SegTME-UNI2: A Foundation Model-Based Framework for Generalisable Multiclass Cell Segmentation and LLM-Driven Tumour Microenvironment Characterisation in Histopathology
Pith reviewed 2026-06-27 01:37 UTC · model grok-4.3
The pith
A pathology foundation model paired with dual decoders, trained through three stages of progressively refined pseudo-labels, produces generalisable six-class cell segmentation that feeds an LLM to generate tumour microenvironment narratives
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
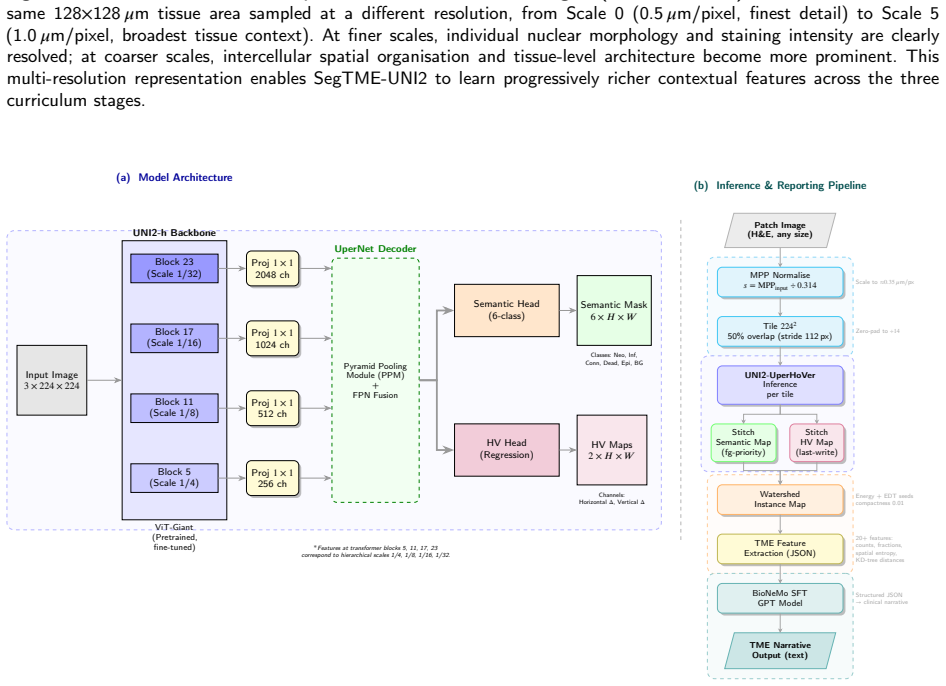
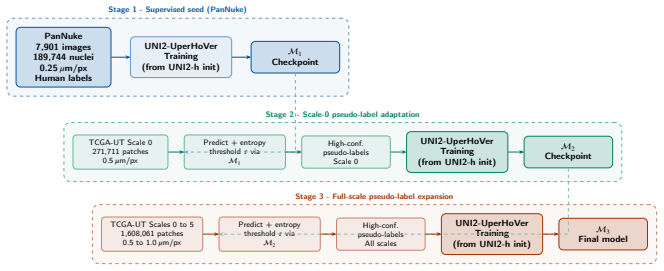
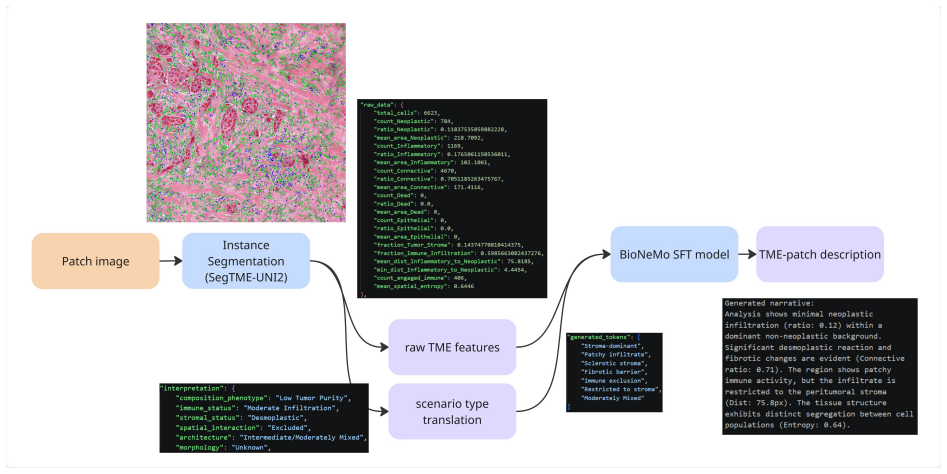
UNI2-UperHoVeR pairs the UNI2-h ViT-Giant foundation model with two parallel UperNet decoders—one producing six-class semantic segmentation and the other regressing horizontal-vertical gradients for watershed-based instance separation—and is trained via a three-stage progressive pseudo-label curriculum: stage 1 on human-annotated PanNuke, stage 2 on entropy-filtered outputs of the stage-1 model applied to 271k TCGA-UT patches, and stage 3 on entropy-filtered outputs of the stage-2 model applied to 1.6M patches across six resolution scales, with no weight transfer between stages; the resulting segmentation outputs drive a TME feature pipeline that encodes more than twenty metrics as JSON for
What carries the argument
The three-stage progressive pseudo-label curriculum, in which each fresh model is trained exclusively on entropy-filtered pseudo-labels generated by the preceding model to raise label quality without weight transfer or human correction.
If this is right
- The six-class segmentation and instance separation generalise across the resolution scales and tissue types present in TCGA-UT.
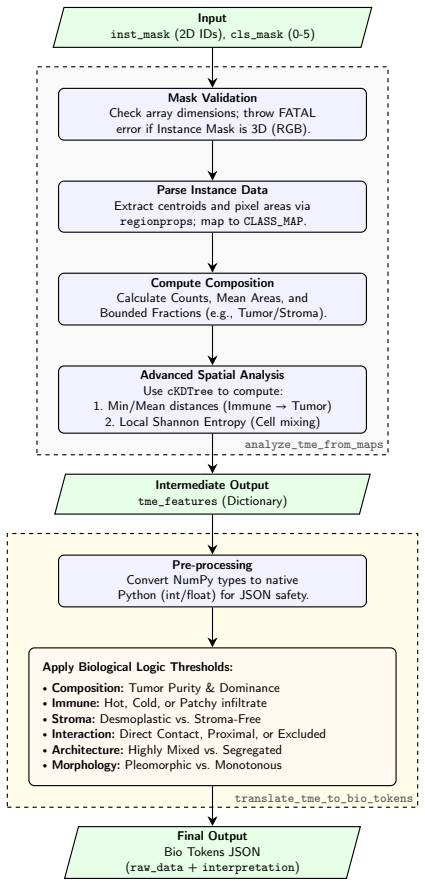
- The TME pipeline computes more than twenty per-patch metrics covering composition, morphology, spatial entropy, and intercellular distances.
- JSON-encoded features from the pipeline are converted by the fine-tuned BioNeMo GPT into clinically interpretable narratives.
- The released pseudo-labelled TCGA-UT dataset and UNI2-UperHoVeR checkpoint directly support large-scale TME profiling.
Where Pith is reading between the lines
- The curriculum may be reusable with other foundation models to bootstrap segmentation tasks that lack dense labels.
- Pairing quantitative TME metrics with LLM narratives could support integration of image-derived features into existing clinical reporting systems.
- Success across multiple resolution scales indicates the framework may tolerate real-world scanner and staining variation once validated on external cohorts.
Load-bearing premise
Entropy-filtered pseudo-labels produced by each successive model are of measurably higher quality than those of the prior stage, sufficient to drive genuine segmentation improvement across tissue types and resolution scales without any human correction or weight transfer.
What would settle it
Segmentation metrics on held-out TCGA-UT partitions show no improvement or decline from stage-1 to stage-3 models, or the LLM-generated TME narratives show systematic mismatch with pathologist review on the same patches.
Figures
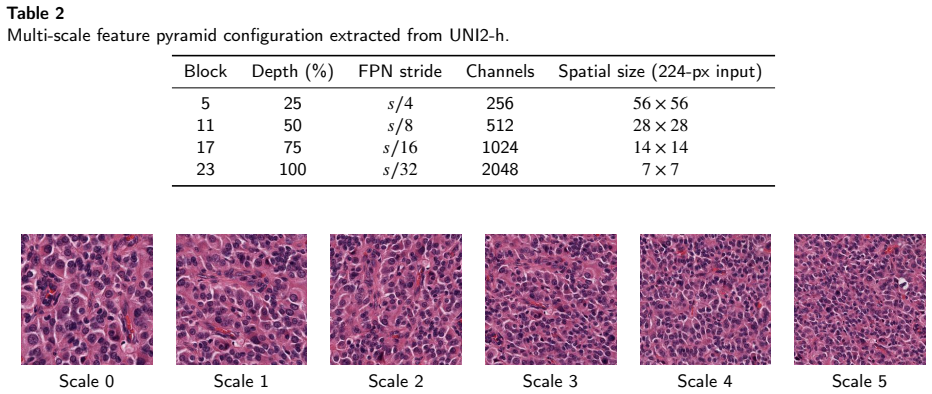
read the original abstract
Characterising the tumour microenvironment (TME) from routine H&E-stained histology images requires simultaneous cell segmentation, feature extraction, and interpretable clinical reporting. We present SegTME-UNI2, a unified framework addressing these requirements. Its core is UNI2-UperHoVeR, a dual-head segmentation model pairing the UNI2-h pathology foundation model (ViT-Giant, pretrained on >100M tiles from 100K slides) with two parallel UperNet decoders: one for six-class semantic segmentation and one for horizontal-vertical gradient regression enabling watershed-based nuclear instance separation. To address the lack of pixel-level annotations in large real-world repositories, UNI2-UperHoVeR undergoes a three-stage progressive pseudo-label curriculum. Each stage trains a fresh model without weight transfer, driving improvement entirely via increased pseudo-label quality: Stage 1: Uses human-annotated PanNuke (7,901 images, 189,744 nuclei, 0.25 um/pixel). Stage 2: Uses entropy-filtered pseudo-labels from the Stage 1 model on 271,711 TCGA-UT scale-0 patches (0.5 um/pixel). Stage 3: Uses pseudo-labels from the Stage 2 model on all 1,608,060 TCGA-UT patches across six resolution scales (0.5-1.0 um/pixel). Segmentation outputs feed a structured TME feature extraction pipeline computing 20+ per-patch compositional, morphological, spatial entropy, and intercellular distance metrics. These are encoded as JSON and passed to a fine-tuned NVIDIA BioNeMo GPT model to generate clinically interpretable TME narratives. Preliminary validation on held-out PanNuke and TCGA-UT partitions demonstrates framework feasibility and internal consistency. The pseudo-labelled TCGA-UT dataset and UNI2-UperHoVeR checkpoint are publicly released to support large-scale TME profiling and spatial biology research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SegTME-UNI2, a framework centered on UNI2-UperHoVeR (UNI2-h ViT-Giant backbone with dual UperNet heads for six-class semantic segmentation and H/V gradient regression for watershed instance separation). It trains this model via a three-stage progressive pseudo-label curriculum (human-annotated PanNuke Stage 1; entropy-filtered pseudo-labels on TCGA-UT scale-0 patches Stage 2; full multi-scale TCGA-UT Stage 3, each stage training a fresh model with no weight transfer), then feeds outputs into a 20+ metric TME feature pipeline whose JSON is rendered as clinical narratives by a fine-tuned BioNeMo GPT. Preliminary validation on held-out PanNuke/TCGA-UT partitions is reported as demonstrating feasibility and internal consistency; the pseudo-labeled dataset and checkpoint are released publicly.
Significance. If the curriculum demonstrably improves pseudo-label quality and yields generalisable six-class segmentation plus instance separation across TCGA-UT resolutions, the framework would provide a scalable route to TME profiling on large unannotated H&E repositories and link quantitative spatial features to LLM-generated narratives. The public release of the pseudo-labeled TCGA-UT dataset and UNI2-UperHoVeR checkpoint is a concrete strength supporting reproducibility and downstream spatial-biology research.
major comments (3)
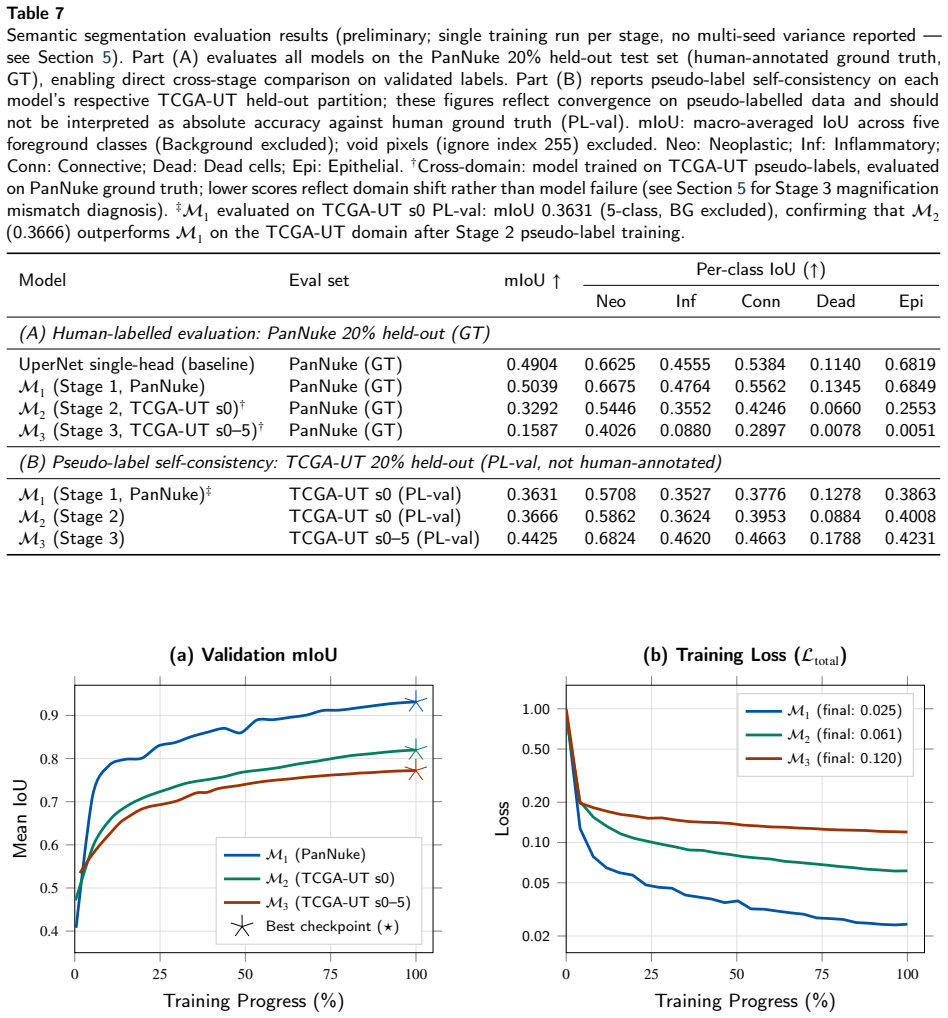
- [Abstract] Abstract: the claim that the three-stage curriculum produces generalisable segmentation 'driving improvement entirely via increased pseudo-label quality' is load-bearing for the central contribution, yet no cross-stage quantitative verification (e.g., agreement with Stage-1 PanNuke labels, entropy-distribution shifts, or per-class Dice on held-out TCGA-UT) is supplied; internal consistency on held-out partitions alone does not confirm that entropy-filtered labels from each fresh model are strictly higher quality.
- [Abstract / Validation] Validation description (preliminary validation paragraph): only 'preliminary validation' and 'internal consistency' are stated, with no reported quantitative metrics (Dice, PQ, AJI, or instance-level F1), ablation of curriculum stages, or external test sets; this leaves the generalisability claim across 0.5–1.0 µm/pixel scales and tissue types unsupported by evidence.
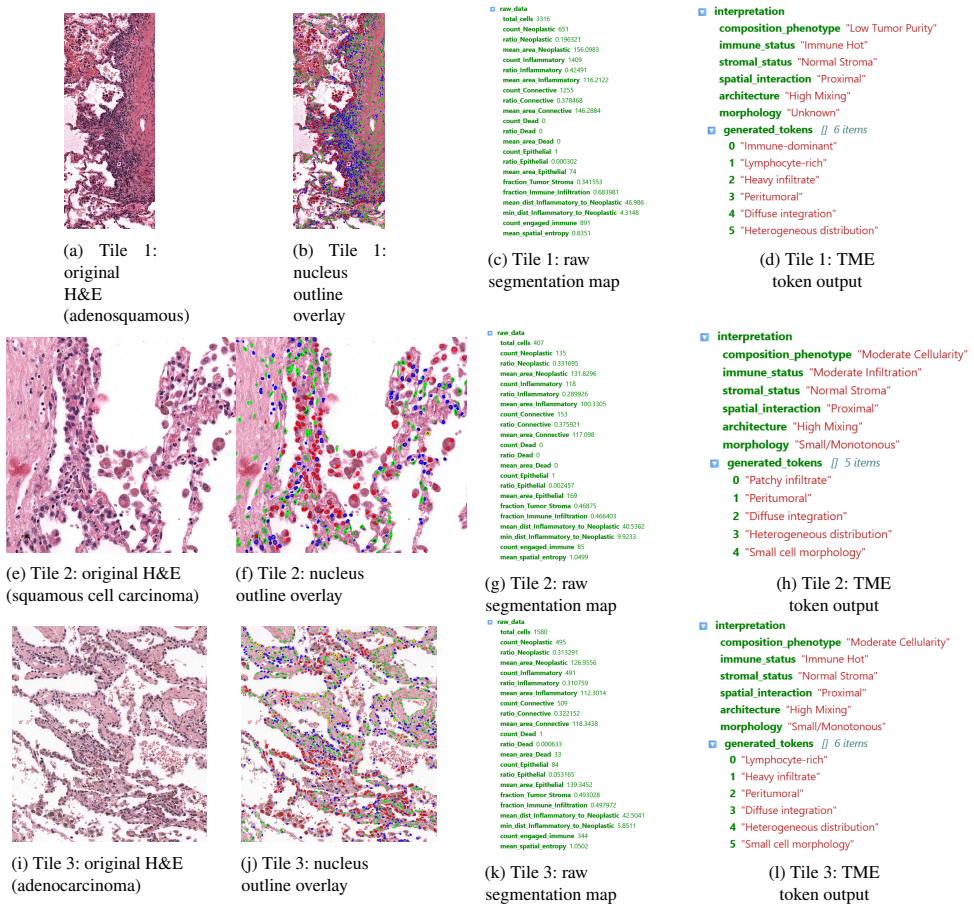
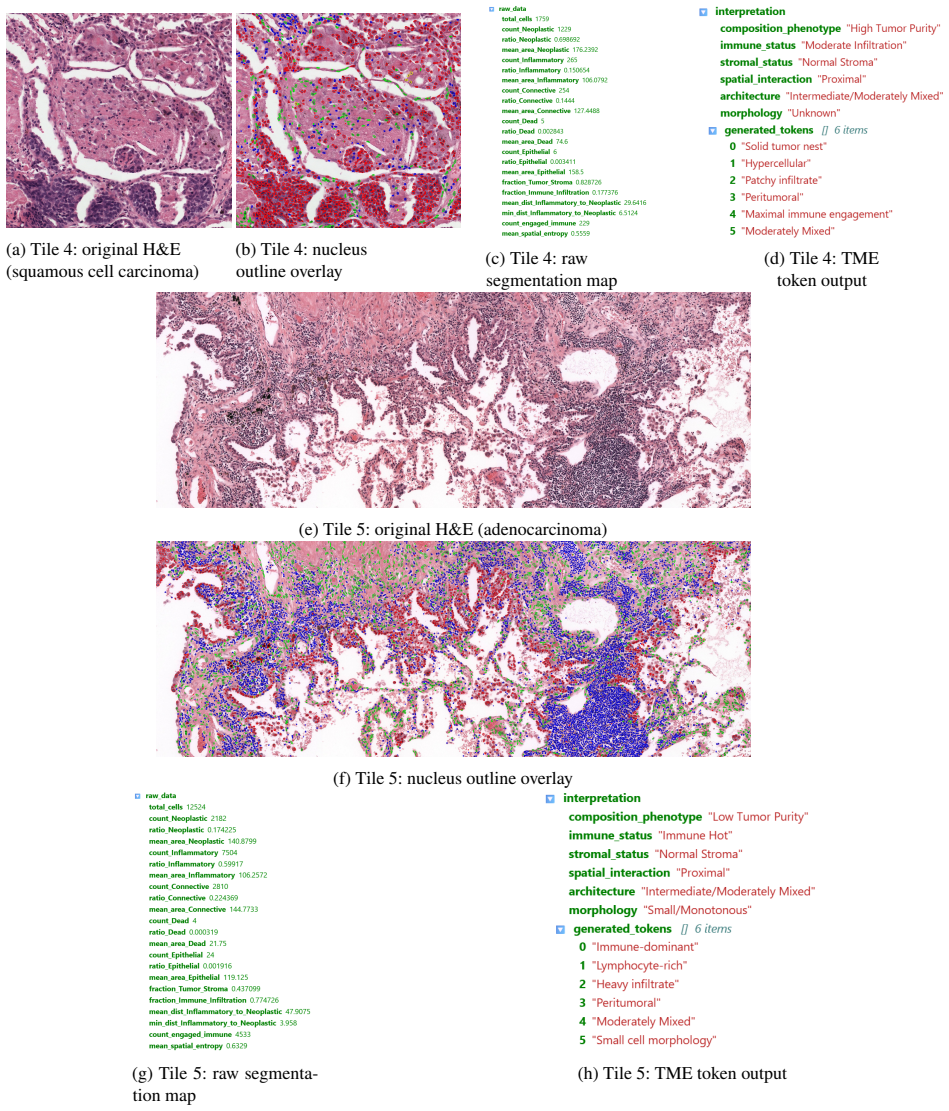
- [TME pipeline] TME feature pipeline section: the 20+ compositional/morphological/spatial metrics and their JSON encoding are asserted to feed clinically interpretable narratives, but no concrete output examples, human evaluation of narrative fidelity, or correlation with known TME biology are provided to substantiate the end-to-end utility.
minor comments (2)
- [Stage 3 description] Clarify whether the six resolution scales in Stage 3 are handled by a single model or by scale-specific fine-tuning; the current description leaves the multi-scale training procedure ambiguous.
- [Curriculum] The abstract states 'no weight transfer' between stages; confirm this is also true for the decoder heads and any auxiliary losses.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond point-by-point to the major comments, indicating where revisions will strengthen the manuscript while maintaining honesty about current limitations.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the three-stage curriculum produces generalisable segmentation 'driving improvement entirely via increased pseudo-label quality' is load-bearing for the central contribution, yet no cross-stage quantitative verification (e.g., agreement with Stage-1 PanNuke labels, entropy-distribution shifts, or per-class Dice on held-out TCGA-UT) is supplied; internal consistency on held-out partitions alone does not confirm that entropy-filtered labels from each fresh model are strictly higher quality.
Authors: We agree that direct cross-stage verification would better substantiate the claim. The manuscript currently supports the progressive curriculum via the design (entropy filtering + scale expansion) and held-out consistency, but lacks explicit metrics like entropy shifts or label agreement. In revision we will add such analyses (e.g., entropy distributions and per-class metrics on held-out data) to provide quantitative support for quality improvement. revision: yes
-
Referee: [Abstract / Validation] Validation description (preliminary validation paragraph): only 'preliminary validation' and 'internal consistency' are stated, with no reported quantitative metrics (Dice, PQ, AJI, or instance-level F1), ablation of curriculum stages, or external test sets; this leaves the generalisability claim across 0.5–1.0 µm/pixel scales and tissue types unsupported by evidence.
Authors: The validation is presented as preliminary and focused on feasibility. We will revise the abstract and validation section to report specific metrics (Dice, PQ, AJI, F1) from held-out PanNuke/TCGA-UT partitions and include curriculum-stage ablations. External test sets beyond the held-out TCGA-UT partitions are not available in the current study; we will clarify the scope of generalisability to the tested distributions and resolutions while noting this limitation. revision: partial
-
Referee: [TME pipeline] TME feature pipeline section: the 20+ compositional/morphological/spatial metrics and their JSON encoding are asserted to feed clinically interpretable narratives, but no concrete output examples, human evaluation of narrative fidelity, or correlation with known TME biology are provided to substantiate the end-to-end utility.
Authors: We acknowledge the absence of concrete examples and evaluations for the TME narrative component. In the revised manuscript we will include sample JSON outputs paired with generated narratives, plus qualitative discussion of alignment with known TME biology to better demonstrate end-to-end utility. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's derivation consists of a three-stage pseudo-label curriculum (human-annotated PanNuke to entropy-filtered TCGA-UT stages) feeding segmentation outputs into a TME metric pipeline and then an LLM for narratives. No equations, self-citations, or definitions reduce any claimed prediction or improvement to quantities defined by the inputs themselves; the curriculum improvement is asserted via the training process and internal consistency on held-out partitions rather than by construction. The foundation model and BioNeMo components are external, and no uniqueness theorems or ansatzes are invoked in a load-bearing way. The chain is therefore self-contained against external benchmarks and does not match any enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Entropy-filtered pseudo-labels from each stage are of higher quality than the previous stage
Reference graph
Works this paper leans on
-
[1]
Bai, W., Oktay, O., Sinclair, M., Suzuki, H., Rajchl, M., Tarroni, G., Glocker, B., King, A., Matthews, P.M., Rueckert, D., 2017. Semi- supervised learning for network-based cardiac mr image segmentation, in: Medical Image Computing and Computer Assisted Intervention (MICCAI), pp. 253–260. doi:10.1007/978-3-319-66185-8_29
-
[2]
Digitalquantificationofstromapercentageenhancesprognosticstratification in pancreatic cancer
Bengtsson,A.,Andersson,R.,Andersson,B.,Ansari,D.,2026. Digitalquantificationofstromapercentageenhancesprognosticstratification in pancreatic cancer. Surgery in Practice and Science doi:10.1016/j.sopen.2026.01.002
-
[3]
Towards a general-purpose foundation model for computational pathology
Chen, R.J., Ding, T., Lu, M.Y., Williamson, D.F.K., Jaume, G., Song, A.H., Chen, B., Zhang, A., Shao, D., Schuffler, P.J., Mahmood, F., 2024a. Towards a general-purpose foundation model for computational pathology. Nature Medicine 30, 850–862. doi:10.1038/ s41591-024-02857-3
-
[4]
Uni2: Towards a universal whole-slide foundation model for pathology
Chen, R.J., Lu, M.Y., Ding, T., Williamson, D.F.K., Jaume, G., Chen, B., Mahmood, F., 2024b. Uni2: Towards a universal whole-slide foundation model for pathology. arXiv preprint arXiv:2406.01647 doi:10.48550/arXiv.2406.01647
-
[5]
Approaches to treat immune hot, altered and cold tumours with combination immunotherapies
Galon, J., Bruni, D., 2019. Approaches to treat immune hot, altered and cold tumours with combination immunotherapies. Nature Reviews Drug Discovery 18, 197–218. doi:10.1038/s41573-018-0007-y
-
[6]
Type, density, and location of immune cells within human colorectal tumors predict clinical outcome
Galon, J., Costes, A., Sanchez-Cabo, F., Kirilovsky, A., Mlecnik, B., Lagorce-Pageès, C., Tosolini, M., Camus, M., Berger, A., Wind, P., Zinzindohoué, F., Bruneval, P., Cugnenc, P.H., Trajanoski, Z., Fridman, W.H., Pagès, F., 2006. Type, density, and location of immune cells within human colorectal tumors predict clinical outcome. Science 313, 1960–1964. ...
-
[7]
Pannukedataset extension, insights and baselines
Gamper,J.,Koohbanani,N.A.,Benes,K.,Graham,S.,Jahanifar,M.,Khurram,S.A.,Azam,A.,Hewitt,K.,Rajpoot,N.,2020. Pannukedataset extension, insights and baselines. arXiv preprint arXiv:2003.10778 doi:10.48550/arXiv.2003.10778
-
[8]
Hover-net: Simultaneous segmentation and classification of nuclei in multi-tissue histology images
Graham, S., Vu, Q.D., Raza, S.E.A., Azam, A., Tsang, Y.W., Kwak, J.T., Rajpoot, N., 2019. Hover-net: Simultaneous segmentation and classification of nuclei in multi-tissue histology images. Medical Image Analysis 58, 101563. doi:10.1016/j.media.2019.101563
-
[9]
Semi-supervisedlearningbyentropyminimization,in:AdvancesinNeuralInformationProcessingSystems (NeurIPS)
Grandvalet,Y.,Bengio,Y.,2004. Semi-supervisedlearningbyentropyminimization,in:AdvancesinNeuralInformationProcessingSystems (NeurIPS)
2004
-
[10]
Hörst, F., Rempe, M., Heine, L., Seibold, C., Keyl, J., Baldini, G., Ugurel, S., Siveke, J., Bockmayr, M., Samek, W., Fuchs, T.J., Kleesiek, J.,
-
[11]
CellViT: Vision transformers for precise cell segmentation and classification. Medical Image Analysis 94, 103143. doi:10.1016/j. media.2024.103143
work page doi:10.1016/j 2024
-
[12]
A visual-language foundation model for pathology image analysis using medical twitter
Huang, Z., Bianchi, F., Yuksekgonul, M., Montine, T.J., Zou, J., 2023. A visual-language foundation model for pathology image analysis using medical twitter. Nature Medicine 29, 2307–2316. doi:10.1038/s41591-023-02504-3
-
[13]
Kather, J.N., Pearson, A.T., Halama, N., Jäger, D., Krause, J., Loosen, S.H., Marx, A., Boor, P., Tacke, F., Neumann, U.P., Grabsch, H.I., Yoshikawa, T., Brenner, H., Chang-Claude, J., Hoffmeister, M., Trautwein, C., Luedde, T., 2019. Deep learning can predict microsatellite instability directly from histology in gastrointestinal cancer. Nature Medicine 2...
-
[14]
Keren,L.,Bosse,M.,Marquez,D.,Angoshtari,R.,Jain,S.,Varma,S.,Yang,S.R.,Kurian,A.,VanValen,D.,West,R.,Bendall,S.C.,Angelo, M., 2018. A structured tumor-immune microenvironment in triple negative breast cancer revealed by multiplexed ion beam imaging. Cell 174, 1373–1387. doi:10.1016/j.cell.2018.08.039
-
[15]
Kirillov, A., He, K., Girshick, R., Rother, C., Dollár, P., 2019. Panoptic segmentation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 9404–9413. doi:10.1109/CVPR.2019.00963
-
[17]
Morphometric grading of invasive ductal breast cancer
Kronqvist, P., Kuopio, T., Collan, Y., 1998. Morphometric grading of invasive ductal breast cancer. i. thresholds for nuclear grade. British Journal of Cancer 78, 800–805. doi:10.1038/bjc.1998.581
-
[18]
A visual-language foundation model for computational pathology
Lu, M.Y., Chen, B., Williamson, D.F.K., Chen, R.J., Liang, I., Ding, T., Jaume, G., Odia, I., Zhang, A., Le, L.P., Gerber, G.K., Mah- mood, F., 2024a. A visual-language foundation model for computational pathology. Nature Medicine 30, 863–874. doi:10.1038/ s41591-024-02856-4
-
[19]
Nature634(8033), 466–473 (Oct 2024)
Lu,M.Y.,Chen,B.,Williamson,D.F.K.,Chen,R.J.,Liang,I.,Ding,T.,Jaume,G.,Odintsov,I.,Le,L.P.,Gerber,G.,Parwani,A.V.,Zhang,A., Mahmood,F.,2024b. AmultimodalgenerativeAIcopilotforhumanpathology. Nature634,604–613. doi:10.1038/s41586-024-07618-3
-
[20]
Lucassen,R.T.,Ciompi,F.,Veta,M.,Ciompi,F.,Bulten,W.,Balkenhol,M.,Geessink,O.,Smit,J.,Litjens,G.,Bejnordi,B.E.,Pluim,J.P.W., van der Laak, J., Geijs, D.J., 2025. A tissue and cell-level annotated H&E and PD-L1 histopathology image dataset in non-small cell lung cancer. arXiv preprint arXiv:2507.16855 doi:10.5281/zenodo.17735903
-
[21]
Bionemo: Large language model framework for life sciences.https://www.nvidia.com/en-us/clara/ bionemo/
NVIDIA Corporation, 2023. Bionemo: Large language model framework for life sciences.https://www.nvidia.com/en-us/clara/ bionemo/
2023
-
[22]
Ronneberger,O.,Fischer,P.,Brox,T.,2015. U-net:Convolutionalnetworksforbiomedicalimagesegmentation,in:MedicalImageComputing and Computer-Assisted Intervention (MICCAI), pp. 234–241. doi:10.1007/978-3-319-24574-4_28
-
[23]
Saltz, J., Gupta, R., Hou, L., Kurc, T., Singh, P., Nguyen, V., Samaras, D., Shroyer, K.R., Zhao, T., Batiste, R., Van Arnam, J., The Cancer GenomeAtlasResearchNetwork,Shmulevich,I.,Rao,A.U.K.,Lazar,A.J.,Sharma,A.,Thorsson,V.,2018.Spatialorganizationandmolecular correlation of tumor-infiltrating lymphocytes using deep learning on pathology images. Cell Re...
-
[24]
Schmidt, U., Weigert, M., Broaddus, C., Myers, G., 2018. Cell detection with star-convex polygons, in: Medical Image Computing and Computer Assisted Intervention (MICCAI), pp. 265–273. doi:10.1007/978-3-030-00934-2_30
-
[25]
Cellpose:ageneralistalgorithmforcellularsegmentation
Stringer, C., Wang, T., Michaelos, M., Pachitariu, M., 2021. Cellpose: a generalist algorithm for cellular segmentation. Nature Methods 18, 100–106. doi:10.1038/s41592-020-01018-x
-
[26]
Tarvainen, A., Valpola, H., 2017. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results, in: Advances in Neural Information Processing Systems (NeurIPS). 27 of 28
2017
-
[27]
Tcga-ut cell instance and semantic pseudo-label dataset
Wan Ahmad, W.S.H.M., 2024. Tcga-ut cell instance and semantic pseudo-label dataset. HuggingFace Datasets.https://huggingface. co/datasets/mizjaggy18/tcga-ut-cell-instance-semantic
2024
-
[28]
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., Davison, J., Shleifer, S., von Platen, P., Ma, C., Jernite, Y., Plu, J., Xu, C., Le Scao, T., Gugger, S., Drame, M., Lhoest, Q., Rush, A., 2020. Transformers: State-of- the-art natural language processing, in: Proceedings of the 2020 Confere...
-
[29]
Xiao, T., Liu, Y., Zhou, B., Jiang, Y., Sun, J., 2018. Unified perceptual parsing for scene understanding, in: Proceedings of the European Conference on Computer Vision (ECCV), pp. 418–434. doi:10.1007/978-3-030-01246-5_26
-
[30]
Segformer: Simple and efficient design for semantic segmentation with transformers, in: Advances in Neural Information Processing Systems (NeurIPS), pp
Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J.M., Luo, P., 2021. Segformer: Simple and efficient design for semantic segmentation with transformers, in: Advances in Neural Information Processing Systems (NeurIPS), pp. 12077–12090
2021
-
[31]
A whole-slide foundation model for digital pathology from real-world data
Xu, H., Usuyama, N., Bagga, J., Zhang, S., Rao, R., Tristan, N., Wong, C., Gero, Z., Javier, G., Poon, H., 2024. A whole-slide foundation model for digital pathology from real-world data. Nature 630, 181–188. doi:10.1038/s41586-024-07441-w. 28 of 28
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.