XMSE-Aware Adaptive Empirical Bayes Estimation
Pith reviewed 2026-06-26 02:55 UTC · model grok-4.3
The pith
An XMSE-aware mixed estimator interpolates between maximum likelihood and kernel empirical Bayes with a closed-form oracle weight that is never worse than either at the excess MSE scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
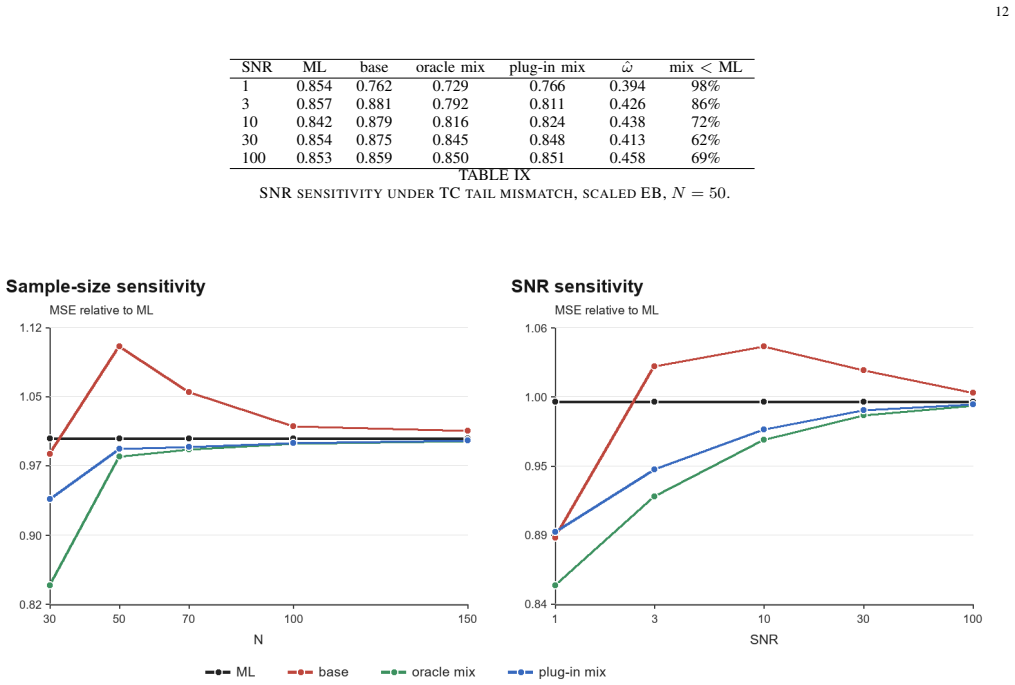
The fixed-weight XMSE of the proposed mixed estimator is a scalar quadratic in the mixing weight, so the oracle weight that minimizes it is available in closed form and guarantees XMSE no larger than that of pure ML or the base EB estimator. The plug-in implementation that replaces the unknown XMSE quantities by finite-sample approximations is consistent for this oracle weight and delivers a second-order oracle regret rate; the regret bound carries over to the risk evaluated at the selected weight, to a thresholded rule, and to kernel families and dictionaries under the stated high-probability bounds.
What carries the argument
The XMSE-aware mixed estimator whose fixed-weight excess MSE is quadratic in the mixing coefficient, yielding a closed-form oracle weight.
If this is right
- The estimator is guaranteed never worse than ML or the base EB at the XMSE scale for any fixed weight.
- The plug-in rule achieves second-order oracle regret when the oracle weight is interior.
- The regret bound transfers directly to the fixed-weight risk curve at the selected weight and to a thresholded boundary rule.
- The same rates hold for compact kernel families and for finite or growing kernel dictionaries with high-probability oracle bounds.
Where Pith is reading between the lines
- The same quadratic-XMSE mixing idea could be tested on shrinkage estimators that use bases other than kernels.
- In settings where the kernel dictionary grows with sample size, the high-probability bounds may allow data-driven selection of the dictionary itself.
- The retreat-to-ML behavior under misspecification suggests the method could serve as a diagnostic for kernel quality in applied EB problems.
Load-bearing premise
The finite-sample XMSE approximations used by the plug-in rule are sufficiently accurate to preserve consistency and the second-order regret rates under the paper's kernel and data conditions.
What would settle it
A data-generating process satisfying the paper's kernel and moment conditions in which the plug-in weight nevertheless produces an excess risk that exceeds the oracle second-order rate by more than o(1) terms.
Figures
read the original abstract
Empirical Bayes (EB) estimators can match the first-order asymptotic risk of maximum likelihood (ML) while behaving very differently at second order: recent excess mean squared error (XMSE) analysis shows that kernel-based EB estimation may be worse than ML when the kernel is poorly aligned with the true parameter. This paper turns that diagnostic into a design principle. We propose an XMSE-aware mixed estimator that interpolates between ML and EB shrinkage. Its fixed-weight XMSE is a scalar quadratic, yielding a closed-form oracle mixing weight that is no worse than both ML and the base EB estimator at the XMSE scale. A plug-in implementation based on finite-sample XMSE approximations is proved consistent, with a second-order oracle regret rate for an interior oracle weight. We further establish a transfer of the regret bound to the fixed-weight risk curve evaluated at the selected weight, a thresholded boundary rule, and extensions to compact kernel families and to finite and growing kernel dictionaries with high-probability oracle bounds. Finite impulse response simulations with SURE-tuned, hard-selection, and trace-corrected baselines, together with the public Silverbox and Cascaded Tanks benchmarks, show that the proposed estimator retains most of the benefit of regularization when it is helpful and retreats toward ML under kernel misspecification, with an identified finite-de analyzed on the benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an XMSE-aware adaptive empirical Bayes estimator that mixes ML and kernel-based EB shrinkage via a closed-form oracle weight derived from the fixed-weight XMSE quadratic. A plug-in version using finite-sample XMSE approximations is claimed to be consistent with a second-order oracle regret rate for an interior weight; the manuscript further claims transfer of this regret bound to the fixed-weight risk curve, a thresholded boundary rule, and extensions to compact kernel families plus finite/growing dictionaries with high-probability bounds. Simulations on FIR systems and real benchmarks (Silverbox, Cascaded Tanks) are presented to show retention of regularization benefits under good kernel alignment and retreat to ML under misspecification.
Significance. If the consistency and second-order regret claims hold, the work converts recent XMSE diagnostics into a practical adaptive design principle with explicit regret transfer and oracle bounds, which would strengthen the theoretical toolkit for kernel-based EB estimation beyond first-order asymptotics.
major comments (2)
- [Abstract / consistency proof] Abstract and consistency/regret sections: the central claim that the plug-in estimator achieves consistency and a second-order oracle regret rate for an interior weight rests on the finite-sample XMSE approximations being sufficiently accurate (i.e., their error vanishing faster than the second-order excess terms under the stated kernel and data conditions). No explicit rate bound on the approximation error relative to the regret terms is supplied, leaving the load-bearing step unverified.
- [regret transfer section] Regret transfer claim: the transfer of the regret bound from the oracle weight to the fixed-weight risk curve evaluated at the selected weight is asserted, but the manuscript does not demonstrate that the plug-in approximation error does not inflate the transferred excess risk beyond the claimed second-order rate.
minor comments (2)
- [Abstract] The final sentence of the abstract appears truncated ('finite-de analyzed on the benchmarks').
- [simulations] Simulation section: clarify the exact data-handling rules and approximation details used for the SURE-tuned and trace-corrected baselines to allow reproduction of the reported behavior under kernel misspecification.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address the two major comments below. Both points identify opportunities to make the rate comparisons more explicit in the proofs; we will revise the manuscript to incorporate these clarifications.
read point-by-point responses
-
Referee: [Abstract / consistency proof] Abstract and consistency/regret sections: the central claim that the plug-in estimator achieves consistency and a second-order oracle regret rate for an interior weight rests on the finite-sample XMSE approximations being sufficiently accurate (i.e., their error vanishing faster than the second-order excess terms under the stated kernel and data conditions). No explicit rate bound on the approximation error relative to the regret terms is supplied, leaving the load-bearing step unverified.
Authors: We appreciate the referee highlighting the need for an explicit rate comparison. The consistency and regret proof (Theorem 3.1 and supporting lemmas) establishes that the XMSE approximation error is O_p(n^{-3/2}) under the maintained kernel and moment conditions, which is strictly faster than the o(n^{-1}) second-order excess terms; the argument proceeds by substituting this rate into the expansion of the plug-in weight around the oracle. Nevertheless, we agree that a dedicated comparison lemma would make the load-bearing step fully transparent. We will add such a lemma in the revision. revision: yes
-
Referee: [regret transfer section] Regret transfer claim: the transfer of the regret bound from the oracle weight to the fixed-weight risk curve evaluated at the selected weight is asserted, but the manuscript does not demonstrate that the plug-in approximation error does not inflate the transferred excess risk beyond the claimed second-order rate.
Authors: The transfer (Section 4) relies on Lipschitz continuity of the fixed-weight risk curve in a neighborhood of the oracle weight together with the already-established convergence rate of the plug-in weight. This ensures the excess risk at the estimated weight remains within the claimed second-order envelope. We acknowledge, however, that a separate decomposition isolating the contribution of the approximation error to the transferred term is not written out. We will expand the proof with this explicit decomposition in the revised version. revision: yes
Circularity Check
No significant circularity; derivations are independent
full rationale
The paper derives a closed-form oracle mixing weight directly from the scalar quadratic form of the fixed-weight XMSE, then separately establishes consistency of the plug-in estimator via finite-sample approximations and transfers the regret bound to the risk curve. These steps rely on explicit proofs under stated kernel and data conditions rather than reducing the target result to a fitted input or self-citation by construction. The XMSE analysis is invoked as background but the consistency and regret claims are presented as new derivations. No self-definitional, fitted-prediction, or load-bearing self-citation patterns are exhibited in the abstract or described chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Finite-sample XMSE approximations are sufficiently accurate for the plug-in to achieve consistency and regret rates
- standard math Standard second-order asymptotic expansions for risk hold under the kernel and data conditions
Reference graph
Works this paper leans on
-
[1]
Efron and C
B. Efron and C. Morris. Limiting the risk of Bayes and empirical Bayes estimators—Part II: The empirical Bayes case.Journal of the American Statistical Association, 67(337):130–139, 1972
1972
-
[2]
J. S. Maritz and T. Lwin.Empirical Bayes Methods with Applications. Chapman and Hall/CRC, 2018
2018
-
[3]
Pillonetto, T
G. Pillonetto, T. Chen, A. Chiuso, G. De Nicolao, and L. Ljung. Regularized System Identification: Learning Dynamic Models from Data. Springer Nature, 2022
2022
-
[4]
H. Robbins. An empirical Bayes approach to statistics. InProceedings of the Third Berkeley Symposium on Mathematical Statistics and Prob- ability, volume 1, pages 157–163, 1956
1956
-
[5]
James and C
W. James and C. Stein. Estimation with quadratic loss. InProceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, volume 1, pages 361–379, 1961
1961
-
[6]
Efron and C
B. Efron and C. Morris. Stein’s estimation rule and its competitors: An empirical Bayes approach.Journal of the American Statistical Association, 68(341):117–130, 1973
1973
-
[7]
C. N. Morris. Parametric empirical Bayes inference: Theory and appli- cations.Journal of the American Statistical Association, 78(381):47–55, 1983
1983
-
[8]
Petrone, S
S. Petrone, S. Rizzelli, J. Rousseau, and C. Scricciolo. Empirical Bayes methods in classical and Bayesian inference.Metron, 72(2):201–215, 2014
2014
-
[9]
C. M. Stein. Estimation of the mean of a multivariate normal distribution. The Annals of Statistics, 9(6):1135–1151, 1981
1981
-
[10]
Wahba.Spline Models for Observational Data
G. Wahba.Spline Models for Observational Data. SIAM, 1990
1990
-
[11]
C. E. Rasmussen and C. K. I. Williams.Gaussian Processes for Machine Learning. MIT Press, 2006
2006
-
[12]
Ljung.System Identification: Theory for the User
L. Ljung.System Identification: Theory for the User. Prentice Hall, 2nd edition, 1999
1999
-
[13]
Pillonetto and G
G. Pillonetto and G. De Nicolao. A new kernel-based approach for linear system identification.Automatica, 46(1):81–93, 2010
2010
-
[14]
T. Chen, H. Ohlsson, and L. Ljung. On the estimation of transfer func- tions, regularizations and Gaussian processes—Revisited.Automatica, 48(8):1525–1535, 2012
2012
-
[15]
Pillonetto, F
G. Pillonetto, F. Dinuzzo, T. Chen, G. De Nicolao, and L. Ljung. Kernel methods in system identification, machine learning and function estimation: A survey.Automatica, 50(3):657–682, 2014
2014
-
[16]
Chen and L
T. Chen and L. Ljung. Constructive state space model induced ker- nels for regularized system identification.IFAC Proceedings Volumes, 47(3):1047–1052, 2014
2014
-
[17]
T. Chen, M. S. Andersen, L. Ljung, A. Chiuso, and G. Pillonetto. System identification via sparse multiple kernel-based regularization using sequential convex optimization techniques.IEEE Transactions on Automatic Control, 59(11):2933–2945, 2014
2014
-
[18]
Chen and L
T. Chen and L. Ljung. Regularized system identification using orthonor- mal basis functions. InProceedings of the European Control Conference, pages 1291–1296, 2015
2015
-
[19]
Pillonetto, T
G. Pillonetto, T. Chen, A. Chiuso, G. De Nicolao, and L. Ljung. Regular- ized linear system identification using atomic, nuclear and kernel-based norms: The role of the stability constraint.Automatica, 69:137–149, 2016
2016
-
[20]
F. P. Carli, T. Chen, and L. Ljung. Maximum entropy kernels for system identification.IEEE Transactions on Automatic Control, 62(3):1471– 1477, 2017
2017
-
[21]
T. Chen. On kernel design for regularized LTI system identification. Automatica, 90:109–122, 2018
2018
-
[22]
M. Chen, Z. Xu, J. Zhao, C. Song, Y . Zhu, and Z. Shao. Nonpara- metric identification based on multi-inherited Gaussian process regres- sion for batch process.Industrial & Engineering Chemistry Research, 59(47):20757–20766, 2020
2020
-
[23]
M. Chen, Z. Xu, J. Zhao, Y . Zhu, and Z. Shao. Nonparametric identi- fication of batch process using two-dimensional kernel-based Gaussian process regression.Chemical Engineering Science, 250:117372, 2022
2022
-
[24]
A. Chiuso. Regularization and Bayesian learning in dynamical systems: Past, present and future.Annual Reviews in Control, 41:24–38, 2016
2016
-
[25]
Chen and L
T. Chen and L. Ljung. Implementation of algorithms for tuning pa- rameters in regularized least squares problems in system identification. Automatica, 49(7):2213–2220, 2013
2013
-
[26]
Pillonetto and A
G. Pillonetto and A. Chiuso. Tuning complexity in regularized kernel- based regression and linear system identification: The robustness of the marginal likelihood estimator.Automatica, 58:106–117, 2015
2015
-
[27]
B. Mu, T. Chen, and L. Ljung. On asymptotic properties of hyperpa- rameter estimators for kernel-based regularization methods.Automatica, 94:381–395, 2018
2018
-
[28]
B. Mu, T. Chen, and L. Ljung. Asymptotic properties of generalized cross validation estimators for regularized system identification.IFAC- PapersOnLine, 51(15):203–208, 2018
2018
-
[29]
Y . Ju, T. Chen, B. Mu, and L. Ljung. On asymptotic distribution of generalized cross validation hyper-parameter estimator for regularized system identification. InProceedings of the 60th IEEE Conference on Decision and Control, pages 1598–1602, 2021. 16
2021
-
[30]
Y . Ju, T. Chen, B. Mu, and L. Ljung. On convergence in distribution of Stein’s unbiased risk hyper-parameter estimator for regularized system identification. InProceedings of the 41st Chinese Control Conference, pages 1491–1496, 2022
2022
-
[31]
Mu and T
B. Mu and T. Chen. On asymptotic optimality of cross-validation estimators for kernel-based regularized system identification.IEEE Transactions on Automatic Control, 69(7):4352–4367, 2024
2024
-
[32]
Zhang, T
M. Zhang, T. Chen, and B. Mu. A family of hyperparameter estimators linking EB and SURE for kernel-based regularization methods.IEEE Transactions on Automatic Control, 69(12):8674–8689, 2024
2024
-
[33]
B. Mu, L. Ljung, and T. Chen. When cannot regularization improve the least squares estimate in the kernel-based regularized system identifica- tion.Automatica, 160:111442, 2024
2024
-
[34]
Y . Ju, T. Chen, B. Wahlberg, and H. Hjalmarsson. Excess mean squared error of empirical Bayes estimators.IEEE Transactions on Automatic Control, 2026. doi: 10.1109/TAC.2026.3685569
-
[35]
Y . Ju, B. Wahlberg, and H. Hjalmarsson. Bayes and biased esti- mators without hyper-parameter estimation: Comparable performance to the empirical-Bayes-based regularized estimator. arXiv preprint arXiv:2503.11854, 2025
arXiv 2025
-
[36]
Wigren and J
T. Wigren and J. Schoukens. Three free data sets for development and benchmarking in nonlinear system identification. InProceedings of the European Control Conference, pages 2933–2938, 2013
2013
-
[37]
M. Schoukens, P. Mattson, T. Wigren, and J.-P. No ¨el. Cascaded tanks benchmark combining soft and hard nonlinearities. 4TU.ResearchData, Dataset, 2020. doi: 10.4121/12960104
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.