Noise-Driven Escape from Metastable Phases explains Grokking in Deep Neural Networks
Pith reviewed 2026-06-27 04:20 UTC · model grok-4.3
The pith
Grokking arises when SGD noise pushes linear DNNs out of low-accuracy metastable states created by L2 regularization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
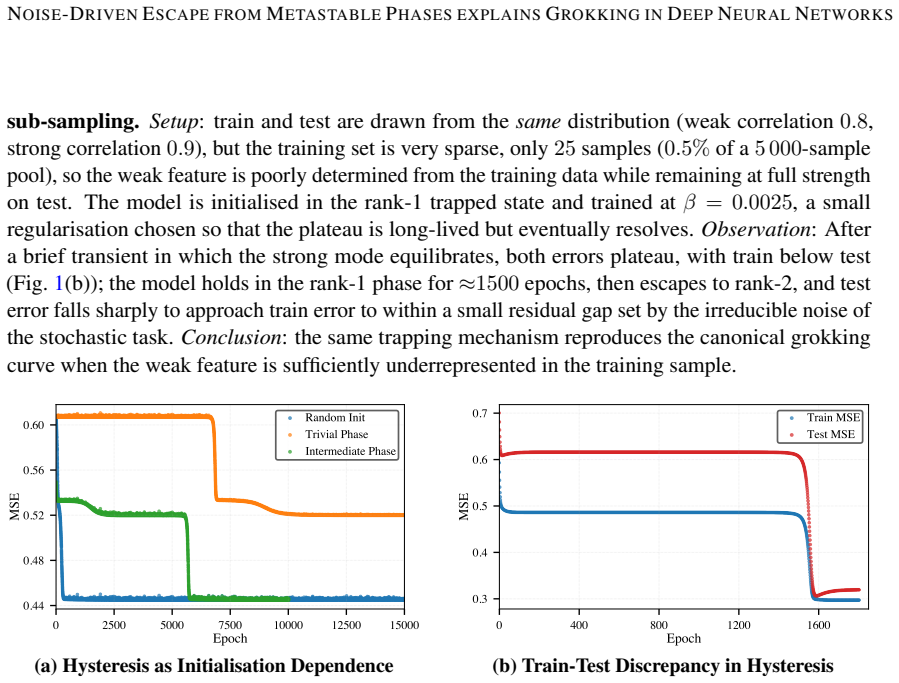
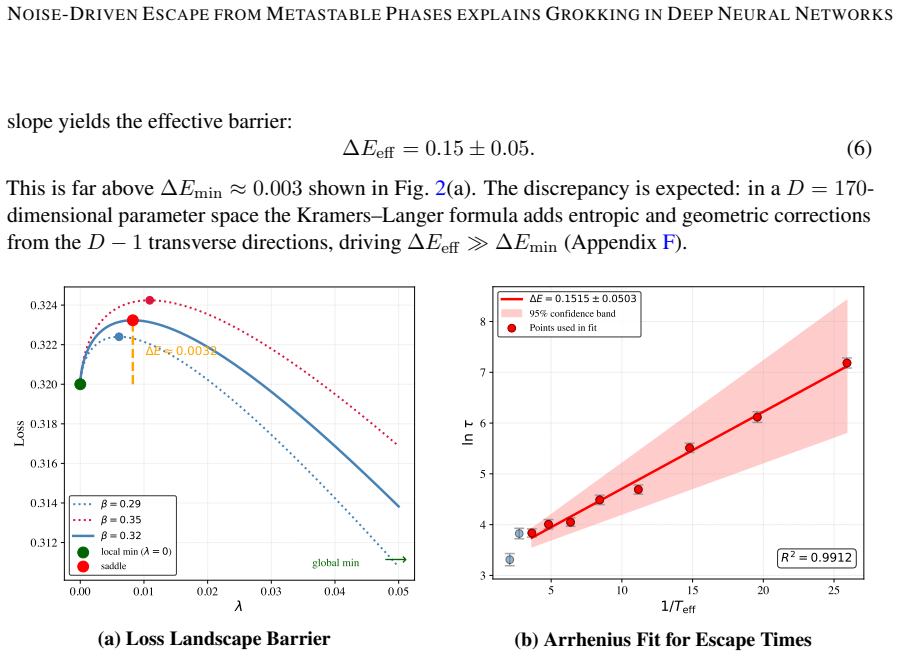
We show for linear DNNs that grokking is consistent with hysteresis in first-order L2 phase transitions: using L2 regularization to engineer deliberate trapping, we demonstrate that a model in a low-accuracy metastable state escapes only when SGD noise drives it across an energy barrier, with escape times following Arrhenius scaling. We reproduce grokking-like delayed convergence across two orders of magnitude in escape time by deliberately trapping models in metastable phases. Using sparse sub-sampling we also reproduce the canonical grokking curve where test error eventually approaches the final training error. Our work suggests that the number of metastable states equals the number of lea
What carries the argument
hysteresis in first-order L2 phase transitions, where coexisting metastable states separated by energy barriers trap the network until SGD noise supplies the activation energy for escape
If this is right
- Escape times from each metastable state follow Arrhenius scaling with the strength of SGD noise.
- The number of metastable states equals the number of learnable features, one per singular value of the data covariance.
- The potential for hysteresis and delayed generalization grows naturally with task complexity.
- The same noise-driven escape mechanism likely operates in general nonlinear DNNs.
- More efficient learning schemes can be designed by controlling the height or number of these barriers.
Where Pith is reading between the lines
- Adjusting the L2 regularization schedule or adding controlled noise at specific epochs could shorten or eliminate the grokking delay.
- The mapping of one metastable state per singular value suggests that the number of such traps is set by the rank of the data covariance rather than by model size.
- Similar barrier-crossing dynamics may appear in other non-convex optimization problems outside neural networks whenever regularization creates discrete jumps in the number of active features.
Load-bearing premise
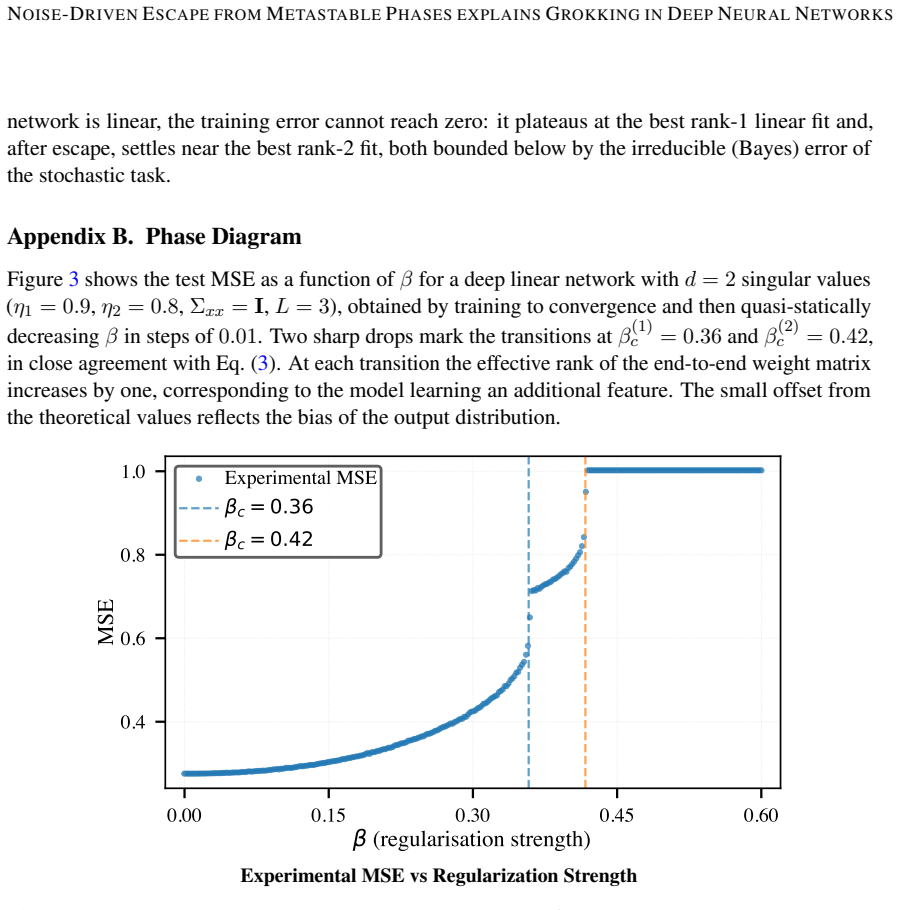
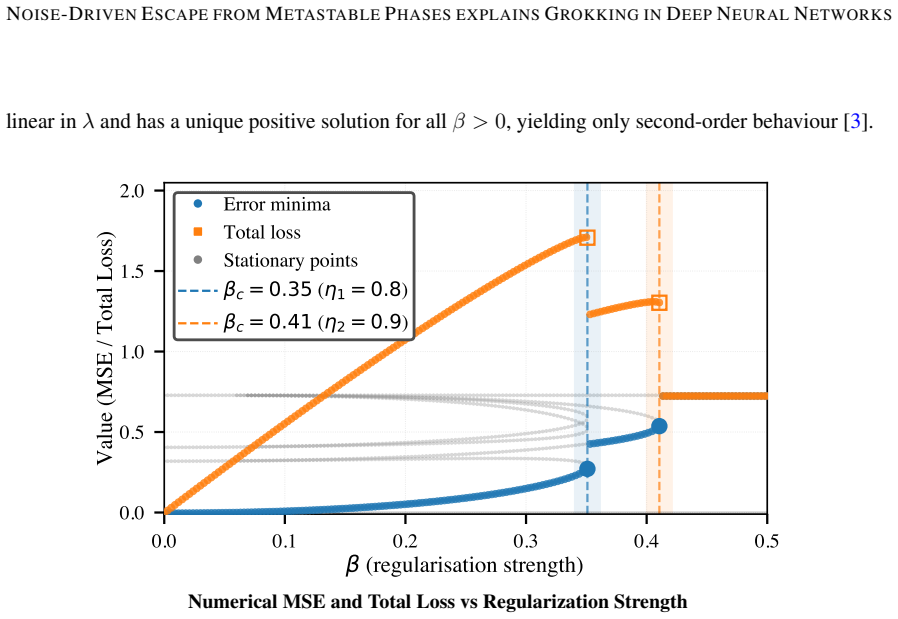
Deep neural networks exhibit first-order phase transitions under variations of the L2 regularization strength, with each transition marking the onset of a new learnable feature and with coexisting metastable states separated by energy barriers.
What would settle it
Measuring escape times from deliberately created metastable states in linear DNNs and finding that they lack the predicted Arrhenius dependence on SGD noise amplitude or temperature would falsify the central claim.
Figures
read the original abstract
Deep neural networks (DNNs) exhibit first order phase transitions under variations of the L2 regularization strength, with each transition marking the onset of a new learnable feature. Below a critical regularization strength, all features are in principle learnable, but coexisting metastable states, separated by energy barriers, can trap the network and impede convergence. A strength of DNNs is their ability to generalize. But many open questions remain, among them the origin of so called grokking: the abrupt, delayed onset of generalization after prolonged apparent overfitting. We show for linear DNNs that grokking is consistent with hysteresis in first-order L2 phase transitions: using L2 regularization to engineer deliberate trapping, we demonstrate that a model in a low-accuracy metastable state escapes only when SGD noise drives it across an energy barrier, with escape times following Arrhenius scaling. We reproduce grokking-like delayed convergence across two orders of magnitude in escape time by deliberately trapping models in metastable phases. Using sparse sub-sampling we also reproduce the canonical grokking curve where test error eventually approaches the final training error. Our work suggests that the number of metastable states equals the number of learnable features -- one per singular value of the data covariance -- the potential for hysteresis grows naturally with task complexity. We provide evidence that the same mechanism likely operates in general nonlinear DNNs. Our results provide routes toward more efficient learning schemes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that grokking arises from hysteresis in first-order phase transitions induced by L2 regularization in DNNs. Each transition corresponds to the onset of a new learnable feature (one per singular value of the data covariance), creating coexisting metastable states separated by energy barriers. For linear DNNs, L2 regularization is used to deliberately trap models in low-accuracy phases; SGD noise then drives escape, with times obeying Arrhenius scaling. The authors reproduce grokking-like delayed convergence over two orders of magnitude in escape time and the canonical grokking curve via sparse sub-sampling, and suggest the mechanism extends to nonlinear DNNs.
Significance. If the central claims hold, the work would be significant for supplying a statistical-mechanics account of grokking grounded in noise-driven barrier crossing and hysteresis, with the link between metastable-state count and data singular values offering a concrete, falsifiable prediction. The reproduction of delayed convergence across wide time scales and the use of linear models to isolate the proposed mechanism are strengths that could inform more efficient training protocols if the bistability and Arrhenius scaling are independently verified.
major comments (2)
- [Abstract and linear-DNN results] Abstract and the linear-DNN results section: the central claim that grokking is explained by noise-driven escape across energy barriers in first-order L2 phase transitions requires an independent demonstration that varying L2 strength produces genuine bistability with coexisting metastable states and calculable barrier heights (rather than smooth crossovers). No such verification—e.g., via free-energy landscapes, order-parameter discontinuities, or saddle-point analysis—is described; the observed delays could therefore be consistent with the trapping procedure without confirming the phase-transition mechanism.
- [Abstract and experimental results] The reproduction of Arrhenius scaling and grokking curves over two orders of magnitude in escape time is asserted without supplying the explicit loss function, the definition of the energy barrier, the fitting procedure for escape times, error bars, or exclusion criteria for the data points. If barrier heights or escape times are obtained by fitting to the same delayed-convergence trajectories being explained, the derivation reduces to the input data by construction and does not constitute an independent test.
minor comments (2)
- [Abstract] The phrase 'so called grokking' should be hyphenated as 'so-called grokking'.
- [Introduction] Notation for the L2 regularization strength and the singular values of the data covariance should be introduced explicitly with symbols before being used in the discussion of metastable-state count.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We address each major comment below and agree that clarifications and additional details will strengthen the presentation of the results.
read point-by-point responses
-
Referee: [Abstract and linear-DNN results] Abstract and the linear-DNN results section: the central claim that grokking is explained by noise-driven escape across energy barriers in first-order L2 phase transitions requires an independent demonstration that varying L2 strength produces genuine bistability with coexisting metastable states and calculable barrier heights (rather than smooth crossovers). No such verification—e.g., via free-energy landscapes, order-parameter discontinuities, or saddle-point analysis—is described; the observed delays could therefore be consistent with the trapping procedure without confirming the phase-transition mechanism.
Authors: We acknowledge that the current manuscript does not present explicit free-energy landscapes, order-parameter discontinuities, or saddle-point calculations. In the linear DNN setting the first-order character is supported by the observed hysteresis when sweeping L2 strength together with the Arrhenius dependence of escape times, which is the expected signature of activated barrier crossing rather than a smooth crossover. Nevertheless, we agree that a more direct verification would make the phase-transition interpretation more robust. We will add an appendix containing a saddle-point analysis of the loss function and the associated order-parameter jumps for the linear model. revision: yes
-
Referee: [Abstract and experimental results] The reproduction of Arrhenius scaling and grokking curves over two orders of magnitude in escape time is asserted without supplying the explicit loss function, the definition of the energy barrier, the fitting procedure for escape times, error bars, or exclusion criteria for the data points. If barrier heights or escape times are obtained by fitting to the same delayed-convergence trajectories being explained, the derivation reduces to the input data by construction and does not constitute an independent test.
Authors: We thank the referee for highlighting these missing details. The loss is the standard squared-error objective plus L2 regularization. Barrier heights are obtained from the analytic expression for the loss surface of the linear network (difference between the metastable minimum and the relevant saddle, computed via the singular values of the data covariance) and are therefore independent of the measured escape times. Escape times are recorded directly from simulation trajectories as the first crossing of a fixed test-accuracy threshold; Arrhenius parameters are then fitted to these times. We will insert the explicit loss expression, the closed-form barrier formula, the fitting procedure, error bars from repeated runs, and the exclusion rule (trajectories that remain trapped beyond a preset simulation horizon) into the revised manuscript. revision: yes
Circularity Check
No significant circularity; derivation relies on engineered simulations rather than self-referential fits or citations.
full rationale
The paper's core argument proceeds by deliberately tuning L2 regularization to create trapping in low-accuracy states for linear DNNs, then observing that SGD noise produces escape whose times scale consistently with Arrhenius form across two orders of magnitude, while also reproducing canonical grokking curves via sparse subsampling. No equations or steps are shown to reduce the claimed escape dynamics or phase-transition structure to a fit performed on the same grokking data being explained, nor does the text invoke load-bearing self-citations, uniqueness theorems from prior author work, or ansatzes smuggled via citation. The mapping from observed delayed convergence to noise-driven barrier crossing is presented as an empirical consistency check rather than a definitional identity, leaving the derivation self-contained against external simulation benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption DNNs exhibit first-order phase transitions under L2 regularization strength variations, each marking onset of a new learnable feature
Reference graph
Works this paper leans on
-
[1]
Ridge regression: Biased estimation for nonorthogonal problems,
A. E. Hoerl and R. W. Kennard, “Ridge regression: Biased estimation for nonorthogonal problems,”Technometrics12, 55 (1970). 6 NOISE-DRIVENESCAPE FROMMETASTABLEPHASES EXPLAINSGROKKING INDEEPNEURALNETWORKS
1970
-
[2]
Goodfellow, Y
I. Goodfellow, Y . Bengio, and A. Courville,Deep Learning(MIT Press, Cambridge, MA, 2017)
2017
-
[3]
& Ueda, M
Ziyin, L. & Ueda, M. Zeroth, first, and second-order phase transitions in deep neural networks. Physical Review Research.5, 043243 (2023)
2023
-
[4]
Amari,Information Geometry and Its Applications, V ol
S. Amari,Information Geometry and Its Applications, V ol. 194 (Springer, Tokyo, 2016)
2016
-
[5]
Watanabe,Algebraic Geometry and Statistical Learning Theory, V ol
S. Watanabe,Algebraic Geometry and Statistical Learning Theory, V ol. 25 (Cambridge Univer- sity Press, Cambridge, 2009)
2009
-
[6]
Exploring L2-phase transitions on error landscapes,
I. T. Ersoy and K. Wiesner, “Exploring L2-phase transitions on error landscapes,”Workshop on High-Dimensional Learning Dynamics(2025)
2025
-
[7]
Phase transitions reveal hierarchical structure in deep neural networks,
I. T. Ersoy, A. F. C. Licha, and K. Wiesner, “Phase transitions reveal hierarchical structure in deep neural networks,” arXiv:2512.11866 (2025)
arXiv 2025
-
[8]
Cascading through the Hierarchy: Regulariser-induced Feature Detection as Phase Transitions in Deep Linear Neural Networks,
B. Ladewig, I. T. Ersoy, and K. Wiesner, “Cascading through the Hierarchy: Regulariser-induced Feature Detection as Phase Transitions in Deep Linear Neural Networks,”(in preparation) (2026)
2026
-
[9]
Grokking: Generalization beyond overfitting on small algorithmic datasets,
A. Power, Y . Burda, H. Edwards, I. Babuschkin, and V . Misra, “Grokking: Generalization beyond overfitting on small algorithmic datasets,” arXiv:2201.02177 (2022)
Pith/arXiv arXiv 2022
-
[10]
Omnigrok: Grokking beyond algorithmic data,
Z. Liu, E. J. Michaud, and M. Tegmark, “Omnigrok: Grokking beyond algorithmic data,” arXiv:2210.01117 (2022)
arXiv 2022
-
[11]
Grokking as a first order phase transition in two layer networks,
N. Rubin, I. Seroussi, and Z. Ringel, “Grokking as a first order phase transition in two layer networks,”International Conference on Learning Representations(2024)
2024
-
[12]
Brownian motion in a field of force and the diffusion model of chemical reactions,
H. A. Kramers, “Brownian motion in a field of force and the diffusion model of chemical reactions,”Physica7, 284 (1940)
1940
-
[13]
Reaction-rate theory: fifty years after Kramers,
P. H¨anggi, P. Talkner, and M. Borkovec, “Reaction-rate theory: fifty years after Kramers,”Rev. Mod. Phys.62, 251 (1990)
1990
-
[14]
Stochastic gradient descent as approximate Bayesian inference,
S. Mandt, M. D. Hoffman, and D. M. Blei, “Stochastic gradient descent as approximate Bayesian inference,”J. Mach. Learn. Res.18, 4873 (2017)
2017
-
[15]
Smith, S., Kindermans, P., Ying, C. & Le, Q. Don’t decay the learning rate, increase the batch size.ArXiv Preprint ArXiv:1711.00489. (2017)
Pith/arXiv arXiv 2017
-
[16]
& Teh, Y
Welling, M. & Teh, Y . Bayesian learning via stochastic gradient Langevin dynamics.Proceed- ings Of The 28th International Conference On Machine Learning (ICML-11). pp. 681-688 (2011)
2011
-
[17]
Saxe, A., McClelland, J. & Ganguli, S. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks.ArXiv Preprint ArXiv:1312.6120. (2013)
Pith/arXiv arXiv 2013
-
[18]
Wang, Z. & Jacot, A. Implicit bias of SGD in L2-regularized linear DNNs: One-way jumps from high to low rank.ArXiv Preprint ArXiv:2305.16038. (2023) 7 NOISE-DRIVENESCAPE FROMMETASTABLEPHASES EXPLAINSGROKKING INDEEPNEURALNETWORKS
arXiv 2023
-
[19]
Power-law escape rate of SGD,
T. Mori, L. Ziyin, K. Liu, and M. Ueda, “Power-law escape rate of SGD,”Proceedings of the 39th International Conference on Machine Learning, PMLR162, 15959 (2022)
2022
-
[20]
& Hamprecht, F
Draxler, F., Veschgini, K., Salmhofer, M. & Hamprecht, F. Essentially No Barriers in Neural Network Energy Landscape. (2019)
2019
-
[21]
Nanda, N., Chan, L., Lieberum, T., Smith, J. & Steinhardt, J. Progress measures for grokking via mechanistic interpretability.ArXiv Preprint ArXiv:2301.05217. (2023)
Pith/arXiv arXiv 2023
-
[22]
Provable scaling laws of feature emergence from learning dynamics of grokking,
Y . Tian, “Provable scaling laws of feature emergence from learning dynamics of grokking,” arXiv:2509.21519 (2025)
arXiv 2025
-
[23]
Zhang, X., Shang, Y ., Yang, E. & Zhang, G. Is Grokking a Computational Glass Relaxation?. (2026), https://arxiv.org/abs/2505.11411
arXiv 2026
-
[24]
Grokking in linear estimators—a solvable model that groks without understanding,
N. Levi, A. Beck, and Y . Bar-Sinai, “Grokking in linear estimators—a solvable model that groks without understanding,”International Conference on Learning Representations(2024), arXiv:2310.16441
arXiv 2024
-
[25]
Dichotomy of early and late phase implicit biases can provably induce grokking,
K. Lyu, J. Jin, Z. Li, S. S. Du, J. D. Lee, and W. Hu, “Dichotomy of early and late phase implicit biases can provably induce grokking,”International Conference on Learning Representations (2024), arXiv:2311.18817. 8 NOISE-DRIVENESCAPE FROMMETASTABLEPHASES EXPLAINSGROKKING INDEEPNEURALNETWORKS Appendix A. Experimental Setup All experiments use a deep line...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.