Learning Fair Pareto-Optimal Policies in Multi-Objective Reinforcement Learning
Pith reviewed 2026-06-27 00:55 UTC · model grok-4.3
The pith
For concave piecewise-linear welfare functions like GGF, fair policies stay inside the convex coverage set of multi-objective RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
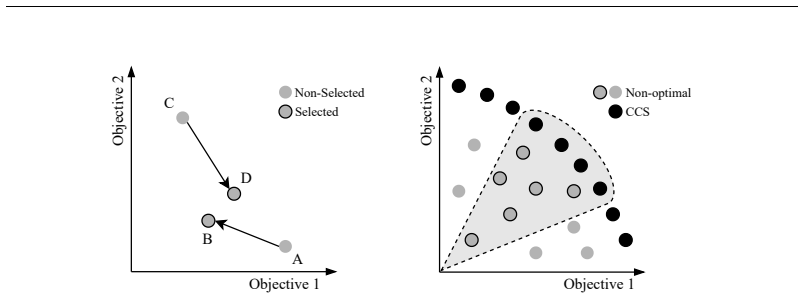
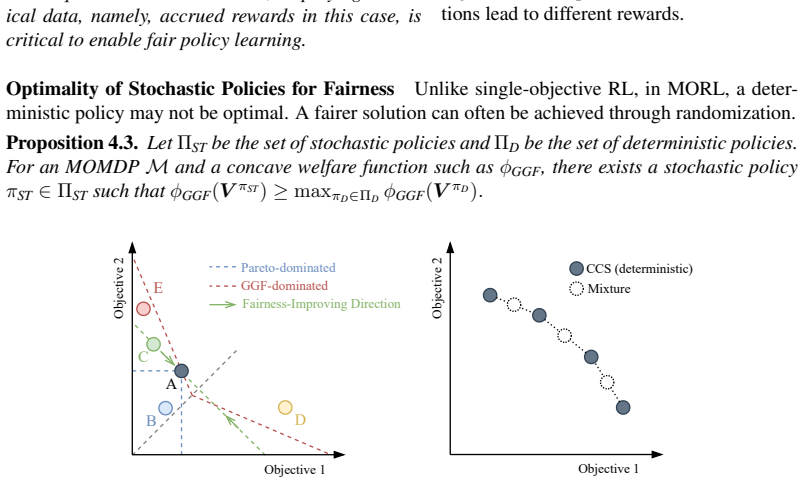
For concave, piecewise-linear welfare functions such as the generalized Gini welfare function, fair policies remain inside the convex coverage set. Non-stationary policies that track accrued reward histories and stochastic policies both increase fairness by responding to historical imbalances. Three algorithms are introduced that combine the GGF scalarization with multi-policy multi-objective Q-learning to learn the required set of policies.
What carries the argument
The convex coverage set (CCS) as an approximated Pareto front that contains all fair policies for concave piecewise-linear welfare functions, integrated with the generalized Gini welfare function inside multi-policy multi-objective Q-learning.
If this is right
- A single set of policies learned via the proposed algorithms suffices for any user preference expressible by the welfare function.
- Non-stationary policies that carry reward history improve equity without leaving the CCS.
- Stochastic policies further reduce historical inequities while preserving Pareto optimality.
- The same CCS-based learning framework works across multiple domains when compared with prior MORL baselines.
Where Pith is reading between the lines
- The result suggests that fairness constraints need not expand the policy search space beyond what linear scalarization already covers for this class of welfare functions.
- In practice this could let deployed systems switch among pre-learned policies when user preferences shift rather than retraining from scratch.
- A natural next test is whether the same containment extends to welfare functions that are concave but not piecewise linear.
Load-bearing premise
Welfare functions must be concave and piecewise-linear for the containment of fair policies inside the convex coverage set to hold.
What would settle it
An explicit counter-example of a concave piecewise-linear welfare function together with a fair policy that lies strictly outside the convex coverage set would falsify the central containment result.
Figures

read the original abstract
Fairness is an important aspect of decision-making in multi-objective reinforcement learning (MORL), where policies must ensure both optimality and equity across multiple, potentially conflicting objectives. While single-policy MORL methods can learn fair policies for fixed user preferences using welfare functions such as the generalized Gini welfare function (GGF), they fail to provide the diverse set of policies necessary for dynamic or unknown user preferences. To address this limitation, we formalize the fair optimization problem in multi-policy MORL, where the goal is to learn a set of Pareto-optimal policies that ensure fairness across all possible user preferences. Our key technical contributions are threefold: (1) We show that for concave, piecewise-linear welfare functions (e.g., GGF), fair policies remain in the convex coverage set (CCS), which is an approximated Pareto front for linear scalarization. (2) We demonstrate that non-stationary policies, augmented with accrued reward histories, and stochastic policies improve fairness by dynamically adapting to historical inequities. (3) We propose three novel algorithms, which include integrating GGF with multi-policy multi-objective Q-Learning (MOQL), state-augmented multi-policy MOQL for learning non-statoinary policies, and its novel extension for learning stochastic policies. We evaluate our algorithms across various domains and compare our methods against the state-of-the-art MORL baselines. The empirical results show that our methods learn a set of fair policies that accommodate different user preferences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
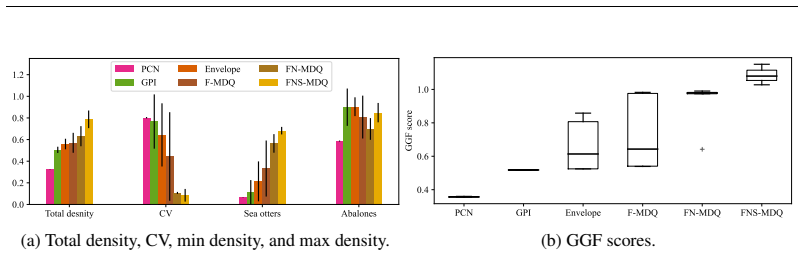
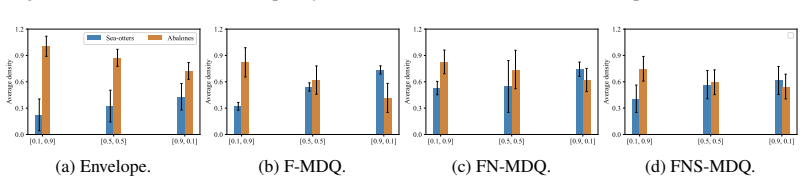
Summary. The paper formalizes the fair multi-policy MORL problem and claims three contributions: (1) for concave piecewise-linear welfare functions such as GGF, every fair policy lies inside the convex coverage set (CCS) of policies optimal for some linear scalarization; (2) non-stationary and stochastic policies improve fairness via history augmentation; (3) three MOQL-based algorithms (GGF-integrated, state-augmented, and stochastic variants) learn covering sets of fair policies. Empirical results across domains are reported to show that the learned sets accommodate varying user preferences better than prior MORL baselines.
Significance. If the CCS-containment result is correct, the work supplies a theoretically grounded reduction that lets multi-policy MORL restrict its search to an approximated Pareto front while still guaranteeing fairness for any concave piecewise-linear welfare function; this would be a useful bridge between single-policy welfare optimization and preference-agnostic policy sets. The algorithmic extensions for non-stationary and stochastic policies are natural and the empirical demonstration, if properly controlled, would support practical adoption.
major comments (2)
- [§3] §3 / Theorem on CCS containment: the central claim that every GGF-optimal policy remains inside the CCS rests on concavity and piecewise-linearity guaranteeing a supporting hyperplane; the manuscript must supply the full derivation (including the precise geometric condition on the attainable reward set) and discuss or exhibit cases where the breakpoints of the GGF or non-convexity of the reward set would place a fair policy strictly outside the CCS, as this directly determines whether restricting search to the CCS is sufficient.
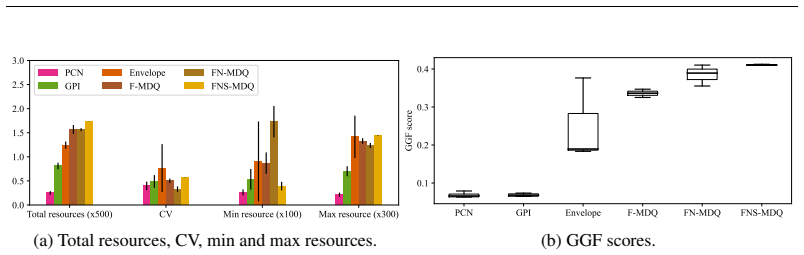
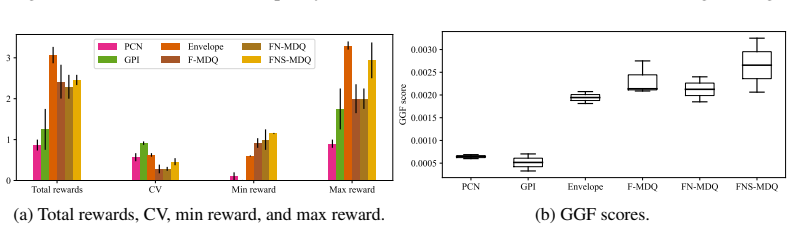
- [§5] §5 (empirical evaluation): the claim of superiority over state-of-the-art MORL baselines is load-bearing for the algorithmic contribution, yet the reported results lack error bars, explicit dataset generation details, hyper-parameter tables, and per-preference welfare scores; without these the reader cannot verify that the learned CCS covers arbitrary user preferences rather than overfitting the tested welfare functions.
minor comments (2)
- Notation for the CCS and the welfare function should be introduced once with a single consistent symbol set rather than re-defined across sections.
- [§5] The abstract states 'we evaluate our algorithms across various domains' but the experimental section should include a table listing environment names, objective counts, and episode lengths for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and will revise the manuscript to strengthen both the theoretical presentation and the empirical reporting.
read point-by-point responses
-
Referee: [§3] §3 / Theorem on CCS containment: the central claim that every GGF-optimal policy remains inside the CCS rests on concavity and piecewise-linearity guaranteeing a supporting hyperplane; the manuscript must supply the full derivation (including the precise geometric condition on the attainable reward set) and discuss or exhibit cases where the breakpoints of the GGF or non-convexity of the reward set would place a fair policy strictly outside the CCS, as this directly determines whether restricting search to the CCS is sufficient.
Authors: We agree that the current presentation would benefit from an expanded derivation. In the revised manuscript we will include the complete proof of the CCS-containment result, explicitly stating the supporting-hyperplane argument that follows from concavity and piecewise linearity of the GGF together with the precise geometric condition on the attainable reward set. We will also add a dedicated paragraph analyzing potential violations: we show that any departure from concavity or piecewise linearity (or a non-convex reward set) can indeed place a fair policy outside the CCS, but that these cases lie outside the assumptions of our theorem; under the stated conditions the containment holds. This addition will clarify the scope of the reduction to the CCS. revision: yes
-
Referee: [§5] §5 (empirical evaluation): the claim of superiority over state-of-the-art MORL baselines is load-bearing for the algorithmic contribution, yet the reported results lack error bars, explicit dataset generation details, hyper-parameter tables, and per-preference welfare scores; without these the reader cannot verify that the learned CCS covers arbitrary user preferences rather than overfitting the tested welfare functions.
Authors: We accept that the current empirical section is insufficiently detailed for independent verification. In the revised manuscript we will (i) report mean performance with standard-error bars across multiple random seeds, (ii) provide explicit descriptions of dataset generation procedures and environment parameterizations, (iii) include a comprehensive hyper-parameter table, and (iv) add tables of per-preference welfare scores evaluated on a wider grid of user preference vectors. These changes will demonstrate that the learned policy sets generalize across preferences rather than overfitting the specific welfare functions used during training. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central technical claim is a mathematical containment result: for concave piecewise-linear welfare functions such as GGF, fair policies remain inside the CCS. This is stated as an independent derivation from standard MORL concepts rather than a redefinition, a fitted parameter renamed as prediction, or a load-bearing self-citation. The three proposed algorithms follow from this result and from the introduction of non-stationary and stochastic policies, but none of the steps reduce by construction to the inputs via the enumerated circularity patterns. The derivation is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Welfare functions such as GGF are concave and piecewise-linear
Reference graph
Works this paper leans on
-
[1]
Lucas N Alegre, Ana LC Bazzan, Diederik M Roijers, Ann Nowé, and Bruno C da Silva. Sample- efficient multi-objective learning via generalized policy improvement prioritization.arXiv preprint arXiv:2301.07784,
-
[2]
A multi-objective frame- work for fair reinforcement learning
Alexandra Cimpeana, Catholijn Jonkerb, Pieter Libina, and Ann Nowéa. A multi-objective frame- work for fair reinforcement learning. InMulti-Objective Decision Making Workshop 2023,
2023
-
[3]
Optimizing generalized gini indices for fairness in rankings.arXiv preprint arXiv:2204.06521,
13 Virginie Do and Nicolas Usunier. Optimizing generalized gini indices for fairness in rankings.arXiv preprint arXiv:2204.06521,
-
[4]
Welfare and fairness in multi-objective reinforcement learning.arXiv preprint arXiv:2212.01382,
Zimeng Fan, Nianli Peng, Muhang Tian, and Brandon Fain. Welfare and fairness in multi-objective reinforcement learning.arXiv preprint arXiv:2212.01382,
-
[5]
Multiaccuracy: Black-box post-processing for fairness in classification
Michael P Kim, Amirata Ghorbani, and James Zou. Multiaccuracy: Black-box post-processing for fairness in classification. InProceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, pp. 247–254,
2019
-
[6]
DOI: 10.1145/2764468.2764490. M. Laumanns, L. Thiele, K. Deb, and E. Zitzler. Combining convergence and diversity in evolution- ary multiobjective optimization.Evolutionary Computation, 10(3):263–282.,
-
[7]
User fairness in recommender systems
Jurek Leonhardt, Avishek Anand, and Megha Khosla. User fairness in recommender systems. In Companion Proceedings of the The Web Conference 2018, pp. 101–102,
2018
-
[8]
Socially fair reinforcement learning.arXiv preprint arXiv:2208.12584,
Debmalya Mandal and Jiarui Gan. Socially fair reinforcement learning.arXiv preprint arXiv:2208.12584,
-
[9]
Scalable multi-objective reinforcement learning with fairness guarantees using lorenz dominance
Dimitris Michailidis, Willem Röpke, Diederik M Roijers, Sennay Ghebreab, and Fernando P Santos. Scalable multi-objective reinforcement learning with fairness guarantees using lorenz dominance. arXiv preprint arXiv:2411.18195,
-
[10]
Samer B Nashed, Justin Svegliato, and Su Lin Blodgett. Fairness and sequential decision making: Limits, lessons, and opportunities.arXiv preprint arXiv:2301.05753,
-
[11]
Pareto conditioned networks.arXiv preprint arXiv:2204.05036,
Mathieu Reymond, Eugenio Bargiacchi, and Ann Nowé. Pareto conditioned networks.arXiv preprint arXiv:2204.05036,
-
[12]
Fairness in preference-based reinforcement learning
Umer Siddique, Abhinav Sinha, and Yongcan Cao. Fairness in preference-based reinforcement learning. InICML 2023 Workshop The Many Facets of Preference-Based Learning,
2023
-
[13]
equal treatment of equals
16 Supplementary Materials The following content was not necessarily subject to peer review. 8 Proofs of Technical Analysis In this section, we provide formal proofs of our technical analysis in detail. For better legibility, we first recall the equations and results that we need for our proofs. ∀ω∈Ω,max π∈Π ϕ(V(π)),(3) whereΩis the set of valid preferenc...
2008
-
[14]
This domain presents a unique challenge centered around the acquisition of three types of resources: gold, gems, and stones, thereby establishing a multi-objective framework withK=
10.2 Resource Gathering In this scenario of resource gathering, we consider a5×5grid world domain inspired from (Barrett & Narayanan, 2008). This domain presents a unique challenge centered around the acquisition of three types of resources: gold, gems, and stones, thereby establishing a multi-objective framework withK=
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.