Notation Matters: A Benchmark Study of Token-Optimized Formats in Agentic AI Systems
Pith reviewed 2026-06-29 07:10 UTC · model grok-4.3
The pith
TRON reduces tokens by up to 27% in agentic tool use while staying within 14 points of JSON accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
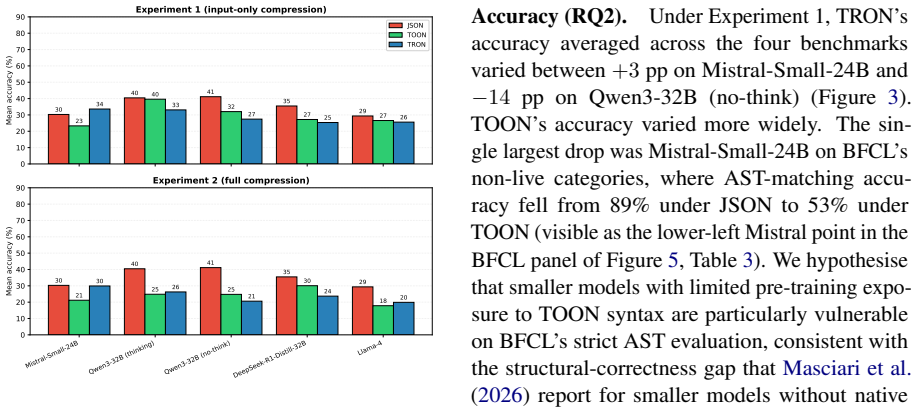
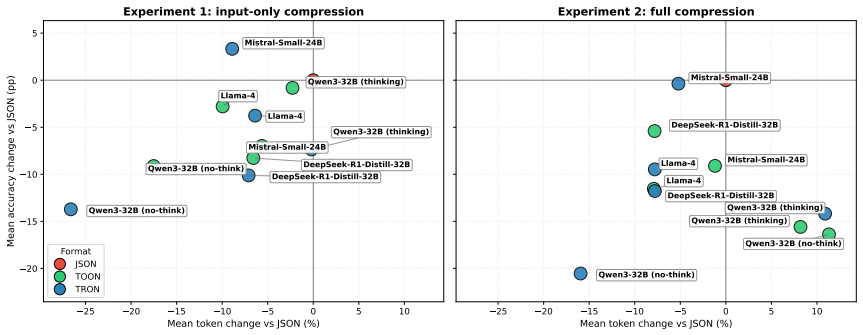
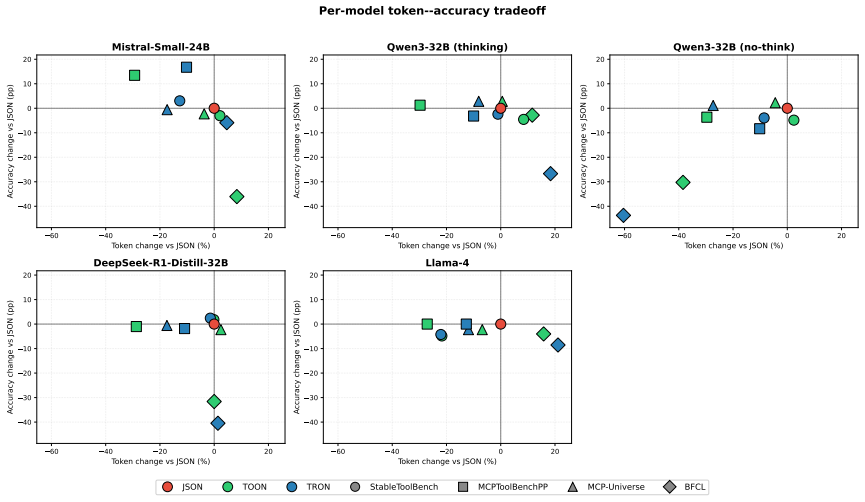
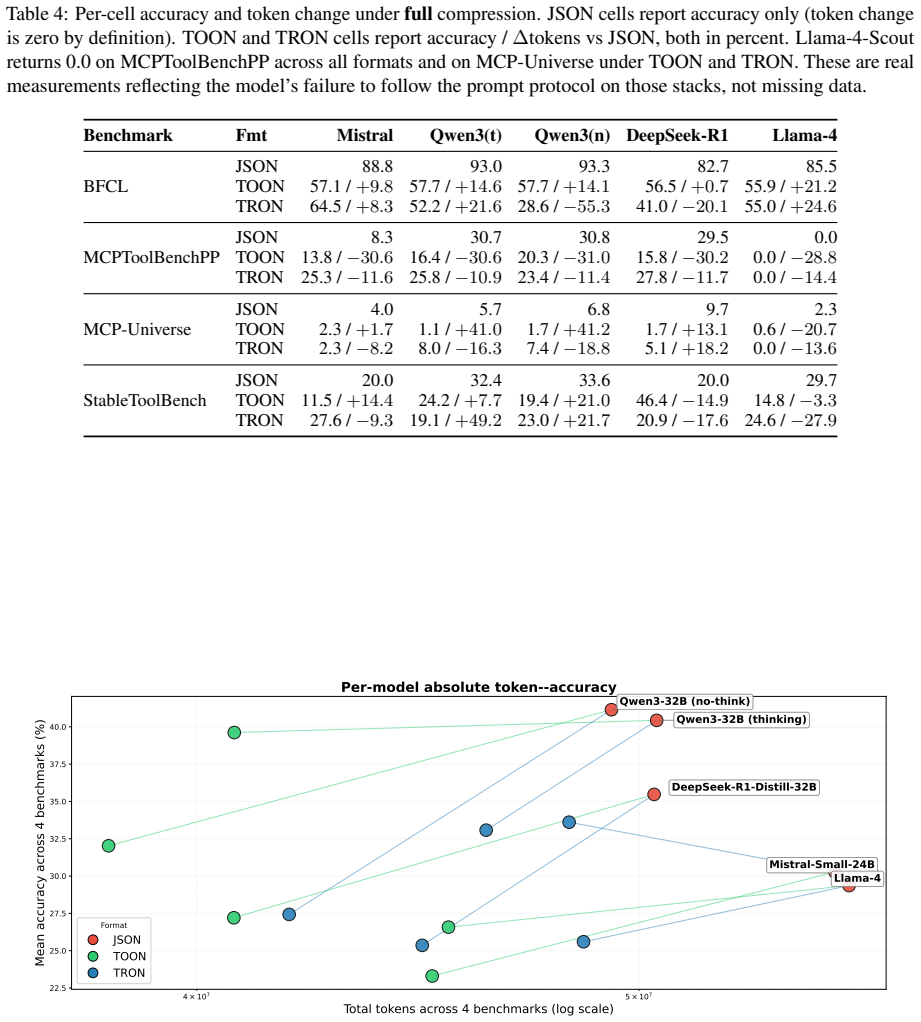
TRON reduces tokens by up to 27% with accuracy within 14 percentage points of the JSON baseline across the four agentic benchmarks. TOON reaches up to 18% token reduction at a similar accuracy cost yet additionally produces cascading multi-turn parsing failures and collapses parallel tool-call output for most models tested.
What carries the argument
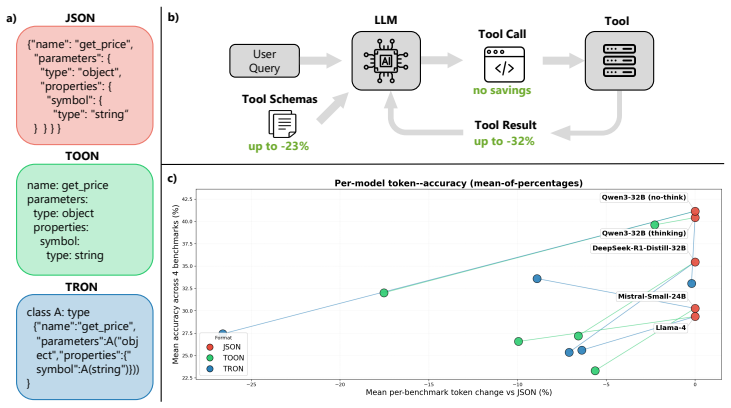
Decoupled measurement of input compression versus output compression on agentic benchmarks, applied to TOON and TRON as compact object notations.
If this is right
- Agent frameworks could adopt TRON for tool schemas and results to lower token budgets while preserving most task success.
- TOON would require additional safeguards against multi-turn parsing drift before it can replace JSON in chained agent workflows.
- Parallel tool-call generation must be re-tested when switching notations because TOON breaks it for most models.
- Token savings appear in both comprehension and generation stages, so the formats can be applied independently to input and output sides.
Where Pith is reading between the lines
- If the pattern holds on proprietary models, production agents might default to TRON for cost-sensitive tool loops.
- The multi-turn failure mode in TOON suggests that future benchmarks should track cumulative error over conversation length rather than single turns.
- Notation choice could interact with model scale; larger models might absorb the accuracy cost more easily than the five tested here.
Load-bearing premise
The four chosen benchmarks and five open-weight models are representative enough that the measured token and accuracy differences will hold in other real-world agent loops.
What would settle it
Re-running the identical benchmarks on closed-source models or on longer-horizon tasks and observing token savings fall below 10% or accuracy gaps exceed 20 points would falsify the reported reductions.
Figures
read the original abstract
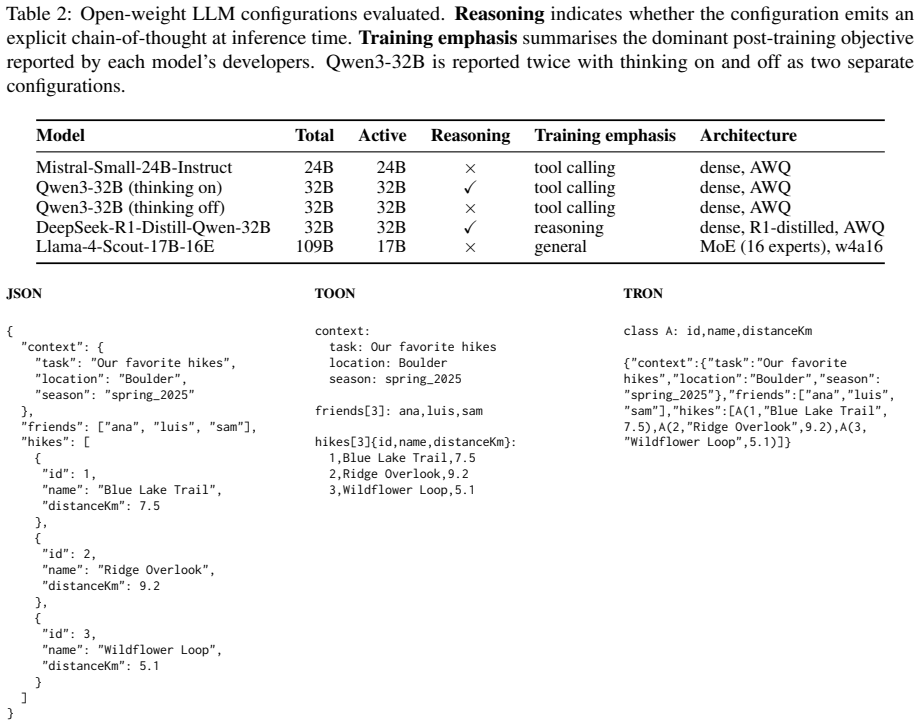
Large language models in Agentic AI systems consume tool schemas and execution results and emit tool invocations as structured data. The default language for that exchange, JSON, was designed for application-to-application interchange rather than token efficiency, so its structural elements impose substantial token overhead. Recent work proposes token-optimized alternatives such as TOON (Token-Oriented Object Notation) and TRON (Token Reduced Object Notation) as more compact replacements, but these formats have been evaluated only on isolated comprehension or generation tasks. Whether their token reductions hold inside end-to-end agentic loops therefore remains an open question. We evaluate TOON and TRON on four agentic benchmarks (BFCL, MCPToolBenchPP, MCP-Universe, StableToolBench) and five open-weight LLMs, decoupling input compression from output compression to measure comprehension and generation independently. TRON reduces tokens by up to 27% with accuracy within 14pp of the JSON baseline. TOON achieves up to 18% reduction at a similar 9pp accuracy cost, but additionally cascades on multi-turn parsing failures and collapses parallel tool-call output for most models. The code is available at: https://github.com/lkutschka/notation-matters
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates whether token-optimized notations TOON and TRON preserve their reported efficiency gains when used inside full agentic loops rather than isolated tasks. On four benchmarks (BFCL, MCPToolBenchPP, MCP-Universe, StableToolBench) and five open-weight LLMs it decouples input and output compression and reports that TRON cuts tokens by up to 27 % while keeping accuracy within 14 pp of the JSON baseline; TOON cuts up to 18 % at a 9 pp accuracy cost but additionally triggers multi-turn parsing cascades and collapses parallel tool-call output for most models. Reproducible code is released.
Significance. If the measured deltas generalize, the study supplies the first end-to-end evidence that compact notations can be substituted for JSON in agentic pipelines without catastrophic accuracy loss, together with an open implementation that supports direct replication and extension.
major comments (2)
- [Experimental Setup] Experimental Setup (abstract and benchmark description): the claim that the observed token reductions 'hold inside end-to-end agentic loops' rests on the unexamined assumption that the four selected benchmarks adequately sample tool-schema complexity, multi-turn dynamics, parallel calls, and tokenizer behavior; the abstract itself flags TOON's sensitivity to interaction style, yet no diversity analysis or coverage argument is supplied.
- [Results] Results and Methods: accuracy deltas are stated as 'within 14 pp' and 'within 9 pp' without reported variance, confidence intervals, or statistical tests across the five models or repeated runs, so it is impossible to judge whether the observed differences are distinguishable from noise.
minor comments (1)
- The GitHub link is given but the manuscript does not state the exact commit or tag used for the reported numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the experimental setup and statistical presentation. We address each major comment below and outline the revisions we will incorporate.
read point-by-point responses
-
Referee: [Experimental Setup] Experimental Setup (abstract and benchmark description): the claim that the observed token reductions 'hold inside end-to-end agentic loops' rests on the unexamined assumption that the four selected benchmarks adequately sample tool-schema complexity, multi-turn dynamics, parallel calls, and tokenizer behavior; the abstract itself flags TOON's sensitivity to interaction style, yet no diversity analysis or coverage argument is supplied.
Authors: We agree that an explicit coverage argument strengthens the justification. The four benchmarks were selected as established suites in the agentic tool-use literature. In the revision we will add a dedicated paragraph to Section 3 (Experimental Setup) that maps each benchmark to the dimensions of schema complexity, multi-turn dynamics, parallel calls, and tokenizer behavior, thereby supplying the requested diversity analysis. revision: partial
-
Referee: [Results] Results and Methods: accuracy deltas are stated as 'within 14 pp' and 'within 9 pp' without reported variance, confidence intervals, or statistical tests across the five models or repeated runs, so it is impossible to judge whether the observed differences are distinguishable from noise.
Authors: We accept that variance reporting improves interpretability. The revised manuscript will include mean accuracy and standard deviation across the five models for each notation-benchmark pair and will note the consistency of the deltas. Because the original runs were not repeated with multiple random seeds, we cannot supply confidence intervals derived from repeated trials; we will state this limitation explicitly. revision: partial
Circularity Check
Empirical benchmark measurements with no derivation chain or self-referential reductions
full rationale
The paper consists entirely of direct empirical measurements of token counts and task accuracy for JSON, TOON, and TRON on four public benchmarks across five LLMs. No equations, fitted parameters, uniqueness theorems, or ansatzes are present; the reported deltas (e.g., up to 27% token reduction) are computed from raw tokenizer outputs and benchmark scores rather than being derived from or equivalent to any inputs by construction. Self-citations to prior format proposals are incidental background and do not bear the load of the central claims, which rest on reproducible benchmark runs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ONTO: A Token-Efficient Columnar Notation for LLM Input Optimization
ONTO: A token- efficient columnar notation for LLM input optimiza- tion. (arXiv:2604.17512). ArXiv:2604.17512 [cs]. 10 DeepSeek-AI
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
DeepSeek-V3 technical report. arXiv preprint arXiv:2412.19437. Shiqing Fan, Xichen Ding, Liang Zhang, and Linjian Mo
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
arXiv preprint arXiv:2508.07575
MCPToolBench++: A large scale ai agent model context protocol MCP tool use benchmark. arXiv preprint arXiv:2508.07575. Zhicheng Guo, Sijie Cheng, Hao Wang, Shihao Liang, Yujia Qin, Peng Li, Zhiyuan Liu, Maosong Sun, and Yang Liu
-
[4]
StableToolBench: Towards stable large-scale benchmarking on tool learning of large language models. (arXiv:2403.07714). ArXiv:2403.07714 [cs]. Tim Huang
-
[5]
https: //github.com/tron-format/tron-javascript
TRON-JavaScript: A JavaScript library for working with the TRON format. https: //github.com/tron-format/tron-javascript. MIT License. Accessed: 2026-05-06. Mateo Lafalce. 2025.TOON vs. JSON: A Mathematical Evaluation of Byte Efficiency in Structured Data. Ziyang Luo, Zhiqi Shen, Wenzhuo Yang, Zirui Zhao, Prathyusha Jwalapuram, Amrita Saha, Doyen Sahoo, Si...
2026
-
[6]
arXiv preprint arXiv:2508.14704
MCP-Universe: Benchmarking large language mod- els with real-world model context protocol servers. arXiv preprint arXiv:2508.14704. Elio Masciari, Vincenzo Moscato, Enea Vincenzo Napolitano, Gian Marco Orlando, Marco Per- illo, and Diego Russo
-
[7]
Are LLMs ready for TOON? benchmarking structural correctness- sustainability trade-offs in novel structured output formats. (arXiv:2601.12014). ArXiv:2601.12014 [cs]. Ivan Matveev
-
[8]
Token-oriented object nota- tion vs JSON: A benchmark of plain and con- strained decoding generation. (arXiv:2603.03306). ArXiv:2603.03306 [cs]. Damon McMillan
-
[9]
Structured context engi- neering for file-native agentic systems: Evaluat- ing schema accuracy, format effectiveness, and multi-file navigation at scale. (arXiv:2602.05447). ArXiv:2602.05447 [cs]. Model Context Protocol Authors
-
[10]
https://github.com/modelcontextprotocol
Model context protocol: An open protocol for seamless integration between LLM applications and external data. https://github.com/modelcontextprotocol. Accessed: 2026-01-13. Manas Mudbari and Chandan Bhagat. 2026.TSLN: Time-Series Lean Notation: A Novel Data Serializa- tion Format for Token-Efficient Analysis with Large Language Models. Gowthamkumar Nandakishore
2026
-
[11]
JTON: A Token-Efficient JSON Superset with Zen Grid Tabular Encoding for Large Language Models
JTON: A token- efficient JSON superset with zen grid tabular encod- ing for large language models. (arXiv:2604.05865). ArXiv:2604.05865 [cs]. Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Gorilla: Large Language Model Connected with Massive APIs
Gorilla: Large language model connected with massive APIs.arXiv preprint arXiv:2305.15334. Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
ToolLLM: Facilitating large language models to master 16000+ real-world APIs.arXiv preprint arXiv:2307.16789. Johann Schopplich
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
compact, human-readable, schema- aware JSON for LLM prompts
TOON: Token-oriented ob- ject notation. compact, human-readable, schema- aware JSON for LLM prompts. spec, bench- marks, TypeScript sdk. https://github.com/ toon-format/toon. MIT License. Accessed: 2026- 05-06. Janghoon Yang
2026
-
[15]
evaluates multi- turn agentic reasoning. While MCP-Universe ships with both a native function-calling mode (using the OpenAI tool-use API) and a text-based ReAct agent (Yao et al., 2023), we use the ReAct agent because the native API manages tool schemas in- ternally and so cannot accept custom serializations. The ReAct agent embeds tool schemas as text i...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.