Invariant Reasoning Directions in Latent Trajectories of Language Models
Pith reviewed 2026-06-30 08:04 UTC · model grok-4.3
The pith
Latent trajectories in language models contain stable low-rank invariant reasoning directions that can be isolated to improve consistency under paraphrase and perturbation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
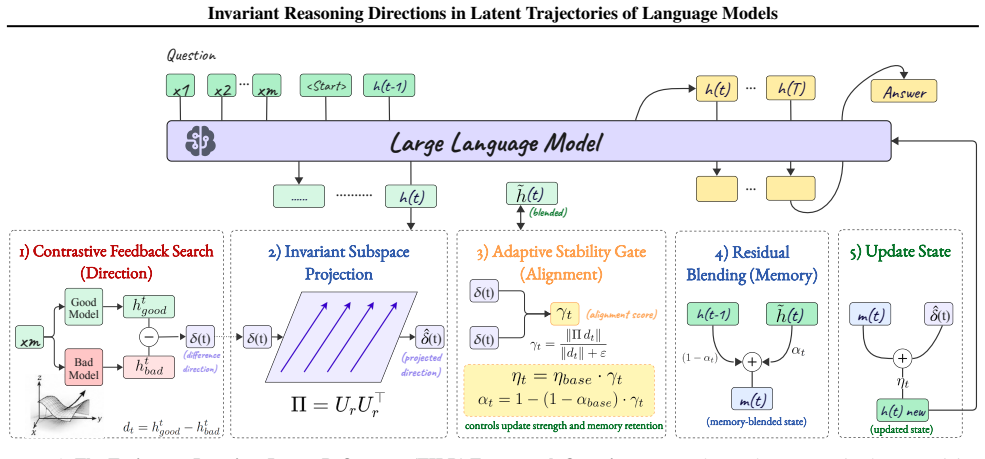
Contrastive refinement signals between stronger and weaker reasoning trajectories exhibit a highly concentrated low-rank structure, while unconstrained latent updates remain sensitive to paraphrases, checkpoint choice, and trajectory perturbations. These observations indicate that latent reasoning trajectories contain stable invariant directions mixed with unstable instance-specific variation. TILR learns a low-rank invariant subspace from contrastive trajectory differences across inputs, then constrains latent interventions to this subspace while suppressing poorly aligned updates through an adaptive alignment gate. Interventions on these directions causally improve reasoning consistency an
What carries the argument
Trajectory-Invariant Latent Refinement (TILR), which extracts a low-rank invariant subspace from contrastive trajectory differences across inputs and constrains interventions to this subspace with an adaptive alignment gate.
If this is right
- A small number of latent directions explain most variation between strong and weak reasoning trajectories.
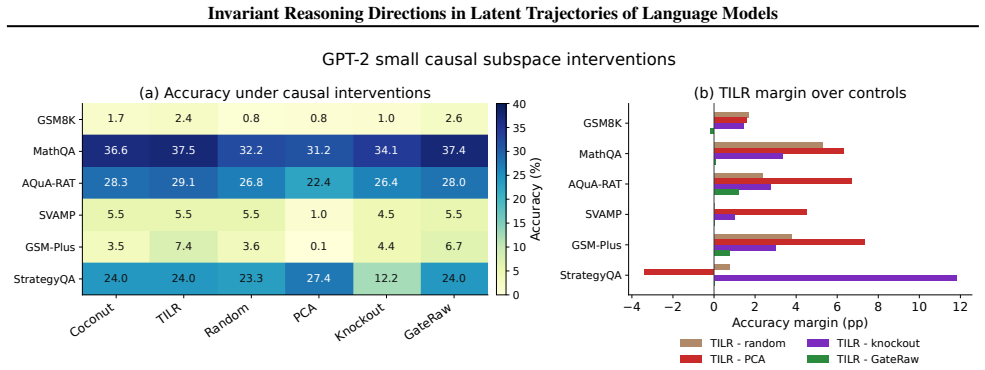
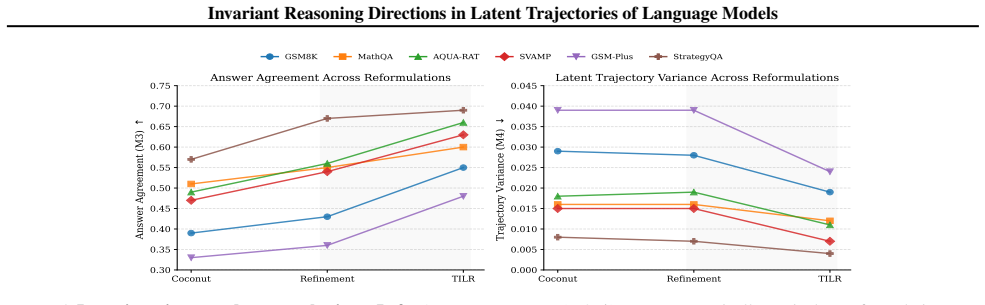
- Interventions on these directions improve answer consistency under paraphrase by approximately 10 percent.
- Latent trajectory variance is reduced by up to 50 percent.
- Reasoning accuracy is preserved while consistency gains appear across six benchmarks.
- Constraining updates to the learned subspace suppresses poorly aligned changes that would otherwise destabilize trajectories.
Where Pith is reading between the lines
- The same low-rank extraction procedure could be tested on non-reasoning behaviors such as factual recall or translation to check whether invariant directions appear more broadly.
- If the subspace proves transferable across model families, it would suggest a route to post-hoc robustness fixes that avoid full retraining.
- The geometric framing implies that many consistency failures arise from drifting outside a narrow stable manifold rather than from missing knowledge.
Load-bearing premise
The low-rank structure found in contrastive trajectory differences across inputs captures stable, transferable invariant reasoning directions rather than artifacts tied to specific models, checkpoints, or input distributions.
What would settle it
If the subspace extracted by TILR fails to produce measurable gains in answer consistency on held-out paraphrases or new model checkpoints, or if the explained variance remains high-rank rather than low-rank when measured across diverse inputs.
Figures

read the original abstract
Latent reasoning models perform multi-step inference directly in hidden-state space, yet the structure of these latent reasoning trajectories remains poorly understood. We show that contrastive refinement signals between stronger and weaker reasoning trajectories exhibit a highly concentrated low-rank structure, while unconstrained latent updates remain sensitive to paraphrases, checkpoint choice, and trajectory perturbations. These observations suggest that latent reasoning trajectories contain stable invariant directions mixed with unstable instance-specific variation. We introduce \textbf{Trajectory-Invariant Latent Refinement (TILR)}, a training-free intervention framework for identifying and manipulating stable reasoning directions in latent space. TILR first learns a low-rank invariant subspace from contrastive trajectory differences across inputs, then constrains latent interventions to this subspace while suppressing poorly aligned updates through an adaptive alignment gate. Across six reasoning benchmarks, we find that a small number of latent directions explain most variation between strong and weak reasoning trajectories. Interventions on these directions causally improve reasoning consistency and reduce trajectory instability under paraphrases and perturbations. TILR improves answer consistency under paraphrase by ~10% and reduces latent trajectory variance by up to $50\%$ while preserving reasoning accuracy. These results support a geometric view of latent reasoning in which transferable reasoning behavior emerges from stable low-dimensional structure within hidden-state trajectories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that contrastive refinement signals between stronger and weaker reasoning trajectories in language models exhibit a highly concentrated low-rank structure, while unconstrained updates are sensitive to paraphrases and perturbations. It introduces Trajectory-Invariant Latent Refinement (TILR), a training-free method that extracts a low-rank invariant subspace from these contrastive differences and constrains interventions to it via an adaptive alignment gate. Across six reasoning benchmarks, interventions on the extracted directions are reported to causally improve answer consistency under paraphrase by ~10% and reduce latent trajectory variance by up to 50% while preserving accuracy, supporting a geometric view of transferable reasoning behavior in hidden-state trajectories.
Significance. If the results hold with proper validation, the work provides a geometric perspective on latent reasoning trajectories and a practical training-free intervention technique that could improve robustness in reasoning models. The emphasis on low-rank structure and causal manipulation of invariant directions is a potential strength for understanding and enhancing model behavior without retraining.
major comments (3)
- [Abstract] Abstract: The abstract states quantitative gains (~10% consistency improvement, up to 50% variance reduction) and causal effects but supplies no experimental details, error bars, baseline comparisons, statistical tests, or description of how the low-rank subspace is computed or validated; claims rest on unshown results.
- [TILR method description] TILR method description: The subspace is derived directly from the contrastive (strong vs. weak) trajectory differences that the method later intervenes on; without external benchmarks or held-out validation described, the approach risks circular dependence on the same signals used to define success.
- [Experiments section] Experiments section: No evidence is provided that the extracted subspace itself is insensitive to checkpoint choice or to how 'strong' vs. 'weak' trajectories are sampled, which is load-bearing for the claim that it captures stable, transferable invariant reasoning directions rather than artifacts tied to specific models or input distributions.
minor comments (2)
- [Abstract] Abstract: The claim that 'a small number of latent directions explain most variation' lacks specific quantification such as the rank of the subspace or fraction of variance explained.
- [Notation] Notation: The adaptive alignment gate is referenced but its precise formulation and implementation details are not provided.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where additional clarity and validation will strengthen the manuscript. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states quantitative gains (~10% consistency improvement, up to 50% variance reduction) and causal effects but supplies no experimental details, error bars, baseline comparisons, statistical tests, or description of how the low-rank subspace is computed or validated; claims rest on unshown results.
Authors: The abstract is intentionally concise per typical length constraints. The full manuscript details the six benchmarks, SVD-based subspace extraction from contrastive trajectory differences, baseline comparisons, and variance metrics in Sections 3 and 4. We will revise the abstract to include a brief clause on the method (low-rank subspace from contrastive differences) and evaluation across six benchmarks, while directing readers to the main text for error bars and statistical details. revision: partial
-
Referee: [TILR method description] TILR method description: The subspace is derived directly from the contrastive (strong vs. weak) trajectory differences that the method later intervenes on; without external benchmarks or held-out validation described, the approach risks circular dependence on the same signals used to define success.
Authors: The subspace is extracted from contrastive differences on a collection of inputs, but evaluation uses independent metrics: paraphrase consistency and trajectory variance on held-out test examples and perturbation sets that are disjoint from the contrastive pairs. These metrics do not reuse the strong/weak labels or differences. We will add explicit text in Section 2 clarifying this separation and confirming held-out splits for validation. revision: yes
-
Referee: [Experiments section] Experiments section: No evidence is provided that the extracted subspace itself is insensitive to checkpoint choice or to how 'strong' vs. 'weak' trajectories are sampled, which is load-bearing for the claim that it captures stable, transferable invariant reasoning directions rather than artifacts tied to specific models or input distributions.
Authors: We agree this robustness check is important for the invariance claim. The current results span multiple models and benchmarks but lack explicit ablations on checkpoint variation or alternative strong/weak sampling procedures. We will add these experiments in the revised manuscript, reporting subspace stability (e.g., cosine similarity of top directions) across checkpoints and sampling variants. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical pipeline: contrastive differences between strong/weak trajectories are used to identify a low-rank subspace, after which interventions constrained to that subspace are tested for consistency gains on six reasoning benchmarks. This is a data-driven identification step followed by separate evaluation, not a derivation in which the claimed invariant directions or performance gains reduce to the input signals by construction (no equations equate the subspace extraction directly to the success metric). No self-citation chains, ansatzes smuggled via prior work, or fitted parameters renamed as predictions appear in the provided abstract or description. The central geometric claim remains independently testable against external benchmarks and perturbations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mathqa: Towards interpretable math word problem solving with operation-based for- malisms
Amini, A., Gabriel, S., Lin, S., Koncel-Kedziorski, R., Choi, Y ., and Hajishirzi, H. Mathqa: Towards interpretable math word problem solving with operation-based for- malisms. InProceedings of the 2019 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)...
2019
-
[2]
Arjovsky, M., Bottou, L., Gulchandani, I., and Lopez- Paz, D. Invariant risk minimization.arXiv preprint arXiv:1907.02893,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[3]
Training Verifiers to Solve Math Word Problems
URL https://arxiv. org/abs/2110.14168. Deng, Y ., Prasad, K., Fernandez, R., Smolensky, P., Chaud- hary, V ., and Shieber, S. Implicit chain of thought reasoning via knowledge distillation.arXiv preprint arXiv:2311.01460,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step
Deng, Y ., Choi, Y ., and Shieber, S. From explicit cot to implicit cot: Learning to internalize cot step by step. arXiv preprint arXiv:2405.14838,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
URLhttps://arxiv.org/abs/2407.21783. Hao, S., Sukhbaatar, S., Su, D., Li, X., Hu, Z., Weston, J., and Tian, Y . Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Trgp: Trust region gradient projection for continual learning.arXiv preprint arXiv:2202.02931,
Lin, S., Yang, L., Fan, D., and Zhang, J. Trgp: Trust region gradient projection for continual learning.arXiv preprint arXiv:2202.02931,
-
[7]
Patel, A., Bhattamishra, S., and Goyal, N. Are nlp models really able to solve simple math word problems? InPro- ceedings of the 2021 conference of the North American chapter of the association for computational linguistics: human language technologies, pp. 2080–2094,
2021
-
[8]
arXiv preprint arXiv:2103.09762 (2021)
Saha, G., Garg, I., and Roy, K. Gradient projection memory for continual learning.arXiv preprint arXiv:2103.09762,
-
[9]
S., Sinha, M., and Dasgupta, T
Sheshanarayana, D., Pal, R. S., Sinha, M., and Dasgupta, T. Thinking in latents: Adaptive anchor refinement for im- plicit reasoning in llms.arXiv preprint arXiv:2603.15051,
-
[10]
Steering Language Models With Activation Engineering
Turner, A. M., Thiergart, L., Leech, G., Udell, D., Vazquez, J. J., Mini, U., and MacDiarmid, M. Steering lan- guage models with activation engineering.arXiv preprint arXiv:2308.10248,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
URL https://arxiv.org/ abs/2409.12122. 10 Invariant Reasoning Directions in Latent Trajectories of Language Models Appendix A. Stopped-Gradient and the Full Jacobian The simplification used in Section 3 treats fgood(˜ht) and fbad(˜ht) as constants with respect to ˜ht. The full gradient of the contrastive objective includes Jacobian terms from both referen...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[12]
Stacking all N T= 600 differences and computing a truncated SVD yields the invariant subspace
The procedure requires only forward passes and no ground-truth labels: for each xi, we run the Coconut backbone with residual blending, pass each intermediate state ˜ht i through both reference models, and form the contrastive differences δt i =h t good,i −h t bad,i. Stacking all N T= 600 differences and computing a truncated SVD yields the invariant subs...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.