Small Data, Big Noise: Adversarial Training for Robust Parameter-Efficient Fine-Tuning
Pith reviewed 2026-06-27 13:18 UTC · model grok-4.3
The pith
A framework called SDBN integrates adversarial training into parameter-efficient fine-tuning to improve robustness and generalization on limited noisy data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SDBN brings adversarial training to PEFT by optimizing over discrete uncertainty sets of input variants, where SDBN-h selects gradient-chosen character-level edits and SDBN-p uses LLM-generated variants, yielding better robustness and generalization than standard PEFT without extra parameters.
What carries the argument
The SDBN framework, which performs robust optimization over discrete uncertainty sets of adversarial input variants during PEFT training.
If this is right
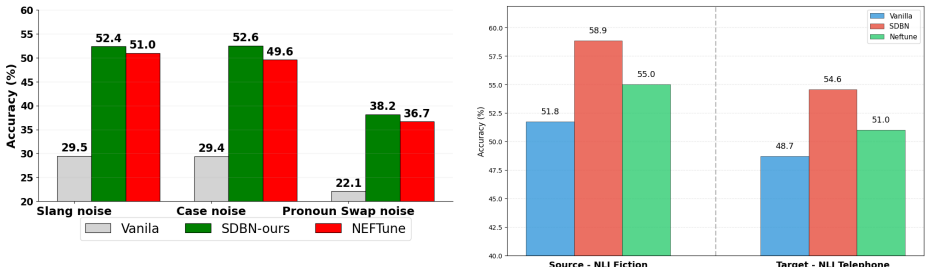
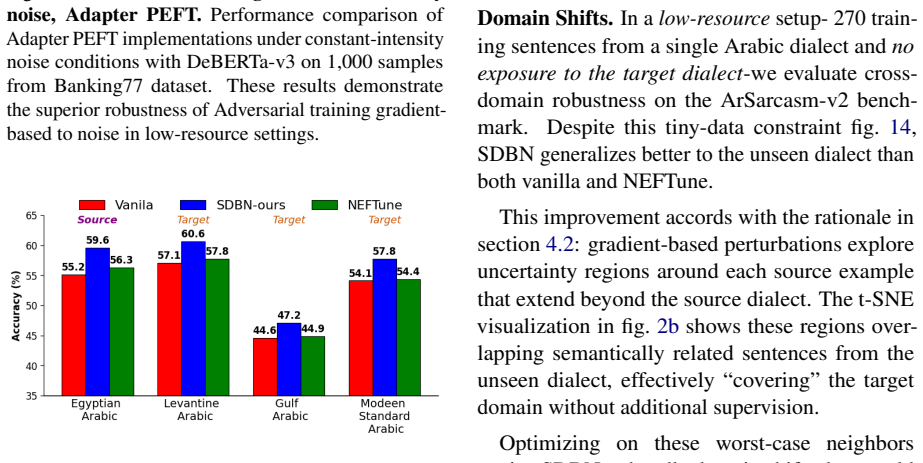
- Performance gains are largest in low-resource settings and under word-level or character-level corruptions.
- The method works for both classification and generative tasks via the two variants.
- No additional model parameters are introduced.
- Computational overhead remains modest compared to standard PEFT.
Where Pith is reading between the lines
- The same discrete-set approach could be tested on modalities beyond text if similar uncertainty sets can be defined.
- Combining SDBN with existing data-augmentation techniques might compound the robustness effect.
- Deployment in production systems with unpredictable user input could be more reliable if the uncertainty sets match actual error patterns.
Load-bearing premise
The chosen character edits and LLM-generated variants represent enough real-world noise to deliver actual robustness gains.
What would settle it
Testing SDBN-trained models on noise distributions outside the character-edit and LLM-variant sets shows the reported robustness improvements disappear or reverse.
Figures



read the original abstract
Parameter-Efficient Fine-Tuning (PEFT) has become essential for adapting foundation models to downstream NLP tasks. However, current PEFT methods often struggle with robustness to noise and performance degradation on limited training data. We propose SDBN (Small Data Big Noise), a unified framework that brings adversarial training to PEFT - a combination that remains less studied in the PEFT setting despite its complementary strengths - to enhance model robustness and generalization, outperforming alternative approaches. We also introduce two variants of the method that use discrete uncertainty sets: SDBN-h, which enumerates character-level edits and selects worst-case variants using gradients, and SDBN-p, which uses LLM-generated variants for robust optimization in generative tasks. Experiments across multiple benchmarks reveal substantial improvements, particularly in low-resource settings and under both word-level and character-level corruptions. This framework addresses the less explored intersection of adversarial training and parameter-efficient adaptation, without introducing additional parameters or only modest computational overhead, making PEFT deployments more reliable in real-world scenarios where data scarcity and linguistic variability often coexist
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SDBN, a unified framework that applies adversarial training to parameter-efficient fine-tuning (PEFT) methods. It introduces two variants using discrete uncertainty sets: SDBN-h (gradient-selected character-level edits) and SDBN-p (LLM-generated variants) for robust optimization, claiming substantial improvements in robustness and generalization on NLP benchmarks under word- and character-level noise, especially in low-resource settings, with no or modest additional parameters or overhead.
Significance. If the empirical claims hold after proper validation, the work would address a practically important gap at the intersection of adversarial training and PEFT, potentially improving reliability of adapted models in noisy, data-scarce deployments. The emphasis on parameter efficiency and modest overhead is a positive aspect for real-world applicability.
major comments (2)
- [Abstract] Abstract: the central claim of 'substantial improvements' and 'outperforming alternative approaches' is asserted without any quantitative results, baseline comparisons, effect sizes, or experimental details, preventing assessment of whether the data support the robustness claims.
- [SDBN-h and SDBN-p] Description of SDBN-h and SDBN-p: the robustness gains rest on the assumption that the discrete uncertainty sets (gradient-selected character edits in SDBN-h; LLM-generated variants in SDBN-p) represent real-world noise distributions. No validation against held-out noise distributions or ablation of post-hoc choices in variant generation is reported, which is load-bearing for the outperformance claims under corruptions.
minor comments (2)
- [Abstract] The title and abstract introduce SDBN without immediately clarifying that it stands for 'Small Data Big Noise'.
- Notation for the two variants (SDBN-h, SDBN-p) is introduced without an explicit table or diagram contrasting their uncertainty-set construction and optimization procedures.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'substantial improvements' and 'outperforming alternative approaches' is asserted without any quantitative results, baseline comparisons, effect sizes, or experimental details, preventing assessment of whether the data support the robustness claims.
Authors: The abstract serves as a high-level overview, while the manuscript's experimental section details the quantitative results, baseline comparisons, and effect sizes across NLP benchmarks under noise conditions. To better support the claims in the abstract, we will revise it to include specific quantitative highlights from our experiments. revision: yes
-
Referee: [SDBN-h and SDBN-p] Description of SDBN-h and SDBN-p: the robustness gains rest on the assumption that the discrete uncertainty sets (gradient-selected character edits in SDBN-h; LLM-generated variants in SDBN-p) represent real-world noise distributions. No validation against held-out noise distributions or ablation of post-hoc choices in variant generation is reported, which is load-bearing for the outperformance claims under corruptions.
Authors: Our uncertainty sets are designed based on prevalent noise types in real-world NLP data, with SDBN-h targeting character-level edits common in typos and SDBN-p capturing generative variations. The reported experiments evaluate robustness on held-out test sets with injected word- and character-level corruptions, providing evidence for the claims. We recognize the value of additional validation using independent real-world noise datasets and ablations on variant generation choices. We will incorporate these in the revised version to strengthen the manuscript. revision: yes
Circularity Check
No circularity detected in derivation or claims
full rationale
The paper presents SDBN as an empirical framework proposal combining adversarial training with PEFT, supported by benchmark experiments on robustness under noise. No equations, derivations, or parameter-fitting steps are described that reduce by construction to the inputs (e.g., no fitted uncertainty sets renamed as predictions, no self-definitional relations, and no load-bearing self-citations invoked as uniqueness theorems). The method variants (SDBN-h/p) are defined explicitly via gradient selection and LLM generation, with performance claims resting on external validation rather than internal tautology. This is a standard non-circular empirical proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LoRA: Low-Rank Adaptation of Large Language Models
Edward Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , title =. arXiv preprint arXiv:2106.09685 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
MEL o RA : M ini- E nsemble L ow- R ank A dapters for P arameter- E fficient F ine- T uning
Ren, Pengjie and Shi, Chengshun and Wu, Shiguang and Zhang, Mengqi and Ren, Zhaochun and de Rijke, Maarten and Chen, Zhumin and Pei, Jiahuan. MEL o RA : M ini- E nsemble L ow- R ank A dapters for P arameter- E fficient F ine- T uning. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi...
-
[3]
International Conference on Learning Representations (ICLR) , year =
Qingru Zhang and Minshuo Chen and Alexander Bukharin and Nikos Karampatziakis and Pengcheng He and Yu Cheng and Weizhu Chen and Tuo Zhao , title =. International Conference on Learning Representations (ICLR) , year =
-
[4]
QLoRA: Efficient Finetuning of Quantized LLMs
Tim Dettmers and Artidoro Pagnoni and Ari Holtzman and Luke Zettlemoyer , title =. arXiv preprint arXiv:2305.14314 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2404.13425 , year =
Yuheng Ji and Yue Liu and Zhicheng Zhang and Zhao Zhang and Yuting Zhao and Gang Zhou and Xingwei Zhang and Xinwang Liu and Xiaolong Zheng , title =. arXiv preprint arXiv:2404.13425 , year =
-
[6]
2024 , pages=
Fu, Jiadong and Fang, Jiang and Sun, Jiyan and Zhuang, Shangyuan and Geng, Liru and Liu, Yinlong , booktitle=. 2024 , pages=
2024
-
[7]
International Conference on Learning Representations (ICLR) , year =
Chen Zhu and Yu Cheng and Zhe Gan and Siqi Sun and Tom Goldstein and Jingjing Liu , title =. International Conference on Learning Representations (ICLR) , year =
-
[8]
Understanding adversarial training:. Neurocomputing , volume =. 2018 , issn =. doi:https://doi.org/10.1016/j.neucom.2018.04.027 , url =
-
[9]
2021 , organization=
Ben-Zaken, Elad and Ravfogel, Shauli and Goldberg, Yoav , booktitle=. 2021 , organization=
2021
-
[10]
2019 , organization=
Houlsby, Neil and Giurgiu, Andrei and Jastrzebski, Stanisław and Morrone, Bruna and de Laroussilhe, Quentin and Gesmundo, Andrea and Attariyan, Mona and Gelly, Sylvain , booktitle=. 2019 , organization=
2019
-
[11]
Kim, Yeachan and Kim, Junho and Lee, SangKeun , booktitle=. Towards. 2024 , organization=
2024
-
[12]
Towards Deep Learning Models Resistant to Adversarial Attacks
Towards deep learning models resistant to adversarial attacks , author=. arXiv preprint arXiv:1706.06083 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
International Conference on Learning Representations (ICLR) , year =
Explaining and Harnessing Adversarial Examples , author =. International Conference on Learning Representations (ICLR) , year =
-
[14]
Robust Optimization , author =
-
[15]
arXiv preprint arXiv:2003.04807 , year =
Iñigo Casanueva and Tadas Temčinas and Daniela Gerz and Matthew Henderson and Ivan Vulić , title =. arXiv preprint arXiv:2003.04807 , year =
-
[16]
Proceedings of the Eighth Text REtrieval Conference (TREC-8) , year =
Amit Singhal and Steve Abney and Michiel Bacchiani and Michael Collins and Donald Hindle and Fernando Pereira , title =. Proceedings of the Eighth Text REtrieval Conference (TREC-8) , year =
-
[17]
1995 , booktitle =
Ken Lang , title =. 1995 , booktitle =
1995
-
[18]
Convex optimization , author=
-
[19]
Preprint , year=
NEFTune: Noisy Embeddings Improve Instruction Finetuning , author=. Preprint , year=
-
[20]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Towards Robust and Generalized Parameter-Efficient Fine-Tuning for Noisy Label Learning , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2024 , organization=
2024
-
[21]
arXiv preprint arXiv:2110.07602 , year =
P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks , author =. arXiv preprint arXiv:2110.07602 , year =
-
[22]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Prefix-Tuning: Optimizing Continuous Prompts for Generation , author =. arXiv preprint arXiv:2101.00190 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
2019 , url=
Jiang, Haoming and He, Pengcheng and Chen, Weizhu and Liu, Xiaodong and Gao, Jianfeng and Zhao, Tuo , journal=. 2019 , url=
2019
-
[24]
2021 , url=
Miyato, Takeru and Dai, Andrew M and Goodfellow, Ian , journal=. 2021 , url=
2021
-
[25]
Proceedings of the 25th International Conference on Machine Learning (ICML 2008) , pages =
Extracting and Composing Robust Features with Denoising Autoencoders , author =. Proceedings of the 25th International Conference on Machine Learning (ICML 2008) , pages =. 2008 , url =
2008
-
[26]
Proceedings of the Workshop on Understanding Foundation Models at ICLR , year =
Empirical Analysis of the Strengths and Weaknesses of PEFT Techniques for LLMs , author =. Proceedings of the Workshop on Understanding Foundation Models at ICLR , year =
-
[27]
Overview of the WANLP 2021 Shared Task on Sarcasm and Sentiment Detection in Arabic
Abu Farha, Ibrahim and Zaghouani, Wajdi and Magdy, Walid. Overview of the WANLP 2021 Shared Task on Sarcasm and Sentiment Detection in Arabic. Proceedings of the Sixth Arabic Natural Language Processing Workshop. 2021
2021
-
[28]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author =. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages =
2019
-
[29]
He, Pengcheng and Gao, Jianfeng and Chen, Weizhu , booktitle =
-
[30]
SQuAD: 100,000+ Questions for Machine Comprehension of Text
Pranav Rajpurkar and Jian Zhang and Konstantin Lopyrev and Percy Liang , title =. arXiv preprint arXiv:1606.05250 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Proceedings of the GEMS 2011 Workshop on Geometrical Models of Natural Language Semantics, EMNLP 2011 , pages =
Marco Baroni and Alessandro Lenci , title =. Proceedings of the GEMS 2011 Workshop on Geometrical Models of Natural Language Semantics, EMNLP 2011 , pages =. 2011 , address =
2011
-
[32]
Neural Information Processing (ICONIP 2019) , series=
Models in the Wild: On Corruption Robustness of Neural NLP Systems , author=. Neural Information Processing (ICONIP 2019) , series=. 2019 , url=
2019
-
[33]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL) , year=
Combating Adversarial Misspellings with Robust Word Recognition , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL) , year=
-
[34]
2018 , url=
Ebrahimi, Javid and Rao, Anyi and Lowd, Daniel and Dou, Dejing , booktitle=. 2018 , url=
2018
-
[35]
Findings of the Association for Computational Linguistics: ACL 2022 , year=
Improving Zero-Shot Cross-lingual Transfer Between Closely Related Languages by Injecting Character-Level Noise , author=. Findings of the Association for Computational Linguistics: ACL 2022 , year=
2022
-
[36]
arXiv preprint arXiv:1901.11196 , year =
Jason Wei and Kai Zou , title =. arXiv preprint arXiv:1901.11196 , year =
-
[37]
2025 , month = dec, howpublished =
Update to. 2025 , month = dec, howpublished =
2025
-
[38]
The. arXiv preprint arXiv:2407.21783 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
arXiv preprint arXiv:1911.12237 , year =
Gliwa, Bogdan and Mochol, Iwona and Biesek, Maciej and Wawer, Aleksander , title =. arXiv preprint arXiv:1911.12237 , year =
-
[40]
Computational Linguistics , volume =
Jiehang Zeng and Jianhan Xu and Xiaoqing Zheng and Xuanjing Huang , title =. Computational Linguistics , volume =. 2023 , url =
2023
-
[41]
Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (
Po-Sen Huang and Robert Stanforth and Johannes Welbl and Chris Dyer and Dani Yogatama and Sven Gowal and Krishnamurthy Dvijotham and Pushmeet Kohli , title =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (. 2019 , url =
2019
-
[42]
Certified Robustness to Adversarial Word Substitutions , booktitle =
Robin Jia and Aditi Raghunathan and Kerem Gokhan G. Certified Robustness to Adversarial Word Substitutions , booktitle =. 2019 , url =
2019
-
[43]
Yi Zhou and Xiaoqing Zheng and Cho-Jui Hsieh and Kai-Wei Chang and Xuanjing Huang , title =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages =. 2021 , url =
2021
-
[44]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages =
Maor Ivgi and Jonathan Berant , title =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages =. 2021 , url =
2021
-
[45]
Ajinkya More , title =
-
[46]
2019 , address =
Xiong, Wenhan and Wu, Jiawei and Wang, Hong and Kulkarni, Vivek and Yu, Mo and Chang, Shiyu and Guo, Xiaoxiao and Wang, William Yang , booktitle =. 2019 , address =
2019
-
[47]
Qwen2.5 Technical Report , author =. arXiv preprint arXiv:2412.15115 , year =. 2412.15115 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open Foundation and Fine-Tuned Chat Models , author =. arXiv preprint arXiv:2307.09288 , year =. 2307.09288 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.