HyperNOMAD: Hyperparameter optimization of deep neural networks using mesh adaptive direct search
Pith reviewed 2026-05-25 10:25 UTC · model grok-4.3
The pith
Mesh adaptive direct search can optimize both architecture and learning hyperparameters of deep neural networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HyperNOMAD applies the MADS algorithm to simultaneously tune the hyperparameters responsible for both the architecture and the learning process of a deep neural network, taking advantage of categorical variables for flexibility in the exploration of the search space, and achieves results comparable to the current state of the art on the MNIST and CIFAR-10 data sets.
What carries the argument
The Mesh Adaptive Direct Search (MADS) algorithm extended to handle categorical variables, used to search the mixed continuous-categorical space of DNN hyperparameters.
If this is right
- Enables tuning of both continuous and categorical hyperparameters in a single derivative-free optimization run.
- Produces network configurations whose accuracy on MNIST and CIFAR-10 matches levels reported by existing tuning methods.
- Avoids the need for gradient information when the performance surface is treated as a black-box function.
- Supports direct inclusion of discrete architectural decisions without separate handling stages.
Where Pith is reading between the lines
- The same search strategy could be tested on regression or sequence-modeling tasks that also mix numerical and categorical hyperparameters.
- Direct head-to-head counts of function evaluations against Bayesian optimization or evolutionary methods would clarify relative efficiency.
- Scaling behavior on networks with thousands of hyperparameters remains open and could be checked by increasing depth or width in controlled experiments.
Load-bearing premise
That the MADS algorithm, when extended with categorical variable handling, can locate competitive hyperparameter configurations in the high-dimensional mixed search space of a DNN without excessive computational cost or premature convergence.
What would settle it
A run of HyperNOMAD on CIFAR-10 that produces a best accuracy more than two percentage points below the best literature result after a similar number of evaluations.
Figures


read the original abstract
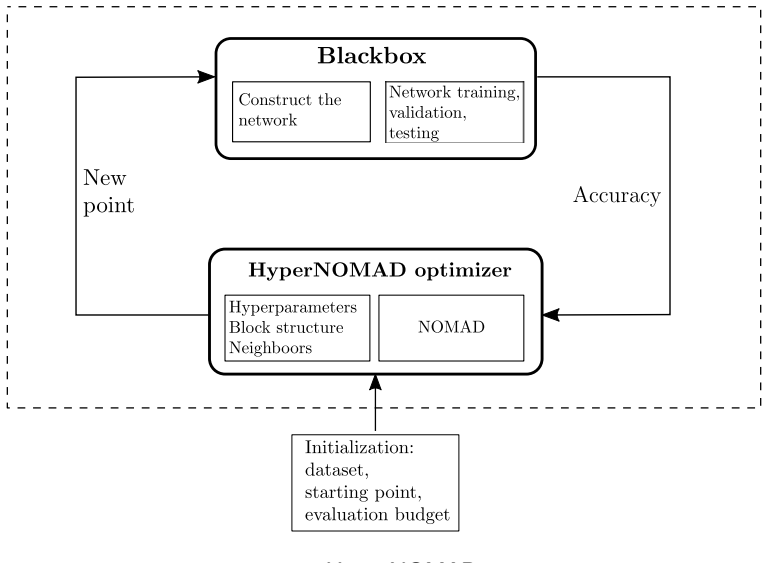
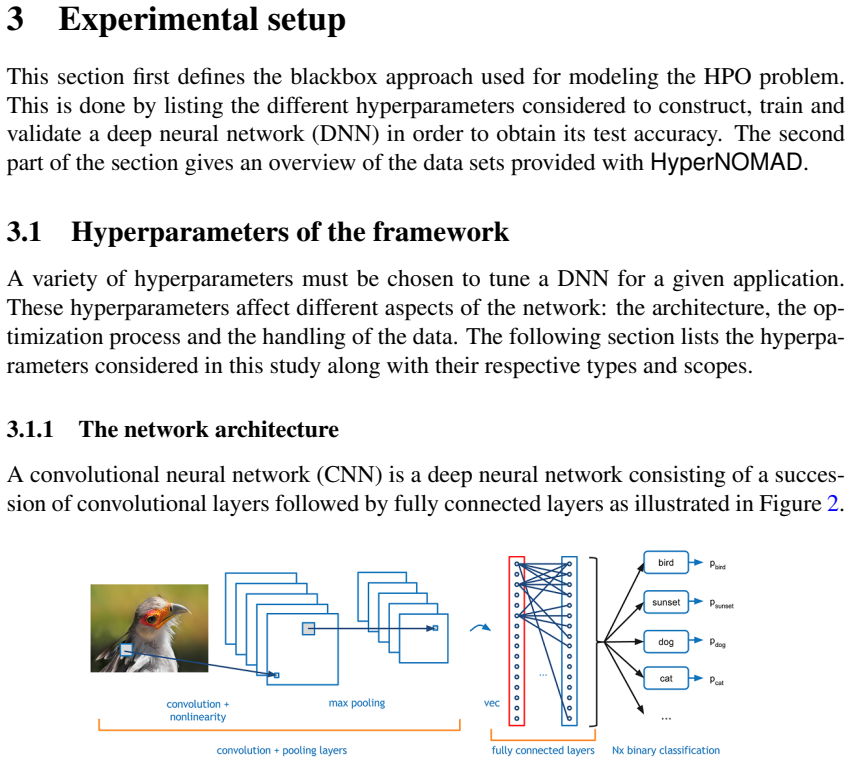
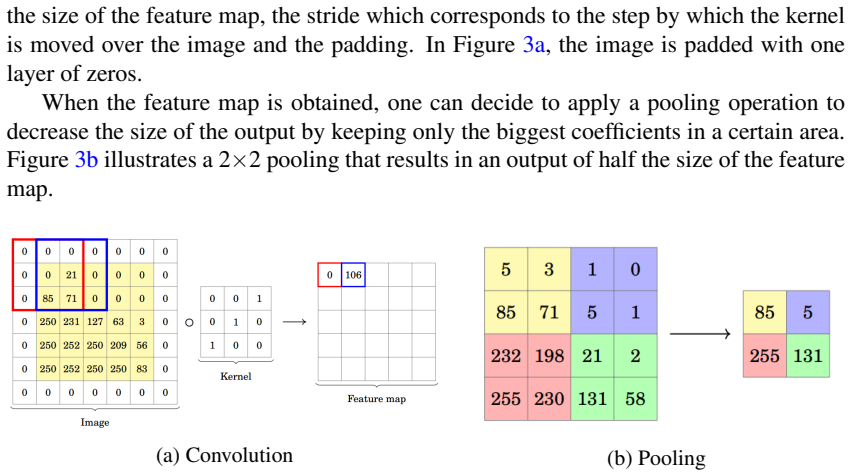
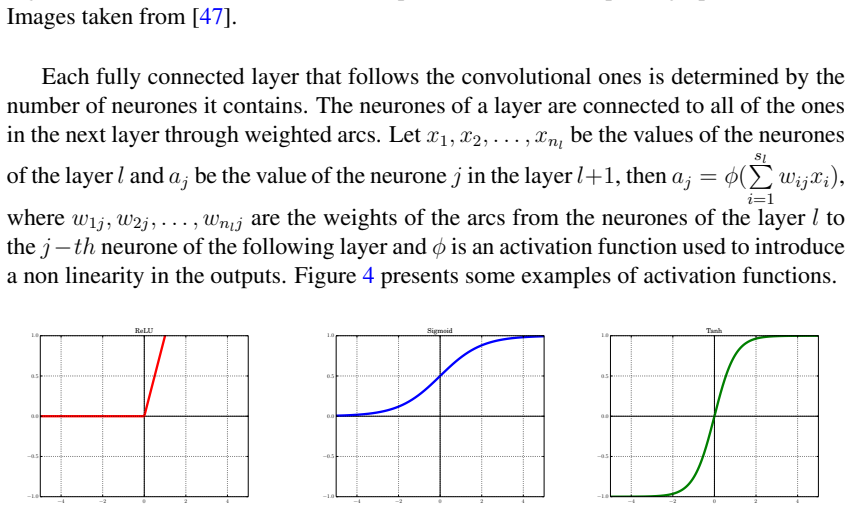
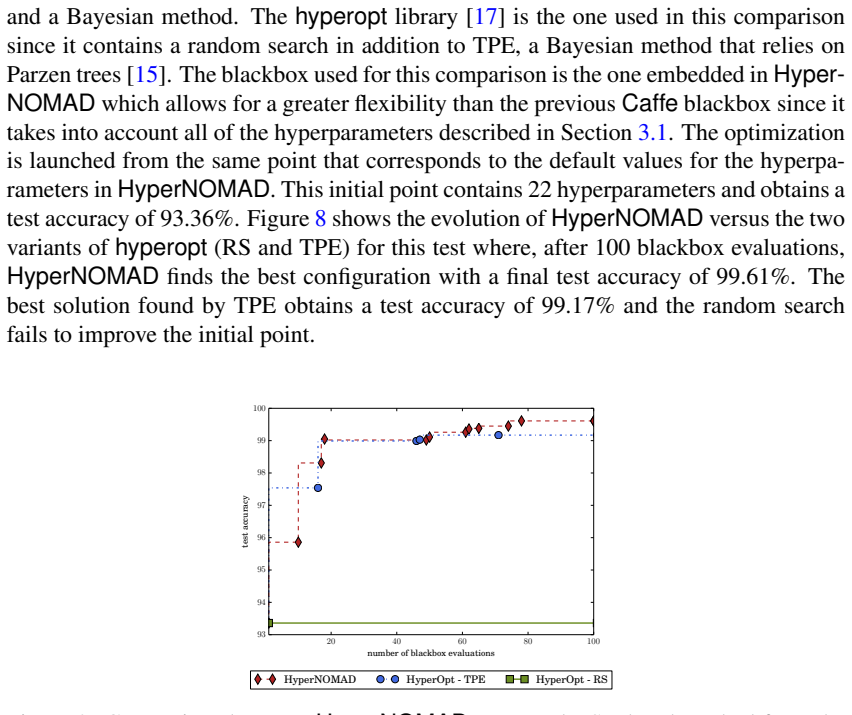
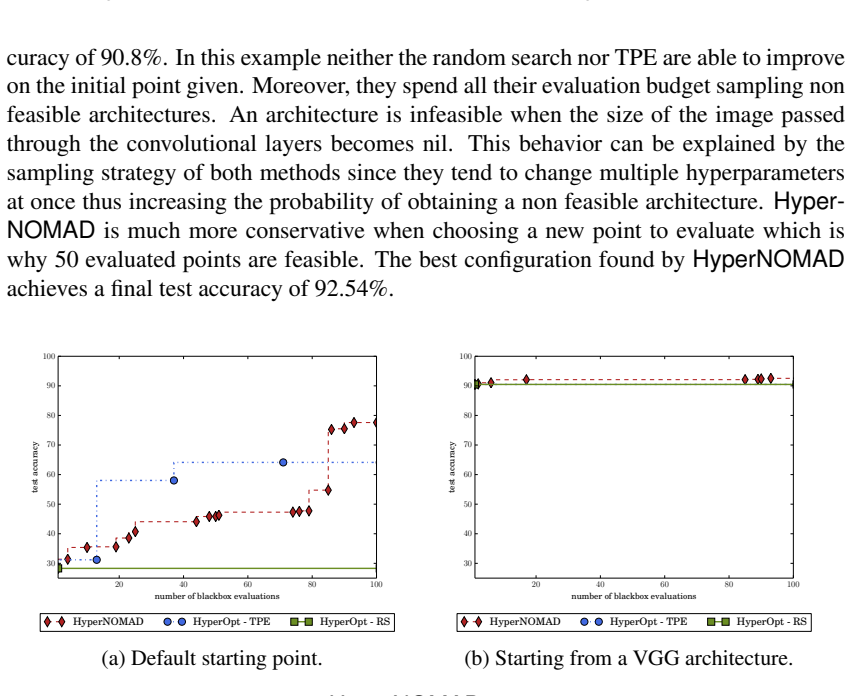
The performance of deep neural networks is highly sensitive to the choice of the hyperparameters that define the structure of the network and the learning process. When facing a new application, tuning a deep neural network is a tedious and time consuming process that is often described as a "dark art". This explains the necessity of automating the calibration of these hyperparameters. Derivative-free optimization is a field that develops methods designed to optimize time consuming functions without relying on derivatives. This work introduces the HyperNOMAD package, an extension of the NOMAD software that applies the MADS algorithm [7] to simultaneously tune the hyperparameters responsible for both the architecture and the learning process of a deep neural network (DNN), and that allows for an important flexibility in the exploration of the search space by taking advantage of categorical variables. This new approach is tested on the MNIST and CIFAR-10 data sets and achieves results comparable to the current state of the art.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HyperNOMAD, an extension of the NOMAD implementation of the Mesh Adaptive Direct Search (MADS) algorithm, to perform hyperparameter optimization for deep neural networks. The extension handles mixed continuous-categorical variables to tune both network architecture and learning-process hyperparameters simultaneously. Experiments on MNIST and CIFAR-10 report accuracies comparable to the state of the art.
Significance. If the reported results hold under the supplied experimental protocol, the work demonstrates that an extended MADS algorithm can locate competitive hyperparameter configurations in high-dimensional mixed search spaces without premature convergence. The open-source HyperNOMAD package is a concrete strength that supports reproducibility.
minor comments (3)
- [Abstract] Abstract: the claim of 'comparable to the current state of the art' would be strengthened by a single sentence summarizing the achieved test accuracies and the main baselines used.
- [Section 4] Section 4 (experimental results): the tables would benefit from explicit reporting of the number of independent runs and any observed variance, even if the central claim does not depend on statistical significance testing.
- [Section 3] Notation for the categorical-variable handling (around the definition of the poll and search steps) could be made more uniform with the original MADS references.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report lists no specific major comments, so we have no points to address point-by-point at this stage.
Circularity Check
No significant circularity; empirical application of prior algorithm
full rationale
The manuscript describes HyperNOMAD as an extension of the established NOMAD/MADS framework (cited as [7]) to handle categorical variables in DNN hyperparameter search, then reports direct experimental accuracies on MNIST and CIFAR-10. No equations, fitted parameters, or predictions are defined in terms of the target results themselves. The MADS reference is to a previously published, externally verifiable algorithm rather than a self-citation chain that bears the central claim. The reported performance numbers are independent empirical measurements, not reductions by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
M.A. Abramson, C. Audet, J.W. Chrissis, and J.G. Walston. Mesh Adaptive Di- rect Search Algorithms for Mixed Variable Optimization. Optimization Letters, 3(1):35–47, 2009
work page 2009
-
[3]
M.A. Abramson, C. Audet, and J.E. Dennis, Jr. Filter pattern search algorithms for mixed variable constrained optimization problems. Pacific Journal of Optimiza- tion, 3(3):477–500, 2007
work page 2007
- [4]
-
[5]
C. Audet, C.-K. Dang, and D. Orban. Optimization of algorithms with OPAL. Mathematical Programming Computation, 6(3):233–254, 2014
work page 2014
-
[6]
C. Audet and J.E. Dennis, Jr. Pattern search algorithms for mixed variable pro- gramming. SIAM Journal on Optimization, 11(3):573–594, 2001
work page 2001
-
[7]
C. Audet and J.E. Dennis, Jr. Mesh Adaptive Direct Search Algorithms for Con- strained Optimization. SIAM Journal on Optimization, 17(1):188–217, 2006. 19
work page 2006
-
[8]
C. Audet and W. Hare. Derivative-Free and Blackbox Optimization . Springer Series in Operations Research and Financial Engineering. Springer International Publishing, Cham, Switzerland, 2017
work page 2017
- [9]
-
[10]
C. Audet and D. Orban. Finding optimal algorithmic parameters using derivative- free optimization. SIAM Journal on Optimization, 17(3):642–664, 2006
work page 2006
-
[11]
C. Audet and C. Tribes. Mesh-based Nelder-Mead algorithm for inequality con- strained optimization. Computational Optimization and Applications , 71(2):331– 352, 2018
work page 2018
- [12]
-
[13]
P. Balaprakash, M. Salim, T. Uram, V . Vishwanath, and S. Wild. DeepHyper: Asynchronous Hyperparameter Search for Deep Neural Networks. In 2018 IEEE 25th International Conference on High Performance Computing (HiPC), pages 42– 51, 2018
work page 2018
-
[14]
Y . Bengio. Practical recommendations for gradient-based training of deep archi- tectures. In Neural networks: Tricks of the trade, pages 437–478. Springer, 2012
work page 2012
-
[15]
J. Bergstra, R. Bardenet, Y . Bengio, and B. K´egl. Algorithms for hyper-parameter optimization. In Advances in neural information processing systems, 2011
work page 2011
-
[16]
J. Bergstra and Y . Bengio. Random search for hyper-parameter optimization.Jour- nal of Machine Learning Research, 13:281–305, 2012
work page 2012
-
[17]
J. Bergstra, D. Yamins, and D.D. Cox. Making a Science of Model Search: Hyper- parameter Optimization in Hundreds of Dimensions for Vision Architectures. In Proceedings of the 30th International Conference on International Conference on Machine Learning, volume 28 of ICML’13, pages I–115–I–123. JMLR.org, 2013
work page 2013
-
[18]
T. Bosc. Learning to Learn Neural Networks. Technical report, arXiv, 2016
work page 2016
-
[19]
L. Bottou. Stochastic Gradient Descent Tricks, volume 7700 of Lecture Notes in Computer Science (LNCS), pages 430–445. Springer, 2012
work page 2012
-
[20]
X. Bouthillier and C. Tsirigotis. Or´ıon: Asynchronous Distributed Hyperparameter Optimization. https://github.com/Epistimio/orion, 2019
work page 2019
-
[21]
A.R. Conn, K. Scheinberg, and L.N. Vicente. Introduction to Derivative-Free Op- timization. MOS-SIAM Series on Optimization. SIAM, Philadelphia, 2009. 20
work page 2009
- [22]
-
[23]
G. Diaz, A. Fokoue, G. Nannicini, and H. Samulowitz. An effective algorithm for hyperparameter optimization of neural networks. IBM Journal of Research and Development, 61(4):9:1–9:11, 2017
work page 2017
- [24]
- [25]
- [26]
-
[27]
H. Ghanbari and K. Scheinberg. Black-Box Optimization in Machine Learning with Trust Region Based Derivative Free Algorithm. Technical report, arXiv, 2017
work page 2017
-
[28]
D. Golovin, B. Solnik, S. Moitra, G. Kochanski, J. Karro, and D. Sculley. Google Vizier: A Service for Black-Box Optimization. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages 1487–1495. ACM, 2017
work page 2017
-
[29]
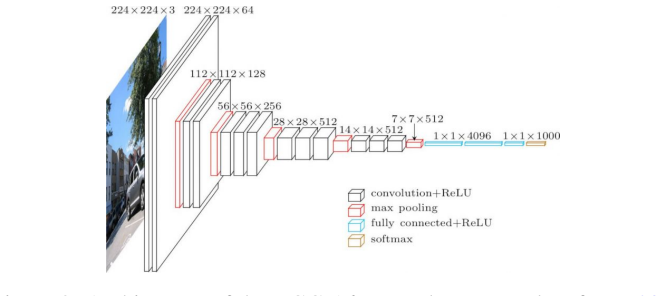
M. Hassan. VGG16 : Convolutional Network for Classification and Detection. https://neurohive.io/en/popular-networks/vgg16/, 2019
work page 2019
-
[30]
R. Hooke and T.A. Jeeves. “Direct Search” Solution of Numerical and Statistical Problems. Journal of the Association for Computing Machinery , 8(2):212–229, 1961
work page 1961
- [31]
-
[32]
Y . Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM international conference on Multimedia, pages 675–
-
[33]
D.P. Kingma and L.B. Jimmy. Adam: A Method for Stochastic Optimization. Technical report, arXiv, 2015. 21
work page 2015
-
[34]
M. Kokkolaras, C. Audet, and J.E. Dennis, Jr. Mixed variable optimization of the number and composition of heat intercepts in a thermal insulation system. Opti- mization and Engineering, 2(1):5–29, 2001
work page 2001
-
[35]
A. Krizhevsky and G. Hinton. Learning multiple layers of features from tiny im- ages. Technical report, Citeseer, 2009
work page 2009
-
[36]
S. Le Digabel. Algorithm 909: NOMAD: Nonlinear Optimization with the MADS algorithm. ACM Transactions on Mathematical Software, 37(4):44:1–44:15, 2011
work page 2011
-
[37]
Y . LeCun and C. Cortes. MNIST handwritten digit database. http://yann.lecun.com/exdb/mnist/, 2010
work page 2010
- [38]
- [39]
-
[40]
L. Li, K. Jamieson, G. DeSalvo, A. Rostamizadeh, and A. Talwalkar. Hyperband: A novel bandit-based approach to hyperparameter optimization. Journal of Ma- chine Learning Research, 18:1–52, 2018
work page 2018
-
[41]
G. Litjens, T. Kooi, B. E. Bejnordi, A. A. A. Setio, F. Ciompi, M. Ghafoorian, J. A. Van Der Laak, G. Van Bram, and C. L. S ´anchez. A survey on deep learning in medical image analysis. Medical image analysis, 42:60–88, 2017
work page 2017
-
[42]
J. Liu, N. Ploskas, and N.V . Sahinidis. Tuning BARON using derivative-free opti- mization algorithms. Journal of Global Optimization, 2018
work page 2018
-
[43]
P.R. Lorenzo, J. Nalepa, M. Kawulok, L.S. Ramos, and J.R. Pastor. Particle swarm optimization for hyper-parameter selection in deep neural networks. In Proceed- ings of the Genetic and Evolutionary Computation Conference. ACM, 2017
work page 2017
-
[44]
I. Loshchilov and F. Hutter. CMA-ES for hyperparameter optimization of deep neural networks. Technical report, arXiv, 2016
work page 2016
- [45]
- [46]
- [47]
-
[48]
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011
work page 2011
-
[49]
M. Porcelli and Ph.L. Toint. BFO, A Trainable Derivative-free Brute Force Op- timizer for Nonlinear Bound-constrained Optimization and Equilibrium Computa- tions with Continuous and Discrete Variables.ACM Transactions on Mathematical Software, 44(1):6:1–6:25, 2017
work page 2017
-
[50]
M.J.D. Powell. The BOBYQA algorithm for bound constrained optimization without derivatives. Technical Report DAMTP 2009/NA06, Department of Ap- plied Mathematics and Theoretical Physics, University of Cambridge, Silver Street, Cambridge CB3 9EW, England, 2009
work page 2009
-
[51]
E. Real, A. Aggarwal, Y . Huang, and Q. V . Le. Regularized evolution for image classifier architecture search. Technical report, arXiv, 2018
work page 2018
-
[52]
K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. Technical report, arXiv, 2014
work page 2014
-
[53]
S.C. Smithson, G. Yang, W.J. Gross, and B.H. Meyer. Neural networks de- signing neural networks: multi-objective hyper-parameter optimization. In 2016 IEEE/ACM International Conference on Computer-Aided Design (ICCAD). IEEE, 2016
work page 2016
- [54]
-
[55]
M. Suganuma, S. Shirakawa, and T. Nagao. A genetic programming approach to designing convolutional neural network architectures. In Proceedings of the Genetic and Evolutionary Computation Conference, pages 497–504. ACM, 2017
work page 2017
-
[56]
T. Tieleman and G. Hinton. Lecture 6.5-rmsprop: Divide the gradient by a run- ning average of its recent magnitude. COURSERA: Neural networks for machine learning, 2012
work page 2012
-
[57]
V . Torczon. On the convergence of pattern search algorithms. SIAM Journal on Optimization, 7(1):1–25, 1997. 23
work page 1997
-
[58]
M. Wistuba, N. Schilling, and L. Schmidt-Thieme. Scalable Gaussian process- based transfer surrogates for hyperparameter optimization. Machine Learning , 107(1):43–78, 2018
work page 2018
-
[59]
Yelp. Metric Optimization Engine. https://github.com/Yelp/MOE, 2014
work page 2014
-
[60]
S.R. Young, D.C. Rose, T.P. Karnowski, S.H. Lim, and R.M. Patton. Optimizing deep learning hyper-parameters through an evolutionary algorithm. InProceedings of the Workshop on Machine Learning in High-Performance Computing Environ- ments. ACM, 2015
work page 2015
-
[61]
A. Zela, A. Klein, and S. Falknerand F. Hutter. Towards automated deep learning: Efficient joint neural architecture and hyperparameter search. Technical report, arXiv, 2018
work page 2018
-
[62]
B. Zoph and Q. V . Le. Neural architecture search with reinforcement learning. Technical report, arXiv, 2016
work page 2016
-
[63]
LB” represents the lower bound and “UB
B. Zoph, V . Vasudevan, J. Shlens, and Q.V . Le. Learning transferable architectures for scalable image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8697–8710, 2018. Appendices A Using HyperNOMAD HyperNOMAD is a C++ and Python package dedicated to the hyperparameter opti- mization of deep neural netwo...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.