From Spatial to Spectral: An Efficient, Frequency-Guided Feature Representation Learner for Small Object Detection
Pith reviewed 2026-06-26 08:53 UTC · model grok-4.3
The pith
A frequency-guided framework with DER modules lets small object detectors outperform YOLOv11 using one-sixth the parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
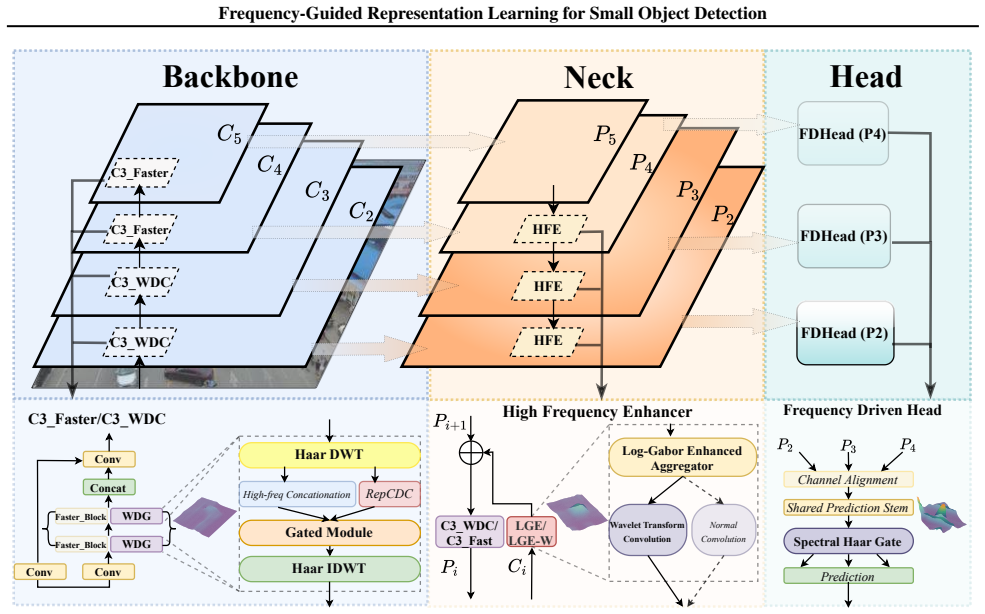
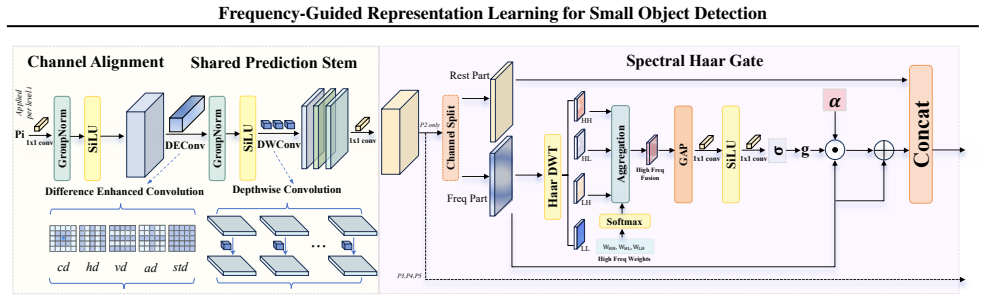
The central claim is that the Decompose-Enhance-Reconstruct (DER) operator, implemented via the Wavelet-Difference Gate, Log-Gabor Enhancer, and Frequency-Driven Head, systematically decouples feature modeling from resolution reduction, captures discriminative high-frequency components, and enables accurate small-object localization across CNN and Transformer architectures with markedly lower parameter counts.
What carries the argument
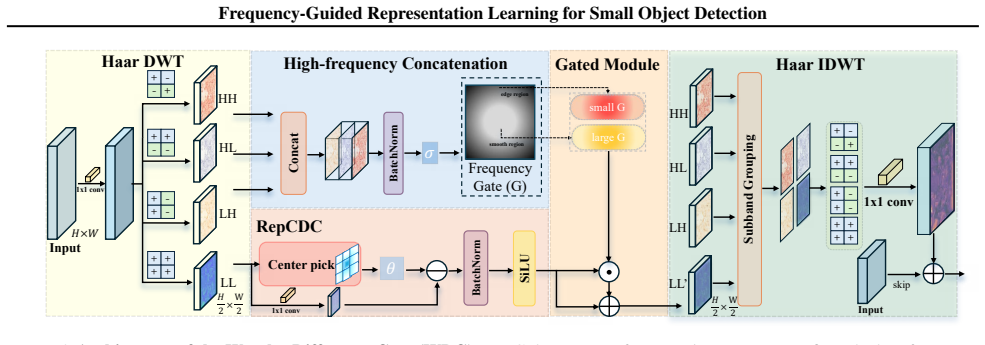
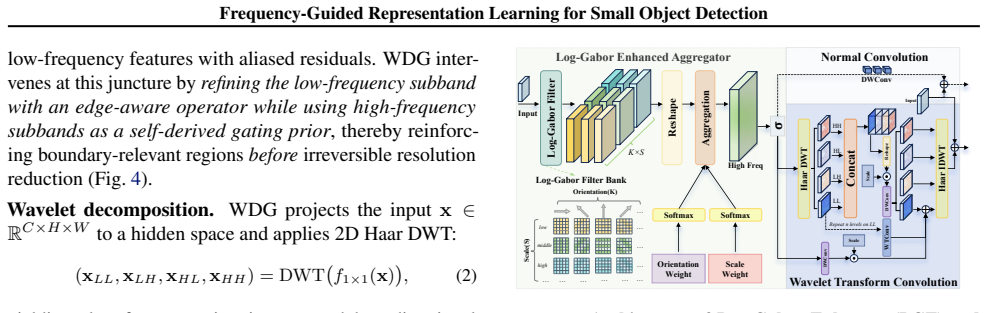
The DER (Decompose-Enhance-Reconstruct) operator realized through three plug-and-play frequency modules (Wavelet-Difference Gate, Log-Gabor Enhancer, Frequency-Driven Head) that perform spectral modulation at backbone, neck, and head stages.
If this is right
- The modules integrate into both CNN and Transformer detectors without architecture-specific retuning.
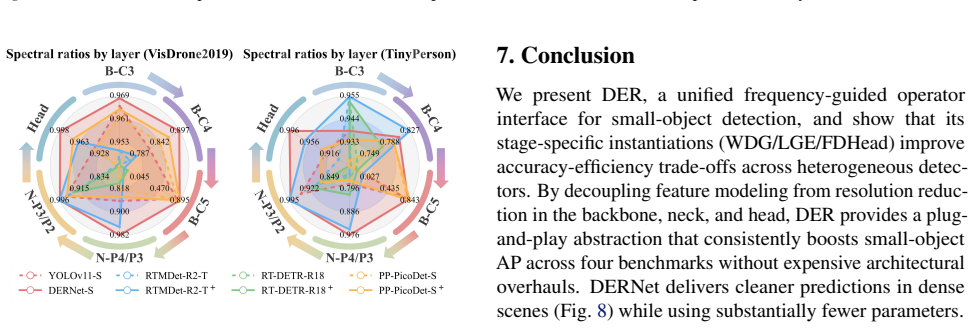
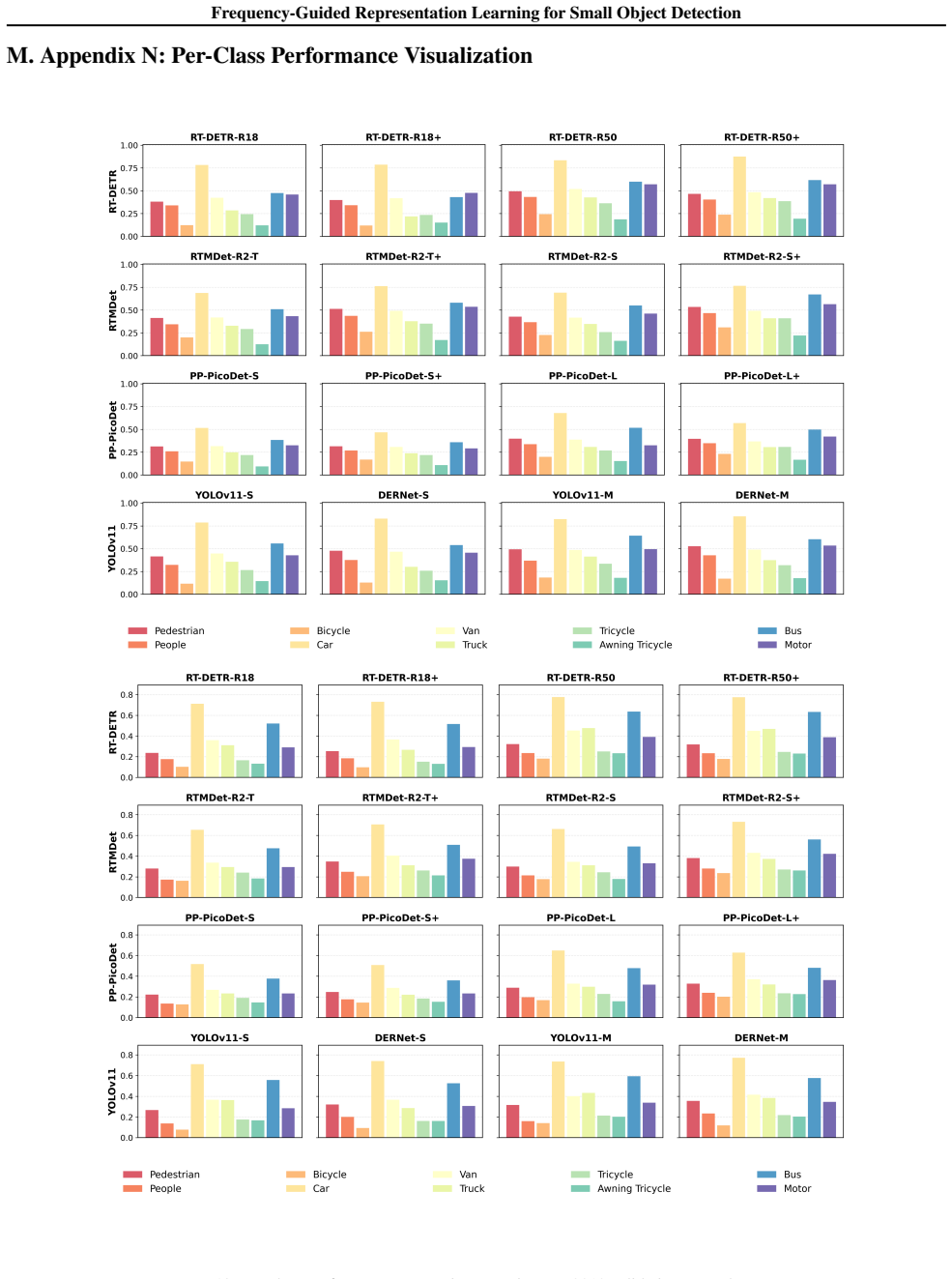
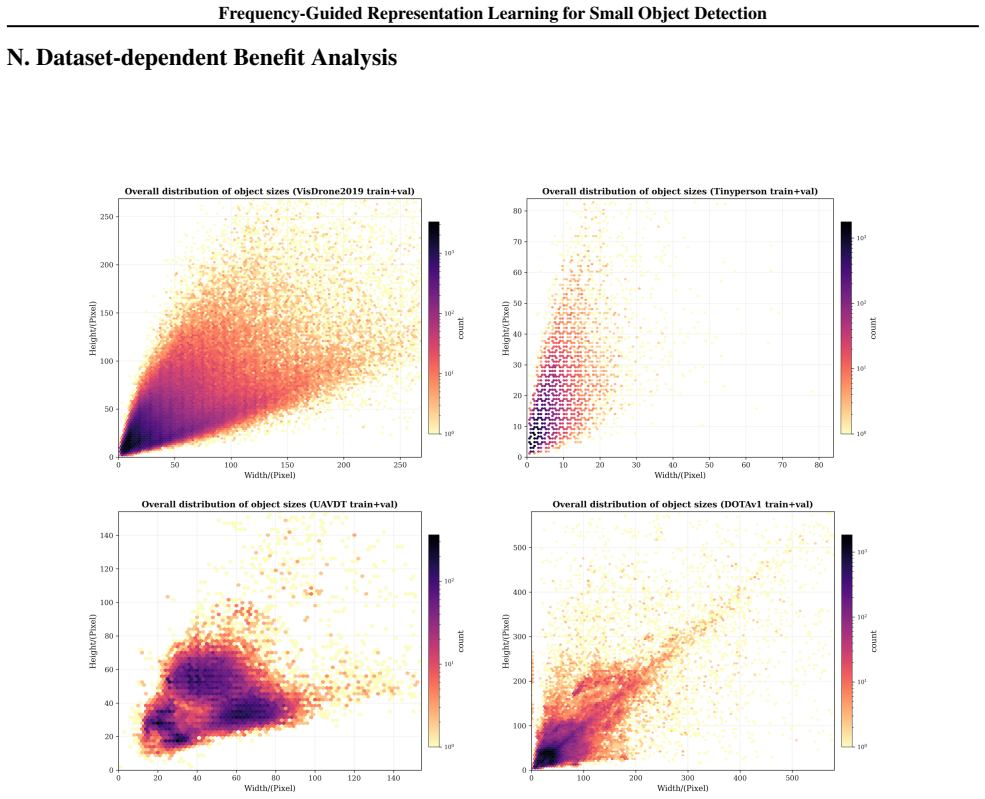
- Detection performance improves consistently across VisDrone2019, UAVDT, TinyPerson, and DOTAv1.
- Parameter count drops to roughly one-sixth that of YOLOv11 at equivalent scale while accuracy holds or rises.
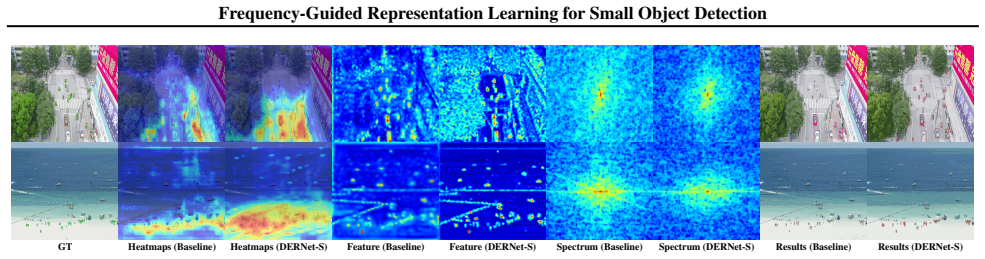
- Spectral diagnostics and error decomposition directly attribute gains to the recovered high-frequency cues.
Where Pith is reading between the lines
- The same frequency-modulation pattern may transfer to other fine-detail tasks such as small-lesion segmentation in medical images.
- Reduced model size opens the possibility of running accurate small-object detection on edge hardware for real-time drone monitoring.
- Testing additional frequency bases beyond wavelets and Gabor filters could reveal further efficiency gains on new domains.
Load-bearing premise
The high-frequency components isolated by the modules are reliably more discriminative for small objects than they are sources of background noise.
What would settle it
An ablation study in which the three frequency modules are removed or replaced by equivalent spatial operations and the detector shows no accuracy gain or a loss on VisDrone2019 or UAVDT would falsify the central claim.
Figures





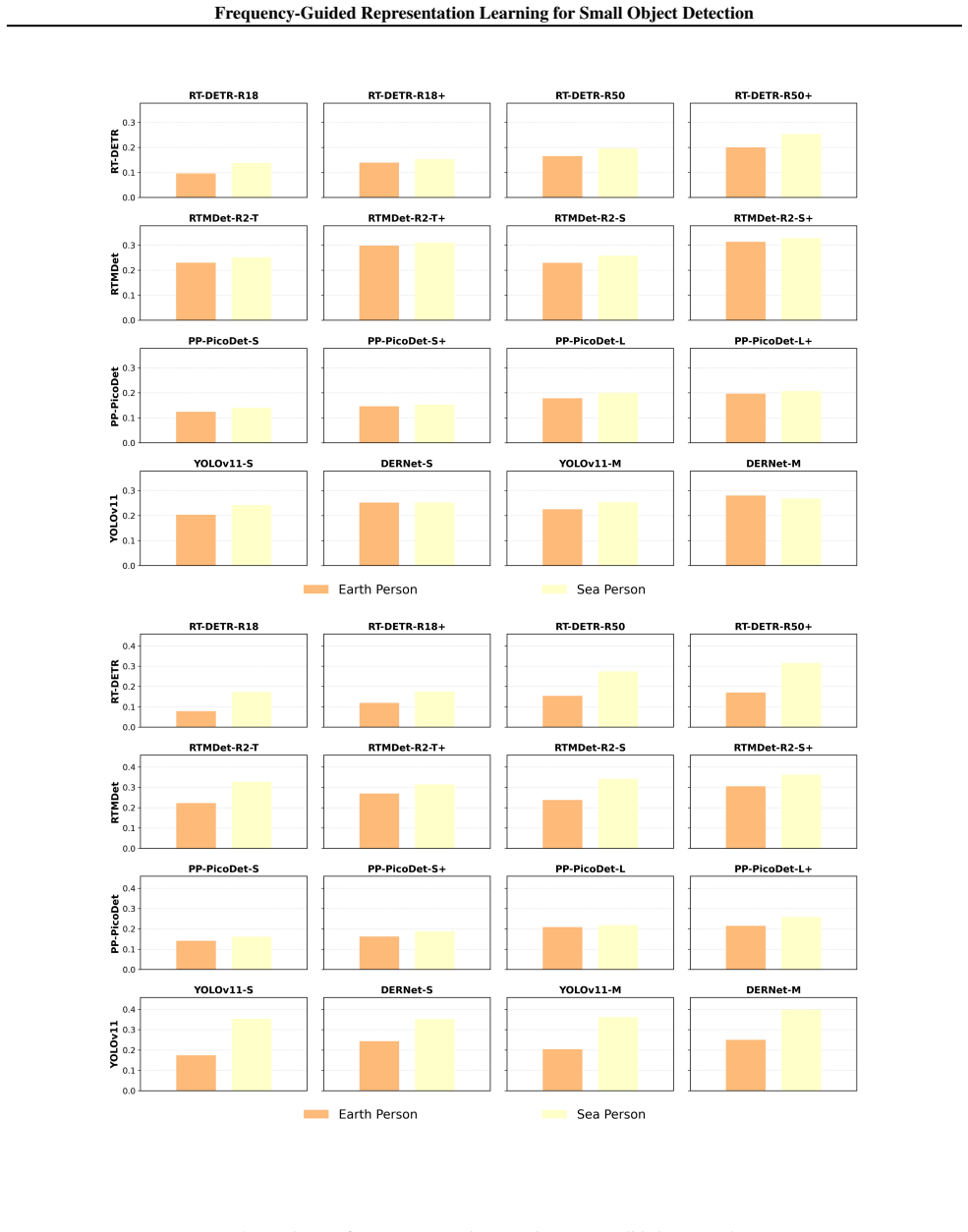
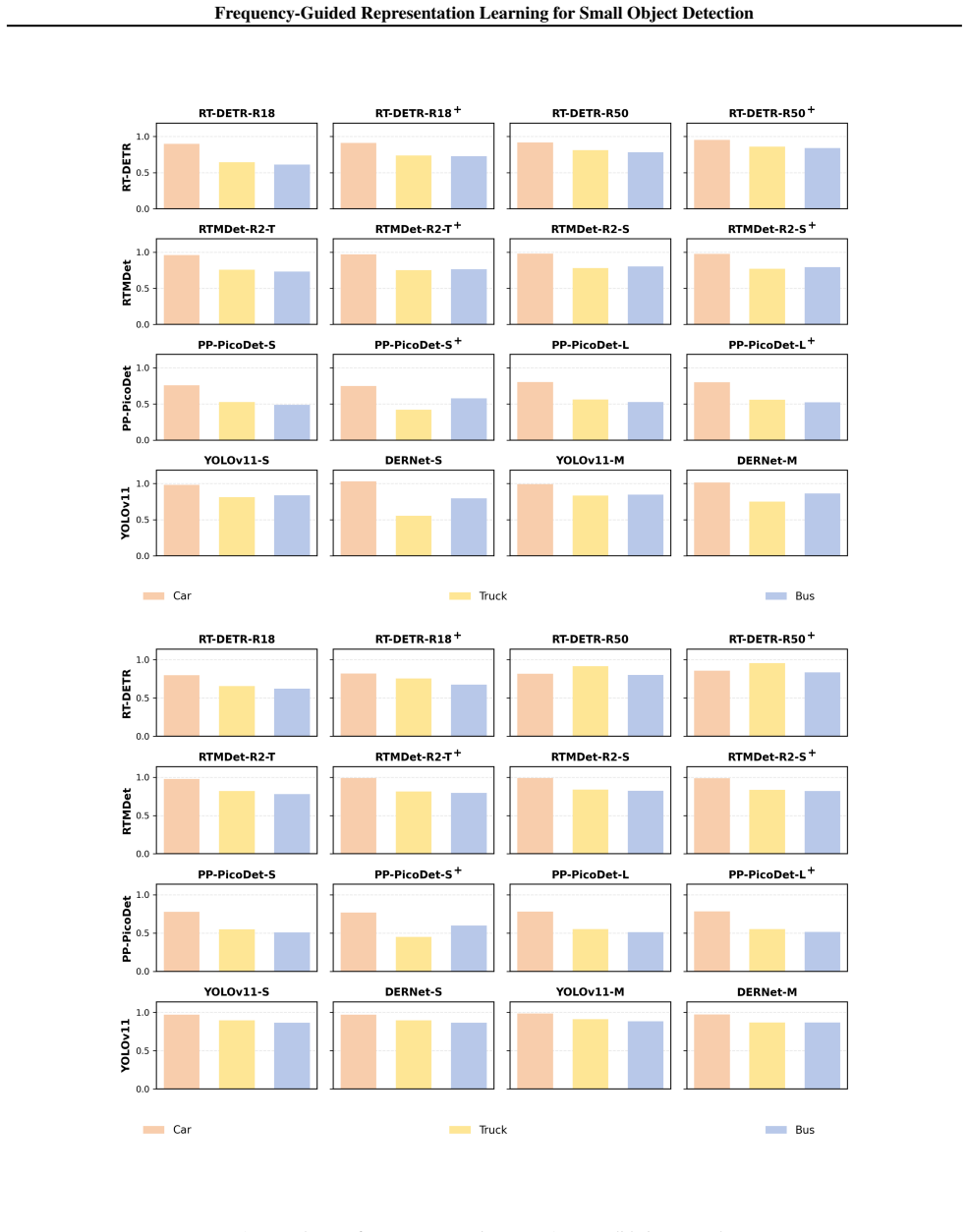
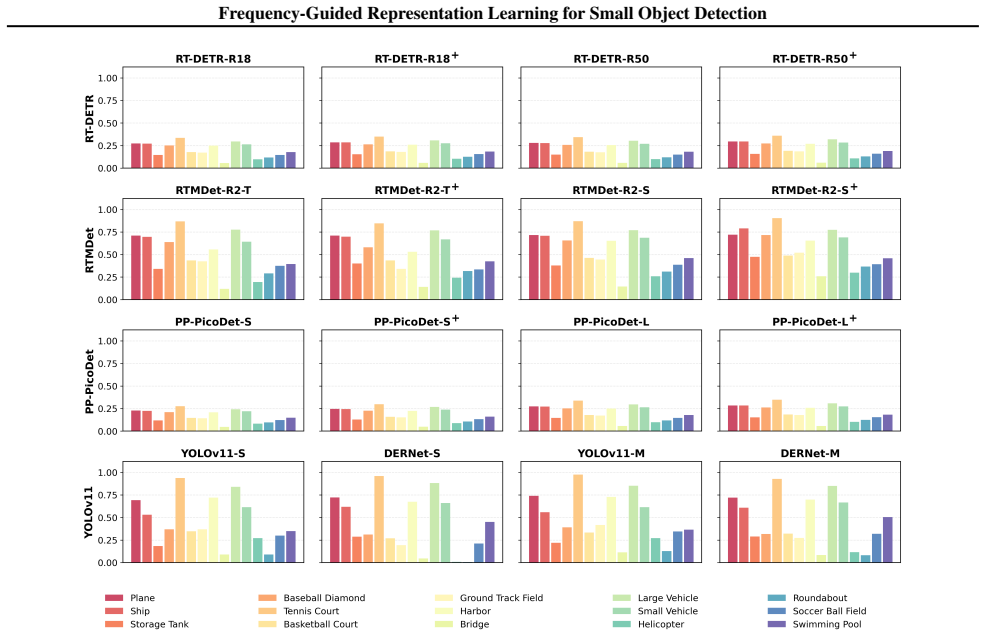
read the original abstract
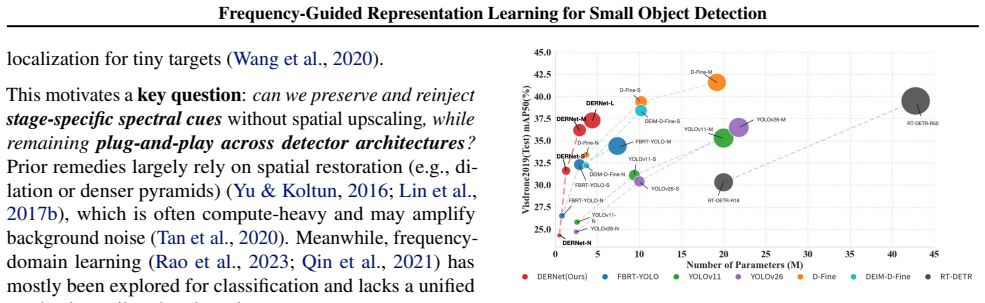
Efficient small object detection is bottlenecked by the inherent feature scarcity of tiny targets, which is further aggravated by operations of spatial-domain detectors that indiscriminately discard critical high-frequency details. Recovering these fragile cues within the spatial domain is notoriously difficult, as it often requires computationally expensive architectural upscaling that inadvertently amplifies background noise. To bridge this gap, we propose a paradigm \textbf{shift from spatial to spectral} feature processing, introducing a holistic solution with the following novelty: (1) A versatile \textbf{Frequency-Guided Feature Representation framework} that generalizes across diverse detector architectures (both CNN and Transformer-based), offering a robust alternative to spatial-only feature extraction; (2) The unified \textbf{Decompose--Enhance--Reconstruct (DER)} operator, instantiated via three \textbf{lightweight, plug-and-play} modules -- Wavelet-Difference Gate (WDG), Log-Gabor Enhancer (LGE), and Frequency-Driven Head (FDHead) -- to systematically inject frequency-aware modulation into the backbone, neck, and head. This mechanism decouples feature modeling from resolution reduction, capturing discriminative high-frequency components to enable accurate localization with significantly reduced parameter redundancy; (3) Extensive validation on multi-domain benchmarks (VisDrone2019, UAVDT, TinyPerson, DOTAv1) demonstrating consistent gains. Notably, our proposed \textbf{DERNet} series outperforms YOLOv11 models under the same scale while requiring \textbf{only 1/6 of the parameters}, backed by rigorous spectral diagnostics and error decomposition analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes shifting small object detection from spatial to spectral feature processing via a Frequency-Guided Feature Representation framework. It introduces the Decompose-Enhance-Reconstruct (DER) operator instantiated as three lightweight plug-and-play modules (Wavelet-Difference Gate, Log-Gabor Enhancer, Frequency-Driven Head) inserted into backbone, neck, and head. These are claimed to generalize across CNN and Transformer detectors, capture high-frequency cues without resolution upscaling, and yield DERNet variants that outperform same-scale YOLOv11 models while using only 1/6 the parameters on VisDrone2019, UAVDT, TinyPerson, and DOTAv1, supported by spectral diagnostics and error decomposition.
Significance. If the empirical claims hold with rigorous controls, the work could offer a parameter-efficient, architecture-agnostic route to recovering discriminative high-frequency information for tiny targets in aerial imagery. The emphasis on lightweight modules and diagnostic analysis would be a positive contribution to efficient detection if the frequency components prove reliably signal rather than noise.
major comments (2)
- [Abstract] Abstract, claim (3): The headline result that DERNet outperforms YOLOv11 at the same scale with 1/6 the parameters is load-bearing for the contribution, yet the abstract supplies no mAP values, parameter tables, dataset splits, or error bars. The full manuscript must include these quantitative comparisons and ablations to substantiate the efficiency claim.
- [Spectral diagnostics section] § on spectral diagnostics and error decomposition: The central premise that WDG, LGE, and FDHead isolate discriminative high-frequency components for small objects (rather than amplifying background clutter) is not secured by the description. The paper should provide concrete evidence, such as frequency-spectrum comparisons before/after each module or controlled experiments on synthetic small-object data, to rule out dataset-specific frequency bias in the UAV benchmarks.
minor comments (2)
- [Method] The description of the DER operator would benefit from explicit equations showing how the three modules compose and their parameter counts relative to the baseline detector.
- [Experiments] Clarify whether the modules require any architecture-specific retuning when inserted into Transformer-based detectors, as asserted to be plug-and-play.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment below with specific responses. The full manuscript already contains the quantitative results and spectral analysis referenced in the claims; we are prepared to enhance clarity where needed.
read point-by-point responses
-
Referee: [Abstract] Abstract, claim (3): The headline result that DERNet outperforms YOLOv11 at the same scale with 1/6 the parameters is load-bearing for the contribution, yet the abstract supplies no mAP values, parameter tables, dataset splits, or error bars. The full manuscript must include these quantitative comparisons and ablations to substantiate the efficiency claim.
Authors: The abstract is intentionally concise per conference guidelines. The full manuscript substantiates the efficiency claim with mAP values, parameter counts, dataset details, splits, and ablations (including error bars) in Section 4, Tables 1–4, and Figures 5–8. These cover all four benchmarks and direct comparisons to YOLOv11 variants. We will revise the abstract to include one or two key mAP deltas if space allows under the word limit. revision: partial
-
Referee: [Spectral diagnostics section] § on spectral diagnostics and error decomposition: The central premise that WDG, LGE, and FDHead isolate discriminative high-frequency components for small objects (rather than amplifying background clutter) is not secured by the description. The paper should provide concrete evidence, such as frequency-spectrum comparisons before/after each module or controlled experiments on synthetic small-object data, to rule out dataset-specific frequency bias in the UAV benchmarks.
Authors: Section 4.3 already presents spectral diagnostics, frequency visualizations, and error decomposition across modules. To directly address the request for stronger isolation evidence, we will add explicit before/after frequency-spectrum plots for WDG, LGE, and FDHead individually, plus controlled experiments on synthetic small-object data with known frequency content, in the revised manuscript. revision: yes
Circularity Check
No circularity: architectural proposal validated empirically on external benchmarks
full rationale
The paper introduces a new Frequency-Guided Feature Representation framework and DER operator (instantiated as WDG, LGE, and FDHead modules) as independent architectural additions to existing CNN/Transformer detectors. Performance claims (DERNet outperforming same-scale YOLOv11 with 1/6 parameters) rest on empirical results across VisDrone2019, UAVDT, TinyPerson, and DOTAv1 rather than any equations, fitted parameters, or self-citations that reduce the gains to a definitional loop or construction from the inputs themselves. No load-bearing self-citation chains, ansatzes smuggled via prior work, or renamings of known results appear in the provided text; the spectral diagnostics are presented as post-hoc analysis, not as the source of the claimed improvements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-frequency spectral components carry the critical discriminative information for small objects that spatial downsampling discards.
invented entities (1)
-
Decompose-Enhance-Reconstruct (DER) operator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Tide: A general toolbox for identifying object detection errors, 2020
Bolya, D., Foley, S., Hays, J., and Hoffman, J. Tide: A general toolbox for identifying object detection errors, 2020. URL https://arxiv.org/abs/2008.08115
arXiv 2020
-
[5]
Frequency-aware feature fusion for dense image prediction
Chen, L., Fu, Y., Gu, L., Yan, C., Harada, T., and Huang, G. Frequency-aware feature fusion for dense image prediction. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. doi:10.48550/arXiv.2408.12879. Accepted by TPAMI, 2024
-
[8]
The unmanned aerial vehicle benchmark: Object detection and tracking
Du, D., Qi, Y., Yu, H., Yang, Y., Duan, K., Li, G., Zhang, W., Huang, Q., and Tian, Q. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), pp.\ 370--386, 2018
2018
-
[9]
Visdrone-det2019: The vision meets drone object detection in image challenge results
Du, D., Zhu, P., Wen, L., Bian, X., Lin, H., Hu, Q., Peng, T., Zheng, J., Wang, X., Zhang, Y., et al. Visdrone-det2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, pp.\ 0--0, 2019
2019
-
[10]
Cross-layer feature pyramid transformer for small object detection in aerial images, 2024
Du, Z., Hu, Z., Zhao, G., Jin, Y., and Ma, H. Cross-layer feature pyramid transformer for small object detection in aerial images, 2024. URL https://arxiv.org/abs/2407.19696
arXiv 2024
-
[12]
E., Amoyal, R., Treister, E., and Freifeld, O
Finder, S. E., Amoyal, R., Treister, E., and Freifeld, O. Wavelet convolutions for large receptive fields. In Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., and Varol, G. (eds.), Computer Vision -- ECCV 2024, pp.\ 363--380, Cham, 2025. Springer Nature Switzerland. ISBN 978-3-031-72949-2
2024
-
[14]
Deim: Detr with improved matching for fast convergence, 2025
Huang, S., Lu, Z., Cun, X., Yu, Y., Zhou, X., and Shen, X. Deim: Detr with improved matching for fast convergence, 2025. URL https://arxiv.org/abs/2412.04234
arXiv 2025
-
[15]
Khanam, R. and Hussain, M. YOLOv11 : An overview of the key architectural enhancements. arXiv preprint arXiv:2410.17725, 2024
Pith/arXiv arXiv 2024
-
[16]
Rethinking features-fused-pyramid-neck for object detection
Li, H. Rethinking features-fused-pyramid-neck for object detection. In European Conference on Computer Vision (ECCV). Springer, 2024
2024
-
[18]
Adaptive complex wavelet informed transformer operator
Li, X., Jiao, L., Liu, F., Yang, S., Zhu, H., Liu, X., Li, L., and Ma, W. Adaptive complex wavelet informed transformer operator. IEEE Transactions on Multimedia, 27: 0 3513--3526, 2025. doi:10.1109/TMM.2025.3535392
-
[20]
L., and Doll \'a r, P
Lin, T.-Y., Maire, M., Belongie, S., Bourdev, L., Girshick, R., Hays, J., Perona, P., Ramanan, D., Zitnick, C. L., and Doll \'a r, P. Microsoft coco: Common objects in context. In European Conference on Computer Vision (ECCV), pp.\ 740--755. Springer, 2014
2014
-
[21]
Feature pyramid networks for object detection
Lin, T.-Y., Doll \'a r, P., Girshick, R., He, K., Hariharan, B., and Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 2117--2125, 2017 b
2017
-
[23]
Path aggregation network for instance segmentation, 2018
Liu, S., Qi, L., Qin, H., Shi, J., and Jia, J. Path aggregation network for instance segmentation, 2018. URL https://arxiv.org/abs/1803.01534
Pith/arXiv arXiv 2018
-
[24]
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.-Y., and Berg, A. C. SSD : Single shot multibox detector. In Computer Vision--ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part I, pp.\ 21--37. Springer, 2016
2016
-
[25]
Luan, D., Dong, Y., Zhou, J., Li, A., Xie, L., Liu, H., and Zhu, J. WCDB-YOLO : Wavelet-enhanced contextual dual-backbone network for small object detection in uav aerial imagery. Drones, 10 0 (3): 0 155, 2026. doi:10.3390/drones10030155. URL https://www.mdpi.com/2504-446X/10/3/155
-
[26]
D-FINE : Redefine regression task in DETR s as fine-grained distribution refinement
Peng, Y., Li, H., Wu, P., Zhang, Y., Sun, X., and Wu, F. D-FINE : Redefine regression task in DETR s as fine-grained distribution refinement. arXiv preprint arXiv:2410.13842, 2024. doi:10.48550/arXiv.2410.13842. URL https://arxiv.org/abs/2410.13842
-
[27]
Fcanet: Frequency channel attention networks
Qin, Z., Zhang, P., Wu, F., and Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp.\ 783--792, 2021
2021
-
[28]
GFNet : Global filter networks for visual recognition
Rao, Y., Zhao, W., Zhu, Z., Zhou, J., and Lu, J. GFNet : Global filter networks for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 45 0 (9): 0 10960--10973, September 2023. doi:10.1109/TPAMI.2023.3263824
-
[29]
You only look once: Unified, real-time object detection, 2016
Redmon, J., Divvala, S., Girshick, R., and Farhadi, A. You only look once: Unified, real-time object detection, 2016. URL https://arxiv.org/abs/1506.02640
Pith/arXiv arXiv 2016
-
[30]
Faster R-CNN : Towards real-time object detection with region proposal networks
Ren, S., He, K., Girshick, R., and Sun, J. Faster R-CNN : Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems (NeurIPS), volume 28, 2015
2015
-
[31]
Sapkota, R., Cheppally, R. H., Sharda, A., and Karkee, M. Yolo26: Key architectural enhancements and performance benchmarking for real-time object detection, 2026. URL https://arxiv.org/abs/2509.25164
arXiv 2026
-
[32]
HS-FPN : High frequency and spatial perception fpn for tiny object detection
Shi, Z., Hu, J., Ren, J., Ye, H., Yuan, X., Ouyang, Y., He, J., Ji, B., and Guo, J. HS-FPN : High frequency and spatial perception fpn for tiny object detection. arXiv preprint arXiv:2412.10116, 2025
arXiv 2025
-
[33]
Tan, M., Pang, R., and Le, Q. V. Efficientdet: Scalable and efficient object detection, 2020. URL https://arxiv.org/abs/1911.09070
arXiv 2020
-
[34]
Tang, F., Nian, B., Ding, J., Ma, W., Quan, Q., Dong, C., Yang, J., Liu, W., and Zhou, S. K. Mobile U-ViT : Revisiting large kernel and U -shaped vit for efficient medical image segmentation. arXiv preprint arXiv:2508.01064, 2025
arXiv 2025
-
[35]
Yolov12: Attention-centric real-time object detectors, 2025
Tian, Y., Ye, Q., and Doermann, D. Yolov12: Attention-centric real-time object detectors, 2025. URL https://arxiv.org/abs/2502.12524
Pith/arXiv arXiv 2025
-
[37]
LSNet : See large, focus small
Wang, A., Chen, H., Lin, Z., Han, J., and Ding, G. LSNet : See large, focus small. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[38]
Wang, J., Zhang, W., Cao, Y., Chen, K., Pang, J., Gong, T., Shi, J., Loy, C. C., and Lin, D. Side-aware boundary localization for more precise object detection, 2020. URL https://arxiv.org/abs/1912.04260
arXiv 2020
-
[39]
Dota: A large-scale dataset for object detection in aerial images
Xia, G.-S., Bai, X., Ding, J., Zhu, Z., Belongie, S., Luo, J., Datcu, M., Pelillo, M., and Zhang, L. Dota: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp.\ 3974--3983, 2018
2018
-
[40]
FBRT-YOLO : Faster and better for real-time aerial image detection
Xiao, Y., Xu, T., Xin, Y., and Li, J. FBRT-YOLO : Faster and better for real-time aerial image detection. arXiv preprint arXiv:2504.20670, 2025
arXiv 2025
-
[42]
Yu, F. and Koltun, V. Multi-scale context aggregation by dilated convolutions, 2016. URL https://arxiv.org/abs/1511.07122
Pith/arXiv arXiv 2016
-
[43]
Scale match for tiny person detection
Yu, X., Gong, Y., Jiang, N., Ye, Q., and Han, Z. Scale match for tiny person detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp.\ 1257--1265, 2020
2020
-
[44]
Zhang, H., Li, F., Liu, S., Zhang, L., Su, H., Zhu, J., Ni, L. M., and Shum, H.-Y. DINO : DETR with improved denoising anchor boxes for end-to-end object detection. arXiv preprint arXiv:2203.03605, 2022 a
Pith/arXiv arXiv 2022
-
[45]
Making convolutional networks shift-invariant again, 2019
Zhang, R. Making convolutional networks shift-invariant again, 2019. URL https://arxiv.org/abs/1904.11486
Pith/arXiv arXiv 2019
-
[46]
Efficient long-range attention network for image super-resolution
Zhang, X., Zeng, H., Guo, S., and Zhang, L. Efficient long-range attention network for image super-resolution. In European Conference on Computer Vision, pp.\ 649--667. Springer, 2022 b
2022
-
[48]
arXiv preprint arXiv:2005.12872 , year=
End-to-End Object Detection with Transformers , author=. arXiv preprint arXiv:2005.12872 , year=
arXiv 2005
-
[49]
European Conference on Computer Vision , pages=
Efficient Long-Range Attention Network for Image Super-resolution , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[50]
Wang, Ao and Chen, Hui and Liu, Lihao and Chen, Kai and Lin, Zijia and Han, Jungong and Ding, Guiguang , journal=
-
[51]
Khanam, Rahima and Hussain, Muhammad , journal=
-
[52]
Xiao, Yao and Xu, Tingfa and Xin, Yu and Li, Jianan , journal=
-
[53]
arXiv preprint arXiv:2304.08069 , year=
DETRs Beat YOLOs on Real-time Object Detection , author=. arXiv preprint arXiv:2304.08069 , year=
-
[54]
and Shum, Heung-Yeung , journal=
Zhang, Hao and Li, Feng and Liu, Shilong and Zhang, Lei and Su, Hang and Zhu, Jun and Ni, Lionel M. and Shum, Heung-Yeung , journal=
-
[55]
Wang, Ao and Chen, Hui and Lin, Zijia and Han, Jungong and Ding, Guiguang , booktitle=
-
[56]
Kevin , journal=
Tang, Fenghe and Nian, Bingkun and Ding, Jianrui and Ma, Wenxin and Quan, Quan and Dong, Chengqi and Yang, Jie and Liu, Wei and Zhou, S. Kevin , journal=
-
[57]
, booktitle=
Liu, Wei and Anguelov, Dragomir and Erhan, Dumitru and Szegedy, Christian and Reed, Scott and Fu, Cheng-Yang and Berg, Alexander C. , booktitle=. 2016 , publisher=
2016
-
[58]
Ren, Shaoqing and He, Kaiming and Girshick, Ross and Sun, Jian , booktitle=. Faster
-
[59]
Shi, Zican and Hu, Jing and Ren, Jie and Ye, Hengkang and Yuan, Xuyang and Ouyang, Yan and He, Jia and Ji, Bo and Guo, Junyu , journal=
-
[60]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Feature Pyramid Networks for Object Detection , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[61]
2023 , month=
Rao, Yongming and Zhao, Wenliang and Zhu, Zheng and Zhou, Jie and Lu, Jiwen , journal=. 2023 , month=
2023
-
[62]
Guoping Xu and Wentao Liao and Xuan Zhang and Chang Li and Xinwei He and Xinglong Wu , keywords =. Haar wavelet downsampling: A simple but effective downsampling module for semantic segmentation , journal =. 2023 , issn =. doi:https://doi.org/10.1016/j.patcog.2023.109819 , url =
-
[63]
arXiv preprint arXiv:2503.18783 , year=
Frequency Dynamic Convolution for Dense Image Prediction , author=. arXiv preprint arXiv:2503.18783 , year=
-
[64]
Adaptive Complex Wavelet Informed Transformer Operator , year=
Li, Xiaotong and Jiao, Licheng and Liu, Fang and Yang, Shuyuan and Zhu, Hao and Liu, Xu and Li, Lingling and Ma, Wenping , journal=. Adaptive Complex Wavelet Informed Transformer Operator , year=
-
[65]
and Amoyal, Roy and Treister, Eran and Freifeld, Oren , editor =
Finder, Shahaf E. and Amoyal, Roy and Treister, Eran and Freifeld, Oren , editor =. Wavelet Convolutions for Large Receptive Fields , booktitle =. 2025 , publisher =
2025
-
[66]
Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops , pages=
VisDrone-DET2019: The vision meets drone object detection in image challenge results , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops , pages=
-
[67]
Proceedings of the European Conference on Computer Vision (ECCV) , pages=
The unmanned aerial vehicle benchmark: Object detection and tracking , author=. Proceedings of the European Conference on Computer Vision (ECCV) , pages=
-
[68]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Scale match for tiny person detection , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[69]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
DOTA: A large-scale dataset for object detection in aerial images , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[70]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
FcaNet: Frequency Channel Attention Networks , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
-
[71]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Frequency-aware Feature Fusion for Dense Image Prediction , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[72]
2026 , eprint=
YOLO26: Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection , author=. 2026 , eprint=
2026
-
[73]
2016 , eprint=
You Only Look Once: Unified, Real-Time Object Detection , author=. 2016 , eprint=
2016
-
[74]
Recent advances in small object detection based on deep learning: A review , journal =
Kang Tong and Yiquan Wu and Fei Zhou , keywords =. Recent advances in small object detection based on deep learning: A review , journal =. 2020 , issn =. doi:https://doi.org/10.1016/j.imavis.2020.103910 , url =
-
[75]
2018 , eprint=
Path Aggregation Network for Instance Segmentation , author=. 2018 , eprint=
2018
-
[76]
2016 , eprint=
Multi-Scale Context Aggregation by Dilated Convolutions , author=. 2016 , eprint=
2016
-
[77]
Proceedings of the European conference on computer vision (ECCV) , pages=
Sod-mtgan: Small object detection via multi-task generative adversarial network , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[78]
2020 , eprint=
EfficientDet: Scalable and Efficient Object Detection , author=. 2020 , eprint=
2020
-
[79]
2019 , eprint=
Making Convolutional Networks Shift-Invariant Again , author=. 2019 , eprint=
2019
-
[80]
2020 , eprint=
Side-Aware Boundary Localization for More Precise Object Detection , author=. 2020 , eprint=
2020
-
[81]
European Conference on Computer Vision (ECCV) , year =
Microsoft COCO: Common Objects in Context , author =. European Conference on Computer Vision (ECCV) , year =
-
[82]
European Conference on Computer Vision (ECCV) , year =
Rethinking Features-Fused-Pyramid-Neck for Object Detection , author =. European Conference on Computer Vision (ECCV) , year =
-
[83]
2024 , eprint =
Cross-Layer Feature Pyramid Transformer for Small Object Detection in Aerial Images , author =. 2024 , eprint =
2024
-
[84]
Jiayi Chen and Ningzhong Liu and Han Sun and Yu Wang , keywords =. Freq-DETR: Frequency-aware transformer for real-time small object detection in unmanned aerial vehicle imagery , journal =. 2026 , issn =. doi:https://doi.org/10.1016/j.eswa.2025.129710 , url =
-
[85]
2020 , eprint=
TIDE: A General Toolbox for Identifying Object Detection Errors , author=. 2020 , eprint=
2020
-
[86]
RTMDet-R2: An Improved Real-Time Rotated Object Detector
Xiang, Haifeng and Jing, Naifeng and Jiang, Jianfei and Guo, Hongbo and Sheng, Weiguang and Mao, Zhigang and Wang, Qin. RTMDet-R2: An Improved Real-Time Rotated Object Detector. Pattern Recognition and Computer Vision. 2024
2024
-
[87]
arXiv preprint arXiv:2111.00902 , year =
PP-PicoDet: A Better Real-Time Object Detector on Mobile Devices , author =. arXiv preprint arXiv:2111.00902 , year =
-
[88]
2026 , doi =
Luan, Di and Dong, Yuna and Zhou, Jian and Li, Ang and Xie, Ling and Liu, Hongying and Zhu, Jun , journal =. 2026 , doi =
2026
-
[89]
2024 , doi =
Peng, Yansong and Li, Hebei and Wu, Peixi and Zhang, Yueyi and Sun, Xiaoyan and Wu, Feng , journal =. 2024 , doi =
2024
-
[90]
Jinjiang Liu and Yonghua Xie , keywords =. WDFS-DETR: A Transformer-based framework with multi-scale attention for small object detection in UAV Engineering Tasks , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.rineng.2025.105930 , url =
-
[91]
Xiyang Dai and Yinpeng Chen and Bin Xiao and Dongdong Chen and Mengchen Liu and Lu Yuan and Lei Zhang , title =. CoRR , volume =. 2021 , url =. 2106.08322 , timestamp =
arXiv 2021
-
[92]
Xiang Li and Wenhai Wang and Lijun Wu and Shuo Chen and Xiaolin Hu and Jun Li and Jinhui Tang and Jian Yang , title =. CoRR , volume =. 2020 , url =. 2006.04388 , timestamp =
arXiv 2020
-
[93]
Scott and Weilin Huang , title =
Chengjian Feng and Yujie Zhong and Yu Gao and Matthew R. Scott and Weilin Huang , title =. CoRR , volume =. 2021 , url =. 2108.07755 , timestamp =
arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.