Encoding Database Schemas with Relation-Aware Self-Attention for Text-to-SQL Parsers
Pith reviewed 2026-05-25 14:32 UTC · model grok-4.3
The pith
Relation-aware self-attention lets the encoder reason about table and column relations when turning questions into SQL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
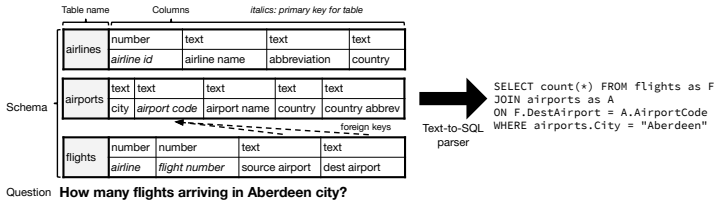
Relation-aware self-attention within the encoder enables reasoning about how the tables and columns in the provided schema relate to each other and uses this information when interpreting the question, reaching 42.94 percent exact match accuracy on Spider versus the 18.96 percent in prior published work.
What carries the argument
relation-aware self-attention, which augments standard self-attention to incorporate explicit relational information between schema elements during encoding.
If this is right
- The encoder can directly exploit foreign-key links and table connections instead of inferring them only from question wording.
- Exact-match performance rises on questions that span multiple tables in a schema.
- Generalization improves to database schemas and domains absent from the training set.
- No extra hand-crafted schema features are required beyond the relation labels supplied to the attention layer.
Where Pith is reading between the lines
- The same attention modification could be applied to other structured-input tasks such as semantic parsing over knowledge bases.
- Collecting training data with deliberately varied relation patterns might increase the method's robustness beyond what Spider provides.
- If the learned relations prove transferable, the approach could reduce the amount of schema-specific fine-tuning needed for new databases.
Load-bearing premise
The training examples supply enough different schema relations for the attention parameters to learn patterns that transfer to new schemas.
What would settle it
Accuracy on a held-out set of schemas whose relation types or combinations do not appear in the training distribution, where the reported gain over baseline encoders vanishes.
Figures


read the original abstract
When translating natural language questions into SQL queries to answer questions from a database, we would like our methods to generalize to domains and database schemas outside of the training set. To handle complex questions and database schemas with a neural encoder-decoder paradigm, it is critical to properly encode the schema as part of the input with the question. In this paper, we use relation-aware self-attention within the encoder so that it can reason about how the tables and columns in the provided schema relate to each other and use this information in interpreting the question. We achieve significant gains on the recently-released Spider dataset with 42.94% exact match accuracy, compared to the 18.96% reported in published work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes using relation-aware self-attention within the encoder of a text-to-SQL model so that the encoder can reason about relations among tables and columns in the input schema when interpreting the natural language question. It reports achieving 42.94% exact match accuracy on the Spider dataset, a substantial improvement over the 18.96% in prior published work.
Significance. If the experimental results hold, the work would establish that explicitly encoding schema relations via attention yields meaningful gains in cross-domain semantic parsing, directly addressing the challenge of generalizing to unseen database schemas.
major comments (2)
- [Abstract] Abstract: The central accuracy claim of 42.94% exact match is stated without any description of experimental details, baselines, data splits, error bars, or training protocol, so the reported gains cannot be verified from the provided text.
- [Experiments] Experiments section: The Spider test split only guarantees unseen databases, not unseen relation distributions (foreign-key graphs, join patterns, column-type co-occurrences). This leaves open the possibility that the model fits recurring training-schema motifs rather than learning transferable relational reasoning, which is the load-bearing premise of the generalization claim.
minor comments (1)
- The abstract would benefit from a one-sentence outline of the model architecture or the precise form of the relation-aware attention to give readers immediate context for the accuracy number.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, agreeing where the critique is valid and outlining specific revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central accuracy claim of 42.94% exact match is stated without any description of experimental details, baselines, data splits, error bars, or training protocol, so the reported gains cannot be verified from the provided text.
Authors: We agree that the abstract should provide sufficient context for the key result. In the revised version we will expand the abstract to briefly state that results are reported on the Spider development set using exact match accuracy, with comparison to the 18.96% baseline from prior published work, and that full experimental details (including data splits, training protocol, and model configuration) appear in the Experiments section. If error bars were computed they will be referenced; otherwise the abstract will note that the primary metric is exact match. revision: yes
-
Referee: [Experiments] Experiments section: The Spider test split only guarantees unseen databases, not unseen relation distributions (foreign-key graphs, join patterns, column-type co-occurrences). This leaves open the possibility that the model fits recurring training-schema motifs rather than learning transferable relational reasoning, which is the load-bearing premise of the generalization claim.
Authors: We acknowledge this limitation of the Spider benchmark: while databases are unseen, certain relational patterns may recur across train and test schemas. The 24-point absolute gain from adding relation-aware self-attention nevertheless provides evidence that the encoder benefits from explicit modeling of schema relations in a manner that improves generalization over prior approaches. We will add a short discussion paragraph noting this benchmark limitation and suggesting that future datasets with more controlled schema diversity would further isolate the contribution of relational reasoning. revision: yes
Circularity Check
No circularity: empirical result on external benchmark with no definitional reduction
full rationale
The paper presents a neural encoder-decoder model that augments self-attention with schema relation encodings and reports 42.94% exact-match accuracy on the Spider test split. No equations, fitted parameters, or uniqueness theorems are shown that would make the accuracy score equivalent to its training inputs by construction. The benchmark split, evaluation metric, and baseline comparison (18.96%) are externally defined and independent of the model's learned weights. No self-citation chains or ansatzes are invoked to justify core claims. The derivation is therefore self-contained as a standard empirical ML contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A large annotated semantic parsing corpus for developing natural language interfaces.: Salesforce/WikiSQL. Salesforce, March 2019. URL https://github.com/salesforce/ WikiSQL
work page 2019
-
[2]
Natural Language Interfaces to Databases - An Introduction
I. Androutsopoulos, G. D. Ritchie, and P. Thanisch. Natural Language Interfaces to Databases - An Introduction. arXiv:cmp-lg/9503016, March 1995. URL http://arxiv.org/abs/cmp- lg/9503016
work page internal anchor Pith review Pith/arXiv arXiv 1995
-
[3]
Coarse-to-Fine Decoding for Neural Semantic Parsing
Li Dong and Mirella Lapata. Coarse-to-Fine Decoding for Neural Semantic Parsing. arXiv:1805.04793 [cs], May 2018. URL http://arxiv.org/abs/1805.04793
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Kummerfeld, Li Zhang, Karthik Ramanathan, Sesh Sadasivam, Rui Zhang, and Dragomir Radev
Catherine Finegan-Dollak, Jonathan K. Kummerfeld, Li Zhang, Karthik Ramanathan, Sesh Sadasivam, Rui Zhang, and Dragomir Radev. Improving Text-to-SQL Evaluation Methodology. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 351–360. Association for Computational Linguistics, 2018. URL ...
work page 2018
-
[5]
A Theoretically Grounded Application of Dropout in Re- current Neural Networks
Yarin Gal and Zoubin Ghahramani. A Theoretically Grounded Application of Dropout in Re- current Neural Networks. In D. D. Lee, M. Sugiyama, U. V . Luxburg, I. Guyon, and R. Garnett, editors, Advances in Neural Information Processing Systems 29 , pages 1019–1027. Curran Associates, Inc., 2016. URL http://papers.nips.cc/paper/6241-a-theoretically- grounded-...
work page 2016
-
[6]
Learning a neural semantic parser from user feedback
Srinivasan Iyer, Ioannis Konstas, Alvin Cheung, Jayant Krishnamurthy, and Luke Zettlemoyer. Learning a neural semantic parser from user feedback. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 963–973, 2017. URL http://www.aclweb.org/anthology/P17-1089
work page 2017
-
[7]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A Method for Stochastic Optimization. arXiv:1412.6980 [cs], December 2014. URL http://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[8]
Fei Li and H. V . Jagadish. Constructing an interactive natural language interface for relational databases. Proceedings of the VLDB Endowment, 8(1):73–84, September 2014. URL http: //dx.doi.org/10.14778/2735461.2735468
-
[9]
Automatic differentiation in PyTorch
Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in PyTorch. October 2017. URL https://openreview.net/forum?id=BJJsrmfCZ
work page 2017
-
[10]
Towards a theory of natural language interfaces to databases
Ana-Maria Popescu, Oren Etzioni, , and Henry Kautz. Towards a theory of natural language interfaces to databases. In Proceedings of the 8th International Conference on Intelligent User Interfaces, pages 149–157, 2003. URL http://doi.acm.org/10.1145/604045.604070
-
[11]
Ana-Maria Popescu, Alex Armanasu, Oren Etzioni, David Ko, and Alexander Yates. Mod- ern Natural Language Interfaces to Databases: Composing Statistical Parsing with Semantic Tractability. In COLING 2004: Proceedings of the 20th International Conference on Computa- tional Linguistics, 2004. URL http://aclweb.org/anthology/C04-1021
work page 2004
-
[12]
Self-Attention with Relative Position Representations
Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. Self-Attention with Relative Position Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) , pages 464–468. Association for Computational Linguistics, 2018. doi: 10.18653/v1...
-
[13]
IncSQL: Training Incremental Text-to-SQL Parsers with Non-Deterministic Oracles
Tianze Shi, Kedar Tatwawadi, Kaushik Chakrabarti, Yi Mao, Oleksandr Polozov, and Weizhu Chen. IncSQL: Training Incremental Text-to-SQL Parsers with Non-Deterministic Oracles. arXiv:1809.05054 [cs], September 2018. URL http://arxiv.org/abs/1809.05054
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Lappoon R. Tang and Raymond J. Mooney. Automated construction of database interfaces: Intergrating statistical and relational learning for semantic parsing. In 2000 Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora, pages 133–141, 2000. URL http://www.aclweb.org/anthology/W00-1317. 9
work page 2000
-
[15]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is All you Need. In I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems 30, pages 5998–6008. Curran Associates, Inc., 2017....
work page 2017
-
[16]
SQLNet: Generating Structured Queries From Natural Language Without Reinforcement Learning
Xiaojun Xu, Chang Liu, and Dawn Song. SQLNet: Generating Structured Queries From Natural Language Without Reinforcement Learning. arXiv:1711.04436 [cs], November 2017. URL http://arxiv.org/abs/1711.04436
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Sqlizer: Query synthesis from natural language
Navid Yaghmazadeh, Yuepeng Wang, Isil Dillig, , and Thomas Dillig. Sqlizer: Query synthesis from natural language. In International Conference on Object-Oriented Programming, Systems, Languages, and Applications, ACM, pages 63:1–63:26, October 2017. URL http://doi.org/ 10.1145/3133887
-
[18]
A Syntactic Neural Model for General-Purpose Code Generation
Pengcheng Yin and Graham Neubig. A Syntactic Neural Model for General-Purpose Code Generation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 440–450. Association for Computational Linguistics,
-
[19]
URL http://aclweb.org/anthology/P17-1041
doi: 10.18653/v1/P17-1041. URL http://aclweb.org/anthology/P17-1041
-
[20]
TypeSQL: Knowledge-Based Type-Aware Neural Text-to-SQL Generation
Tao Yu, Zifan Li, Zilin Zhang, Rui Zhang, and Dragomir Radev. TypeSQL: Knowledge-Based Type-Aware Neural Text-to-SQL Generation. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 588–594. Association for Computational Linguis- ti...
-
[21]
SyntaxSQLNet: Syntax Tree Networks for Complex and Cross-Domain Text-to-SQL Task
Tao Yu, Michihiro Yasunaga, Kai Yang, Rui Zhang, Dongxu Wang, Zifan Li, and Dragomir Radev. SyntaxSQLNet: Syntax Tree Networks for Complex and Cross-Domain Text-to-SQL Task. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1653–1663. Association for Computational Linguistics, 2018. URL http: //aclweb.org/ant...
work page 2018
-
[22]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing,...
work page 2018
-
[23]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing,...
work page 2018
-
[24]
John M. Zelle and Raymond J. Mooney. Learning to parse database queries using inductive logic programming. In Proceedings of the Thirteenth National Conference on Artificial Intelligence - Volume 2, pages 1050–1055, 1996. URL http://dl.acm.org/citation.cfm?id=1864519. 1864543
work page 1996
-
[25]
Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning
Victor Zhong, Caiming Xiong, and Richard Socher. Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning. arXiv:1709.00103 [cs], August 2017. URL http://arxiv.org/abs/1709.00103. 10
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.