Clustering in pure-attention hardmax transformers and its role in sentiment analysis
Pith reviewed 2026-05-23 23:38 UTC · model grok-4.3
The pith
Hardmax self-attention transformers converge their inputs to clusters around leader points in the infinite-layer limit.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By viewing such transformers as discrete-time dynamical systems and invoking the geometric hyperplane-separation property of hardmax attention, the transformer inputs asymptotically converge to a clustered equilibrium determined by special points called leaders.
What carries the argument
the hyperplane-separation property of hardmax self-attention, which selects attention weights and thereby steers the discrete dynamical system toward leader-determined clusters
If this is right
- Inputs converge to a clustered equilibrium whose centers are the leader points.
- Context in language tasks is captured by routing semantically weaker tokens into clusters around leader tokens.
- The same dynamics yields a fully interpretable transformer that solves sentiment-analysis problems without learned parameters beyond the leader selection.
- Remaining mathematical challenges must still be resolved before the clustering picture applies to trained, multi-head, softmax-based transformers.
Where Pith is reading between the lines
- Leader points may correspond to the tokens that carry the strongest semantic signal in a given sequence.
- The same geometric mechanism could be used to design new, explicitly clustered attention layers that remain interpretable at arbitrary depth.
- If real transformers approximate hardmax behavior in deep layers, their attention maps should exhibit similar leader-driven clustering on natural-language data.
Load-bearing premise
The analysis assumes a pure-attention hardmax self-attention mechanism with normalization sublayers whose geometric hyperplane-separation property governs the infinite-layer limit.
What would settle it
A concrete numerical iteration of the hardmax-plus-normalization map on a finite point set that fails to produce clusters whose centers coincide with the leaders predicted by the hyperplane geometry.
Figures









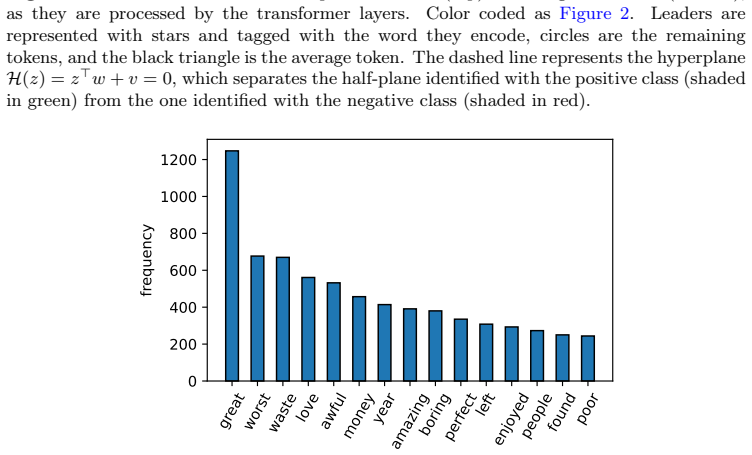
read the original abstract
Transformers are extremely successful machine learning models whose mathematical properties remain poorly understood. Here, we rigorously characterize the behavior of transformers with hardmax self-attention and normalization sublayers as the number of layers tends to infinity. By viewing such transformers as discrete-time dynamical systems describing the evolution of points in a Euclidean space, and thanks to a geometric interpretation of the self-attention mechanism based on hyperplane separation, we show that the transformer inputs asymptotically converge to a clustered equilibrium determined by special points called \textit{leaders}. We then leverage this theoretical understanding to solve sentiment analysis problems from language processing using a fully interpretable transformer model, which effectively captures `context' by clustering meaningless words around leader words carrying the most meaning. Finally, we outline remaining challenges to bridge the gap between the mathematical analysis of transformers and their real-life implementation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript rigorously characterizes the infinite-layer limit of pure-attention hardmax transformers equipped with normalization sublayers by modeling them as discrete-time dynamical systems on Euclidean space. A geometric argument based on hyperplane separation is used to prove that token representations asymptotically converge to a clustered equilibrium whose attractors are special points termed leaders. The derived clustering property is then applied to construct a fully interpretable transformer for sentiment-analysis tasks, in which semantically meaningless tokens cluster around leader tokens that carry the primary meaning; remaining challenges for closing the gap to practical implementations are outlined.
Significance. If the convergence theorem holds, the work supplies a parameter-free dynamical-systems explanation for clustering phenomena in a precisely defined subclass of attention models and demonstrates how the resulting leaders can be exploited for interpretable NLP. The geometric hyperplane-separation technique and the explicit scoping to hardmax-plus-normalization dynamics constitute clear strengths; the sentiment-analysis application supplies a concrete, falsifiable use case.
minor comments (3)
- The definition and selection rule for the 'leaders' should be stated explicitly in the introduction or in a dedicated preliminary section rather than introduced only in the convergence theorem statement.
- Notation for the normalization sublayers and the precise form of the hardmax operator should be unified across the dynamical-system formulation and the sentiment-analysis experiments.
- The discussion of the gap between the infinite-layer analysis and finite practical transformers would benefit from a short paragraph quantifying how many layers are typically required for the clustering to become observable in the reported experiments.
Simulated Author's Rebuttal
We thank the referee for the positive and constructive review. The recommendation for minor revision is appreciated, and we will make the necessary adjustments in the revised version.
Circularity Check
No significant circularity in the derivation chain
full rationale
The central result is a mathematical characterization of the infinite-layer limit for the specific dynamical system of hardmax self-attention plus normalization, obtained via geometric hyperplane separation. No load-bearing step reduces by construction to a fitted parameter, self-definition, or self-citation chain; the clustering equilibrium follows from the stated model equations and geometric property without circular reduction. The sentiment-analysis application is scoped as a downstream illustration, not part of the convergence derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Transformers with hardmax self-attention and normalization can be modeled as discrete-time dynamical systems on Euclidean space
- domain assumption Self-attention admits a geometric interpretation based on hyperplane separation
invented entities (1)
-
leaders
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Control, Optimal Transport and Neural Differential Equations in Supervised Learning
A novel framework approximates unbalanced optimal transport using Neural ODEs via a generalized discrete problem, a Sinkhorn-inspired scheme with proven convergence and error estimates, and derived transport dynamics.
Reference graph
Works this paper leans on
-
[1]
F. A. Acheampong, H. Nunoo-Mensah, and W. Chen. Transformer models for text-based emotion detection: a review of bert-based approaches.Artificial Intelligence Review, 54 (8):5789–5829, 2021
work page 2021
-
[2]
S. Alberti, N. Dern, L. Thesing, and G. Kutyniok. Sumformer: Universal approximation for efficient transformers. In Topological, Algebraic and Geometric Learning Workshops 2023, pages 72–86. PMLR, 2023
work page 2023
- [3]
-
[4]
T. Brown et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, volume 33, pages 1877–1901, 2020
work page 1901
-
[5]
F. Charton, A. Hayat, and G. Lample. Learning advanced mathematical computations from examples. In9th International Conference on Learning Representations (ICLR 2021), 2021
work page 2021
-
[6]
F. Charton, A. Hayat, S. T. McQuade, N. J. Merrill, and B. Piccoli. A deep language model to predict metabolic network equilibria. arXiv:2112.03588 [cs.LG], 2021
-
[7]
R. T. Q. Chen, Y. Rubanova, J. Bettencourt, and D. K. Duvenaud. Neural ordinary differential equations. InAdvances in Neural Information Processing Systems, volume 31, 2018
work page 2018
-
[8]
A. Dosovitskiy et al. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021
work page 2021
-
[9]
Effects of padding on LSTMs and CNNs
M. Dwarampudi and N. Reddy. Effects of padding on lstms and cnns. arXiv:1903.07288 [cs.LG], 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[10]
W. E. A proposal on machine learning via dynamical systems.Communications in Math- ematics and Statistics, 5(1):1–11, 2017
work page 2017
-
[11]
I. M. Elfadel and J. L. Wyatt Jr. The ‘softmax’ nonlinearity: Derivation using statistical mechanics and useful properties as a multiterminal analog circuit element.Advances in Neural Information Processing Systems, 6, 1993
work page 1993
-
[12]
B. Geshkovski and E. Zuazua. Turnpike in optimal control of pdes, resnets, and beyond. Acta Numerica, 31:135–263, 2022
work page 2022
-
[13]
B. Geshkovski, C. Letrouit, Y. Polyanskiy, and P. Rigollet. The emergence of clusters in self-attention dynamics. arXiv:2305.05465 [cs.LG], 2023. CLUSTERING IN PURE-ATTENTION HARDMAX TRANSFORMERS 23
-
[14]
B. Geshkovski, C. Letrouit, Y. Polyanskiy, and P. Rigollet. A mathematical perspective on Transformers. arXiv:2312.10794 [cs.LG], 2023
-
[15]
F. Gloeckle, B. Rozière, A. Hayat, and G. Synnaeve. Temperature-scaled large language models for lean proofstep prediction. In37th Conference on Neural Information Processing Systems (NeurIPS 2023), 2023
work page 2023
- [16]
-
[17]
S. Hochreiter and J. Schmidhuber. Long Short-Term Memory.Neural Computation, 9(8): 1735–1780, 11 1997. ISSN 0899-7667
work page 1997
-
[18]
S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. InProceedings of the 32nd International Conference on Machine Learning, volume 37, pages 448–456, 2015
work page 2015
-
[19]
J. M. Jumper et al. Highly accurate protein structure prediction with alphafold.Nature, 596:583–589, 2021
work page 2021
-
[20]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv:1412.6980 [cs.LG], 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[21]
Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Soricut. Albert: A lite bert for self-supervised learning of language representations. InInternational Conference on Learning Representations, 2020
work page 2020
-
[22]
Q. Li, T. Lin, and Z. Shen. Deep learning via dynamical systems: An approximation perspective. Journal of the European Mathematical Society, 25(5):1671–1709, 2022
work page 2022
- [23]
-
[24]
A. L. Maas, R. E. Daly, P. T. Pham, D. Huang, A. Y. Ng, and C. Potts. Learning word vectors for sentiment analysis. InProceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 142–150, 2011
work page 2011
-
[25]
R. Pascanu, T. Mikolov, and Y. Bengio. On the difficulty of training recurrent neural networks. InInternational conference on machine learning, pages 1310–1318, 2013
work page 2013
-
[26]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
A. Paszke et al. Pytorch: An imperative style, high-performance deep learning library. arXiv:1912.01703 [cs.LG], 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[27]
S. Peluchetti and S. Favaro. Infinitely deep neural networks as diffusion processes. In International Conference on Artificial Intelligence and Statistics, pages 1126–1136. PMLR, 2020
work page 2020
-
[28]
S. Peluchetti and S. Favaro. Doubly infinite residual neural networks: a diffusion process approach. Journal of Machine Learning Research, 22:175/1–48, 2021
work page 2021
-
[29]
A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever. Improving lan- guage understanding by generative pre-training. Technical report, OpenAI, 2018. Available from: https://cdn.openai.com/research-covers/language-unsupervised/ language_understanding_paper.pdf
work page 2018
-
[30]
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. Mcleavey, and I. Sutskever. Robust speechrecognitionvialarge-scaleweaksupervision. In Proceedings of the 40th International Conference on Machine Learning, volume 202, pages 28492–28518, 2023
work page 2023
-
[31]
D. Ruiz-Balet and E. Zuazua. Neural ode control for classification, approximation, and transport. SIAM Review, 65(3):735–773, 2023
work page 2023
-
[32]
M. E. Sander, P. Ablin, M. Blondel, and G. Peyré. Sinkformers: Transformers with Doubly Stochastic Attention. In Proceedings of The 25th International Conference on Artificial Intelligence and Statistics, pages 3515–3530, 2022
work page 2022
-
[33]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is All you Need. InAdvances in Neural Information Processing Systems, volume 30, 2017
work page 2017
-
[34]
C. Yun, S. Bhojanapalli, A. S. Rawat, S. J. Reddi, and S. Kumar. Are transformers universal approximators of sequence-to-sequence functions? InInternational Conference on Learning Representations, 2020. 24 A. ALCALDE, G. F ANTUZZI, AND E. ZUAZUA Email address: albert.alcalde@fau.de Email address: giovanni.fantuzzi@fau.de Email address: enrique.zuazua@fau.de
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.