Decoupling Code Complexity from Newcomer Participation: A Causal Study of AI Coding Agent Adoption in OSS
Pith reviewed 2026-07-03 08:51 UTC · model grok-4.3
The pith
Adopting AI coding agents raises per-function code complexity but shows no causal reduction in newcomer inflow or retention in open-source projects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
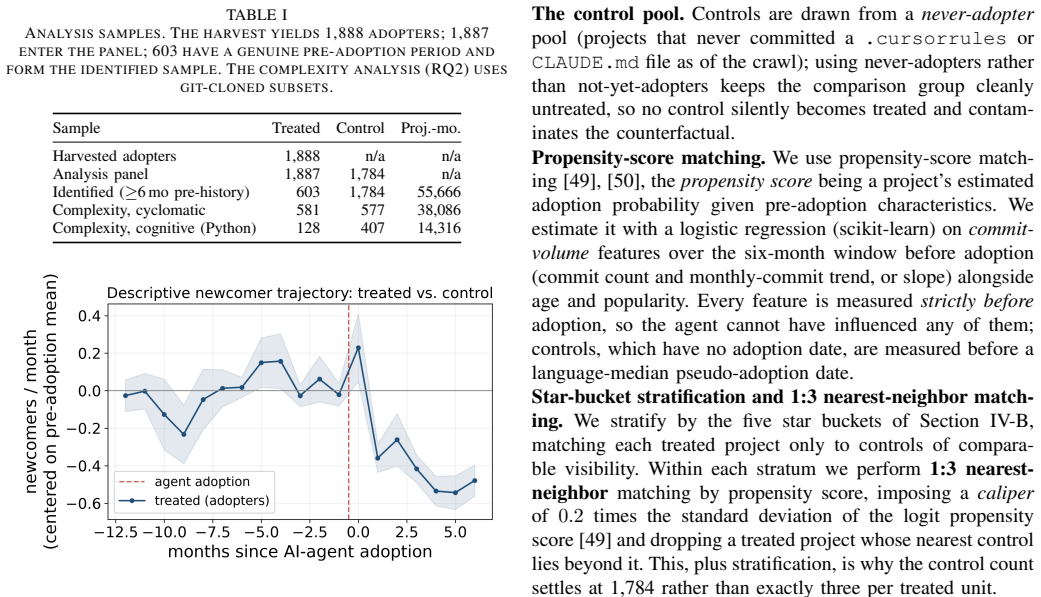
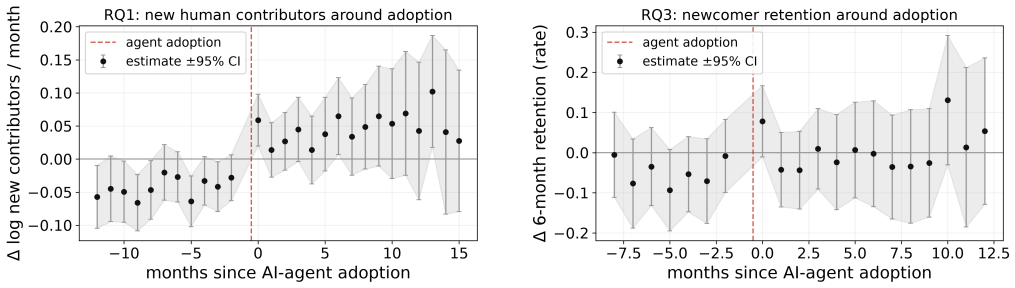
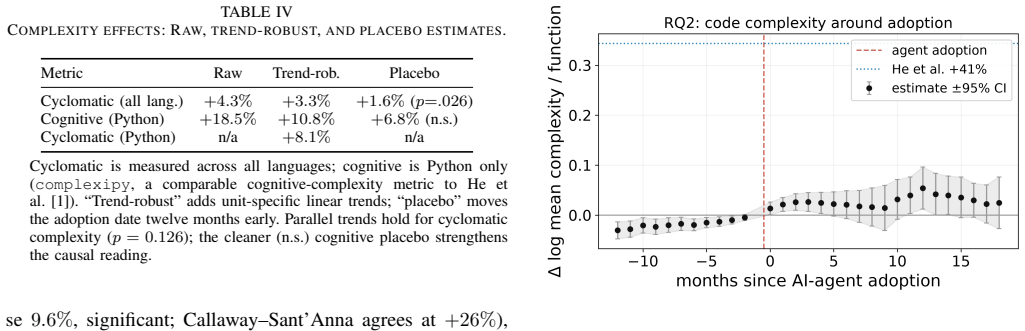
Difference-in-differences estimates on matched projects reveal no significant decline in newcomer inflow after AI agent adoption, with point estimates ranging from a small increase to an insignificant dip under conservative trend controls; onboarding and retention metrics remain unchanged while per-function code complexity increases by about 11 percent on Python cognitive measures and 3-4 percent cyclomatic across languages, yet newcomer participation does not fall in the fixed-unit subsets experiencing those rises.
What carries the argument
Difference-in-differences design on projects matched by pre-adoption characteristics, with adoption timed by the first commit containing an AI coding agent configuration file.
Load-bearing premise
The first commit of a configuration file accurately marks the genuine start of AI agent adoption and that parallel trends plus no anticipation effects hold after matching.
What would settle it
A statistically significant drop in newcomer commits or issues post-adoption in the same 603-project sample under alternative matching or trend specifications would falsify the no-crowding-out finding.
Figures
read the original abstract
Open-source projects depend on a steady inflow of newcomers. A growing concern is that AI coding agents (tools such as Cursor and Claude Code that write code from natural-language instructions) will crowd them out, by absorbing the simple tasks that beginners start with and by making code harder to read. We give this concern a causal answer. Using GitHub code search we identify 1,888 projects that adopted an agent, signaled by their first commit of a configuration file. We apply difference-in-differences against matched non-adopting controls, restricting the main analysis to the 603 adopters with a genuine pre-adoption period. We find no evidence of crowding-out: across estimators newcomer inflow shows no significant decline after adoption (point estimates run from a small increase to, under the most conservative trend specification, a slight and insignificant dip), onboarding and retention are unchanged, and a sparse, correlational beginner-task measure (good-first-issue labels, which we cannot test for parallel trends) shows no decline. The feared mechanism is real but decoupled: adoption raises per-function code complexity (about +11% on a cognitive metric for Python, a quarter of the prior estimate, and +3 to 4% in cyclomatic terms across all languages), yet in fixed-unit subsets where complexity rose (Python on the cognitive metric, and all languages on the cyclomatic metric), newcomer participation does not decline. These results suggest that, in established open-source projects, adopting an AI coding agent makes code modestly more complex but does not crowd out the human newcomers that a project depends on: the feared trade-off between AI assistance and human participation does not materialize.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that adoption of AI coding agents in OSS projects (signaled by first commit of a configuration file) does not crowd out newcomers: DiD estimates on 603 matched projects with pre-adoption periods show no significant decline in newcomer inflow, onboarding, or retention after adoption (point estimates range from small increase to insignificant dip under conservative trends), despite a real increase in code complexity (+11% on Python cognitive metric, +3-4% cyclomatic across languages). The feared trade-off is decoupled, as complexity rises do not reduce participation in fixed-unit subsets.
Significance. If the causal identification holds, the result would be significant for OSS sustainability and AI policy debates, providing evidence that AI assistance can raise complexity without displacing human newcomers. The use of GitHub observational data with standard DiD and matching is a strength, as is the explicit decoupling of the complexity mechanism from participation outcomes.
major comments (3)
- [Methods (treatment identification)] Methods section on treatment definition: The central DiD relies on dating adoption to the first commit of an agent configuration file (identifying 1,888 projects, then restricting to 603 with pre-period). This signal may not mark genuine onset of AI use if many projects commit the file without subsequent agent-generated commits or if informal use preceded it, inducing measurement error in treatment timing and attenuating crowding-out estimates toward zero. The matching and pre-period restriction do not address this.
- [Results (DiD estimates and trend specifications)] Results on parallel trends and robustness: The paper notes the beginner-task measure (good-first-issue labels) cannot be tested for parallel trends and relies on a 'most conservative trend specification' whose details are not fully specified; without these checks or alternative specifications shown for the main inflow/retention outcomes, the no-decline conclusion rests on unverified assumptions.
- [Results (complexity-participation subsets)] Subgroup analysis on complexity and participation: The claim that newcomer participation does not decline in fixed-unit subsets where complexity rose (Python cognitive metric; all languages cyclomatic) is load-bearing for the decoupling conclusion, but requires explicit verification that DiD assumptions (e.g., no anticipation, parallel trends in those subsets) hold after the same matching; otherwise the interpretation is undermined by potential selection.
minor comments (2)
- [Methods (complexity measures)] Clarify the exact definition and validation of the 'cognitive metric' for Python complexity and how it differs from prior estimates.
- [Methods (matching)] Provide more detail on the matching procedure (covariates, caliper, balance checks) to allow replication.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on treatment identification, trend specifications, and subgroup analyses. We address each point below with targeted revisions to strengthen the manuscript while preserving the core findings.
read point-by-point responses
-
Referee: Methods section on treatment definition: The central DiD relies on dating adoption to the first commit of an agent configuration file (identifying 1,888 projects, then restricting to 603 with pre-period). This signal may not mark genuine onset of AI use if many projects commit the file without subsequent agent-generated commits or if informal use preceded it, inducing measurement error in treatment timing and attenuating crowding-out estimates toward zero. The matching and pre-period restriction do not address this.
Authors: We agree this proxy introduces potential measurement error. Such error would bias estimates toward zero, rendering our null finding on crowding-out more conservative rather than overstated. We will add a robustness check restricting the sample to projects with post-config commits exhibiting agent-like patterns (e.g., large automated diffs) and expand the limitations section to discuss pre-adoption informal use. revision: partial
-
Referee: Results on parallel trends and robustness: The paper notes the beginner-task measure (good-first-issue labels) cannot be tested for parallel trends and relies on a 'most conservative trend specification' whose details are not fully specified; without these checks or alternative specifications shown for the main inflow/retention outcomes, the no-decline conclusion rests on unverified assumptions.
Authors: We will fully specify the conservative trend specification (including functional form and implementation) in the main text and appendix. For the beginner-task measure we will explicitly label it exploratory and note the parallel-trends limitation. We will also report alternative trend specifications (linear, quadratic, and event-study) for the primary inflow and retention outcomes to demonstrate robustness. revision: yes
-
Referee: Subgroup analysis on complexity and participation: The claim that newcomer participation does not decline in fixed-unit subsets where complexity rose (Python cognitive metric; all languages cyclomatic) is load-bearing for the decoupling conclusion, but requires explicit verification that DiD assumptions (e.g., no anticipation, parallel trends in those subsets) hold after the same matching; otherwise the interpretation is undermined by potential selection.
Authors: The subgroups are defined within the already-matched sample. We will add explicit pre-trend and anticipation tests (reporting coefficients on leads) for the complexity-increased subsets on both the cognitive and cyclomatic metrics to verify the DiD assumptions hold post-matching. revision: yes
Circularity Check
No circularity: standard DiD on external observational data
full rationale
The paper's derivation chain consists of identifying adopters via first config-file commit on GitHub, restricting to 603 projects with pre-periods, applying matching, and running difference-in-differences estimators for newcomer inflow, onboarding, retention, and complexity metrics. These steps rely on external data and standard econometric methods with no reduction of results to fitted parameters by construction, no self-definitional relations, and no load-bearing self-citations or imported uniqueness theorems. The analysis is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Difference-in-differences identification assumptions hold, including parallel trends between adopters and matched controls in the pre-adoption period.
Reference graph
Works this paper leans on
-
[1]
H. He, C. Miller, S. Agarwal, C. K ¨astner, and B. Vasilescu, ”Speed at the cost of quality: How Cursor AI increases short-term velocity and long- term complexity in open-source projects,” inProc. 23rd Int. Conf. Min- ing Software Repositories (MSR), 2026, doi: 10.1145/3793302.3793349. arXiv:2511.04427
-
[2]
S. Peng, E. Kalliamvakou, P. Cihon, and M. Demirer, ”The impact of AI on developer productivity: Evidence from GitHub Copilot,” arXiv:2302.06590, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
J. T. Liang, C. Yang, and B. A. Myers, ”A large-scale survey on the usability of AI programming assistants: Successes and challenges,” in Proc. IEEE/ACM 46th Int. Conf. Software Engineering (ICSE), 2024, pp. 616–628
2024
-
[4]
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, et al., ”Evaluating large language models trained on code,” arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Vaithilingam, T
P. Vaithilingam, T. Zhang, and E. L. Glassman, ”Expectation vs. experi- ence: Evaluating the usability of code generation tools powered by large language models,” inExtended Abstracts CHI Conf. Human Factors in Computing Systems (CHI EA), 2022, art. 332, pp. 1–7
2022
-
[6]
Barke, M
S. Barke, M. B. James, and N. Polikarpova, ”Grounded Copilot: How programmers interact with code-generating models,”Proc. ACM Pro- gram. Lang., vol. 7, no. OOPSLA1, pp. 85–111, 2023
2023
-
[7]
Ziegler, E
A. Ziegler, E. Kalliamvakou, X. A. Li, A. Rice, D. Rifkin, S. Simister, et al., ”Productivity assessment of neural code completion,” inProc. 6th ACM SIGPLAN Int. Symp. Machine Programming (MAPS), 2022, pp. 21–29
2022
-
[8]
Moradi Dakhel, V
A. Moradi Dakhel, V . Majdinasab, A. Nikanjam, F. Khomh, M. C. Desmarais, and Z. M. Jiang, ”GitHub Copilot AI pair programmer: Asset or liability?,”J. Syst. Softw., vol. 203, art. 111734, 2023
2023
-
[9]
An empirical evaluation of GitHub Copilot’s code suggestions,
N. Nguyen and S. Nadi, “An empirical evaluation of GitHub Copilot’s code suggestions,” inProc. 19th Int. Conf. Mining Software Repositories (MSR), 2022, pp. 1–5
2022
-
[10]
Asleep at the keyboard? Assessing the security of GitHub Copilot’s code contributions,
H. Pearce, B. Ahmad, B. Tan, B. Dolan-Gavitt, and R. Karri, “Asleep at the keyboard? Assessing the security of GitHub Copilot’s code contributions,” inProc. IEEE Symp. Security and Privacy (SP), 2022, pp. 754–768
2022
-
[11]
Large language models for software engineering: Survey and open problems,
A. Fan, B. Gokkaya, M. Harman, M. Lyubarskiy, S. Sengupta, S. Yoo, and J. M. Zhang, “Large language models for software engineering: Survey and open problems,” inProc. IEEE/ACM Int. Conf. Software Engineering: Future of Software Engineering (ICSE-FoSE), 2023, pp. 31–53
2023
-
[12]
Large language models for software engineering: A systematic literature review,
X. Hou, Y . Zhao, Y . Liu, Z. Yang, K. Wang, L. Li, X. Luo, D. Lo, J. Grundy, and H. Wang, “Large language models for software engineering: A systematic literature review,”ACM Trans. Softw. Eng. Methodol., vol. 33, no. 8, art. 220, pp. 220:1–220:79, 2024
2024
-
[13]
Is GitHub Copilot a substitute for human pair-programming? An empirical study,
S. Imai, “Is GitHub Copilot a substitute for human pair-programming? An empirical study,” inProc. ACM/IEEE 44th Int. Conf. Software Engineering: Companion Proceedings (ICSE-Companion), 2022, pp. 319–321
2022
-
[14]
A complexity measure,
T. J. McCabe, “A complexity measure,”IEEE Trans. Softw. Eng., vol. SE-2, no. 4, pp. 308–320, Dec. 1976
1976
-
[15]
Cognitive complexity: An overview and evaluation,
G. A. Campbell, “Cognitive complexity: An overview and evaluation,” inProc. Int. Conf. Technical Debt (TechDebt), 2018, pp. 57–58
2018
-
[16]
Cyclomatic complexity,
C. Ebert, J. Cain, G. Antoniol, S. Counsell, and P. Laplante, “Cyclomatic complexity,”IEEE Softw., vol. 33, no. 6, pp. 27–29, 2016
2016
-
[17]
Social barriers faced by newcomers placing their first contribution in open source software projects,
I. Steinmacher, T. U. Conte, M. A. Gerosa, and D. Redmiles, “Social barriers faced by newcomers placing their first contribution in open source software projects,” inProc. 18th ACM Conf. Computer Supported Cooperative Work & Social Computing (CSCW), 2015, pp. 1379–1392
2015
-
[18]
A systematic literature review on the barriers faced by newcomers to open source software projects,
I. Steinmacher, M. A. G. Silva, M. A. Gerosa, and D. F. Redmiles, “A systematic literature review on the barriers faced by newcomers to open source software projects,”Information and Software Technology, vol. 59, pp. 67–85, 2015
2015
-
[19]
Overcoming open source project entry barriers with a portal for newcomers,
I. Steinmacher, T. U. Conte, C. Treude, and M. A. Gerosa, “Overcoming open source project entry barriers with a portal for newcomers,” inProc. 38th Int. Conf. Software Engineering (ICSE), 2016, pp. 273–284
2016
-
[20]
Community, joining, and specialization in open source software innovation: a case study,
G. von Krogh, S. Spaeth, and K. R. Lakhani, “Community, joining, and specialization in open source software innovation: a case study,” Research Policy, vol. 32, no. 7, pp. 1217–1241, 2003
2003
-
[21]
Socialization in an open source software community: a socio-technical analysis,
N. Ducheneaut, “Socialization in an open source software community: a socio-technical analysis,”Computer Supported Cooperative Work (CSCW), vol. 14, no. 4, pp. 323–368, 2005
2005
-
[22]
The role of mentoring and project characteristics for onboarding in open source soft- ware projects,
F. Fagerholm, A. S. Guinea, J. M ¨unch, and J. Borenstein, “The role of mentoring and project characteristics for onboarding in open source soft- ware projects,” inProc. 8th ACM/IEEE Int. Symp. Empirical Software Engineering and Measurement (ESEM), 2014, Art. no. 55, pp. 1–10
2014
-
[23]
Newcomers’ barriers... is that all? An analysis of mentors’ and new- comers’ barriers in OSS projects,
S. Balali, I. Steinmacher, U. Annamalai, A. Sarma, and M. A. Gerosa, “Newcomers’ barriers... is that all? An analysis of mentors’ and new- comers’ barriers in OSS projects,”Computer Supported Cooperative Work (CSCW), vol. 27, no. 3, pp. 679–714, 2018
2018
-
[24]
Joining free/open source software communities: an analysis of newbies’ first interactions on project mailing lists,
C. Jensen, S. King, and V . Kuechler, “Joining free/open source software communities: an analysis of newbies’ first interactions on project mailing lists,” inProc. 44th Hawaii Int. Conf. System Sciences (HICSS), 2011, pp. 1–10
2011
-
[25]
How Early Participa- tion Determines Long-Term Sustained Activity in GitHub Projects?,
W. Xiao, H. He, W. Xu, Y . Zhang, and M. Zhou, “How Early Participa- tion Determines Long-Term Sustained Activity in GitHub Projects?,” in Proc. 31st ACM Joint Eur. Softw. Eng. Conf. Symp. Found. Softw. Eng. (ESEC/FSE), 2023, pp. 29–41, doi: 10.1145/3611643.3616349
-
[26]
The First Issue Matters: Linking Task-Level Characteristics to Long-Term Newcomer Retention in OSS,
Y . Hao, W. Xu, K. Gao, and X. Zhang, “The First Issue Matters: Linking Task-Level Characteristics to Long-Term Newcomer Retention in OSS,” arXiv preprintarXiv:2603.27136, 2026
-
[27]
Who Will Stay in the FLOSS Community? Modeling Participant’s Initial Behavior,
M. Zhou and A. Mockus, “Who Will Stay in the FLOSS Community? Modeling Participant’s Initial Behavior,”IEEE Trans. Softw. Eng., vol. 41, no. 1, pp. 82–99, Jan. 2015, doi: 10.1109/TSE.2014.2349496
-
[28]
Does the Initial Environment Impact the Future of Developers?,
M. Zhou and A. Mockus, “Does the Initial Environment Impact the Future of Developers?,” inProc. 33rd Int. Conf. Softw. Eng. (ICSE), 2011, pp. 271–280, doi: 10.1145/1985793.1985831
-
[29]
Going Farther Together: The Impact of Social Capital on Sustained Participation in Open Source,
H. S. Qiu, A. Nolte, A. Brown, A. Serebrenik, and B. Vasilescu, “Going Farther Together: The Impact of Social Capital on Sustained Participation in Open Source,” inProc. IEEE/ACM 41st Int. Conf. Softw. Eng. (ICSE), 2019, pp. 688–699, doi: 10.1109/ICSE.2019.00078
-
[30]
Will You Come Back to Contribute? Investigating the Inactivity of OSS Core Developers in GitHub,
F. Calefato, M. A. Gerosa, G. Iaffaldano, F. Lanubile, and I. Steinmacher, “Will You Come Back to Contribute? Investigating the Inactivity of OSS Core Developers in GitHub,”Empir. Softw. Eng., vol. 27, no. 3, art. no. 76, 2022, doi: 10.1007/s10664-021-10012-6
-
[31]
A First Look at Good First Is- sues on GitHub,
X. Tan, M. Zhou, and Z. Sun, “A First Look at Good First Is- sues on GitHub,” inProc. 28th ACM Joint Meet. Eur. Softw. Eng. Conf. Symp. Found. Softw. Eng. (ESEC/FSE), 2020, pp. 398–409, doi: 10.1145/3368089.3409746
-
[32]
Rec- ommending Good First Issues in GitHub OSS Projects,
W. Xiao, H. He, W. Xu, X. Tan, J. Dong, and M. Zhou, “Rec- ommending Good First Issues in GitHub OSS Projects,” inProc. IEEE/ACM 44th Int. Conf. Softw. Eng. (ICSE), 2022, pp. 1830–1842, doi: 10.1145/3510003.3510196
-
[33]
Magnet or sticky? An OSS project-by-project typology,
K. Yamashita, S. McIntosh, Y . Kamei, and N. Ubayashi, “Magnet or sticky? An OSS project-by-project typology,” inProc. 11th Working Conf. Mining Software Repositories (MSR), 2014, pp. 344–347
2014
-
[34]
Developer turnover in global, in- dustrial open source projects: Insights from applying survival analysis,
B. Lin, G. Robles, and A. Serebrenik, “Developer turnover in global, in- dustrial open source projects: Insights from applying survival analysis,” inProc. 12th IEEE Int. Conf. Global Software Engineering (ICGSE), 2017, pp. 66–75
2017
-
[35]
Why modern open source projects fail,
J. Coelho and M. T. Valente, “Why modern open source projects fail,” inProc. 11th Joint Meeting Foundations of Software Engineering (ESEC/FSE), 2017, pp. 186–196
2017
-
[36]
On the abandonment and survival of open source projects: An empirical investi- gation,
G. Avelino, E. Constantinou, M. T. Valente, and A. Serebrenik, “On the abandonment and survival of open source projects: An empirical investi- gation,” inProc. ACM/IEEE Int. Symp. Empirical Software Engineering and Measurement (ESEM), 2019, pp. 1–12
2019
-
[37]
Ecosystem-level determinants of sustained activity in open-source projects: A case study of the PyPI ecosystem,
M. Valiev, B. Vasilescu, and J. Herbsleb, “Ecosystem-level determinants of sustained activity in open-source projects: A case study of the PyPI ecosystem,” inProc. 26th ACM Joint Meeting European Software Engineering Conf. and Symp. Foundations of Software Engineering (ESEC/FSE), 2018, pp. 644–655
2018
-
[38]
Impact of developer turnover on quality in open-source software,
M. Foucault, M. Palyart, X. Blanc, G. C. Murphy, and J.-R. Falleri, “Impact of developer turnover on quality in open-source software,” inProc. 10th Joint Meeting Foundations of Software Engineering (ESEC/FSE), 2015, pp. 829–841
2015
-
[39]
Two case studies of open source software development: Apache and Mozilla,
A. Mockus, R. T. Fielding, and J. D. Herbsleb, “Two case studies of open source software development: Apache and Mozilla,”ACM Trans. Softw. Eng. Methodol., vol. 11, no. 3, pp. 309–346, 2002
2002
-
[40]
An empirical comparison of developer retention in the RubyGems and npm software ecosystems,
E. Constantinou and T. Mens, “An empirical comparison of developer retention in the RubyGems and npm software ecosystems,”Innov. Syst. Softw. Eng., vol. 13, no. 2, pp. 101–115, 2017
2017
-
[41]
Revisiting event-study designs: Robust and efficient estimation,
K. Borusyak, X. Jaravel, and J. Spiess, “Revisiting event-study designs: Robust and efficient estimation,”Rev. Econ. Stud., vol. 91, no. 6, pp. 3253–3285, 2024
2024
-
[42]
Difference-in-differences with multiple time periods,
B. Callaway and P. H. C. Sant’Anna, “Difference-in-differences with multiple time periods,”J. Econometrics, vol. 225, no. 2, pp. 200–230, 2021
2021
-
[43]
Estimating dynamic treatment effects in event studies with heterogeneous treatment effects,
L. Sun and S. Abraham, “Estimating dynamic treatment effects in event studies with heterogeneous treatment effects,”J. Econometrics, vol. 225, no. 2, pp. 175–199, 2021
2021
-
[44]
Difference-in-differences with variation in treat- ment timing,
A. Goodman-Bacon, “Difference-in-differences with variation in treat- ment timing,”J. Econometrics, vol. 225, no. 2, pp. 254–277, 2021
2021
-
[45]
Two-way fixed effects estimators with heterogeneous treatment effects,
C. de Chaisemartin and X. D’Haultf ¨oeuille, “Two-way fixed effects estimators with heterogeneous treatment effects,”Amer. Econ. Rev., vol. 110, no. 9, pp. 2964–2996, 2020
2020
-
[46]
A more credible approach to parallel trends,
A. Rambachan and J. Roth, “A more credible approach to parallel trends,”Rev. Econ. Stud., vol. 90, no. 5, pp. 2555–2591, 2023
2023
-
[47]
What’s trending in difference-in-differences? A synthesis of the recent econometrics literature,
J. Roth, P. H. C. Sant’Anna, A. Bilinski, and J. Poe, “What’s trending in difference-in-differences? A synthesis of the recent econometrics literature,”J. Econometrics, vol. 235, no. 2, pp. 2218–2244, 2023
2023
-
[48]
The state of applied econometrics: Causality and policy evaluation,
S. Athey and G. W. Imbens, “The state of applied econometrics: Causality and policy evaluation,”J. Econ. Perspect., vol. 31, no. 2, pp. 3–32, 2017
2017
-
[49]
An introduction to propensity score methods for reduc- ing the effects of confounding in observational studies,
P. C. Austin, “An introduction to propensity score methods for reduc- ing the effects of confounding in observational studies,”Multivariate Behavioral Research, vol. 46, no. 3, pp. 399–424, 2011
2011
-
[50]
Matching methods for causal inference: A review and a look forward,
E. A. Stuart, “Matching methods for causal inference: A review and a look forward,”Statistical Science, vol. 25, no. 1, pp. 1–21, 2010
2010
-
[51]
The promises and perils of mining GitHub,
E. Kalliamvakou, G. Gousios, K. Blincoe, L. Singer, D. M. German, and D. Damian, “The promises and perils of mining GitHub,” inProc. 11th Working Conf. Mining Softw. Repositories (MSR), 2014, pp. 92–101
2014
-
[52]
The GHTorrent dataset and tool suite,
G. Gousios, “The GHTorrent dataset and tool suite,” inProc. 10th Working Conf. Mining Softw. Repositories (MSR), 2013, pp. 233–236
2013
-
[53]
Social coding in GitHub: Transparency and collaboration in an open software repository,
L. Dabbish, C. Stuart, J. Tsay, and J. Herbsleb, “Social coding in GitHub: Transparency and collaboration in an open software repository,” inProc. ACM Conf. Computer Supported Cooperative Work (CSCW), 2012, pp. 1277–1286
2012
-
[54]
Influence of social and technical factors for evaluating contribution in GitHub,
J. Tsay, L. Dabbish, and J. Herbsleb, “Influence of social and technical factors for evaluating contribution in GitHub,” inProc. 36th Int. Conf. Softw. Eng. (ICSE), 2014, pp. 356–366
2014
-
[55]
An exploratory study of the pull-based software development model,
G. Gousios, M. Pinzger, and A. van Deursen, “An exploratory study of the pull-based software development model,” inProc. 36th Int. Conf. Softw. Eng. (ICSE), 2014, pp. 345–355
2014
-
[56]
Vasilescu, Y
B. Vasilescu, Y . Yu, H. Wang, P. Devanbu, and V . Filkov, ”Quality and productivity outcomes relating to continuous integration in GitHub,” in Proc. 2015 10th Joint Meeting Found. Softw. Eng. (ESEC/FSE), 2015, pp. 805–816
2015
-
[57]
Terrell, A
J. Terrell, A. Kofink, J. Middleton, C. Rainear, E. Murphy-Hill, C. Parnin, and J. Stallings, ”Gender differences and bias in open source: pull request acceptance of women versus men,” PeerJ Comput. Sci., vol. 3, p. e111, 2017
2017
-
[58]
Vasilescu, D
B. Vasilescu, D. Posnett, B. Ray, M. G. J. van den Brand, A. Serebrenik, P. Devanbu, and V . Filkov, ”Gender and tenure diversity in GitHub teams,” in Proc. 33rd Annu. ACM Conf. Human Factors Comput. Syst. (CHI), 2015, pp. 3789–3798
2015
-
[59]
Casalnuovo, B
C. Casalnuovo, B. Vasilescu, P. Devanbu, and V . Filkov, ”Developer onboarding in GitHub: the role of prior social links and language experience,” in Proc. 2015 10th Joint Meeting Found. Softw. Eng. (ESEC/FSE), 2015, pp. 817–828
2015
-
[60]
Rastogi, N
A. Rastogi, N. Nagappan, G. Gousios, and A. van der Hoek, ”Re- lationship between geographical location and evaluation of developer contributions in GitHub,” in Proc. 12th ACM/IEEE Int. Symp. Empirical Softw. Eng. Meas. (ESEM), 2018, pp. 1–8, Art. no. 22
2018
-
[61]
Midha and P
V . Midha and P. Palvia, ”Factors affecting the success of Open Source Software,” J. Syst. Softw., vol. 85, no. 4, pp. 895–905, 2012
2012
-
[62]
M. Zhou, A. Mockus, X. Ma, L. Zhang, and H. Mei, ”Inflow and retention in OSS communities with commercial involvement: A case study of three hybrid projects,” ACM Trans. Softw. Eng. Methodol., vol. 25, no. 2, pp. 1–29, Art. no. 13, 2016
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.