Hidden Consensus:Preference-Validity Compression in Human Feedback
Pith reviewed 2026-06-27 13:23 UTC · model grok-4.3
The pith
RLHF preference aggregation discards multiple majority-supported responses in 79% of cases, measuring argmax rather than plural alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
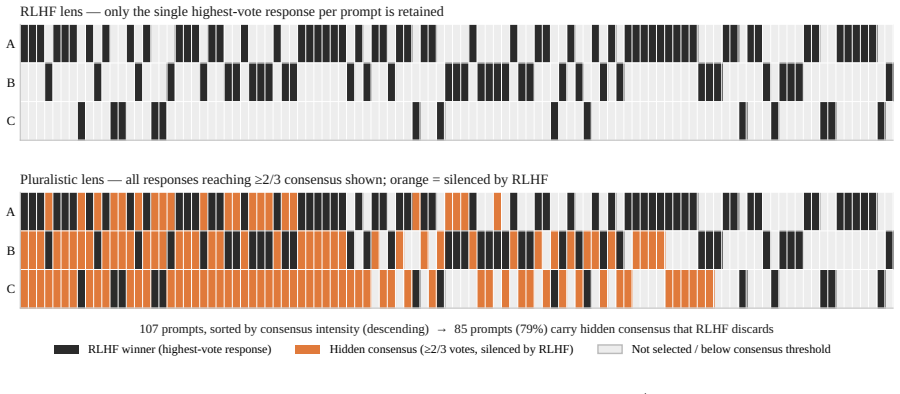
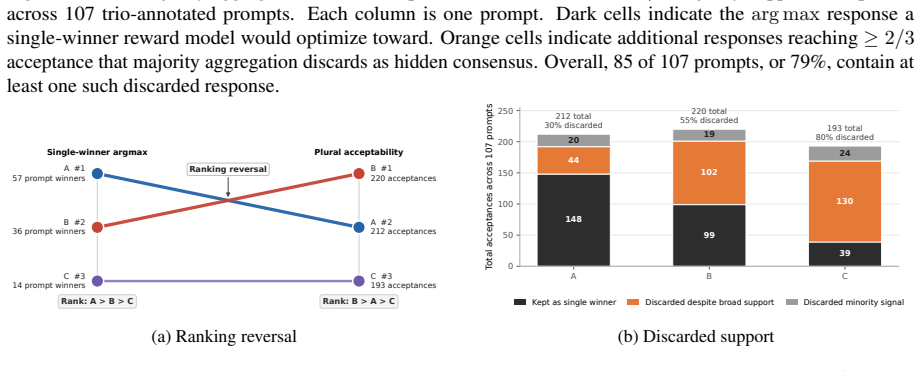
The central claim is that RLHF-style feedback aggregation exhibits Preference-Validity Compression: across 321 preference events, 79% of the 107 prompts contain more than one majority-supported response that single-winner aggregation discards, and apparent dominance gaps diminish when all majority-supported options are considered. Discarded responses reflect coherent local, practical, or cultural interpretive frames rather than noise. Majority aggregation therefore measures argmax acceptability rather than plural alignment, and alignment methods should instead satisfy Validity-Preserving Consistency by remaining stable across plural-valid frames.
What carries the argument
Preference-Validity Compression, the collapse of multiple plural-valid response options into a single optimization target.
If this is right
- Majority aggregation in this corpus measures argmax acceptability rather than plural alignment.
- Apparent dominance gaps between top responses diminish when all majority-supported options are retained.
- Future alignment methods must satisfy Validity-Preserving Consistency by remaining stable across plural-valid interpretive frames rather than collapsing them into one reward target.
Where Pith is reading between the lines
- If the pattern generalizes, models trained on single-winner rewards may systematically under-represent valid responses in culturally diverse user populations.
- Multi-winner aggregation or frame-aware reward modeling could be tested as direct alternatives on the same 107 prompts to quantify changes in downstream model behavior.
Load-bearing premise
The multiple acceptable responses selected by participants reflect coherent local, practical, or cultural interpretive frames rather than annotation inconsistency or noise.
What would settle it
Re-annotating the same 107 prompts with a fresh group of 20 participants from comparable backgrounds and finding that the share of prompts with multiple majority-supported responses falls well below 79%.
Figures





read the original abstract
Standard RLHF pipelines often reduce heterogeneous human judgments into a single scalar reward target. We argue that this reduction can mis-measure alignment in structurally plural societies, where disagreement may reflect culturally, historically, linguistically, regionally, or normatively grounded interpretations rather than annotation noise. We call this failure Preference-Validity Compression, the collapse of multiple plural-valid response options into a single optimization target. Using Malaysia as a diagnostic setting, we analyze RLHF-style feedback aggregation through preference events linking prompts, responses, and acceptability judgments across interpretive frames. Across 321 preference events from 20 participants and 107 trio-annotated prompts, 79% of prompts contain more than one majority-supported response that single-winner aggregation would discard, and apparent dominance gaps between top responses diminish when all majority-supported options are considered. Participants frequently select multiple acceptable responses, and discarded responses demonstrably reflect coherent local, practical, or cultural frames. These findings show that majority aggregation in this corpus measures argmax acceptability rather than plural alignment. We treat this as a measurement-validity issue and argue that future alignment methods should satisfy Validity-Preserving Consistency, remaining stable across plural-valid interpretive frames rather than collapsing them into a single reward target.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that RLHF-style single-winner aggregation in preference data performs Preference-Validity Compression by collapsing multiple plural-valid responses (grounded in cultural, practical, or interpretive frames) into one optimization target. In a Malaysia diagnostic corpus of 321 events from 20 participants across 107 trio-annotated prompts, 79% of prompts exhibit more than one majority-supported response that would be discarded by argmax aggregation; dominance gaps shrink when all majority-supported options are retained. The work concludes that majority aggregation measures argmax acceptability rather than plural alignment and advocates Validity-Preserving Consistency for future methods.
Significance. If the empirical pattern and its coherence interpretation hold, the result identifies a measurement-validity limitation in current RLHF pipelines when applied to structurally plural settings, with direct implications for reward modeling and alignment objectives that aim to remain stable across multiple valid frames rather than forcing a single scalar target.
major comments (3)
- [Abstract / Results] Abstract and results section: the headline statistic (79% of 107 prompts contain >1 majority-supported response) is presented as evidence that single-winner aggregation discards plural-valid options, yet the manuscript provides no quantitative checks (e.g., intra-participant consistency rates, inter-annotator agreement on acceptability, or controls for order effects) to distinguish coherent interpretive frames from annotation inconsistency or noise; without these, the mapping from raw counts to the 'coherent local, practical, or cultural frames' claim remains unsupported.
- [Methods] Methods description (implied in abstract): participant recruitment, prompt selection criteria, definition of 'majority-supported,' and any statistical tests for the 79% figure are not reported, preventing assessment of whether the observed multiplicity reflects stable plural validity or sampling artifacts.
- [Abstract / Discussion] The central interpretive step—that discarded responses 'demonstrably reflect coherent' frames—is load-bearing for the Preference-Validity Compression diagnosis and the call for Validity-Preserving Consistency, but the provided evidence is limited to the raw event counts without qualitative coding, frame identification, or falsification tests against the noise hypothesis.
minor comments (2)
- [Methods] Clarify the exact definition and operationalization of 'majority-supported response' and 'trio-annotated prompts' to allow replication.
- [Introduction] The term 'Preference-Validity Compression' is introduced without comparison to related concepts in preference aggregation or multi-winner voting literature; a brief positioning would strengthen the contribution.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments, which highlight opportunities to strengthen the methodological transparency and evidential support in our manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results section: the headline statistic (79% of 107 prompts contain >1 majority-supported response) is presented as evidence that single-winner aggregation discards plural-valid options, yet the manuscript provides no quantitative checks (e.g., intra-participant consistency rates, inter-annotator agreement on acceptability, or controls for order effects) to distinguish coherent interpretive frames from annotation inconsistency or noise; without these, the mapping from raw counts to the 'coherent local, practical, or cultural frames' claim remains unsupported.
Authors: We agree that explicit checks are required to differentiate stable plural validity from noise or inconsistency. The current draft emphasizes the aggregate 79% count derived from majority thresholds, but the data collection protocol included repeated annotations per participant. In revision we will add intra-participant consistency rates (proportion of prompts on which individual annotators maintain the same acceptability judgments) and inter-annotator agreement (Fleiss' kappa on acceptability labels). Response trios were presented in randomized order to mitigate order effects. These additions will provide quantitative grounding for the coherence interpretation. revision: yes
-
Referee: [Methods] Methods description (implied in abstract): participant recruitment, prompt selection criteria, definition of 'majority-supported,' and any statistical tests for the 79% figure are not reported, preventing assessment of whether the observed multiplicity reflects stable plural validity or sampling artifacts.
Authors: The full manuscript contains a Methods section, yet we acknowledge it is insufficiently detailed in the submitted version. We will expand it to report: recruitment of 20 Malaysian participants via local university and community networks with attention to demographic diversity; prompt selection focused on everyday scenarios chosen for potential cultural or practical interpretive variation; the operational definition of majority-supported (accepted by more than 50% of the 20 annotators); and a direct count for the 79% figure together with a binomial proportion confidence interval to evaluate deviation from chance. This expansion will allow readers to assess sampling and stability concerns. revision: yes
-
Referee: [Abstract / Discussion] The central interpretive step—that discarded responses 'demonstrably reflect coherent' frames—is load-bearing for the Preference-Validity Compression diagnosis and the call for Validity-Preserving Consistency, but the provided evidence is limited to the raw event counts without qualitative coding, frame identification, or falsification tests against the noise hypothesis.
Authors: The interpretive claim rests on the observed multiplicity combined with the study context, but we recognize that raw counts alone leave the coherence assertion under-supported. In the revised manuscript we will add a qualitative analysis subsection that codes representative discarded responses for distinct local, practical, or cultural frames, together with falsification checks (e.g., comparison of within-frame versus across-frame consistency). These elements will make the mapping from counts to coherent frames explicit and testable. revision: yes
Circularity Check
No circularity: central claims are direct empirical counts with no derivations or self-referential reductions
full rationale
The paper presents an empirical analysis of 321 preference events across 107 prompts, reporting the 79% statistic as a direct count of majority-supported responses. No equations, fitted parameters, predictions, or derivation chains appear in the provided text. The interpretation that discarded responses reflect coherent frames is stated as demonstrated by the data rather than derived from prior self-citations or ansatzes. This matches the default expectation of no significant circularity for a data-driven observation paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Disagreement among participants reflects culturally, historically, linguistically, regionally, or normatively grounded interpretations rather than annotation noise.
invented entities (1)
-
Preference-Validity Compression
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in neural information processing systems , volume=
-
[2]
arXiv preprint arXiv:2405.00254 , year=
Rlhf from heterogeneous feedback via personalization and preference aggregation , author=. arXiv preprint arXiv:2405.00254 , year=
-
[3]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[4]
AI magazine , volume=
Truth is a lie: Crowd truth and the seven myths of human annotation , author=. AI magazine , volume=
-
[5]
Proceedings of the 1st workshop on benchmarking: past, present and future , pages=
We need to consider disagreement in evaluation , author=. Proceedings of the 1st workshop on benchmarking: past, present and future , pages=
-
[6]
arXiv preprint arXiv:2402.08925 , year=
Maxmin-rlhf: Alignment with diverse human preferences , author=. arXiv preprint arXiv:2402.08925 , year=
-
[7]
Proceedings of the joint 15th linguistic annotation workshop (LAW) and 3rd designing meaning representations (DMR) workshop , pages=
On releasing annotator-level labels and information in datasets , author=. Proceedings of the joint 15th linguistic annotation workshop (LAW) and 3rd designing meaning representations (DMR) workshop , pages=
-
[8]
arXiv preprint arXiv:2406.08469 , year=
Pal: Pluralistic alignment framework for learning from heterogeneous preferences , author=. arXiv preprint arXiv:2406.08469 , year=
-
[9]
Advances in Neural Information Processing Systems , volume=
The PRISM alignment dataset: What participatory, representative and individualised human feedback reveals about the subjective and multicultural alignment of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Operationalizing pluralistic values in large language model alignment reveals trade-offs in safety, inclusivity, and model behavior , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[11]
arXiv preprint arXiv:2404.10271 , year=
Social choice should guide ai alignment in dealing with diverse human feedback , author=. arXiv preprint arXiv:2404.10271 , year=
-
[12]
Proceedings of the 41st International Conference on Machine Learning , pages=
Position: a roadmap to pluralistic alignment , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[13]
arXiv preprint arXiv:2307.15217 , year=
Open problems and fundamental limitations of reinforcement learning from human feedback , author=. arXiv preprint arXiv:2307.15217 , year=
-
[14]
International conference on machine learning , pages=
Whose opinions do language models reflect? , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[15]
Behavioral and brain sciences , volume=
The weirdest people in the world? , author=. Behavioral and brain sciences , volume=. 2010 , publisher=
2010
-
[16]
Proceedings of the AAAI conference on artificial intelligence , volume=
Why AI Is WEIRD and shouldn't be this way: towards AI for everyone, with everyone, by everyone , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[17]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Not all countries celebrate thanksgiving: On the cultural dominance in large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[18]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
MalayMMLU: A multitask benchmark for the low-resource Malay language , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[19]
arXiv preprint arXiv:2508.05429 , year=
MyCulture: Exploring Malaysia's Diverse Culture under Low-Resource Language Constraints , author=. arXiv preprint arXiv:2508.05429 , year=
-
[20]
2026 , note=
Demographic Statistics Malaysia, First Quarter 2026 , author=. 2026 , note=
2026
-
[21]
Sociological forum , volume=
The making of race in colonial Malaya: Political economy and racial ideology , author=. Sociological forum , volume=. 1986 , organization=
1986
-
[22]
Transforming Malaysia: Dominant and competing paradigms , pages=
Race paradigm and nation-building in Malaysia , author=. Transforming Malaysia: Dominant and competing paradigms , pages=. 2014 , publisher=
2014
-
[23]
Japanese Journal of Southeast Asian Studies , volume=
Debating about identity in Malaysia: A discourse analysis , author=. Japanese Journal of Southeast Asian Studies , volume=. 1996 , publisher=
1996
-
[24]
Readings on Development: Malaysia , volume=
Managing a Stable Tension: Ethnic Relations in Malaysia Reexamined , author=. Readings on Development: Malaysia , volume=
-
[25]
2024 , note=
National Youth Survey 2024 , author=. 2024 , note=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.