Efficient Visual Pointing for Embodied AI:Agent-Driven Data Synthesis, Cross-Block Attention, and Iterative Correction
Pith reviewed 2026-06-30 06:41 UTC · model grok-4.3
The pith
Agent-driven synthesis plus two model modules reach 77.2 percent accuracy on visual pointing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
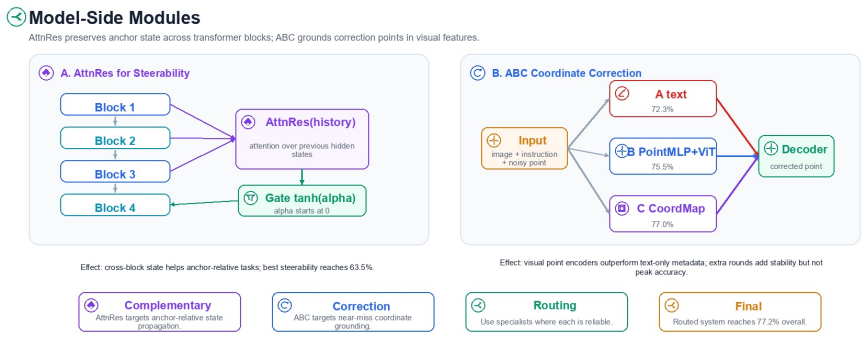
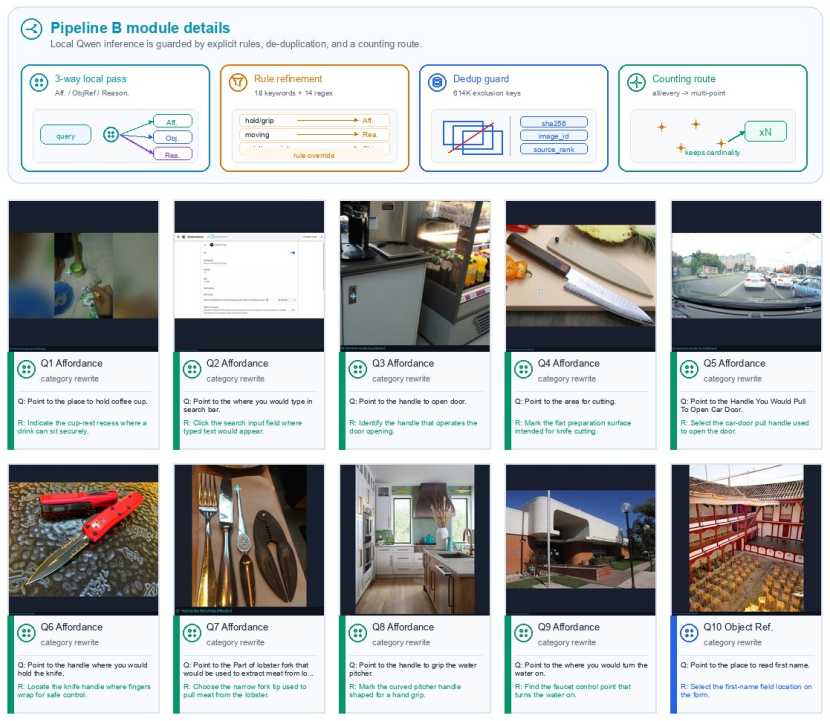
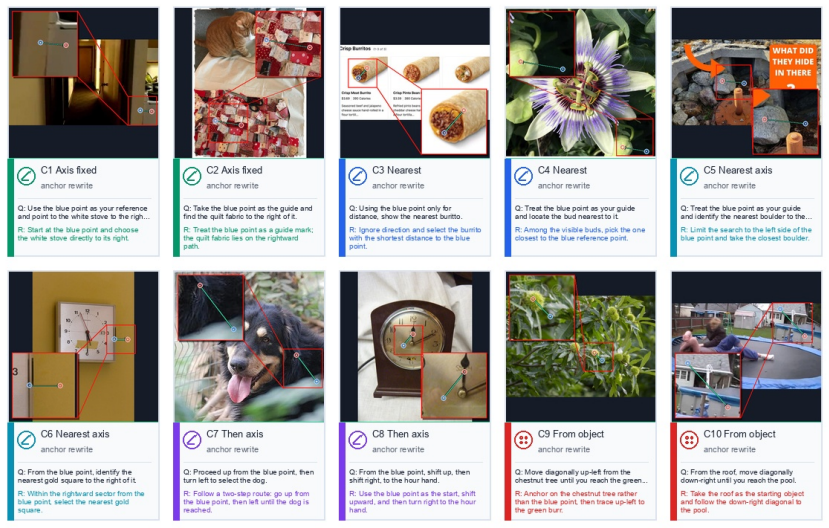
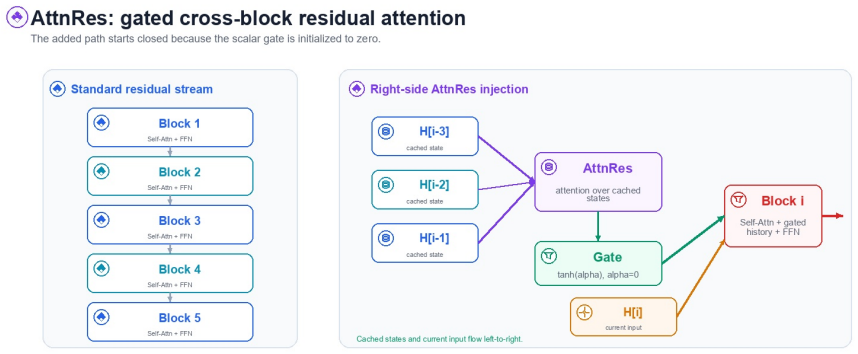
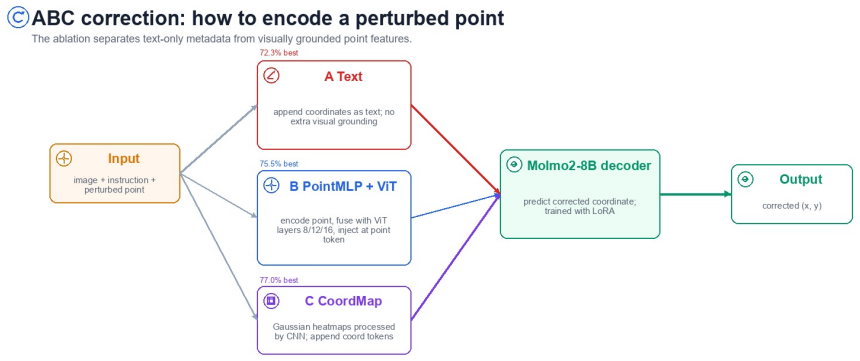
The PointArena 2026 solution achieves 77.2 percent overall accuracy by building semantic and anchor-relative candidate pools from 55,372 processed outputs, creating a verified main set of 10,000 samples through masks, templates and path verification, then applying AttnRes for steerable gated cross-block attention and ABC correction that encodes perturbed coordinates with visual features, all combined via category-aware routing of complementary specialists.
What carries the argument
AttnRes gated cross-block attention and ABC coordinate correction, supported by agent-driven candidate-pool synthesis and category-aware routing.
If this is right
- The approach yields complementary performance across affordance, spatial relation, reasoning, counting and steerability categories.
- Agent-driven synthesis scales the training inventory to 37,574 trainable rows from 55,372 outputs.
- Category-aware routing lets specialist modules handle distinct error types.
- The steerable-data pipeline produces both a main verified set and reserve samples for further use.
Where Pith is reading between the lines
- The synthesis-plus-correction pattern could apply to other localization-heavy vision-language tasks.
- Ablating the modules separately on additional benchmarks would isolate their individual effects.
- The pipeline's verification steps might lower annotation costs in related embodied domains.
Load-bearing premise
Local validation scores accurately predict benchmark performance and that the three targeted failure modes explain the gains without overfitting to the synthesis pipeline.
What would settle it
Training the same base model without AttnRes or ABC correction and measuring whether accuracy on the full benchmark falls well below 77.2 percent.
Figures
read the original abstract
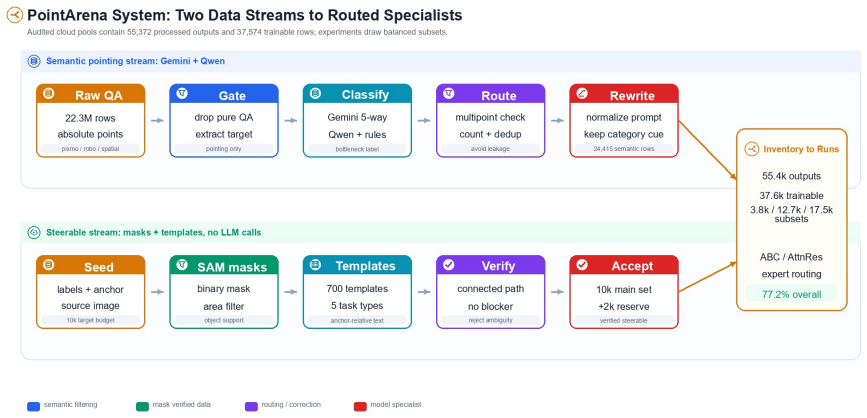
Visual pointing maps a language instruction to pixel co ordinates, a core skill for embodied AI. We describe our PointArena 2026 solution, which achieves 77.2% overall accuracy and ranks second on the benchmark. The ap proach targets three failure modes. First, agent-driven syn thesis builds large semantic and anchor-relative candidate pools; the server inventory contains 55,372 processed out puts, 53,772 de-duplicated sample IDs, and 37,574 train able completed or accepted rows. Second, a determinis tic steerable-data pipeline creates a verified 10,000-sample main set, plus reserve samples, using masks, templates, and path verification. Third, two model-side modules address complementary errors: AttnRes adds gated cross-block at tention for steerability, while ABC correction encodes per turbed coordinates with visual features for general coordi nate grounding. Category-aware routing combines comple mentary specialists; local validation used to select experts records 93.9% Affordance, 82.6% Spatial Relation, 78.2% Reasoning, 70.4% Counting, and 63.0% Steerability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the PointArena 2026 solution for visual pointing, which maps language instructions to pixel coordinates for embodied AI. It reports 77.2% overall accuracy (second place on the benchmark) by targeting three failure modes: agent-driven synthesis producing a server inventory of 55,372 processed outputs and 37,574 trainable rows; a deterministic steerable-data pipeline yielding a verified 10,000-sample main set; and two model modules (AttnRes with gated cross-block attention for steerability, ABC correction encoding perturbed coordinates with visual features) combined via category-aware routing. Local validation on the main set is reported as 93.9% Affordance, 82.6% Spatial Relation, 78.2% Reasoning, 70.4% Counting, and 63.0% Steerability.
Significance. If the benchmark result is shown to follow from the targeted modules rather than the synthesis pipeline alone, the work would supply a concrete, scalable recipe for improving visual grounding in embodied systems through large-scale verified data and complementary architectural corrections. The explicit inventory sizes and the modular separation of synthesis from model-side fixes constitute reusable engineering contributions.
major comments (1)
- [Abstract] Abstract: the central claim that AttnRes and ABC correction (plus the synthesis pipeline) produce the 77.2% benchmark accuracy rests solely on local validation scores recorded on the 10k-sample main set generated by the identical agent-driven and steerable pipeline. No ablation that isolates the contribution of each module, no held-out benchmark subset evaluation, and no distributional comparison between the local set and the test benchmark are described; therefore the attribution of the headline result to the three targeted failure modes remains untested.
minor comments (1)
- [Abstract] Abstract: several compound words contain extraneous spaces ("co ordinates", "ap proach", "de-duplicated").
Simulated Author's Rebuttal
We thank the referee for highlighting the need for stronger evidence linking our modules to the benchmark result. We respond to the comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that AttnRes and ABC correction (plus the synthesis pipeline) produce the 77.2% benchmark accuracy rests solely on local validation scores recorded on the 10k-sample main set generated by the identical agent-driven and steerable pipeline. No ablation that isolates the contribution of each module, no held-out benchmark subset evaluation, and no distributional comparison between the local set and the test benchmark are described; therefore the attribution of the headline result to the three targeted failure modes remains untested.
Authors: The manuscript reports the 77.2% benchmark accuracy for the complete system (synthesis pipeline plus AttnRes and ABC correction with category-aware routing) and provides local validation scores on the 10k main set to characterize per-category performance. We agree that the current text does not contain module-isolating ablations, a distributional comparison between the main set and benchmark test distribution, or evaluation on a held-out benchmark subset. These omissions leave the precise attribution of the headline result to the targeted failure modes incompletely supported by the presented evidence. We will revise the manuscript to include ablations on the main set and an explicit discussion of how the steerable pipeline aligns with benchmark characteristics. revision: yes
- Evaluation on a held-out subset of the official benchmark test set cannot be performed locally, as benchmark organizers typically withhold test labels and full test distribution details from participants.
Circularity Check
No circularity; benchmark result is externally measured
full rationale
The headline 77.2% accuracy is reported on the external PointArena benchmark. Local validation numbers (93.9% Affordance etc.) are computed on the 10k-sample set produced by the synthesis pipeline and are used only for expert selection; they are not the source of the benchmark score. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the text. The derivation chain is therefore self-contained against an external benchmark.
Axiom & Free-Parameter Ledger
free parameters (1)
- main set size
Reference graph
Works this paper leans on
-
[1]
Cascade r-cnn: Delv- ing into high quality object detection
Zhaowei Cai and Nuno Vasconcelos. Cascade r-cnn: Delv- ing into high quality object detection. InIEEE Conf. Com- put. Vis. Pattern Recog., 2018. 3
2018
-
[2]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nico- las Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InEur . Conf. Comput. Vis., 2020. 2
2020
-
[3]
Smith, Fei Xia, Dieter Fox, and Ranjay Krishna
Long Cheng, Jiafei Duan, Yi Ru Wang, Haoquan Fang, Boyang Li, Yushan Huang, Elvis Wang, Ainaz Eftekhar, Jason Lee, Wentao Yuan, Rose Hendrix, Noah A. Smith, Fei Xia, Dieter Fox, and Ranjay Krishna. Pointarena: Probing multimodal grounding through language-guided pointing.arXiv preprint arXiv:2505.09990, 2025. 1, 2
-
[4]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pas- cale Fung, and Steven C. H. Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. InAdv. Neural Inform. Process. Syst., 2023. 2
2023
-
[5]
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tri- pathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, Jiasen Lu, Taira Anderson, Erin Bransom, Kiana Ehsani, et al. Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models.arXiv preprint arXiv:2409.17146, 2024. 1, 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Denoising dif- fusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. InAdv. Neural Inform. Pro- cess. Syst., 2020. 3
2020
-
[7]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language mod- els. InInt. Conf. Learn. Represent., 2022. 1, 3 4
2022
-
[8]
Berg, Wan-Yen Lo, Piotr Doll´ar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Doll´ar, and Ross Girshick. Segment anything. InInt. Conf. Com- put. Vis., 2023. 2, 3
2023
-
[9]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven C. H. Hoi. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Int. Conf. Mach. Learn., 2023. 2
2023
-
[10]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InAdv. Neural Inform. Process. Syst., 2023. 2
2023
-
[11]
Simple base- lines for human pose estimation and tracking
Bin Xiao, Haiping Wu, and Yichen Wei. Simple base- lines for human pose estimation and tracking. InEur . Conf. Comput. Vis., 2018. 3
2018
-
[12]
Florence-2: Advancing a unified representation for a variety of vision tasks, 2023
Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, and Lu Yuan. Florence-2: Advancing a unified representation for a va- riety of vision tasks.arXiv preprint arXiv:2311.06242,
-
[13]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
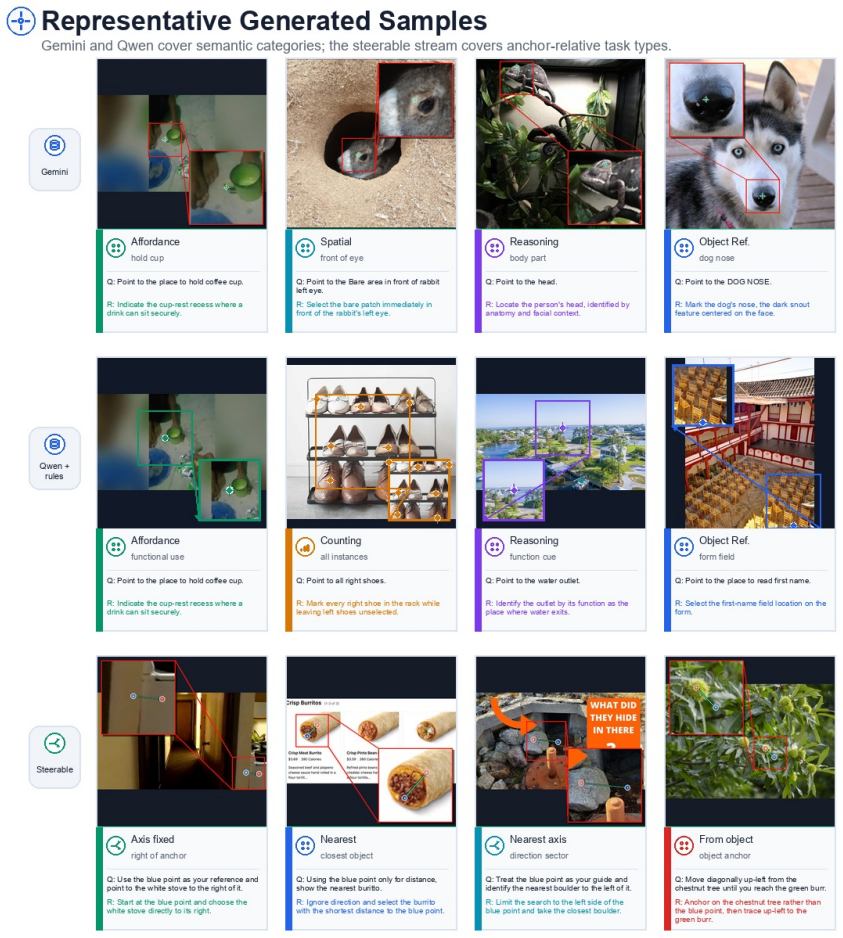
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chun- yuan Li, and Jianfeng Gao. Set-of-mark prompting un- leashes extraordinary visual grounding in gpt-4v.arXiv preprint arXiv:2310.11441, 2023. 2 5 Figure 2: Representative generated samples with the original question and category-specific restatement. In each panel,Qis the original pointing question attach...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.