SQLConductor: Search-to-Policy Learning for Step-wise Text-to-SQL Orchestration
Pith reviewed 2026-06-26 06:17 UTC · model grok-4.3
The pith
A learned policy selects Text-to-SQL actions step-by-step using stability signals from tree search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
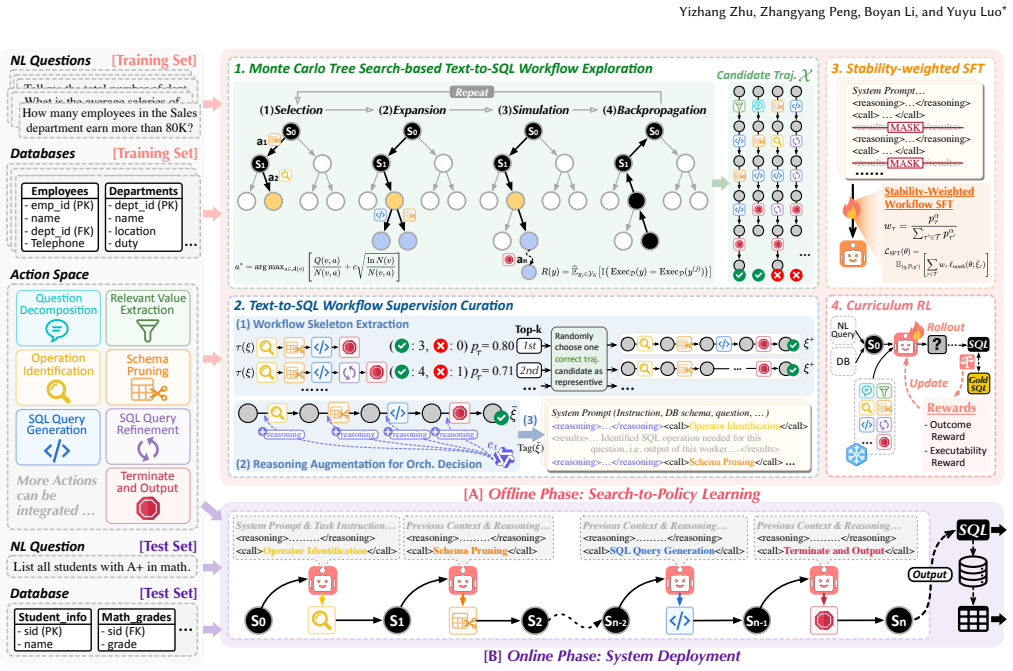
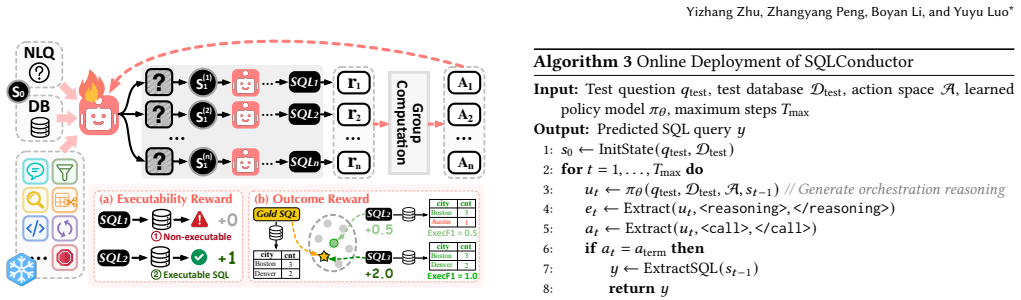
SQLConductor formulates Text-to-SQL subtasks as specialized actions for workflow composition and trains a policy model to select the next action based on intermediate artifacts and feedback. Search-to-Policy Learning uses Monte Carlo Tree Search to explore candidate workflows and stability estimation to identify robust supervision. The policy is trained with Stability-weighted Supervised Fine-tuning to prioritize high-quality orchestration patterns and further enhanced through Curriculum Reinforcement Learning. This transforms offline workflow search into a deployable policy for step-wise orchestration at inference time, reaching 73.2 percent execution accuracy on BIRD-Dev while coordinating
What carries the argument
Search-to-Policy Learning, which uses Monte Carlo Tree Search to explore workflows and stability estimation to produce supervision signals for training the step-wise orchestration policy.
If this is right
- The orchestration policy adapts to intermediate artifacts and feedback rather than committing to a full workflow in advance.
- A compact policy can coordinate frozen larger Text-to-SQL models to achieve higher execution accuracy than methods that train comparable or larger backbones directly.
- The learned policy generalizes to out-of-distribution datasets and handles diverse query demands without predefined stage orders.
- Step-wise orchestration becomes practical at inference time after offline search converts into an online policy.
Where Pith is reading between the lines
- Keeping large action models frozen while training only the policy may reduce the cost of deploying Text-to-SQL systems on new hardware.
- The same search-to-policy pattern could apply to other adaptive multi-stage reasoning tasks such as code generation or multi-hop question answering.
- Further tests on databases with rapidly changing schemas would show whether the stability signals remain reliable when action models are swapped.
Load-bearing premise
Stability estimation derived from Monte Carlo Tree Search produces supervision signals that allow the learned policy to generalize to out-of-distribution datasets and diverse query demands.
What would settle it
Applying the trained policy to a held-out database schema or query distribution and measuring whether execution accuracy falls below that of prior direct-training baselines would test the generalization claim.
Figures





read the original abstract
Text-to-SQL enables users to access relational databases via natural language, but real-world settings remain challenging due to coordinated reasoning over complex database environments. Existing systems often use multi-stage pipelines or reasoning models specialized for individual stages. However, fixed pipelines rely on predefined stage orders, limiting their adaptivity to query demands and intermediate evidence. Recent orchestration-based methods provide flexibility by composing specialized modules for each query, but typical plan-then-execute approaches still commit to a complete workflow before execution and cannot adapt to intermediate artifacts and feedback. In this paper, we propose SQLConductor, a step-wise orchestration learning framework for Text-to-SQL. SQLConductor formulates Text-to-SQL subtasks as specialized actions for workflow composition and trains a policy model to select the next action based on intermediate artifacts and feedback. To learn this policy, SQLConductor introduces Search-to-Policy Learning, which uses Monte Carlo Tree Search to explore candidate workflows and stability estimation to identify robust supervision. The policy model is trained with Stability-weighted Supervised Fine-tuning to prioritize high-quality orchestration patterns and further enhanced through Curriculum Reinforcement Learning. This transforms offline workflow search into a deployable policy for step-wise orchestration at inference time. Experiments on BIRD-Dev and out-of-distribution datasets show that SQLConductor achieves superior execution accuracy and strong generalization, reaching 73.2% EX on BIRD-Dev with a compact orchestration policy coordinating frozen larger action models, outperforming prior methods that directly train comparable or larger Text-to-SQL backbones. Further analyses show that the learned policy adapts orchestration to diverse query demands.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SQLConductor, a step-wise Text-to-SQL orchestration framework. It formulates subtasks as actions and trains a policy model using Search-to-Policy Learning: Monte Carlo Tree Search explores workflows, stability estimation identifies robust supervision signals, followed by Stability-weighted Supervised Fine-Tuning and Curriculum Reinforcement Learning. The resulting compact policy coordinates frozen larger action models. The paper claims this achieves 73.2% execution accuracy on BIRD-Dev, outperforming prior methods that train larger backbones directly, and shows strong generalization on out-of-distribution datasets.
Significance. If the reported performance and generalization results are substantiated with rigorous experimental protocols, this work could be significant for the Text-to-SQL field. It demonstrates a way to achieve high performance with a small orchestration policy rather than large end-to-end models, and provides adaptivity through step-wise decisions based on intermediate feedback, addressing limitations of fixed pipelines and plan-then-execute approaches.
major comments (3)
- Abstract: The abstract asserts a 73.2% execution accuracy figure and outperformance but supplies no experimental protocol, baseline descriptions, statistical tests, error bars, or data-exclusion rules, so it is impossible to determine whether the reported numbers support the claim. This is load-bearing for all performance claims.
- Search-to-Policy Learning section: The training loop uses search-generated trajectories to supervise the policy; it is unclear whether the stability metric introduces circular dependence on the same search process used for evaluation, which is load-bearing for the generalization claims.
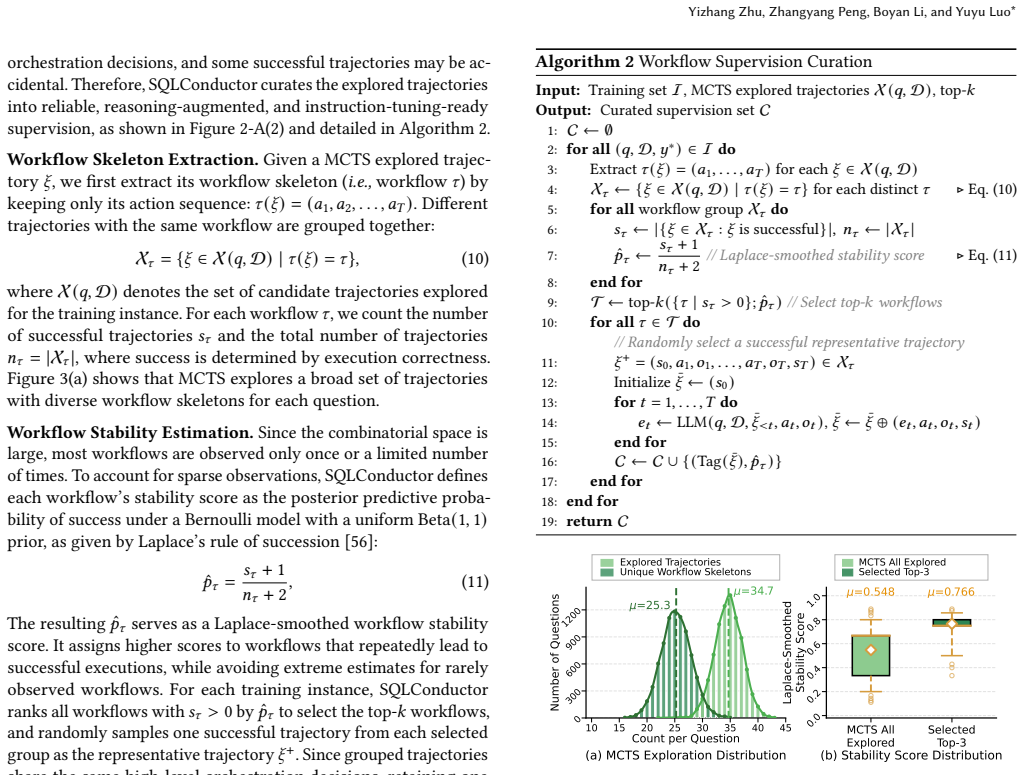
- Experiments on OOD datasets: Stability estimation derived from Monte Carlo Tree Search produces supervision signals claimed to allow the learned policy to generalize to out-of-distribution datasets and diverse query demands. However, no independent verification that the selected supervision signals are invariant across distribution shifts is described, which is central to the OOD generalization result.
minor comments (1)
- Notation in the stability estimation description could be clarified with an explicit equation or pseudocode for the Monte Carlo estimate.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The concerns about experimental clarity, potential circularity in our training procedure, and verification of OOD generalization are important. We address each major comment below with clarifications and proposed revisions.
read point-by-point responses
-
Referee: Abstract: The abstract asserts a 73.2% execution accuracy figure and outperformance but supplies no experimental protocol, baseline descriptions, statistical tests, error bars, or data-exclusion rules, so it is impossible to determine whether the reported numbers support the claim. This is load-bearing for all performance claims.
Authors: We agree that the abstract should better contextualize the performance claims. In the revised version we will expand the abstract to include a concise statement of the evaluation protocol (BIRD-Dev benchmark, standard execution accuracy metric, comparison against prior Text-to-SQL methods), and we will explicitly reference Section 4 for full details on baselines, statistical reporting, error bars, and data handling. This addresses the load-bearing nature of the claim while respecting abstract length constraints. revision: yes
-
Referee: Search-to-Policy Learning section: The training loop uses search-generated trajectories to supervise the policy; it is unclear whether the stability metric introduces circular dependence on the same search process used for evaluation, which is load-bearing for the generalization claims.
Authors: Stability is computed from the variance of execution outcomes across multiple independent MCTS rollouts (different random seeds and simulation depths) performed on the same training query; this intra-query consistency measure is then used only to weight supervision for SFT. Final policy evaluation occurs on a completely disjoint test set (BIRD-Dev and OOD datasets) with no reuse of the search trajectories. We will add an explicit paragraph in the Search-to-Policy Learning section describing this separation and the independence of the stability computation from test-time evaluation. revision: yes
-
Referee: Experiments on OOD datasets: Stability estimation derived from Monte Carlo Tree Search produces supervision signals claimed to allow the learned policy to generalize to out-of-distribution datasets and diverse query demands. However, no independent verification that the selected supervision signals are invariant across distribution shifts is described, which is central to the OOD generalization result.
Authors: The empirical OOD results on separate datasets already demonstrate that policies trained on stability-weighted signals transfer better than alternatives. However, we acknowledge that an explicit analysis isolating invariance of the selected signals (e.g., correlation between stability scores and OOD performance or cross-distribution stability statistics) is not currently provided. In revision we will add a dedicated subsection with such verification metrics and, if needed, additional controlled experiments. revision: partial
Circularity Check
No circularity: MCTS generates offline supervision for independent policy
full rationale
The paper's derivation uses Monte Carlo Tree Search to explore workflows and produce stability-weighted trajectories as training data for a separate policy model via SFT and curriculum RL. This is a standard offline search-to-policy distillation where the search step creates the dataset and the learned policy is deployed without search at inference. No equations, self-citations, or definitions in the abstract or method description reduce any claimed prediction or generalization result back to the inputs by construction. The approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Text-to-SQL subtasks can be formulated as specialized actions whose selection can be learned from intermediate artifacts and feedback
Reference graph
Works this paper leans on
-
[1]
David Berthelot, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, and Colin Raffel. 2019. Mixmatch: A holistic approach to semi-supervised learning.Advances in neural information processing systems32 (2019)
2019
-
[2]
Cameron B Browne, Edward Powley, Daniel Whitehouse, Simon M Lucas, Peter I Cowling, Philipp Rohlfshagen, Stephen Tavener, Diego Perez, Spyridon Samoth- rakis, and Simon Colton. 2012. A survey of monte carlo tree search methods. IEEE Transactions on Computational Intelligence and AI in games4, 1 (2012), 1–43
2012
- [3]
-
[4]
Alejandro Cuadron, Dacheng Li, Wenjie Ma, Xingyao Wang, Yichuan Wang, Siyuan Zhuang, Shu Liu, Luis Gaspar Schroeder, Tian Xia, Huanzhi Mao, et al
- [5]
- [6]
-
[7]
Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, and Wanjun Zhong. 2026. ReTool: Reinforcement Learning for Strategic Tool Use in LLMs. InThe Fourteenth International Confer- ence on Learning Representations. https://openreview.net/forum?id=tRk1nofSmz
2026
-
[8]
Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou. 2024. Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation.Proc. VLDB Endow.17, 5 (2024), 1132–1145
2024
- [9]
-
[10]
Yuxiang Guo, Zhuoran Du, Nan Tang, Kezheng Tang, Congcong Ge, and Yunjun Gao. 2026. DTBench: A Synthetic Benchmark for Document-to-Table Extraction. InProceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining
2026
-
[11]
Mingqian He, Yongliang Shen, Wenqi Zhang, Qiuying Peng, Jun Wang, and Weiming Lu. 2025. Star-sql: Self-taught reasoner for text-to-sql. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 24365–24375
2025
-
[12]
Zijin Hong, Zheng Yuan, Qinggang Zhang, Hao Chen, Junnan Dong, Feiran Huang, and Xiao Huang. 2025. Next-generation database interfaces: A survey of llm-based text-to-sql.IEEE Transactions on Knowledge and Data Engineering (2025)
2025
-
[13]
Ruilin Hu, Yuyu Luo, Guoliang Li, Shuangqiao Wu, and Yun Luo. 2026. OpenSQL: Data-Efficient Text-to-SQL for Open-Source LLMs via Synthesized Intermediate Supervision.Proc. VLDB Endow.(2026)
2026
-
[14]
Levente Kocsis and Csaba Szepesvári. 2006. Bandit based monte-carlo planning. InEuropean conference on machine learning. Springer, 282–293
2006
-
[15]
Chia-Hsuan Lee, Oleksandr Polozov, and Matthew Richardson. 2021. KaggleD- BQA: Realistic Evaluation of Text-to-SQL Parsers. InACL/IJCNLP (1). Association for Computational Linguistics, 2261–2273
2021
-
[16]
Boyan Li, Chong Chen, Zhujun Xue, Yinan Mei, and Yuyu Luo. 2026. DeepEye- SQL: A Software-Engineering-Inspired Text-to-SQL Framework.Proc. ACM Manag. Data4, 3 (2026). https://doi.org/10.1145/3802035
-
[17]
Boyan Li, Ou Ocean Kun Hei, Yue Yu, and Yuyu Luo. 2026. DPC: Training- Free Text-to-SQL Candidate Selection via Dual-Paradigm Consistency. https: //doi.org/10.48550/arXiv.2604.15163 arXiv:2604.15163 [cs.DB] Accepted to ACL 2026 Main Track
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.15163 2026
-
[18]
Boyan Li, Yuyu Luo, Chengliang Chai, Guoliang Li, and Nan Tang. 2024. The Dawn of Natural Language to SQL: Are We Fully Ready? [Experiment, Analysis & Benchmark].Proc. VLDB Endow.17, 11 (2024), 3318–3331
2024
-
[19]
Boyan Li, Yiran Peng, Yupeng Xie, Sirong Lu, Yizhang Zhu, Xing Mu, Xinyu Liu, and Yuyu Luo. 2026. DeepEye: A Steerable Self-driving Data Agent System. InCompanion of the International Conference on Management of Data(India) (SIGMOD Companion ’26). Association for Computing Machinery, New York, NY, USA, 74–77. https://doi.org/10.1145/3788853.3801612
-
[20]
Boyan Li, Jiayi Zhang, Ju Fan, Yanwei Xu, Chong Chen, Nan Tang, and Yuyu Luo. 2025. Alpha-SQL: Zero-Shot Text-to-SQL using Monte Carlo Tree Search. InForty-second International Conference on Machine Learning
2025
-
[21]
Haoyang Li, Shang Wu, Xiaokang Zhang, Xinmei Huang, Jing Zhang, Fuxin Jiang, Shuai Wang, Tieying Zhang, Jianjun Chen, Rui Shi, Hong Chen, and Cuiping Li. 2025. OmniSQL: Synthesizing High-quality Text-to-SQL Data at Scale.Proc. VLDB Endow.18, 11 (2025), 4695–4709
2025
-
[22]
Haoyang Li, Jing Zhang, Hanbing Liu, Ju Fan, Xiaokang Zhang, Jun Zhu, Renjie Wei, Hongyan Pan, Cuiping Li, and Hong Chen. 2024. CodeS: Towards Building Open-source Language Models for Text-to-SQL.Proc. ACM Manag. Data2, 3 (2024), 127
2024
-
[23]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Kevin Chen-Chuan Chang, Fei Huang, Reynold Cheng, and Yongbin Li. 2023. Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs. InNeurIPS
2023
-
[24]
Weibin Liao, Xin Gao, Tianyu Jia, Rihong Qiu, Yifan Zhu, Yang Lin, Xinyu Ma, Junfeng Zhao, and Yasha Wang. 2026. LearNAT: Learning NL2SQL with AST-guided Task Decomposition for Large Language Models. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/ forum?id=q6kXd8Gpfj
2026
-
[25]
Xiaotian Lin, Yanlin Qi, Yizhang Zhu, Themis Palpanas, Chengliang Chai, Nan Tang, and Yuyu Luo. 2025. LEAD: iterative data selection for efficient LLM instruction tuning.Proceedings of the VLDB Endowment19, 3 (2025), 426–439
2025
-
[26]
Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chiang Frank Wang, Kwang-Ting Cheng, Yejin Choi, Jan Kautz, and Pavlo Molchanov. 2026. GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization. InForty- third International Conference on Machine Learning
2026
-
[27]
Xinyu Liu, Shuyu Shen, Boyan Li, Peixian Ma, Runzhi Jiang, Yuxin Zhang, Ju Fan, Guoliang Li, Nan Tang, and Yuyu Luo. 2025. A Survey of Text-to-SQL in the Era of LLMs: Where are we, and where are we going?IEEE Transactions on Knowledge and Data Engineering(2025)
2025
-
[28]
Xinyu Liu, Shuyu Shen, Boyan Li, Nan Tang, and Yuyu Luo. 2025. NL2SQL- BUGs: A Benchmark for Detecting Semantic Errors in NL2SQL Translation. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2(Toronto ON, Canada)(KDD ’25). Association for Computing Machinery, New York, NY, USA, 5662–5673. https://doi.org/10.1145/37...
-
[29]
Yifu Liu, Yin Zhu, Yingqi Gao, Zhiling Luo, Xiaoxia Li, Xiaorong Shi, Yuntao Hong, Jinyang Gao, Yu Li, Bolin Ding, and Jingren Zhou. 2026. XiYan-SQL: A Novel Multi-Generator Framework for Text-to-SQL.IEEE Trans. Knowl. Data Eng.38, 4 (2026), 2474–2487
2026
-
[30]
Tianqi Luo, Chuhan Huang, Leixian Shen, Boyan Li, Shuyu Shen, Wei Zeng, Nan Tang, and Yuyu Luo. 2026. nvBench 2.0: Resolving Ambiguity in Text-to- Visualization through Stepwise Reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track. https: //openreview.net/forum?id=PuzbYHf1GR
2026
-
[31]
Yuyu Luo, Guoliang Li, Ju Fan, Chengliang Chai, and Nan Tang. 2025. Natural language to sql: State of the art and open problems.Proceedings of the VLDB Endowment18, 12 (2025), 5466–5471
2025
- [32]
-
[33]
Yuyu Luo, Xuedi Qin, Nan Tang, and Guoliang Li. 2018. DeepEye: Towards Automatic Data Visualization. In34th IEEE International Conference on Data Engineering, ICDE 2018, Paris, France, April 16-19, 2018. IEEE Computer Society, 101–112. https://doi.org/10.1109/ICDE.2018.00019
- [34]
-
[35]
Da Ma, Ziyue Yang, Hongshen Xu, Haotian Fang, Kai Yu, and Lu Chen. 2026. Empowering LLM Tool Invocation with Tool-call Reward Model. InThe Four- teenth International Conference on Learning Representations. https://openreview. net/forum?id=LnBEASInVr
2026
- [36]
-
[37]
Stefan Nielsen, Edoardo Cetin, Peter Schwendeman, Qi Sun, Jinglue Xu, and Yujin Tang. 2026. Learning to Orchestrate Agents in Natural Language with the Conductor. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=U23A2BUKYt
2026
-
[38]
Ma Peixian, Xialie Zhuang, Chengjin Xu, Xuhui Jiang, Ran Chen, and Jian Guo
-
[39]
InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
SQL-R1: Training natural language to sql reasoning model by reinforcement learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[40]
Mohammadreza Pourreza, Hailong Li, Ruoxi Sun, Yeounoh Chung, Shayan Talaei, Gaurav Tarlok Kakkar, Yu Gan, Amin Saberi, Fatma Ozcan, and Sercan Ö. Arik
-
[41]
CHASE-SQL: Multi-Path Reasoning and Preference Optimized Candidate Selection in Text-to-SQL. InICLR. OpenReview.net
-
[42]
Mohammadreza Pourreza and Davood Rafiei. 2023. DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction. InThirty-seventh Con- ference on Neural Information Processing Systems
2023
-
[43]
Mohammadreza Pourreza, Shayan Talaei, Ruoxi Sun, Xingchen Wan, Hailong Li, Azalia Mirhoseini, Amin Saberi, and Sercan O Arik. 2025. Reasoning-SQL: Rein- forcement Learning with SQL Tailored Partial Rewards for Reasoning-Enhanced Text-to-SQL. InSecond Conference on Language Modeling
2025
-
[44]
Yang Qin, Chao Chen, Zhihang Fu, Ze Chen, Dezhong Peng, Peng Hu, and Jieping Ye. 2025. ROUTE: Robust Multitask Tuning and Collaboration for Text-to-SQL. InThe Thirteenth International Conference on Learning Representations
2025
-
[45]
Jianhao Ruan, Zhihao Xu, Yiran Peng, Fashen Ren, Zhaoyang Yu, Xinbing Liang, Jinyu Xiang, Yongru Chen, Bang Liu, Chenglin Wu, Yuyu Luo, and Jiayi Zhang
-
[46]
AOrchestra: Automating Sub-Agent Creation for Agentic Orchestration. Yizhang Zhu, Zhangyang Peng, Boyan Li, and Yuyu Luo* arXiv:2602.03786 [cs.AI] https://arxiv.org/abs/2602.03786
-
[47]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Lei Sheng and Xu Shuai Shuai. 2025. CSC-SQL: Corrective Self-Consistency in Text-to-SQL via Reinforcement Learning. InIJCNLP-AACL (Findings). The Asian Federation of Natural Language Processing and The Association for Computa- tional Linguistics, 1473–1496
2025
- [49]
-
[50]
Chang-Yu Tai, Ziru Chen, Tianshu Zhang, Xiang Deng, and Huan Sun. 2023. Exploring chain of thought style prompting for text-to-sql. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 5376–5393
2023
-
[51]
Shayan Talaei, Mohammadreza Pourreza, Yu-Chen Chang, Azalia Mirhoseini, and Amin Saberi. 2024. CHESS: Contextual Harnessing for Efficient SQL Synthesis. CoRRabs/2405.16755 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Bing Wang, Changyu Ren, Jian Yang, Xinnian Liang, Jiaqi Bai, LinZheng Chai, Zhao Yan, Qian-Wen Zhang, Di Yin, Xing Sun, and Zhoujun Li. 2025. MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL. InProceedings of the 31st International Conference on Computational Linguistics
2025
- [53]
- [54]
- [55]
-
[56]
Xiangjin Xie, Guangwei Xu, Lingyan Zhao, and Ruijie Guo. 2025. OpenSearch- SQL: Enhancing Text-to-SQL with Dynamic Few-shot and Consistency Align- ment.Proc. ACM Manag. Data3, 3 (2025), 194:1–194:24
2025
- [57]
-
[58]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir R. Radev. 2018. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. InEMNLP. Association for Computational Linguistics, 3911–3921
2018
-
[59]
Shuozhi Yuan, Liming Chen, Miaomiao Yuan, and Zhao Jin. 2026. MCTS-SQL: Light-Weight LLMs Can Master the Text-to-SQL Through Monte Carlo Tree Search. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 34521–34529
2026
-
[60]
Sandy L Zabell. 1989. The rule of succession.Erkenntnis31, 2 (1989), 283–321
1989
-
[61]
Fan Zhang, Vireo Zhang, Shengju Qian, Haoxuan Li, Hao Wu, Jinyang Wu, Donghao Zhou, Zhihong Zhu, Zheng Lian, Xin Wang, and Pheng-Ann Heng
-
[62]
arXiv:2606.13707 [cs.AI] https://arxiv.org/abs/2606.13707
Orchestra-o1: Omnimodal Agent Orchestration. arXiv:2606.13707 [cs.AI] https://arxiv.org/abs/2606.13707
-
[63]
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xiong-Hui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zheng, Bang Liu, Yuyu Luo, and Chenglin Wu. 2025. AFlow: Automating Agentic Workflow Generation. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=z5uVAKwmjf
2025
-
[64]
Yi Zhang, Jan Deriu, George Katsogiannis-Meimarakis, Catherine Kosten, Geor- gia Koutrika, and Kurt Stockinger. 2023. ScienceBenchmark: A Complex Real- World Benchmark for Evaluating Natural Language to SQL Systems.Proc. VLDB Endow.17, 4 (2023), 685–698
2023
-
[65]
Yuxin Zhang, Meihao Fan, Ju Fan, Mingyang Yi, Yuyu Luo, Guoliang Li, Bin Wu, and Wenchao Zhou. 2026. Reward-SQL: Boosting Text-to-SQL via Stepwise Execution-Aware Reasoning and Process-Supervised Rewards.Proceedings of the ACM on Management of Data4, 3 (SIGMOD (2026), 1–27
2026
-
[66]
Yabo Zhang, Yihan Zeng, Qingyun Li, Zhen Hu, Kavin Han, and Wangmeng Zuo
-
[67]
arXiv preprint arXiv:2509.12867(2025)
Tool-R1: Sample-Efficient Reinforcement Learning for Agentic Tool Use. arXiv preprint arXiv:2509.12867(2025)
-
[68]
Yizhang Zhu, Shiyin Du, Boyan Li, Yuyu Luo, and Nan Tang. 2024. Are large language models good statisticians?Advances in Neural Information Processing Systems37 (2024), 62697–62731
2024
-
[69]
Yizhang Zhu, Runzhi Jiang, Boyan Li, Nan Tang, and Yuyu Luo. 2025. EllieSQL: Cost-Efficient Text-to-SQL with Complexity-Aware Routing. InSecond Conference on Language Modeling
2025
- [70]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.