, Katrin Ellice Heintze, and Shagun Bajpai. 2025. Examining the Use and Impact of an AI Code Assistant on Developer Productivity and Experience in the Enterprise. InCHI Extended Abstracts. ACM, 673:1–673:13
2025
-
[35]
Jie JW Wu, Manav Chaudhary, Davit Abrahamyan, Arhaan Khaku, Anjiang Wei, and Fatemeh H Fard. 2025. Clarifycoder: Clarification-aware fine-tuning for programmatic problem solving.arXiv e-prints(2025), arXiv–2504
2025
-
[36]
Jie JW Wu and Fatemeh H Fard. 2025. Humanevalcomm: Benchmarking the communication competence of code generation for llms and llm agents.ACM Transactions on Software Engineering and Methodology34, 7 (2025), 1–42
2025
-
[37]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2025. De- mystifying llm-based software engineering agents.Proceedings of the ACM on Software Engineering2, FSE (2025), 801–824
2025
-
[38]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems37 (2024), 50528–50652
2024
- [40]
-
[41]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems36 (2023), 46595–46623
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.